
Qt与MSVC中文乱码问题的解决方案
参考网上方法,先把文件编码改为待bom的utf-8,然后在cpp文件里加入
#ifdef Q_OS_WIN
#pragma execution_character_set("utf-8") //解决 VS编译器下中文乱码
#endif
具体见文末详情。
在这种时候,如果用到 QString和char*互转,可用如下方法:
1 QString str = "324rwer中文"; 2 3 char* pCh = new char[50]; 4 memset(pCh, 0 , 50); 5 //QString转char* 6 std::string stdStr = str.toStdString(); 7 memcpy(pCh, stdStr.c_str(), stdStr.length()); 8 9 //char* 转 QString 10 QString strCh(pCh); 11 QString strch1 = QString::fromUtf8(pCh); 12 qDebug() << "pCh:" << pCh; 13 qDebug() << "str:" << str; 14 qDebug() << "strCh:" << strCh; 15 qDebug() << "strch1:" << strch1;
详情如下:
转自:https://blog.csdn.net/liuweilhy/article/details/82321105
在学习Qt编程的过程中,大多数人都遇到过中文乱码的问题。总结起来有三类:
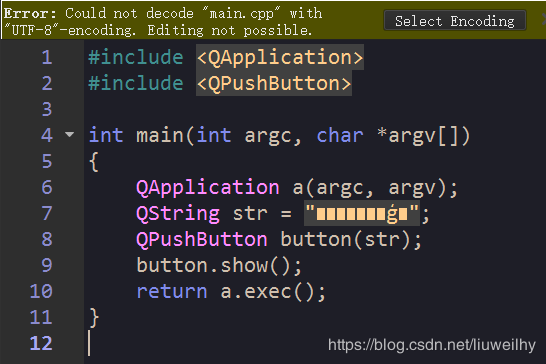
1. Qt Creator中显示的汉字变为乱码,编辑器上方有“Could not decode "..." with "UTF-8"-encoding. Editing not possible.”的错误提示。此时,出现乱码的文档是不可编辑的。如下图所示,“你好中文!”这5个中文字符变成了乱码:
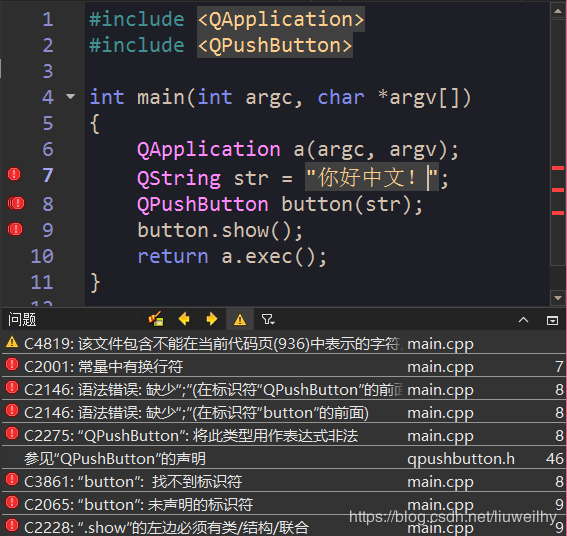
2. Qt Creator中显示的汉字正常,但编译的时候会出现“常量中有换行符”等一系列错误报警。其实,这也是文字编码的问题。如下图所示:
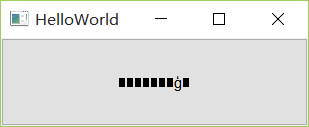
3. 编译时未报错,但生成的程序中文乱码。如下图所示:
其中,第3条是网上提问的最多的,几乎是所有使用MSVC的初学者都会碰到的问题。很多回答是针对Qt4版本的,Qt5中不可用。
二、为什么会出现这些问题?
在解决问题之前,字符编码知识是必需的。你要知道ASCII、GB2312、GBK、Unicode、UTF-8、UTF-16、BOM是怎么回事。此外,你还要明白源码字符集、执行字符集是什么。详细内容可以在网上搜索一下,俯拾即是。
1. Qt Creator的编辑器默认使用UTF-8(代码页65001)编码来读取文本文件。而Visual Studio保存文件时默认采用的是本地编码,对于简体中文的Windows操作系统,这个编码就是GB2312(代码页936)。如果使用Qt Creator读取由Visual Studio创建的文件,那么编辑器就会以UTF-8编码格式读取GB2312编码格式的文件,出现中文乱码,因为这两套编码系统对汉字编码是不同的。至于英文部分不会乱码,是因为UTF-8和GB2312在单字节字符部分是兼容的。
2. MSVC在编译时,会根据源代码文件有无BOM来定义源码字符集。如果有BOM,则按BOM解释识别编码;如果没有,则使用本地字符集,对于简体中文的Windows操作系统就是GB2312。那么,当MSVC遇到一个没有BOM的UTF-8编码的文件时,它通常会把文件看作GB2312的来处理。如果文件全是英文没有问题,但如果包含中文,编译器就会出现误读。这种情况下,Qt Creator编辑器是正常的。但对于MSVC编译器,原代码会被它认识成下图这个样子:
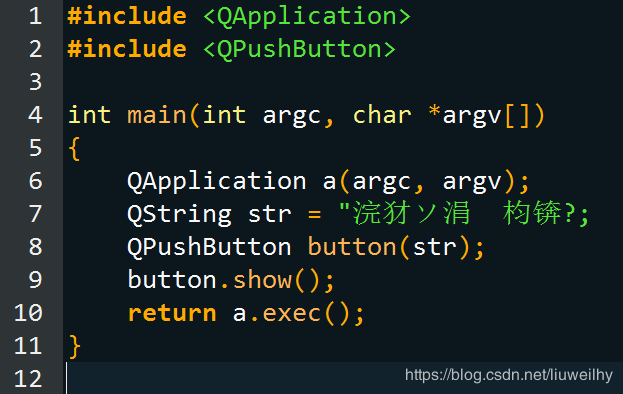
这是我用EverEdit指定本地编码重读后的结果,可以看到汉字出错,末端的引号也没了。
在UTF-8中,一个中文字符(汉字或标点符号)占用3个字节,“你好中文!”这5个中文字符共占用15个字节;而在GB2312中,一个中文字符(汉字或标点符号)占用2个字节,这时,MSVC把UTF-8编码的15个字节加上后面1个字节的英文引号合成16个字节当作8个中文字符处理。之后,MSVC在这一行里直到末尾换行符出现都没有找到下一个引号,它以为你把字符串在这里敲回车换行了,于是报警称“常量中有换行符”,并引出一系列的错误。
不过,当以无BOM的UTF-8编码的字符串正好凑够偶数个字节时(比如偶数个汉字,或奇数个汉字加奇数个英文字母),编译器通常不会报警,因为它以为用GB2312编码读出的是正确的。
3. 不管源文件是何种编码,只要MSVC能够正确识别,就可以通过编译。但MSVC的执行字符集默认是本地字符集。对我们来说,它生成的可执行文件中的文字是GB2312编码的。而生成的Qt程序以UTF-8编码来识别GB2312编码的文字,对于“你好中文!”这几个字符,采用GB2312编码后再以UFT-8编码来读取,就会变成如下的乱码:

当以无BOM的UTF-8编码的字符串正好凑够偶数个字节时(比如偶数个汉字,或奇数个汉字加奇数个英文字母),反而不会出现乱码。那是因为,编译器用GB2312编码读出的乱码本身就是UTF-8编码的,现在又用UTF-8解读,自然就正确了。这纯粹是歪打正着。
三、怎么解决这些问题?
首先,你要确定采用哪种源码字符集。你有两个选择:
1. 采用本地编码字符集(不推荐,跨平台时会比较麻烦,但在Visual Studio环境下配合Add-in工具编程比较方便);
2. 采用UTF-8编码字符集(推荐,适合跨平台)。
a)、 “采用本地编码字符集”方案,解决方法如下:
首先,要把项目中所有的头文件和源文件全都转换成GB2312编码保存。
1. 第1个问题:在Qt Creator中打开项目,点击左侧工具栏“项目”,在“编辑器”选项卡中把“默认编码”改成“GB2312”。如下图所示:
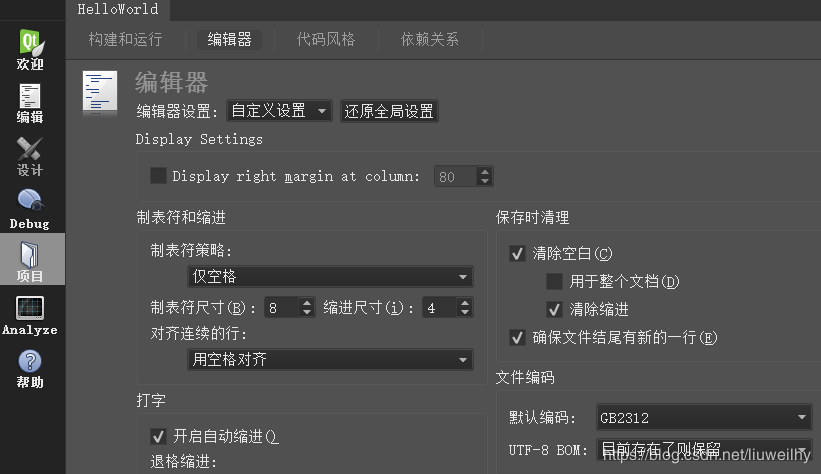
话说回来,既然选择本地字符集,大致上是放弃跨平台了。与其用轻量级的Qt Creator,不如用Visual Studio作开发环境更好。
2. 第2个问题:“常量中有换行符”等一系列报警已不存在了。
3. 第3个问题:在字符串常量上加QStringLiteral宏或QString::fromLocal8Bit函数,如:
QString str = "你好中文!";
改为:
QString str = QStringLiteral("你好中文!");
或者:
QString str = QString::fromLocal8Bit("你好中文!");
不过,在这两种形式下,你都无法用tr方法来创建翻译了。
b)、 “采用UTF-8编码字符集”方案,解决方法如下:
首先,要把项目中所有的头文件和源文件全都转换成UTF-8+BOM编码保存。
1. 第1个问题不存在了。
2. 第2个问题也不存在了。
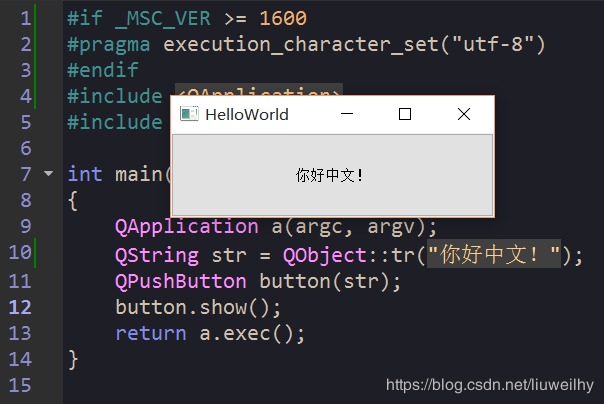
3. 第3个问题,你也可以用上个方案中的方法来解决,但有更好的方法。那就是要用到中文字符的头文件和源文件开头加上MSVC的一个宏:
#if _MSC_VER >= 1600
#pragma execution_character_set("utf-8")
#endif
这个宏告诉MSVC,执行字符集是UTF-8编码的,别瞎整成GB2312的!还有个好处,就是能用tr包中文,方便日后的翻译。最终效果如下:
————————————————
版权声明:本文为CSDN博主「liuweilhy」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/liuweilhy/article/details/82321105

 浙公网安备 33010602011771号
浙公网安备 33010602011771号