

并行计算简介
作者: Blaise Barney, 劳伦斯利弗莫尔国家实验室
译者:卢洋,同济大学,2009年4月
原文地址:https://computing.llnl.gov/tutorials/parallel_comp/
目录
1 摘要
为了让新手更加容易熟悉此话题,本教程覆盖了并行计算中比较基础的部分。首先在概述中介绍的是与并行计算相关的术语和概念。然后探索并行存储模型和编程模型这两个话题。之后讨论一些并行程序设计相关的问题。本教程还包含了几个将简单串行化程序并行化的例子。无基础亦可阅读。
2 概述
2.1 什么是并行计算
l 传统上,一般的软件设计都是串行式计算:
² 软件在一台只有一个CPU的电脑上运行;
² 问题被分解成离散的指令序列;
² 指令被一条接一条的执行;
² 在任何时间CPU上最多只有一条指令在运行

l 在最简单的情形下,并行计算是使用多个计算资源去解决可计算问题。
² 用多核CPU来运行;
² 问题被分解成离散的部分可以被同时解决;
² 每一部分被细分成一系列指令;
² 每一部分的指令可以在不同的CPU上同时的执行;

l 计算资源可以包括:
² 多核CPU;
² 任意数量的CPU用网络连接起来;
² 或者以上两者结合;
l 可计算问题通常展示出如下的特性:
² 能分解成可以同时解决的离散的工作块;
² 同一时刻可以执行多条程序指令;
² 通常用多个计算资源解决问题所花的时间要比单个计算资源要短;
Ø 宇宙是并行的
l 并行计算是由串行计算发展而来,试图去模仿真实世界中事物的处理过程:许多复杂的互相关联的事件同时发生,例如:
银河系的变换; 行星的运动; 天气和海洋的变化;
交通堵塞; 大陆板块迁移; 炊烟升起;
自动的流水线; 建造空间飞行器; 开车买汉堡;

Ø 并行计算的用途:
l 在历史上,并行计算被认为是高端计算,并用于为复杂的科学计算和基于真实世界的工程问题建模。下面是一些例子:
² 大气层、地球、环境
² 物理学应用、核能、原子能、凝聚态、高压、溶解、光电子;
² 生物科学、生物工程、基因学
² 化学、分子科学
² 地理和地震学
² 机械工程、从弥补术到空间飞行器
² 电气工程、电路设计、微电子学
² 计算机科学、数学

l 今天,商务应用是推动快速计算机发展的更大的推动力。这些应用需要用复杂的方法处理大量数据。例如:
² 数据库、数据挖掘
² 石油勘探
² 网络搜索引擎、基于网络的商务服务
² 医学成像和诊断
² 制药设计
² 国有企业或跨国企业的管理
² 金融经济建模
² 高级制图和虚拟现实、特别实在娱乐事业上
² 网络视频和多媒体技术
² 协同工作环境

2.2 为什么使用并行计算
Ø 主要的原因有:
l 节省时间和成本:理论上,使用更多的资源会使一个任务提前完成,而且会节约潜在的成本。况且可以使用便宜的、甚至市面将要淘汰的CPU来构建并行聚簇。
 |
 |
l 解决更大规模的问题:很多问题是相当庞大而复杂的,尤其是当计算机的内存受到限制的时候,用单个计算机来解决是不切实际或者根本不可能的。例如:
² "Grand Challenge" (en.wikipedia.org/wiki/Grand_Challenge) 问题需要Peta级浮点运算能力和存储空间的计算资源。
² 网络搜索引擎和网络数据库每秒钟要执行上百万次的处理。

l 支持并行:单一的计算资源在同一时刻只能做一件事情。多个计算资源能够同时做很多事情。例如:Access Grid (http://www.accessgrid.org/)提供一个全球的合作网络,在这里来自世界上不同国家的人们可以开会并“现场”指导工作。

l 使用非本地资源: 当缺少本地计算资源的时候可以使用广泛的网络或Internet计算资源。例如:
² SETI@home (setiathome.berkeley.edu) 使用超过330000个计算机来执行每秒超过528T次浮点运算;(August 04, 2008)
² Folding@home (folding.stanford.edu)使用超过340,000 计算机来执行每秒4.2P次浮点运算 (November 4, 2008)

l 串行计算的限制:在理论上和实际上,想要轻易地制造更快的串行计算机存在着巨大的限制。
² 传输速度——线性计算机的执行速度直接取决于数据在硬件中传输的速度。光速的绝对限制是每纳秒
² 微型化的极限——处理器技术使芯片集成了更多的晶体管。但是,即使使用分子或者原子级别的组件也会很快达到芯片集成晶体管的极限。
² 经济上的限制——让单个芯片变得更快需要增加昂贵的投入。用多个一般的芯片来取代单个高性能的芯片或许性能会更好而且更便宜。
现在的计算机体系结构越来越依赖于硬件层次的并行来提高性能:
² 多个执行单元
² 管道指令
² 多核
Ø 谁?什么?
l Top500.org 给出了并行计算用户的数据统计——下面的图标只是一个样例。下面几点需要注意:
² 扇形可能重叠——例如,研究的部分可能在经典研究中。作者不得不二选一。
² 目前为止未分类的最大应用可能是多种应用集合。

Ø 未来
在过去的20年里,更快速网络、分布式系统、多核处理器体系结构(甚至是在桌面应用级别)的发展趋势已经很清楚的指出并行化是未来科学计算的发展方向。
3 概念和术语
3.1 冯诺依曼体系结构
以匈牙利数学家约翰. 冯诺依曼命名,他是第一个在1945年的论文中提出通用电子计算机必要条件的创始人。
从那时开始,实际上所有的计算机都遵从这个基本的设计,区别于早期的硬布线编程的计算机设计。
主要有五个主要的部件构成:内存、控制单元、逻辑计算单元、输入输出
读/写,随机存储内存用于储存程序指令和数据:程序指令是告诉计算机做什么事的代码数据、数据是程序用到的简单数据。
控制单元从内存中取回指令/数据,解码指令然后连续协调操作来完成编码工作。
计算单元完成基本的计算操作。
输入输出是用户操作的界面。
 |
3.2 Flynn经典分类法
有很多方法给并行计算机分类,其中,Flynn分类法从1966年开始使用被大家广为接受。
Flynn分类是利用两个独立的标准指令和数据对多核计算机体系结构进行划分的。每一个标准有两种可能的值:单个或者多个
|
|
|
S I S D 单指令单数据 |
S I M D 单指令多数据 |
|
M I S D 多指令单数据 |
M I M D 多指令多数据 |
Ø 单指令单数据(SISD)
串行计算机
单个指令:在一个系统时钟周期只有一条指令可以被执行。
单数据:在一个系统时钟周期只有一个数据流可以被用来输入。
确定性执行。
这是迄今为止最老的,但大多数通用计算机都是这个类型。
例如:老一代的大型机、微机和工作站,还有现在大多数的PC机。

UNIVAC1 |
IBM 360 |
CRAY1 |
CDC 7600 |
PDP1 |
Dell Laptop |
Ø
|
|
并行计算机的一种
单指令:所有的处理单元在给定的时钟周期只能
执行相同的指令。
多数据:每一个处理器单元可以同时处理不同的
数据元素。
最适合处理高度规则的问题,如图形图像处理。
同步,确定性执行。
两类:处理器数组和向量流水线。
例如:处理器矩阵:Connection Machine CM-2,
MasPar MP-1 & MP-2, ILLIAC IV;向量流水线:IBM 9000, Cray X-MP, Y-MP & C90, Fujitsu VP, NEC SX-2, Hitachi S820, ETA10。
最先进的计算机,特别是带有图形处理器单元的计算机都使用SIMD指令集和执行单元。

ILLIAC IV |
MasPar |
 |
Cray X-MP |
Cray Y-MP |
Thinking Machines CM-2 |
Cell Processor (GPU) |
Ø
单数据流进入多处理器单元。
每一个处理器单元通过独立的指令流在独立的操作数据。
这种计算机几乎在市面上找不到。有一个实验机Carnegie-Mellon C.mmp
可能用于单信号流上多频率过滤、用多密码学算法破解单码信息。

Ø
现在,大多数通用并行计算机都是这种。
多指令:每个处理器可以执行不同的指令流
多数据:每个处理器可以用不同的数据流。
同步或异步、确定性或非确定性执行。
例如:大多数的超级计算机、网格计算机、多核SMP计算机,多核PC机。
注意:很多MIMD体系结构也包含SIMD执行子构件。

IBM POWER5 |
HP/Compaq Alphaserver |
Intel IA32 |
AMD Opteron |
Cray XT3 |
IBM BG/L |
3.3 一些通用的并行术语
像其他的东西一样,并行计算机有他自己的术语。下面列出了一些与并行计算相关的通用的术语。其中大多数都会在后面再进行详细的讨论。
Task:可计算工作在逻辑上不连续的分区。一个任务通常是一个程序或者类似程序一样的可以被处理器执行的指令集。
Parallel Task:一个任务可以被多个处理器安全的并行的执行,产生正确的结果。
Serial Execution:程序相继的执行,每次一个状态。在最简单的情况下,单核处理器就是这样运行的。可是,实际上所有并行的任务有一些并行程序的区域一定要串行的执行。
Parallel Execution:一个或多个任务同时执行的程序,每个任务同时能够执行相同的或不同的代码语句。
Pipelining:不同的处理器单元把一个任务根据输入流来分解成一系列步骤来执行,相当于一条流水线;并行计算的一种。
Shared Memory(共享内存):完全从硬件的视角来描述计算机体系结构,所有的处理器直接存取通用的物理内存(基于总线结构)。在编程的角度上来看,他指出从并行任务看内存是同样的视图,并且能够直接定位存取相同的逻辑内存位置上的内容,不管物理内存是否真的存在。
Symmetric Multi-Processor(对称多处理器):这种硬件体系结构是多处理器共享一个地址空间访问所有资源的模型;共享内存计算。
Distributed Memory(分布式存储):从硬件的角度来看,基于网络存储的物理内存访问是不常见的。在程序模型中,任务只能看到本地机器的内存,当任务执行时一定要用通信才能访问其他机器上的内存空间。
Communication:并行任务都需要交换数据。有几种方法可以完成,例如:共享内存总线、网络传输,然而不管用什么方法,真实的数据交换事件通常与通信相关。
Synchronization:实时并行任务的调度通常与通信相关。总是通过建立一个程序内的同步点来完成,一个任务在这个程序点上等待,直到另一个任务到达相同的逻辑设备点是才能继续执行。同步至少要等待一个任务,致使并行程序的执行时间增加。
Granularity(粒度):在并行计算中,粒度是定量化的用来测定通信和计算比率的方法。粗糙级:在两个通信事件之间可以完成相对大量的可计算工作。精细级:在两个通信事件之间只能完成相对较少量的可计算工作。
Observed Speedup:测量代码并行化之后的加速比。这是最简单也最广泛使用的测量并行程序性能的方法。
|
wall-clock time of serial execution ———————————————————— wall-clock time of parallel execution |
Parallel Overhead(并行开销):对并行任务调度花费的时间没有做有用的工作。并行开销可以包含如下因素:任务启动时间、同步、数据通信、并行编译器、库、工具、操作系统等花费的软件开销,任务终止的时间等。
Massively Parallel(大规模并行):指包含给定的并行系统硬件——有多个处理器。“多个“的意思是可以不断的增加,但是目前大规模并行计算机由上百个处理器构成。
Embarrassingly Parallel:同时解决很多相似的独立的任务;任务之间基本不需要调度。
Scalability:指的是并行系统通过增加更多的处理器的个数按比例提高并行性能的能力。促进可扩展性的因素有:硬件——特别是内存、CPU带宽和网络通信,应用程序算法,相关的并行开销、特定的应用和编码方式的特征。
Multi-core Processors:一个CPU上有多个处理器。
Cluster Computing:用一般的处理器单元(处理器、网络、SMP)来构建并行系统。
Supercomputing / High Performance Computing(高性能计算):使用世界上最快最大的机器来解决大规模的问题。
4 并行计算机存储结构
4.1 共享内存
Ø 一般特性:
共享内存计算机有很多种类,但是都有一个共同的特点,所有的处理器都把内存作为全局的地址空间来进行访问。
多处理器能够单独的运行,但是都共享相同的内存地址。
共享内存的机器可以根据内存的存取次数大体分成两类:UMA和NUMA。
Ø UMA统一的内存访问
现在大多数的SMP处理器就属于此类。
同核处理器。
对内存的存储机会和次数均等。
缓存连贯意思是如果一个处理器更新共享内存,
其他的所有处理器都会知道。这是由硬件层来实现的。
Ø NUMA非统一的内存访问
通常是在物理层上链接两个或多个SMP构成的。
一个SMP能够直接访问另一个SMP的内存
不是所有的处理器都有对内存平等的访问机会
通过连接的内存访问会更慢
如可以保持缓存的连贯性,也可以叫做CC-NUMA - Cache Coherent NUMA。
Ø 优点:
全局的地址空间提供了一个对用户友好的编程视角。
由于内存CPU之间的密切合作使得任务间的数据共享即快速又统一。
Ø 缺点:
主要的缺点是内存和CPU之间的可扩展性较差。增加CPU之后会增加共享内存和CPU之间传输时间,在缓存连贯的系统中,也会增加与缓存内存管理相关的数据流量。
程序员有责任同步系统以确保正确的访问全局存储空间。
代价:用更多的处理器设计和生产共享内存机器越来越困难而且越来越昂贵。

Shared Memory (UMA)
Shared Memory (NUMA)
4.2 分布式内存
Ø 一般特征:
像共享内存系统一样,分布式内存系统也有很多种,但是有一个共同特点:分布式存储系统需要通信网络来连接核间内存。

处理器都有各自的内部寄存器。一个核内的存储地址对其他核不可见,对于所有CPU都没有全局地址空间的概念。
由于每个处理器都有自己独立的内存,本地内存的改变将不会影响到其他的处理器。因此没有实现缓存一致性。
当一个处理器需要访问另一个处理器的数据时,程序员的任务就是清楚的定义什么时候用什么方法来通信。任务间的同步问题也是程序员的职责。
总线网络通信的方式有很多种,最简单的方法类似以太网。
Ø 优点:
a) 内存可以和CPU的个数一起扩展。增加处理器的个数将使得内存的大小等比例增加。
b) 每个处理器可以没有冲突的快速访问自己的内存,也不需维护缓存一致性的开销。
c) 成本效益:可以用一般的下市的CPU加上网络来构建。
Ø 缺点:
d) 1程序员将要负责所有处理器间数据通信相关的细节问题。
e) 2很难从基于全局内存空间的数据结构上建立起到分布式内存管理的映射。
f) 3非统一的内存访问次数。
4.3 混合型分布式共享内存
a) 当今最快最大计算机就是这种混合行分布式共享内存体系结构。

b) 共享内存组件通常用于缓存一致的SMP机器。在特定的SMP核上可以寻址机器的全局内存。
c) 分布式内存组件是由多个SMP网络构成。SMP只能看到自己的缓存区。因此SMP间需要通信。
d) 现在的趋势显示这种类型的存储体系结构将会在不远的将来在高端计算机上继续流行和发展。
e) 优点和缺点:同上。
5 并行编程模型
5.1 概览
现在主要以下几种通用的并行编程模型:共享内存、线程、消息传递、数据并行、混合模型。
并行编程模型是在硬件和内存体系结构层之上的抽象概念。
仔细研究可以发现,这些模型并不是为了某一个特定的机器或内存体系结构而设计的。事实上,这些模型都可以在硬件层之下实现。两个例子:
Ø 分布式内存机器上的共享内存模型:Kendall Square Research (KSR) ALLCACHE approach。机器的内存物理上的实现是分布式内存,但是对用户来说是一个单一的全局地址空间。一般来说,这种方法叫做虚拟共享内存。注意:尽管KSR不再应用于商务贸易方面,但是不代表其他的供应商以后不会再利用这种方式。
Ø 共享内存机器上的消息传递模型:MPI on SGI Origin。SGI Origin 使用 CC-NUMA类型的共享内存体系结构,这种体系结构可以使得每个任务都可以直接访问全局内存。然而,MPI发送和接受消息的功能,就像通常在网络上实现的分布式内存机器一样,实现方法相似,还十分通用。
要使用哪个模型通常取决于可以获得哪个模型和个人的选择。尽管现在有模型相对于其他的来说确实有更好的实现方法,但是这里没有“最好”的模型。
接下来将详细描述上面提到的每个模型,也会讨论它们的实现方法。
5.2 共享内存模型
a) 在共享编程模型中,任务间共享统一的可以异步读写的地址空间。
b) 共享内存的访问控制机制可能使用锁或信号量。
c) 这个模型的优点是对于程序员来说数据没有身份的区分,不需要特别清楚任务简单数据通信。程序开发也相应的得以简化。
d) 在性能上有个很突出的缺点是很难理解和管理数据的本地性问题。
n 处理器自己的缓冲区中使用数据,使用完毕后刷新缓存写入内存,此时可能发生多个处理器使用相同数据的总线冲突。
n 不幸的是,一般用户很难理解或控制数据的本地化问题。
Ø 实现
在共享内存平台上,本地的编译器将会把用户程序变量转换到全局地址空间中。
现在市面上还没有一般的分布式内存平台的实现。然而,先前在我们概览部分提到的KSR,它就是在分布式的机器上提供了一个共享的数据平台。
5.3 线程模型
Ø 在并行编程的线程模型中,单个处理器可以有多个并行的执行路径。

Ø 线程模型的构成如下:
l 操作系统调度主程序a.out开始运行,a.out加载所有必要
l a.out完成一些串行工作,然后创建一些可以被操作系统调度的并行任务(线程)去执行。
l 每次线程都有自己的数据,而且共享整个a.out的资源。这样就节省了拷贝程序资源给每个线程的开销。这样线程之间可以并行执行子程序。
l 线程之间通过全局内存进行通信。这个需要同步构造来确保多个线程不会同时更新同一块全局内存。
l 线程执行完了就自动销毁,但是主程序a.out在应用程序完成之前一直存在,维护必要的共享资源。
Ø 线程通常和共享内存体系结构和操作系统相关。
u 实现:
ü 从程序的角度出发,线程的实现通常包括:
1)并行代码需要调用的子程序库;
2)串行或者并行源代码中的一套编译器指令。
ü 在以上两部分中,程序员都要负责制定所有的并行机制。
ü 线程的实现并不是什么新技术,硬件供应商已经实现了他们自己的线程版本。线程的实现机制本质上的不同使得程序员很难开发出可以移植的多线程应用程序。
ü 不同的标准产生了两个不同的线程实现方式:POSIX线程和OpenMP
u POSIX线程:
ü 基于库函数的,需要并行编码。
ü IEEE POSIX
ü 只适用于C语言
ü 通常是指Pthreads
ü 大多数的硬件供应商现在为自己的线程实现加入Pthreads
ü 十分清晰的并行,需要程序员特别关注实现的细节。
u OpenMP:
ü 基于编译器指令,可以使用串行代码。
ü 有一群计算机软硬件厂商共同定义并支持。OpenMP在1997年完成Fortran的API,于1998年完成C/C++的API
ü 简洁而且跨平台(Unix、Windows NT)
ü 有C/C++和Fortran的实现
ü 使用简单,支持增量并行
微软有自己一套独立的线程实现机制,与以上两者都不相关。
u 更多信息
POSIX的教程computing.llnl.gov/tutorials/pthreads
OpenMP的教程computing.llnl.gov/tutorials/openMP
5.4 消息传递模型
消息传递模型有以下三个特征:
1) 计算时任务集可以用他们自己的内存。多任务可以在相同的物理处理器上,同时可以访问任意数量的处理器。
2) 任务之间通过接收和发送消息来进行数据通信。
3) 数据传输通常需要每个处理器协调操作来完成。例如,发送操作有一个接受操作来配合。

Ø 实现
从编程的角度上来看,消息传递的实现通常由源代码中的子程序库构成。程序员负责决定所有的并行机制。
1980年以来出现了大量的消息传递机制的库函数。这些实现本质上是不同的,这就加大了程序员开发可移植的应用程序的难度。
1992年,建立了MPI讨论组,他们的首要目标就是建立消息传递实现的标准接口。
消息传递接口(MPI)的第一部分于1994年完成,第二部分完成于1996年。两部分MPI规范都可以在这里下载http://www-unix.mcs.anl.gov/mpi/。
MPI现在已经成为了工业界消息传递的标准了,并且代替了市面上几乎所有的其他的实现方法。大多数比较流行的并行计算机都至少实现MPI的一个标准,有些还完全满足标准2。
对于共享内存体系结构,MPI的实现通常不使用网络来进行任务间的通信。替代的办法是利用共享内存来进行通信,这样可以提高性能。
Ø 更多信息:
MPI的教程computing.llnl.gov/tutorials/mpi;
l 数据并行模型有以下特性:
并行工作主要是操纵数据集。数据集一般都是像数组一样典型的通用的数据结构。
任务集都使用相同的数据结构,但是,每个任务都有自己的数据。
每个任务的工作都是相同的,例如,给每个数组元素加4。
l 在共享内存体系结构上,所有的任务都是在全局存储空间中访问数据。在分布式存储体系结构上数据都是从任务的本地存储空间中分离出来的。

实现
l 使用数据并行模型编程通常都是用构造并行的数据来写程序。构造方法是调用并行数据的子函数库,然后数据并行编译器就可以识别构造时用到的编译器指令。
l Fortran90和95:ISO/ANSI标准扩展于Fortran77:
包含Fortran77中的所有东西;加入新的代码格式;添加新的特性集;增加程序结构和命令;增加函数、参数等变量;添加数组处理;增加新的递归函数和内部函数;和很多其他的新特性。大多数通用的并行平台都可以使用。
l 编译器指令:可以让程序员指定数据的排列和分布。针对大多数的通用并行平台都有Fortran的实现。
l 分布式内存模型的实现是用编译器将程序转换成标准的代码,这些代码通过调用MPI库函数来将数据分配给所有的进程。所有的消息传递对于程序员来说是不可见的。
5.6 其他模型
上面提到的并行编程模型都是已经存在,而且会随着计算机软硬件的发展继续进化。除了这些之外这里还有三个更为通用的模型。
Ø 混合型:
这个模型中,是由两个或多个模型组合在一起实现的。
当前通用的混合模型的例子就是:由消息传递模型(MPI)和线程模型(POSIX)或者共享内存模型(OpenMP)组成而成。
混合模型中其他比较通用的模型是:将数据并行和消息传递组成起来。正如我们上面在数据并行模型部分提到的那样,在分布式体系结构上实现数据并行模型实际上是用消息传递的方法来为任务间传递数据的,对程序员是透明的。
Ø 单程序多数据型(SPMD):
SPMD实际上是一个高层次的编程模型,是在前面提到的并行编程模型基础之上构建的。
一段程序可以被所有的任务同时的执行。
任务可以同时执行同一个程序中的相同或不同指令。
SPMD程序通常都包含必要的逻辑,使得任务可以有条件的或者分叉的执行那些可以被执行的程序。所以任务没有必要去执行整个程序,很可能只执行一小块程序就可以了。
所有的任务可能使用不同的数据。

Ø 多程序多数据型(MPMD):
与SPMD类似,MPMD也是高层次编程模型,建立在上面提到的并行编程模型之上。
MPMD应用程序多个执行程序。当程序并行执行时,每个任务可以执行相同或不同的程序作为自己的工作。所有的程序可能使用不同的数据。

6 设计并行程序
6.1 自动化 vs. 手工并行化
设计和开发并行程序是典型的人为设计的过程。程序员负责识别并行性和实现并行机制。
通常,手工开发并行代码是一件费时、复杂、容易出错和迭代的过程。
这些年以来,开发出多种工具帮助程序员吧串行的程序转换成并行的程序。最通用的工具类型是并行化编译器或预编译器,它们可以自动把串行化程序并行化。
并行化编译器通常有以下两种工作方式:
1:全自动化
A)编译器分析源代码并识别代码中的并行性。
B) 分析包括识别并行约束,计算使用并行机制所需要的代价,判断是不是真的提高了性能。
C) 循环程序(do,for)是主要的自动并行化对象。
2:程序员直接指定并行化
A) 使用编译器指令或者编译器标记,程序员清楚的告诉编译器如何来并行化代码。
B) 也可能在程序中的一部分使用自动并行化。
如果你现在手中有串行的代码需要并行化,而且时间和预算有限的情况下自动并行化可能是更好的选择。但是在实施自动并行化之前这里有些很重要的警告应该事先告诉你。
A) 可能产生错误的结果
B) 性能可能反而下降
C) 人为编程的并行性灵活性更好
D) 只能用于代码的子程序(主要是循环)
E) 分析可能指出程序有依赖或者代码过于复杂而不能并行化。
本章剩余的部分主要讲解人为开发并行代码。
6.2 问题的理解和程序
毫无疑问,开发并行软件的第一步就是理解要并行处理的问题。如果写好了串行化代码,也有必要理解写好的这份代码。
在开始花时间尝试开发问题的并行解决方案之前,首先应该判断当前的问题是否真的可以被并行。
可并行化例子:为几千个独立的模块构造方法计算潜在所需开销,完成后找到花费最少的构造方法。这个例子可以被并行处理。每个模块的构造方法是彼此独立的。最小花费的计算也是可并行的问题。
不可并行化的例子:计算费伯那其Fibonacci数列(1,1,2,35,8,13,21……)F(K+2)=F(K+1)+F(K).这个问题不可以并行化,以为费伯那其数列的计算中每一项都依赖与其他项,而不是独立的。K+2这个计算用到了K和K+1的结果。三个子句不可以独立的计算,因此不可以并行。
识别程序中的关键点:
A) 了解程序中哪里做了大部分工作。大多数的科学和技术程序通常在某些地方完成了大部分的任务。
B) 性能分析工具在这里很有用。
C) 关注程序中关键点的并行,忽视那些只使用很少CPU利用率的部分程序。
识别程序中的瓶颈:
A) 是否存在特别慢或者导致可并行的工作停止或延误的程序段?例如:I/O经常是系统瓶颈。
B) 有可能通过重构或者使用不同的算法可以减少或消除程序中的瓶颈。
识别程序的限制因素。常见的限制是数据依赖,像Fibonacci数列中的那样。
研究其他可能的算法,这可能是用来设计并行应用程序最重要的方法。
6.3 问题分解
设计并行程序的第一步是将问题分解成离散的可以被分配到多任务中的工作块。这就是任务分解。
分解并行任务中的可计算工作的两个基本方式是:作用域分解和功能分解。
1)作用域分解:
在这个方法中,与问题相关的数据将会被分解。每个并行的任务只能使用部分数据。
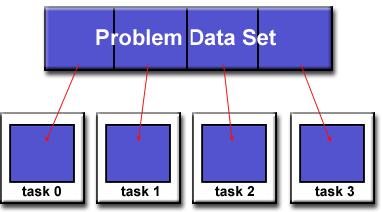
有不同的方法可以分解数据:

2)功能分解:
在这种方式中,主要关注要被完成的计算而不是操作数据的计算。问题是根据当前一定要完成的任务划分的。每个任务完成全部工作的一部分。

功能分解将问题很好的分解到不同的任务中去,例如:
A)生态系统模型
每个程序都要计算给定群体的总数目,每个群体的增长依赖它的邻居。随着时间的流逝,每个进程计算它自己的状态,然后和邻居交换总数信息。所有的进程在下个时间节点再重新计算自己的状态。

B)信号处理
音频信号数据集是通过四个不同的可计算滤波器传递的。每个滤波器都有自己独立的进程。第一部分数据一定是先通过第一个滤波器传输。完成后,第二部分数据再通过第一个滤波器。第四部分数据通过了第一个滤波器后四个任务都开始运行。

C)气候模型
模型中的每个组件都可以当作一个独立的任务。箭头代表计算过程中组件间的数据交换方向:大气层模块生成风速数据发送给大洋模块,大洋模块生产海洋水表温度发送给大气层模块使用,如此往复。

通常联合使用以上两种问题分解方法。
6.4 通信
Ø 谁需要通信?
任务之间是否需要通信取决于您要解决的问题。
l 不需要通信的情况:
1)实际上有些类型的问题可以将问题分解,并行执行时并不需要任务间共享数据。例如:假设一个图像处理的程序在处理的图像只有黑色,黑色的像素都反转成黑色。图像数据很容易就可以被分解到多个任务上,这些任务显然可以独立执行完成自己的那部分工作。
2)这种类型的问题称为“使人尴尬的并行计算”,因为他们不是直截了当的并行程序。任务之间还是需要少许的通信。
l 需要通信的情况:
大多数并行应用程序没有这么简单,任务间需要彼此共享数据。例如,3D的热扩散问题,其中一个任务的温度计算要知道他周围的任务的计算数据。周围数据改变将直接影响此任务的数据。
Ø 值得考虑的因素:
设计任务间通信的程序时需要考虑很多十分重要的因素。
1. 通信开销:
任务间通信肯定是需要开销的。
原本用于计算的机器时钟周期和计算资源将被用于给数据打包并传输。
频繁的任务间通信需要同步方法,同步使任务把时间花费在等待上而没有工作。
通信传输的竞争可能会占用大量的带宽,甚至影响性能。
2. 带宽和延迟
延迟是从A点到B点发送数据需要花费的时间。通常是微秒级。
带宽是每个时间单元需要通信的数据量。通常是Mb/s或者Gb/s级别。
如果发送很多小消息的话,延迟可能会占用绝大多数的通信资源。将小消息打包成大消息一次性传递通常更加高效,也会增加有效通信带宽。
3. 通信的可见性
在消息传递模型中,通信过程是非常清楚的,对程序员是可见的、可以控制的。
在数据并行模型中,程序员不能确切的知道任务间的通信是如何实现的,特别是在分布式内存体系结构中。
4. 同步通信和异步通信
同步通信需要某种类型的共享数据任务间的“握手”协议。程序员可以将此过程很清楚的在程序中完成。
同步通信通常是指一项任务完成后等待与他要通信的任务,后者完成计算后才可以进行通信。
异步通信允许程序之间可以独立的传输数据。例如:1号任务可以在准备好后发送消息给2号任务然后立即做其他的工作,2号任务接收数据到的时间不是特别重要。
异步通信通常是指不阻塞的通信,因为任务可以一边通信一边做其他任务。
异步通信最适合用于交叉计算问题。
5. 通信的范围
在设计并行代码阶段,知道哪个任务需要彼此通信是至关重要的。下面两个描述的范围可以设计成同步的也可以设计成异步的。
点到点:这里包括两个任务,一个作为数据的制造者/发送者,另一个作为接收者/读数据者。
聚集:这里包括多个任务的数据共享问题,每个任务都是组中的成员。

6. 通信效率
程序员通常会根据影响通信性能的因素进行选择。这里由于篇幅限制只能提到一部分。
应该使用哪种那个给定的模型?用消息传递模型为例,只有MPI实现在给定的硬件平台上可能比别的实现方法要快。
应该使用哪种通信操作?正如前面提到的,异步通信操作能够提升程序的整体性能。
网络媒体:有些平台可能会提供多个网络来进行通信,那么问题是那个网络是最好的呢?
7. 开销和复杂性

最后,请注意这里提到的只是程序员要考虑的问题的一部分。
6.5 同步
l 障碍
·通常障碍会影响所有的任务
·每个任务完成自己的任务之后到达障碍区等待。
·当所有的任务都到达障碍点后所有的任务进行同步。
·执行到这里有不同的情况,通常需要做一串工作。其他的情况自动释放任务继续完成别的工作。
l 锁和信号量
·可能包括任意数量的任务。
·这种方法可以串行访问全局数据和代码段。同时只可以有一个任务使用锁变量或者信号量。
·第一个访问临界资源的任务设置锁,然后就可以安全的访问里面被保护的数据或代码。
·其他的任务试图操作临界区,但是发现已经上锁只能等到锁的拥有者释放锁才可以操作。
·阻塞和非阻塞两种方式
l 同步通信操作
·只涉及到执行通信操作的任务。
·当一个任务完成通信操作,需要某种调度方法来调度其他参与通信的任务。例如:当一个任务完成发送数据的操作他必须等待接受任务的确认信息,才可以说明发送成功。
·其余的在前面通信部分讨论过。
6.6 数据依赖
Ø 定义:
·当程序的执行顺序影响程序的执行结果时,我们说程序间存在依赖。
·不同任务同时使用相同地址的存储空间中的数据那么就存在数据依赖。
·依赖问题在并行编程中是极其重要的,也是限制并行机制的主要因素。
Ø 例如:
·循环中的数据依赖:
|
DO 500 J = MYSTART,MYEND A(J) = A(J-1) * 2.0 500 CONTINUE |
A(J-1)的值一定要在计算A(J)值之前计算,因此A(J)的值依赖A(J-1)的值。不能并行。
如果任务2计算A(J),任务1计算A(J-1),想要得到正确的A(J)的值必须要:
1)分布式内存体系结构中,任务2一定要在任务1计算完A(J-1)的值后才可以计算。
2)共享内存体系结构中,任务2一定要读取任务1更新A(J-1)的值之后才可以计算。
·循环独立数据依赖
|
task 1 task 2 ------ ------ X = 2 X = 4 . . . . Y = X**2 Y = X**3 |
像前面的例子一样,这个例子也是不能并行化的,Y值依赖于:
1)分布式内存体系结构——X的值在任务之间是否通信或者何时通信都存在一定的数据依赖。
2)共享内存体系结构——哪个任务最后将X保存。
·当设计并行程序的时候,识别所有的数据依赖是很重要的。并行化的主要目标可能是循环,所以识别循环中的依赖问题更为重要。
Ø 如何处理数据依赖
·分布式内存体系结构——在同步点上需要通信数据。
·共享内存体系结构——在任务之间同步读写操作。
6.7 负载平衡
·负载平衡指的是使所有分布式的工作高效运行、是CPU可以保持较高的利用率较少的等待。也可以看作是将任务空闲时间最小化的方法。
·对于提升系统性能来说,负载平衡是十分重要的。例如,所有的任务都要在障碍处同步,最慢的任务将决定全局的时间开销。

Ø 如何获得负载平衡:
·平分每个任务的工作量
1)对于数组或者矩阵操作,每个任务分配相似的工作量,任务间平衡的分配数据。
2)对于循环迭代每个迭代的工作量是相似的,给任务平均的分配迭代次数。
3)在异质的机器上性能特点各不相同,一定要用某种性能分析工具来测试负载平衡的性能,根据结果调节工作。
·动态工作分配
1)即使数据平均的分配到各个任务上去,还是会存在一定的负载平衡问题。
稀疏数组——有些任务需要些非零数据而其他任务的数据基本上都是零。
自适应网格——有些任务需要规划自己的网络,而其他的任务不需要。
N-体模拟——有一些小块工作可能需要从原任务分离整合到其他任务中;这些占用小工作的进程比其他的进程需要更多的工作。
2)当进程完成任务的数量很难确定或者不可以预测的时候,使用调度线程池模型可能会有所帮助。当任务完成自己的工作后,它排队去申请新的工作。
3)我们有必要设计算法去检查和处理在程序中动态的发生的负载不平衡现象。
6.8 粒度
Ø 计算通信比(译者注释:一个任务用在计算上的时间除以任务间同步通信所用的时间,比值大说明时间利用率高)
·在并行计算中,粒度是用来描述计算通信比的十分量化的方法。
Ø 细粒度的并行
·通信处理时只能完成很少量的可计算工作。
·低的计算通信率
·促进负载平衡
·意味着高通信开销,降低了性能提升的可能性。
·如果粒度太小很可能任务间的通信和同步所需要的花费时间比用在计算上的还长。
Ø 粗粒度并行
·在每次通信同步之间完成相当多的计算任务。
·高计算通信率
·意味着更加可能进行性能提升。
·更难进行有效的负载平衡调度
Ø 哪个更好?
·最高效的粒度是由算法和当前硬件平台决定的。
·通常情况下,通信和同步的开销很大程度上取决于执行速度,这样使用粗粒度较好。
·细粒度并行机制可以减少负载不平衡所带来的开销。

6.9 I/O
Ø 坏处
·I/O操作通常认为是限制并行化的因素。
·适用于所有平台的并行的I/O系统目前为止尚不成熟。
·在所有任务都看到相同文件系统的环境中,写操作可能导致文件写覆盖。
·文件服务器同时处理多线程读请求的能力将会影响写操作。
·I/O一定是通过网络(NFS或者非本地文件系统)构建的,可能导致服务器性能瓶颈甚至文件服务器崩溃。
Ø 优点
·并行文件系统有以下几种:
1)GPFS:AIX(IBM)的通用的并行文件系统。
2)Lustre:Linux机群(SUN微系统)。
3)PVFS/PVFS2:Linux机群的虚拟并行文件系统(Clemson/Argonne/Ohio State/等)。
4)PanFS: Linux机群的Panasas ActiveScale文件系统。
5)HP SFS:HP存储工作可剪裁的文件系统。Lustre是HP的基于并行文件系统(Linux全局文件系统)的产品。
·并行I/O编程MPI接口规范从1996年开始发布了第二个版本MPI-2。现在也可以拿到生产商免费实现。
·选项:
1)如果你要访问并行文件系统,你要好好研究一下。
2)规则1:尽量减少全局的I/O。
3)限定工作中的某些任务的I/O操作,然后为并行任务分配通信数据。例如:任务1读取输入文件,然后和其他任务通信所需要的数据。同样,任务1从其他任务读取所需的数据后再完成写操作。
5)为每个任务的输入输出文件创建唯一的文件名。
6.10 并行程序设计的限制和消耗
Ø 阿姆达尔(Amdahl's)法则
·阿姆达尔法则指出加速比是由并行化代码部分决定的。
|
1 speedup = -------- 1 - P |
·如果没有代码被并行化,P=0那么加速比=1,没有加速。
·如果50%的代码并行化了,最大的加速比=2,意味着代码比原来快了一倍


·引入处理器的数目完成并行操作的部分。关系描述模型如下:
|
1 speedup = ------------ P + S --- N |
P是并行部分比例,N是处理器数目,S的串行比
·显然并行加速比是有极限的:例如:
|
speedup -------------------------------- N P = .50 P = .90 P = .99 ----- ------- ------- ------- 10 1.82 5.26 9.17 100 1.98 9.17 50.25 1000 1.99 9.91 90.99 10000 1.99 9.91 99.02 100000 1.99 9.99 99.90 |
·但是,确实有些问题可以通过增加问题的规模来提高性能。例如:
1)2D的网格计算 85秒 85%
2)串行部分 15秒 15%
我们通过加倍网络的规格来增加问题的规模并将时间步长减半。结果应该是原来四倍的网格节点数目,两倍数量的时间步长。计时结果如下:
1)2D网格计算 680秒 97.84%
2)串行部分 15秒 2.16%
·这个问题通过增加并行时间比例比固定比例并行时间的问题可扩展性更强。(译者注:将并行计算和串行计算的百分数代入前面公式可知加速比有所提高,证明增加问题规模提高并行比例确实可以提升性能。)
Ø 复杂性
·通常,并行应用程序要比相对应的串行应用程序复杂得多,可能是在一个数量级上。不仅仅要考虑多个指令流在同时执行,而且它们中间还有多个数据流。
·在软件开发周期的每一部分中,程序员因程序复杂而花费的时间是可以测量的。
1)设计
2)编码
3)调试
4)较优
5)维护
·开发并行应用程序的时候特别是与人合作开发的时候,遵循标准的软件开发实践准则是必需的。
Ø 可移植性
·由于MPI、POSIX、HPF、OpenMP等API的标准化,使得并行程序中的可移植性问题比前些年大大改善。
·所有串行程序的可移植性问题都归因于将其并行化。例如,如果你使用生产商的加强的Fortran、C和C++时,可移植性将存在问题。
·尽管上诉几个API存在标准,但是很多实现的细节却是不同的,有时需要修改代码才能实现可移植性。
·操作系统在代码可移植性问题上扮演着重要的角色。
·硬件体系结构有很大差别也会影响可移植性。
Ø 所需资源
·并行的首要目标是减少执行过程中的阻塞时间,但是为了达到这个目的,需要更多的CPU时间。例如,并行代码在八个处理器的内核上运行1个小时实际上用了8个小时的CPU时间。
·并行程序比串行程序所需的内存数量要大得多,这是由于我们需要备份数据,为与并行相关的负载提供库函数和子系统。
·小段的并行程序实际上在性能上要比相似的串行程序差。设置并行环境、任务创建、任务间的通信和终止等所需要的开销占用了总开销的绝大部分。
Ø 可扩展性
·并行程序性能的可扩展性的能力取决于一些相关的因素。只是简单的增加更多的机器很难提高整体性能。
·算法也是可扩展性固有的限制因素。从某种意义上来说,增加更多的资源可能会导致性能下降。很多并行的解决方案在某种程度上显示出这个问题。
·硬件因素在可扩展性方面扮演着重要的角色。例如:
1)SMP机器上的内存和CPU总线带宽
2)通信网络带宽
3)在特定的机器或机群中可以获得的内存大小
4)处理器速度
·并行支持库和子系统软件限制与应用程序的可扩展性。
6.11 性能分析与调整
·相比串行程序来说,并行程序的调试、监视、分析并行程序的执行更加困难。
·现在可以获得很多监视程序执行和程序分析的工具。
·有些非常有用,有些还跨平台。
·起点:
1)LC的“软件和计算支持工具”网页在computing.llnl.gov/code/content/software_tools.php
2)关于“高性能工具和技术”的白皮书有点过时但是很可能十分有用,它提到了很多工具,还提到很多性能相关可给代码开发者应用的话题。可以在这里找到
3)性能分析工具教程Performance Analysis Tools Tutorial
·还有很多工作没有完成,特别是可扩展性领域。
7 并行示例
7.1 数组程序
·这个例子是计算两维数组元素,这里计算每个数组元素彼此互不影响。
·串行程序顺序的每次计算一个元素。
·串行代码可能是这样的形式:
|
do j = 1,n do i = 1,n a(i,j) = fcn(i,j) end do end do |
·元素的计算彼此独立,这就是“令人尴尬的”并行状态。
·这个问题可以密集的计算。

Ø 并行解决方案1
·独立的数组元素计算确保了不需要任务间的数据通信。
·用其他的标准来确定分配方案,例如:子数组划分。最大缓存或内存利用率划分。
·由于通过子数组划分方法是比较满意的,这样就要根据编程语言选择分配方案。
·将数组分配完后,每个任务都执行只和自己的数据通信执行自己的代码。例如:用Fortran块分配:
|
do j = mystart, myend do i = 1,n a(i,j) = fcn(i,j) end do end do |

·注意:只有外层循环变量与串行的方案不同。
Ø 可能的解决方案
·用SPMD模型实现
·主线程初始化数组、发送信息给工作线程并接收计算返回结果。
·工作线程接受主线程分配任务的信息,完成自己要做的计算工作将结果发给主线程。
·使用Fortran存储模式,完成数组的块分配。
·伪代码如下:红色的部分与并行不同。
|
find out if I am MASTER or WORKER if I am MASTER initialize the array send each WORKER info on part of array it owns send each WORKER its portion of initial array receive from each WORKER results else if I am WORKER receive from MASTER info on part of array I own receive from MASTER my portion of initial array # calculate my portion of array do j = my first column,my last column do i = 1,n a(i,j) = fcn(i,j) end do end do send MASTER results endif |
Example: MPI Program in Fortran
Ø 并行解决方案2:线程池
·这里使用两种线程:
1)主线程:
为工作线程维护线程池
在必要的时候分配任务给工作线程
收集工作线程的计算返回的结果集。
2)工作线程:
从主线程处获取任务
完成计算
将结果发送回主线程
·工作线程在运行之前不知道要处理那部分数组,也不知道他们要计算多少任务。
·在运行时,自动的负载平衡:处理速度快的任务将会做更多的工作。
·伪代码如下:红色高亮的与并行中不同
|
find out if I am MASTER or WORKER if I am MASTER do until no more jobs send to WORKER next job receive results from WORKER end do tell WORKER no more jobs else if I am WORKER do until no more jobs receive from MASTER next job calculate array element: a(i,j) = fcn(i,j) send results to MASTER end do endif |
Ø 讨论
·在上面线程池例子中,每个任务的工作室计算独立的数组元素。这里的计算通信比是细粒度的。
·细粒度解决方案可以减少任务空闲时间但带来了更多的通信开销。
·更加理想的解决方案可能是给每个任务分配更多的工作来完成。恰到好处的任务量由问题决定。
7.2 PI 的计算
·有很多种PI值计算方法。考虑下面的近似PI值方法。
1)在正方形中话一个圆;
2)在正方形内随机生成点;
3)确定即在正方形内又在圆形内点的数量;
4)在圆形内点的数量除以在正方形内点的数量,结果付给r;
5)PI约等于4r;
6)注意:生成更多的点近似度会更高;

·此过程串行伪码:
|
npoints = 10000 circle_count = 0 do j = 1,npoints generate 2 random numbers between 0 and 1 xcoordinate = random1 ycoordinate = random2 if (xcoordinate, ycoordinate) inside circle then circle_count = circle_count + 1 end do PI = 4.0*circle_count/npoints |
·注意:在执行这个循环中最花费时间的地方是执行循环。
·导致“令人尴尬的并行”的解决方案
高密度计算
最小化通信
最少化I/O操作
Ø 并行解决方案:
·并行策略:把循环分块给任务集执行。
·近似的PI
1)每个任务执行一部分循环多次。
2)每个任务不需要从其他的任务获取任何信息就可以完成自己工作。(没有数据依赖)
3)使用SPMD模型。一个任务是主线程负责收集结果。

·伪代码如下:红色区是为并行而加
|
npoints = 10000 circle_count = 0 p = number of tasks num = npoints/p find out if I am MASTER or WORKER do j = 1,num generate 2 random numbers between 0 and 1 xcoordinate = random1 ycoordinate = random2 if (xcoordinate, ycoordinate) inside circle then circle_count = circle_count + 1 end do if I am MASTER receive from WORKERS their circle_counts compute PI (use MASTER and WORKER calculations) else if I am WORKER send to MASTER circle_count endif |
Example: MPI Program in Fortran
7.3 简单的加热等式
·并行计算中的大多数问题都是需要进程间通信的。一些常见的问题还需要和邻居任务通信。
·加热等式描述的是温度随着时间而改变,初始化给出温度分布和边界条件值。
·我们用有限差分体系来解决在正方形区域上加热等式量化的问题。
·边界初始化温度是零,中心温度最高。
·外边界温度一直是零
·为了详细阐述这个问题我们用了一个按时间分步的算法。两维数组元素代表正方形中点的温度。
·每一个元素的计算都依赖与邻居元素的值。


·串行代码如下
|
do iy = 2, ny – 1 do ix = 2, nx - 1 u2(ix, iy) = u1(ix, iy) + cx * (u1(ix+1,iy) + u1(ix-1,iy) - 2.*u1(ix,iy)) + cy * (u1(ix,iy+1) + u1(ix,iy-1) - 2.*u1(ix,iy)) end do end do |

Ø 并行解决方案1
·用SPMD模型实施
·整个数组分组成子数组分配给所有的任务。每个任务拥有整个数组的一部分。
·裁定数据依赖
迭代元素属于本身任务而独立于其他任务。
边界元素依赖邻居任务数据,必须通信。
·主线程发送消息给工作线程,检查分块位置和结果集。
·工作线程执行计算,和必要的邻居通信。
·伪代码如下:红色是并行实现所需:
|
find out if I am MASTER or WORKER if I am MASTER initialize array send each WORKER starting info and subarray do until all WORKERS converge gather from all WORKERS convergence data broadcast to all WORKERS convergence signal end do receive results from each WORKER else if I am WORKER receive from MASTER starting info and subarray do until solution converged update time send neighbors my border info receive from neighbors their border info update my portion of solution array determine if my solution has converged send MASTER convergence data receive from MASTER convergence signal end do send MASTER results endif |
Ø 并行解决方案2:重叠的通信和计算
·在前面的解决方案中,我们假定工作线程使用的是阻塞通信。阻塞通信是等待通信完成再执行下一条程序指令。
·在前面的解决方案中,邻居任务通信边界数据,每个进程更新自己那部分数组元素。
·使用非阻塞式通信通常会减少计算时间。非阻塞通信中通信的同时可以继续工作。
·每个任务更新自己的内部数组,同时边界数据在通信,通信完成再更新边界值。
·伪代码:如下
|
find out if I am MASTER or WORKER if I am MASTER initialize array send each WORKER starting info and subarray do until all WORKERS converge gather from all WORKERS convergence data broadcast to all WORKERS convergence signal end do receive results from each WORKER else if I am WORKER receive from MASTER starting info and subarray do until solution converged update time non-blocking send neighbors my border info non-blocking receive neighbors border info update interior of my portion of solution array wait for non-blocking communication complete update border of my portion of solution array determine if my solution has converged send MASTER convergence data receive from MASTER convergence signal end do send MASTER results endif |
7.4 一维的波等式
·在这个例子中,振幅沿着一个统一的震动的轨迹每隔指定的时间计算一次。
·计算包括:
1)在Y轴上的振幅
2)沿着X轴的位置索引i
3)沿着轨迹上的节点
4)在离散的时间点更新振幅

·这里要解的等式就是一维波等式。
A(i,t+1) = (2.0 * A(i,t)) - A(i,t-1) + (c * (A(i-1,t) - (2.0 * A(i,t)) + A(i+1,t)))
这里C是常量
·注意:这里的振幅依赖前面的时间段(t,t-1)和邻居点(i-1 , i+1)。数据依赖意味着并行解决方案要引入通信。
Ø 一维波并行解决方案
·用SPMD模型实现
·整个振幅数组被分割成子数组分配给每个任务。每个任务拥有整个数组的一部分。
·负载平衡:所有点的计算需要相同的工作量,所以点数应该平均分配。
·块分解将按照块大小分解任务,使得任务数和线程个数相等。让每个任务拥有大体上连续的数据点。
·只有数据边界需要通信。块大小越大所需的通信越少。

Ø 伪代码解决方案如下:
|
find out number of tasks and task identities #Identify left and right neighbors left_neighbor = mytaskid - 1 right_neighbor = mytaskid +1 if mytaskid = first then left_neigbor = last if mytaskid = last then right_neighbor = first find out if I am MASTER or WORKER if I am MASTER initialize array send each WORKER starting info and subarray else if I am WORKER receive starting info and subarray from MASTER endif #Update values for each point along string #In this example the master participates in calculations do t = 1, nsteps send left endpoint to left neighbor receive left endpoint from right neighbor send right endpoint to right neighbor receive right endpoint from left neighbor #Update points along line do i = 1, npoints newval(i) = (2.0 * values(i)) - oldval(i) + (sqtau * (values(i-1) - (2.0 * values(i)) + values(i+1))) end do end do #Collect results and write to file if I am MASTER receive results from each WORKER write results to file else if I am WORKER send results to MASTER endif |
8 参考和更多信息
作者: Blaise Barney, 利弗莫尔计算中心。
译者:卢洋,同济大学
由于译者水平有限,翻译中难免出现错误或遗漏欢迎大家指出。联系方式luyang.leon@gmail.com

