

数据采集与融合技术第二次作业
作业①
1)、爬取天气预报实验
1、实验要求
- 在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
2、编程思路
- 出现的问题
本次实验是对书本上的代码进行复现。刚开始在机房时复现没有出现什么问题,然后在下课之后重新运行进行截图时,惊奇地发现竟然出现了错误(头大 (ಥ_ಥ) )
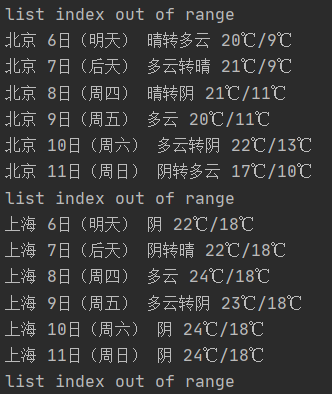
如上图,输出的结果出现了数组越界的异常,同时输出的天气预报少了一天
而且由于代码段用了try-except,所以还没有办法马上知道具体是哪个语句出现了数组越界,不过根据输出结果来看,输出的天气预报少了今天的,猜测应该是第一次循环出了问题,在循环前打断点
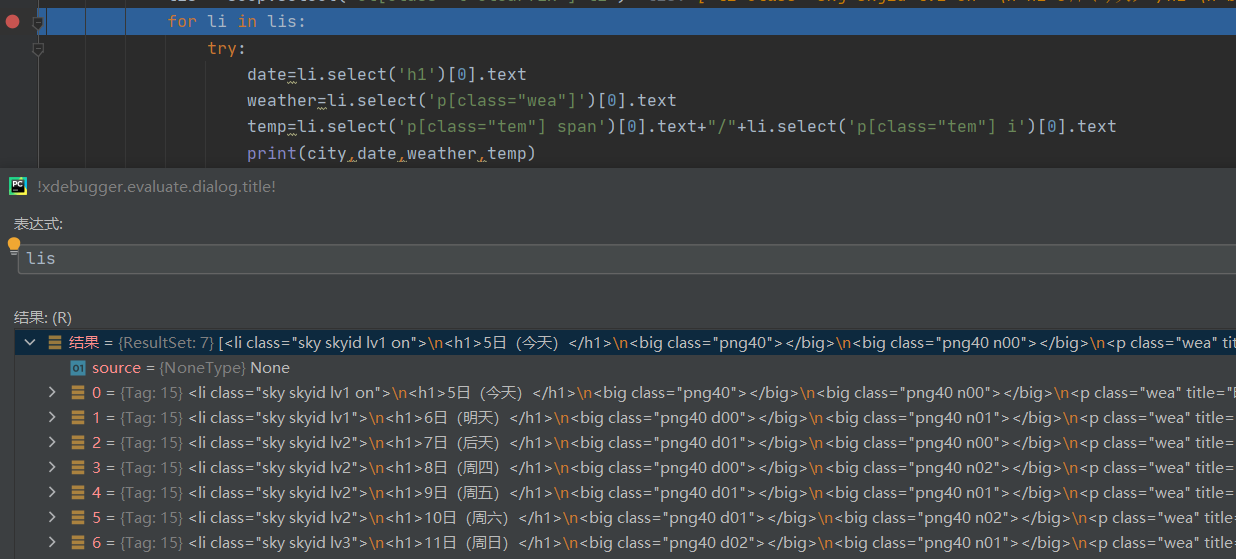
总体格式来看正常,一路走下去,发现了问题出现的位置

程序在执行temp=li.select('p[class="tem"] span')[0].text+"/"+li.select('p[class="tem"] i')[0].text后进入except,在控制台输入li.select('p[class="tem"] span'),发现值为空,大致明白了问题的所在,倒回去查看爬下来的html数据

发现今天的数据中只有一个温度,最后去网站中查看

确实只有一个温度(无奈o(╥﹏╥)o)。由于我每天都是晚上才开始打代码,所以连续试了好几天都是一样的错误。 - 解决方法
在白天18点之前的时候爬取就行了。若要在晚上爬取,则需要进行特判,且今天的数据只能爬取到一个温度数据。
3、完整代码
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)",(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
print("completed")
4、实验结果

2)、心得体会
- 爬取过程
作为一次复现实验,爬取过程以理解代码的思路为主,一路复现下来,学习了别人的编程思路和代码风格,收获颇丰,不亚于自己写代码。 - debug过程
复现过程没出现什么问题,然后因为爬取的时间出现了错误,花了比较多的时间找出问题所在。这个过程让我进一步地理解了调试对于编程的重要性,也对于pycharm的调试方式更加熟练。
作业②
1)爬取股票信息实验
1、实验要求:用requests和BeautifulSoup库方法定向爬取股票相关信息。
2、编程思路
本次实验要爬取动态的股票信息,有一点难度,根据参考链接进行学习,边理解思路边修改其中的bug,最后形成结果。主要的思路如下
- 获取url
这是本次的难点,由于是动态加载的数据,需要进行抓包,对比分析不同点。 - 分析数据
使用split方法,对爬下来的数据进行提取,提取出想要的各项信息。 - 输出数据
由于数据维度较多,且中英文混合,继续使用上次实验的prettytable无法达到比较美观,反而显得歪歪扭扭,因此直接存入excel中,比较整齐,而且对于股票这种非常实用的信息,存入excel中也便于做后续地分析。
3、完整代码
import requests
import re
import pandas as pd
#用get方法访问服务器并提取页面数据
def getHtml(cmd,page):
url = "http://nufm.dfcfw.com/EM_Finance2014NumericApplication/JS.aspx?cb=jQuery112406115645482397511_1542356447436&type=CT&token=4f1862fc3b5e77c150a2b985b12db0fd&sty=FCOIATC&js=(%7Bdata%3A%5B(x)%5D%2CrecordsFiltered%3A(tot)%7D)&cmd="+cmd+"&st=(ChangePercent)&sr=-1&p="+str(page)+"&ps=20"
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
r = requests.get(url,headers=headers)
r.encoding='utf-8'
pat = "data:\[(.*?)\]"
data = re.compile(pat,re.S).findall(r.text)
return data
#调用时获取单个页面股票数据
def getOnePageStock(cmd,page):
data = getHtml(cmd,page)
datas = data[0].split('","')
stocks = []
for i in range(len(datas)):
stock = datas[i].replace('"',"").split(",")
stocks.append(stock)
return stocks
def main():
cmd = {
"上证指数":"C.1",
"深圳指数":"C.5",
"沪深A股":"C._A",
"上证A股":"C.2",
"深圳A股":"C._SZAME",
"新股":"C.BK05011",
"中小板":"C.13",
"创业板":"C.80"
}
for i in cmd.keys():
page = 1
stocks = getOnePageStock(cmd[i],page)
#自动爬取多页,并在结束时停止
while True:
page +=1
if getHtml(cmd[i],page)!= getHtml(cmd[i],page-1):
stocks.extend(getOnePageStock(cmd[i],page))
else:
break
df = pd.DataFrame(stocks)
df.drop([0,14,15,16,17,18,19,20,21,22,23,25],axis=1,inplace=True)
columns = {1:"代码",2:"名称",3:"最新价格",4:"涨跌额",5:"涨跌幅",6:"成交量",7:"成交额",8:"振幅",9:"最高",10:"最低",11:"今开",12:"昨收",13:"量比",24:"时间"}
df.rename(columns = columns,inplace=True)
df.to_excel("股票"+i+".xls")
print("已保存"+i+".xls")
main()
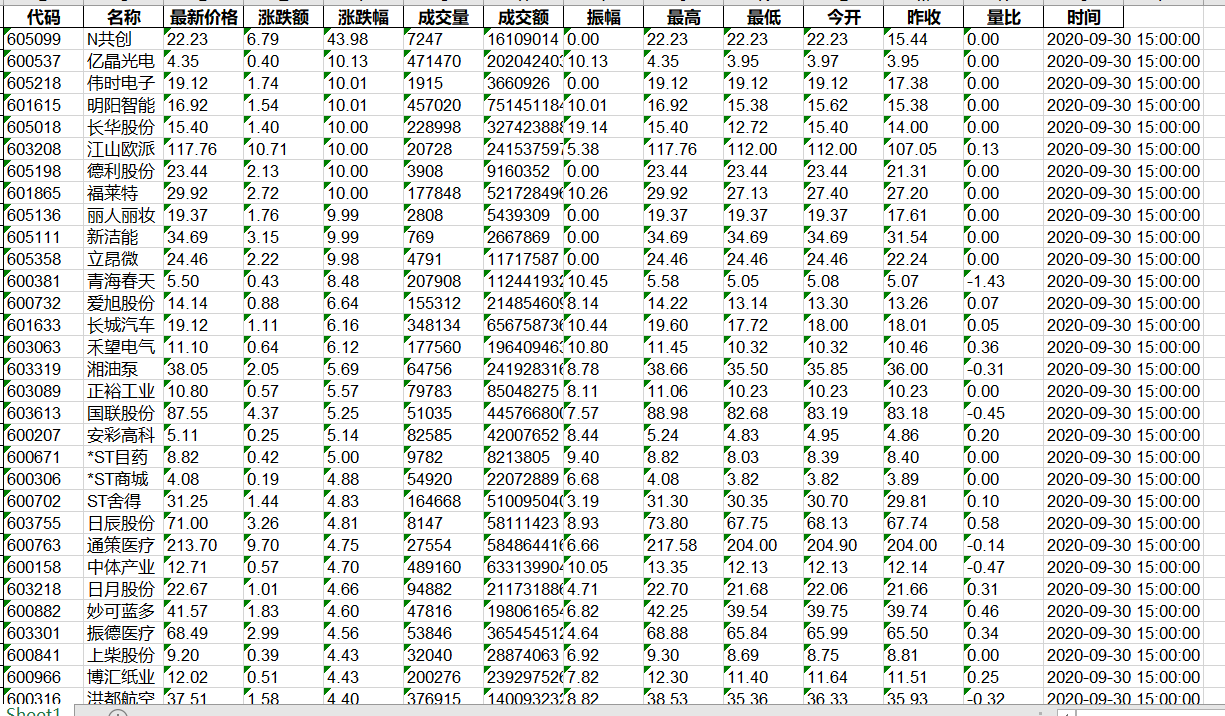
4、部分实验结果截图(输出到表格)
2)心得体会
本次实验学习了如何对动态的网页数据进行爬取,也是第一次用F12抓包来分析url,有一点陌生,属于摸索的过程。而且之前计算机网络的知识学得也比较差,对于抓包也比较陌生,折腾了好久才大致理解。在之后的学习中还要加强网页等方面的基础知识,毕竟爬虫的对象是网页上的数据,有些基础还是要的。
作业③
1)爬取指定代码股票数据实验
1、实验要求:根据自选3位数+学号后3位选取股票,获取印股票信息。抓包方法同作②。
2、编程思路
在有了第二题的基础上,第三题会比较简单,只需要在第二题的基础上稍作改动,加上过滤条件,并把结果输出到控制台即可。我的学号是107结尾,因此我选择的股票代码是399107.同时数据量不大,不必存入到表格中,因此使用prettytable进行存储输出即可(依旧是中英混合问题难以完全对齐,希望prettytable库能优化一下中文对齐问题,不然这个table就一点都不pretty(•́へ•́╬))。
3、完整代码
import requests
import re
import prettytable
#使用prettytable输出数据
Answer=prettytable.PrettyTable(["股票代码","股票名称","今日开","今日最高","今日最低"])
#用get方法访问服务器并提取页面数据
def getHtml(cmd,page):
url = "http://nufm.dfcfw.com/EM_Finance2014NumericApplication/JS.aspx?cb=jQuery112406115645482397511_1542356447436&type=CT&token=4f1862fc3b5e77c150a2b985b12db0fd&sty=FCOIATC&js=(%7Bdata%3A%5B(x)%5D%2CrecordsFiltered%3A(tot)%7D)&cmd="+cmd+"&st=(ChangePercent)&sr=-1&p="+str(page)+"&ps=20"
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
r = requests.get(url,headers=headers)
r.encoding='utf-8'
pat = "data:\[(.*?)\]"
data = re.compile(pat,re.S).findall(r.text)
return data
#获取单个页面股票数据
def getOnePageStock(cmd,page):
data = getHtml(cmd,page)
datas = data[0].split('","')
stocks = []
for i in range(len(datas)):
stock = datas[i].replace('"',"").split(",")
#特判,提取股票代码为399107的股票
if(stock[1]=="399107"):
#选取要求输出的几项,加入到prettytable中
Answer.add_row([stock[1],stock[2],stock[11],stock[9],stock[10]])
return stocks
def main():
cmd = {
"上证指数":"C.1",
"深圳指数":"C.5",
"沪深A股":"C._A",
"上证A股":"C.2",
"深圳A股":"C._SZAME",
"新股":"C.BK05011",
"中小板":"C.13",
"创业板":"C.80"
}
for i in cmd.keys():
page = 1
stocks = getOnePageStock(cmd[i],page)
#自动爬取多页,并在结束时停止
while True:
page +=1
if getHtml(cmd[i],page)!= getHtml(cmd[i],page-1):
stocks.extend(getOnePageStock(cmd[i],page))
else:
break
print(Answer)
main()
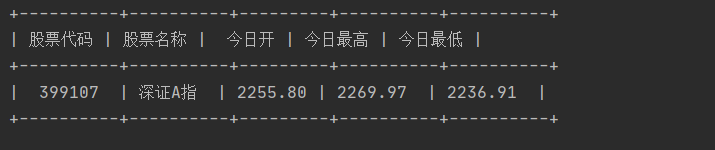
4、实验结果截图
2)心得体会
本次实验是在第二个作业的基础上做的一些小改动,总体来说难度不大,继续熟悉了一些基本的操作。

