
数据采集与融合技术第一次作业——结合三次小作业
作业①
1):BeautifulSoup爬取大学排名实验
1、实验要求
- 用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
2、编程思路
- 获取html数据
使用urllib.request方法,获取指定网址的html数据
url="http://www.shanghairanking.cn/rankings/bcur/2020"
html=urllib.request.urlopen(url).read().decode("utf-8")
- 分析html数据
![]()
如图所示,想要的数据都在互为兄弟节点的td节点下,获取其中一个节点后可以比较轻松地获取其他节点的信息。其中学校名称节点标签特征比较明显,使用select方法定位到学校名称节点

datas=soup.select("a[data-v-45ac69d8]")
然后访问datas的父节点,其他的数据都在父节点的兄弟节点上,使用previous_sibling和next_sibling方法访问,得到想要的节点,使用text方法获取节点的数据
- 数据处理
将获取的数据写入prettytable中,最后以表格的形式输出
3、完整代码
import urllib.request
from bs4 import BeautifulSoup
import prettytable as pt
url="http://www.shanghairanking.cn/rankings/bcur/2020"
html=urllib.request.urlopen(url).read().decode("utf-8")#获取html数据
soup=BeautifulSoup(html,"lxml")
datas=soup.select("a[data-v-45ac69d8]")#定位到学校名称所在的标签
Answer=pt.PrettyTable(["排名",'{0:{1}^13}'.format('学校名称',chr(12288)),"省市","学校类型","总分"])#使用prettytable库创建表,并输入表头
for data in datas:
Name=data.text.strip()#获取学校名称
Rank=data.parent.previous_sibling.text.strip()#大学排名位于学校名称的父节点的前兄弟节点
City=data.parent.next_sibling.text.strip()#城市位于学校名称的父节点的后兄弟节点
Type=data.parent.next_sibling.next_sibling.text.strip()#类型位于学校名称父节点的后第二个兄弟节点
Score=data.parent.next_sibling.next_sibling.next_sibling.text.strip()#总分位于学校名称父节点的后第三个兄弟节点
Answer.add_row([Rank,'{0:{1}^13}'.format(Name,chr(12288)),'{0:{1}^5}'.format(City,chr(12288)),Type,Score])#按行添加数据
print(Answer)
4、结果展示

2)心得体会
1、爬取数据方面
本次实验是第一次自己动手爬取网页数据,从获取html数据到分析html再到使用BeautifulSoup定位想要的数据,走了一遍完整的流程,体会了爬虫的过程。本次实验我的思路是先定位到学校名称所在的节点,然后访问其父节点的各兄弟节点,完成所要数据的获取。在实验的过程中我有一个很大的收获就是学会了使用调试功能,领会到了调试在coding过程中的作用。下图是我调试的过程。

使用pycharm的调试器中计算表达式的功能,在分析各个节点之间关系时,可以很方便的获取节点的父节点、兄弟节点的具体信息,以确定是否是我想要的节点,这样使得编程过程变得很清晰。
2、输出格式处理方面
本次实验在格式输出处理方面花了比较长的时间。按题目要求,我选择了使用prettytable库以比较美观的表格形式输出。第一次尝试时,输出的格式歪歪扭扭(有点小强迫症的我非常难受),如下图

百度查找原因后,得知是由于中文字符在format时,空格的个数会和英文的空格个数不同,所以自动format会比较歪。在加入了参数chr(12288)后,输出格式变得好看很多(结果见上步),数据部分都对的非常齐。有一点不足的地方就是标题无法和数据部分对齐。我尝试了很多方法,其中中间三列可以做到和数据部分对齐,因为标题和数据部分都是中文,可以使用相同的format,但是第一列和第五列确怎么都对不齐,感觉是因为数据部分会受到标题格式的限制。最后就是尽可能地把标题调到和部分比较接近,整体上尽可能地美观。
作业②
1)re方法爬取商城商品定价信息实验
1、实验要求
- 用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
2、编程思路
- 获取html数据
使用request.get方法获取html数据,其中爬取京东需要加headers不然可能会被拒绝
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
url="https://search.jd.com/Search?keyword=%E4%B9%A6%E5%8C%85&enc=utf-8&wq=&pvid=2392af0a86d042458fe8d21d65d13c17"
html=requests.get(url = url,headers = headers).text
- 分析html数据,获取商品名称
![]()
如图所示,商品名称数据都包含在em标签对中,使用正则表达式提取em和/em之间的所有数据

re.findall("<em>.*?</em>",html)
结果如下图所示,出现了三种干扰项:价格、"-"和"/"
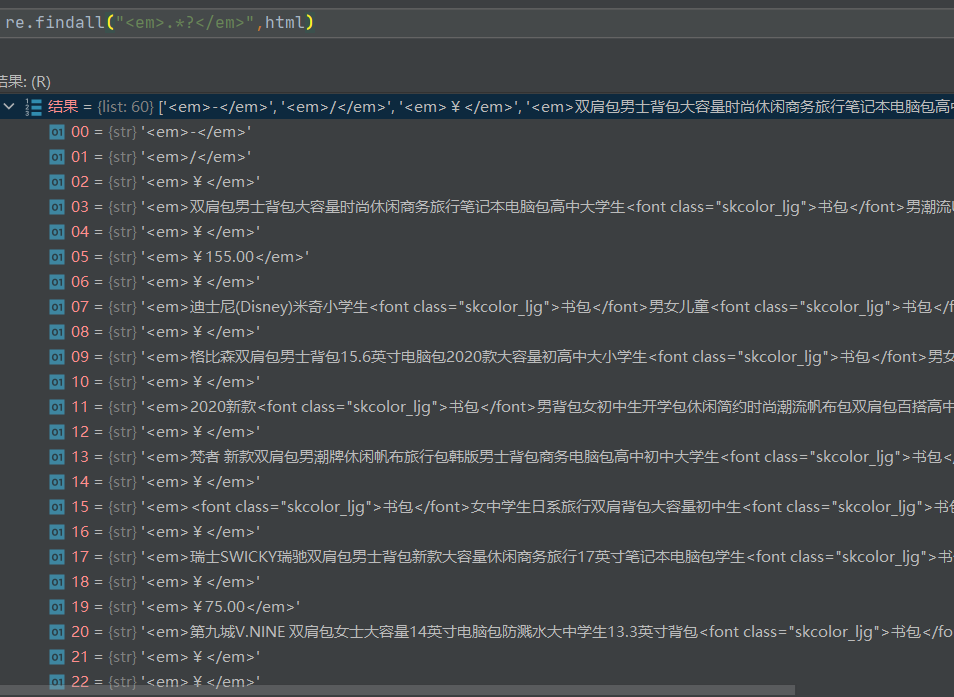
修改正则表达式,过滤掉干扰项
re.findall('<em>[^¥][^<].*?</em>',html)
结果如下图所示,成功获取想要的信息,但经过比对后发现遗漏了一部分信息,观察后发现遗漏的是em和/em之间有换行符的数据。
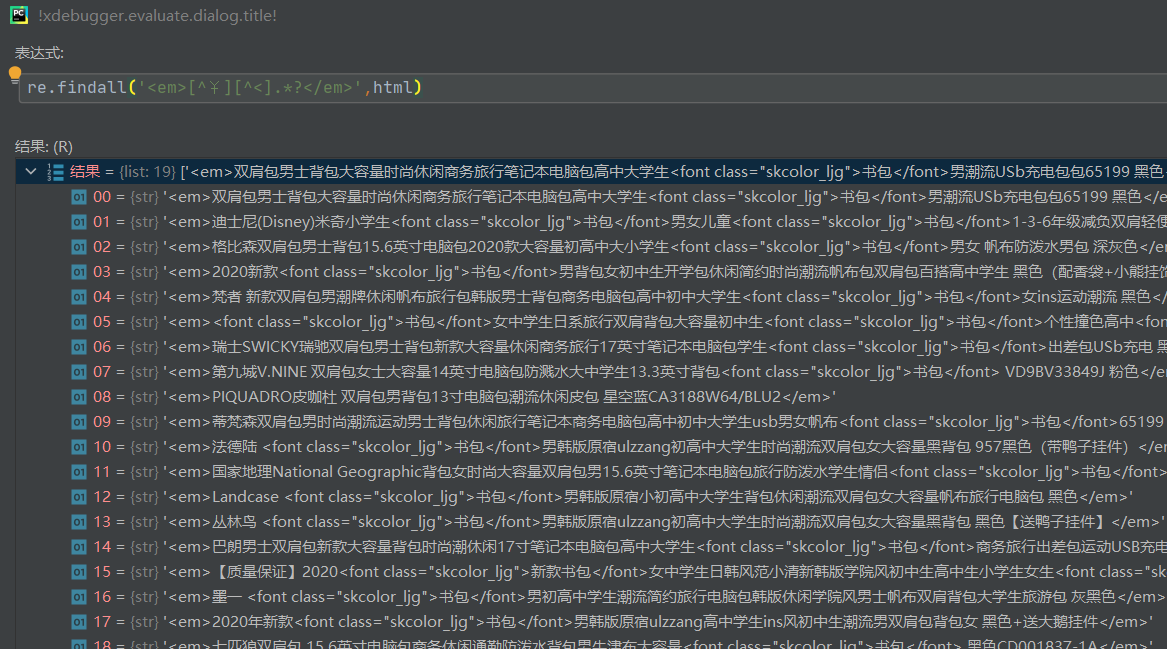
百度查找后,指定re.S参数,使.*?能匹配包括换行符在内的所有字符
re.findall('<em>[^¥][^<].*?</em>',html,re.S)
成功获取想要的数据的初始格式
- 分析html数据,获取价格
价格的获取相对比较简单
re.findall("<em>¥</em><i>\d+.\d+</i>",html)
得到价格的初始数据
- 数据处理
获取初始数据后,可知,只要把每个数据中的所有标签对去掉就能得到想要的结果,使用re.sub方法配合正则表达式可以实现这一功能。最后同作业①一样把数据存入prettytable中,以表格的形式输出。
3、完整代码
import re,requests
import prettytable as pt
#加入headers爬取京东,没有加的话可能会被拒绝
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
url="https://search.jd.com/Search?keyword=%E4%B9%A6%E5%8C%85&enc=utf-8&wq=&pvid=2392af0a86d042458fe8d21d65d13c17"
html=requests.get(url = url,headers = headers).text
#引入prettytable以表格形式输出
Answer=pt.PrettyTable(["价格",'{0:{1}^80}'.format("商品名",chr(12288))])
#获取商品名称,[^¥]排除价格的<em>标签的干扰,[^<]排除类似于<em>-</em>、<em>/</em>这种垃圾标签的干扰。re.S参数使得.*?可以匹配包括换行符的所有字符,否则.*?无法匹配换行符
titles=re.findall('<em>[^¥][^<].*?</em>',html,re.S)
#获取商品价格
prices=re.findall("<em>¥</em><i>\d+.\d+</i>",html)
for i in range(len(titles)):
#sub方法用于去掉字符串中的标签对
title=re.sub('<[^<]+?>',"",titles[i]).replace("\n","").replace("\t","").replace(" ","")
price=re.sub('<[^<]+?>',"",prices[i])
#按行插入数据,chr(12288)用来格式化中文字符串,使得对齐比较美观,但由于本题中有中英字符混合,难以完全对齐,只能做到各商品名基本居中对齐
Answer.add_row([price,'{0:{1}^80}'.format(title,chr(12288))])
print(Answer)
4、结果展示

2)心得体会
1、正则表达式的使用
本次实验是我第一次使用正则表达式来匹配数据,对于正则表达式的用法都比较陌生,都在一步一步地学习正则表达式的语法。实验之后也确实体会到了正则表达式的强大,短短一句话就能匹配出各式各样的数据,熟练之后会发现正则表达式能实现一些意想不到的功能,比如去掉标签对等等。在今后还要再加强对于正则表达式的学习使用。
2、实验的不足之处
依旧是格式方面的问题,这次爬取的数据中混杂着中文和英文,使用作业①中的方法也只能做到是的商品名称数据居中对齐,而无法做到在表格中各行数据占同样的位置。这个问题暂时还没有找到解决的方法,也只是尽可能地调整到美观
作业③
1)爬取网页图片实验
1、实验要求
爬取一个给定网页( http://xcb.fzu.edu.cn/html/2019ztjy )或者自选网页的所有JPG格式文件
2、编程思路
- 获取html数据
我爬取的是学校官网https://www.fzu.edu.cn的数据,使用urllib.request方法获取html数据
url="https://www.fzu.edu.cn"
html=urllib.request.urlopen(url).read().decode("utf-8")
- 分析数据
![]()

在学校网站中检查元素,可以发现图片所对应的html数据都是/attach开头以.jpg结尾,因此使用正则表达式比较方便
re.findall(r"/attach.*?.jpg",html)
- 图片下载
获取图片的地址后,使用urllib.request.urlretrieve可以将指定路径的图片下载下来,并将其存到指定的文件夹中
3、完整代码
#爬取学校官网的图片
import urllib.request
import re
url="https://www.fzu.edu.cn"
html=urllib.request.urlopen(url).read().decode("utf-8")
#图片的字段都是形如/attach/2010/09/17/39885.jpg,因此用正则表达式爬取
l=re.findall(r"/attach.*?.jpg",html)
#存爬下来图片的路径
path="C:\\Users\\57084\\Desktop\\picture\\"
#x用于给爬下来的图片命名,从1开始递增
x=1
for li in l:
#使用urlretrieve方法从指定的网址下载文件到指定的本地路径
urllib.request.urlretrieve("https://www.fzu.edu.cn"+li,path+str(x)+".jpg")
x+=1
4、结果展示

2)心得体会
经过前两次的实验后,第三次实验做起来会轻松很多,本次实验与之前实验的区别在于之前的实验只从爬下来的html数据中提取出想要的数据即可,而本次实验在提取出想要的图片网址之后还需要调用方法到对应的网址把图片下载到本地。
总体来说,经过三次实验,我对于爬虫有了初步的一些了解(挺好玩的(◕ᴗ◕✿)),在之后的学习过程中希望能接触到更高级的爬虫。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号