
【python】下载中国大学MOOC的视频
【python】下载中国大学MOOC的视频
脚本目标:
输入课程id和cookie下载整个课程的视频文件,方便复习时候看
网站的反爬机制分析:
分析数据包的目的:找到获取m3u8文件的路径
1. 从第一步分析数据包开始,就感觉程序员一定是做了反爬机制,从一开始就防备着了,网站在打开调试工具的时候会死循环在debugger上,代码写法和原理可以参考这篇文章【如何防止页面被调试_小敏哥的专栏-CSDN博客_网页禁止调试】,只需要停用断点就可以继续调试,在network里看数据包
2. 搜索关键字m3u8,获得下载m3u8的链接
https://mooc2vod.stu.126.net/nos/hls/2019/03/13/1214418097_fe38e0e942144bxxxxxxxxxxxx8ef_sd.m3u8?ak=7909bff134372bffca53cdc2c17adc27a4c38c6336120510aea1ae1790819de820f66b1081b2dbb1d6300ca9e91c8b349a14ab1e5b4e06c0887fe54fe47de9823059f726dc7bb86b92adbc3d5b34b1320647b25cf54eb8ac6ed1f0d7db7826b19bb0a5ea14ff29775bd482caa79ccf8b
简化得到
https://mooc2vod.stu.126.net/nos/hls/2019/03/13/1214418097_fe38e0e942144bxxxxxxxxxxxx8ef_sd.m3u8
通过get方式,下载查看,里面的ts下载链接是可以需要拼接的,文件没有加密,因此只需要用request发送数据包,就可以下载得到,接下来寻找构造数据包的依据
3. 分析数据包得到,m3u8文件的下载链接出现在另一个链接访问得到的内容里
链接为:https://vod.study.163.com/eds/api/v1/vod/video?videoId=1215086738&signature=75584967794f373450387775426e39512b565a6d4a4643384a366b3743766e556474475a7454466252672b6c5252306a744e585a61365031766269547650504454724750544c683252715a475876585962727a536f7431736a596d4f7843593577306d714654534864385873446e5470397a5675537a7233486836336d7a4355576e506745582b47762f2b37574b6972745365744d673d3d&clientType=1
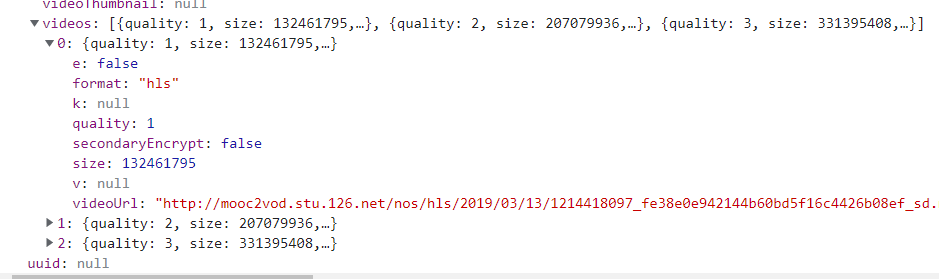
链接需要由videoId和signature,两个变量组成,两个变量必须对应,不然无法访问,并且是采用了http2的形式传输,相当于ban掉了request库,接下来需要找到videoId和其对应的signature
4.分析数据包得到signature的值被包含在以下url中,需要通过http2进行访问,并且在访问的同时需要POST提交一个数据包,数据包的内容为“bizId=1268148xxx&bizType=1&contentType=1
https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey=7d56f95de17346eeb0e0fd1d2d6b5751”
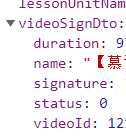
此时需要寻找bizId和csrfKey的值
5. 分析数据包得到,bizid,每节课的名称,每节课videoid(contentId)被存放在以下url的内容中,需要通过http2进行访问,并且在访问的同时需要POST提交一个数据包,数据包的内容为“termId: 1465388xxx”
https://www.icourse163.org/web/j/courseBean.getLastLearnedMocTermDto.rpc?csrfKey=7d56f95de17346eeb0e0fd1d2d6b575
提交的数值和课程链接中tid后面的值相同,需要填写变量仅剩下csrfKey
6.csrfKey被存放在cookie的NTESSTUDYSI=中,只需要cookie就可以得到csrfKey。此时只需要cookie和课程id就能获得每个课程的m3u8文件下载链接
已知信息:
1. 网站的反爬机制
2. 视频ts文件没有加密
3. 网站使用http2协议,使用httpx代替request
4. 拿到m3u8文件的下载链接后,直接甩给上一篇写的m3u8的下载器,改一改拼接在一起,能用就行
5. 虽然在调试的时候提示是“非法的跨域请求”,但是没有判断referer的值,只是判断了cookie值
脚本思路:
1. 获得自己的cookie,从cookie中提取出NTESSTUDYSI=得到csrfKey
2. 用http2.x,且为post的方式访问“https://www.icourse163.org/web/j/courseBean.getLastLearnedMocTermDto.rpc?csrfKey=csrfKey“,构造POST数据包 termId: tid。在得到的数据包内得到每节课的名称,每节课videoid(contentId),bizId(id)
3. 用http2.0,且为post的方式访问,访问做了跨域限制“https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey=csrfKey”构造POST数据包bizId=bizId&bizType=1&contentType=1 。 得到signature
4. 用http2.0,且为get的方式访问https://vod.study.163.com/eds/api/v1/vod/video/videoId=videoId&signature=signature&clientType=1 得到videoUrl,就是一个m3u8的下载地址,删除问号后面的内容,直接访问就可以下载
5. 拼接上次写的脚本
最终功能代码:
import os import re import httpx import time import requests import aiohttp import asyncio import aiofiles obj = re.compile(r".*?NTESSTUDYSI=(?P<csrfkey>.*?);") obj2 = re.compile(r".*?'units': \[{'id':(?P<id>.*?),") obj3 = re.compile(r".*?'contentType': 1, 'contentId':(?P<bizld>.*?),") obj4 = re.compile('.*?"signature":"(.*?)",') obj5 = re.compile('.*?"videoUrl":"(?P<m3u8>.*?)\?ak') obj6 =re.compile('.*?"name":"(.*?)",') def init(): if not os.path.exists("./temp_data"): os.mkdir("./temp_data") if not os.path.exists("./cookie.txt"): cookie = str(input("没有检测到cookie,请输入cookie>")) with open("./cookie.txt", "w") as f: f.write(f"{cookie}") with open("cookie.txt", "r") as f: cookie = f.read() return cookie def get_video_id(csrfkey): tid = str(input("输入课程的tid>")) data = {"termId": f"{tid}"} client = httpx.Client(http2=True) resp = client.post(f"https://www.icourse163.org/web/j/courseBean.getLastLearnedMocTermDto.rpc?csrfKey={csrfkey}",headers=header, data=data) resp.close() json = resp.json() shu_ju = str(json["result"]["mocTermDto"]["chapters"]) bizld = str(obj2.findall(shu_ju)).replace(" ","").replace("[","").replace("]","").replace("'","").split(",") video_id = str(obj3.findall(shu_ju)).replace("' None', ","").replace(" ","").replace("'","").replace("[","").replace("]","").split(",") print("获取bzid和video_id") return bizld,video_id def get_signature(bizlds,csrfkey): signatures=[] client = httpx.Client(http2=True) for bizld in bizlds: data = {"bizId":f"{bizld}","bizType":"1","contentType":"1"} resp=client.post(f"https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey={csrfkey}",headers=header,data=data) resp.close() signatures = signatures+obj4.findall(resp.text) print("获取signatures") return signatures def get_m3u8_url(video_ids,signatures): m3u8_urls = [] merge_name = [] client = httpx.Client(http2=True) for video_id,signature in zip(video_ids,signatures): resp = client.get(f"https://vod.study.163.com/eds/api/v1/vod/video?videoId={video_id}&signature={signature}&clientType=1",headers=header) resp.close() time.sleep(2) merge_name.append(str(obj6.findall(resp.text)).replace("[", "").replace("]", "").replace("'", "")) m3u8_url = obj5.findall(resp.text)[0] m3u8_urls.append(m3u8_url) print("下面是合并文件名:",merge_name) return m3u8_urls,merge_name async def download_ts(file_name,download_url,session): async with session.get(download_url,headers=header) as resp: async with aiofiles.open(f"temp_data/{file_name}",mode="wb") as f: await f.write(await resp.content.read()) async def starter(name,m3u8_url): tasks=[] async with aiohttp.ClientSession() as session: #https://mooc2vod.stu.126.net/nos/hls/2019/03/13/1214418097_fe38e0e942144b60bd5f16c4426b08ef_sd0.ts url = str(m3u8_url).rsplit("/",1)[0] with open(f"temp_data/{name}.txt", "r") as f: for line in f: if line.startswith("#"): continue else: line = line.strip() file_name = line # 得下载的ts文件名 download_url = url + "/" + line print("下载链接是:",download_url) task = download_ts(file_name, download_url, session) tasks.append(task) await asyncio.wait(tasks) # 等待任务执行结束 print("文件下载完成") def m3u8_files_download(url,name): #下载m3u8文件 resp = requests.get(url) with open(f"temp_data/{name}.txt",mode="wb") as f: f.write(resp.content) resp.close() def verification(name): files=[] with open(f"temp_data/{name}.txt","r") as f: for line in f: if line.startswith("#"): continue else: line=line.strip() if os.path.exists(f"temp_data/{line}"): continue else: files.append(line) print("以下文件缺失,请手动查看:",files) def merge_ts(file_name,merge_name): new_name = str(merge_name) with open(f"./{new_name}.mp4", "ab+") as f: with open(f"temp_data/{file_name}.txt","r") as f2: for line in f2: if line.startswith("#"): continue else: line = line.strip().split("/")[-1].strip() ts_name = line try: with open(f"temp_data/{ts_name}","rb") as f3: f.write(f3.read()) except: continue def m3u8_main(m3u8_urls,merge_names): print("获取m3u8链接,开始执行下载任务") for url,merge_name in zip(m3u8_urls,merge_names): name = url.rsplit("/")[-1] m3u8_files_download(url, name) # 下载m3u8文件 asyncio.run(starter(name,url)) print("校验文件完整性") verification(name) merge_ts(name,merge_name) if __name__=="__main__": cookie = init() header = {"cookie": f"{cookie}"} csrfkey = obj.findall(cookie)[0] print("获取csrfkey") bizid,video_id= get_video_id(csrfkey) signatures = get_signature(bizid,csrfkey) m3u8_urls,merge_name = get_m3u8_url(video_id,signatures) m3u8_main(m3u8_urls,merge_name)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号