
Spring源码分析(二十三)BeanFactory的后处理
摘要: 本文结合《Spring源码深度解析》来分析Spring 5.0.6版本的源代码。若有描述错误之处,欢迎指正。
目录
一、激活注册的 BeanFactoryPostProcessor
1. BeanFactoryPostProcessor 的典型应用:PropertyPlaceholderConfigurer
2. 使用自定义 BeanFactoryPostProcessor
3. 激活BeanFactoryPostProcessor
二、注册BeanPostProcessor
三、初始化消息资源
四、初始化ApplicationEventMulticaster
五、注册监听器
BeanFactory作为Spring中容器功能的基础,用于存放所有已经加载的bean,为了保证程序上的高可扩展性,Spring针对BeanFactory做了大量的扩展,比如我们熟知的PostProcessor等都是在这里实现的。
一、激活注册的 BeanFactoryPostProcessor
正式始介绍之前我们先了解下BeanFactoryPostProcessor的用法。
BeanFactoryPostProcessor 接口跟 BeanPostProcessor 类似,可以对 bean 的定义(配置元数据)进行处理。也就是说,Spring IoC容器允许BeanFactoryPostProcessor在容器实际实例化任何其他的bean之前读取配置元数据,并有可能修改它。如果你愿意,你可以配置多个 BeanFactoryPostProcessor。你还能通过设置 “order” 属性来控制 BeanFactoryPostProcessor 的执行次序(仅当BeanFactoryPostProcessor实现了Ordered接口时你才可以设置此属性,因此在实现 BeanFactoryPostProcessor时,就应当考虑实现 Ordered 接口)。请参考 BeanFactoryPostProcessor 和Ordered接口的JavaDoc以获取更详细的信息。
如果你想改变实际的bean实例(例如从配置元数据创建的对象),那么你最好使用 BeanPostProcessor。同样地,BeanFactoryPostProcessor的作用域范围是容器级的。它只和你所使用的容器有关。如果你在容器中定义一个BeanFactoryPostProcessor,它仅仅对此容器中的 bean进行后置处理。BeanFactoryPostProcessor不会对定义在另一个容器中的bean进行后置处理,即使这两个容器都是在同一层次上。在Spring中存在对于BeanFactoryPostProcessor的典型应用,比如 PropertyPlaceholderConfigurer。
1. BeanFactoryPostProcessor 的典型应用:PropertyPlaceholderConfigurer
有时候,阅读Spring的Bean描述文件时,你也许会遇到类似如下的一些配置:
<bean id = "message" class = "distConfig.HelloMessage"> <property name = "mes"> <value>${bean.message}</value> </property> </bean>
其中竟然出现了变量引用:${bean.message}。这就是Spring的分散配置,可以在另外的配置文件中为bean.message指定值。如在bean.property配置如下定义:
bean.message=Hi, can you find me?
当访问名为message的bean时,mes属性就会被置为字符串“Hi,can you find me?”,但Spring框架是怎么知道存在这样的配置文件呢?这就要靠PropertyPlaceholderConfigurer这个类的bean:
<bean id = "mesHandler" class = "org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"> <property name = "locations"> <list> <value>config/bean.properties</value> </list> </property> </bean>
在这个bean中指定了配置文件为config/bean.preperties。到这里似乎找到问题的答案了,但是其实还有个问题。这个“ mesHandler ”只不过是 Spring 框架管理的一个 bean ,并没有被别的 bean 或者对象引用,Spring 的 beanFactory 是怎么知道要从这个 bean 中获取配置信息的呢?
查看层级结构可以看出 PropertyPlaceholderConfigurer 这个类间接继承了BeanFactoryPostProcessor接口。这是一个很特别的接口,当 Spring 加载任何实现了这个接口的 bean 的配置时,都会在 bean工厂载入所有 bean 的配置之后执行 postProcessBeanFactory方法。在 PropertyPlaceholderConfigurer类中实现了postProcessBeanFactory方法,在方法中先后调用了mergeProperties 、 convertProperties、 processProperties 这 3 个方法,分别得到配置,将得到的配置转换为合适的类型,最后将配置内容告知BeanFactory。
正是通过实现BeanFactoryPostProcessor接口,BeanFactory会在实例化任何 bean 之前获得配置信息,从而能够正确解析 bean 描述文件中的变量引用。
2. 使用自定义 BeanFactoryPostProcessor
我们以实现一个BeanFactoryPostProcessor,去除潜在的“流氓”属性值的功能来展示自定义BeanFactoryPostProcessor的创建及使用,例如 bean 定义中留下 bollocks 这样的字眼。
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id = "bfpp" class="org.cellphone.uc.ObscenityRemovingBeanFactoryPostProcessor"> <property name="obscenities"> <set> <value>bollocks</value> <value>winky</value> <value>bum</value> <value>Microsoft</value> </set> </property> </bean> <bean id="simpleBean" class="org.cellphone.uc.SimpleBean"> <property name="connection" value="bollocks"/> <property name="password" value="imaginecup"/> <property name="username" value="Microsoft"/> </bean> </beans>
public class ObscenityRemovingBeanFactoryPostProcessor implements BeanFactoryPostProcessor { private Set<String> obscenities; public ObscenityRemovingBeanFactoryPostProcessor() { this.obscenities = new HashSet<>(); } @Override public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException { String[] beanNames = beanFactory.getBeanDefinitionNames(); for (String beanName : beanNames) { BeanDefinition bd = beanFactory.getBeanDefinition(beanName); StringValueResolver valueResolver = new StringValueResolver() { @Nullable @Override public String resolveStringValue(String strVal) { if (isObscene(strVal)) return "*****"; return strVal; } }; BeanDefinitionVisitor visitor = new BeanDefinitionVisitor(valueResolver); visitor.visitBeanDefinition(bd); } } public boolean isObscene(Object value) { String potentialObscenity = value.toString().toUpperCase(); return this.obscenities.contains(potentialObscenity); } public void setObscenities(Set<String> obscenities) { this.obscenities.clear(); for (String obscenity : obscenities) { this.obscenities.add(obscenity.toUpperCase()); } } }
执行类:
public class PropertyConfigurerTest { public static void main(String[] args) { ConfigurableListableBeanFactory bf = new XmlBeanFactory(new ClassPathResource("spring/beans-factory.xml")); BeanFactoryPostProcessor bfpp = (BeanFactoryPostProcessor) bf.getBean("bfpp"); bfpp.postProcessBeanFactory(bf); System.out.println(bf.getBean("simpleBean")); } }
输出结果:
SimpleBean{connection=*****, username=*****, password=imaginecup}
通过ObscenityRemovingBeanFactoryPostProcessor,Spring很好地实现了屏蔽掉obscenties定义的不应该展示的属性。
3. 激活BeanFactoryPostProcessor
了解了BeanFactoryPostProcessor的用法后便可以深入研究BeanFactoryPostProcessor的调用过程了。
public static void invokeBeanFactoryPostProcessors( ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) { // Invoke BeanDefinitionRegistryPostProcessors first, if any. Set<String> processedBeans = new HashSet<>(); // 对BeanDefinitionRegistry类型的处理 if (beanFactory instanceof BeanDefinitionRegistry) { BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory; List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>(); List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>(); // 硬编码注册的后处理器 for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) { if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) { BeanDefinitionRegistryPostProcessor registryProcessor = (BeanDefinitionRegistryPostProcessor) postProcessor; // 对于BeanDefinitionRegistryPostProcessor类型,在BeanFactoryPostProcessor // 的基础上还有自定义的方法,需要先调用 registryProcessor.postProcessBeanDefinitionRegistry(registry); registryProcessors.add(registryProcessor); } else { // 记录常规在BeanFactoryPostProcessor regularPostProcessors.add(postProcessor); } } // Do not initialize FactoryBeans here: We need to leave all regular beans // uninitialized to let the bean factory post-processors apply to them! // Separate between BeanDefinitionRegistryPostProcessors that implement // PriorityOrdered, Ordered, and the rest. List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>(); // First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered. String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false); for (String ppName : postProcessorNames) { if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) { currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class)); processedBeans.add(ppName); } } sortPostProcessors(currentRegistryProcessors, beanFactory); registryProcessors.addAll(currentRegistryProcessors); // 配置的BeanDefinitionRegistryPostProcessor invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry); currentRegistryProcessors.clear(); // Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered. postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false); for (String ppName : postProcessorNames) { if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) { currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class)); processedBeans.add(ppName); } } sortPostProcessors(currentRegistryProcessors, beanFactory); registryProcessors.addAll(currentRegistryProcessors); invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry); currentRegistryProcessors.clear(); // Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear. boolean reiterate = true; while (reiterate) { reiterate = false; postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false); for (String ppName : postProcessorNames) { if (!processedBeans.contains(ppName)) { currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class)); processedBeans.add(ppName); reiterate = true; } } sortPostProcessors(currentRegistryProcessors, beanFactory); registryProcessors.addAll(currentRegistryProcessors); invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry); currentRegistryProcessors.clear(); } // Now, invoke the postProcessBeanFactory callback of all processors handled so far. // 常规BeanDefinitionPostProcessor invokeBeanFactoryPostProcessors(registryProcessors, beanFactory); invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory); } else { // Invoke factory processors registered with the context instance. invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory); } // Do not initialize FactoryBeans here: We need to leave all regular beans // uninitialized to let the bean factory post-processors apply to them! // 对于配置中读取的BeanFactoryPostProcessor的处理 String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false); // Separate between BeanFactoryPostProcessors that implement PriorityOrdered, // Ordered, and the rest. List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>(); List<String> orderedPostProcessorNames = new ArrayList<>(); List<String> nonOrderedPostProcessorNames = new ArrayList<>(); // 对后处理器进行分类 for (String ppName : postProcessorNames) { if (processedBeans.contains(ppName)) { // skip - already processed in first phase above // 已经处理过 } else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) { priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class)); } else if (beanFactory.isTypeMatch(ppName, Ordered.class)) { orderedPostProcessorNames.add(ppName); } else { nonOrderedPostProcessorNames.add(ppName); } } // First, invoke the BeanFactoryPostProcessors that implement PriorityOrdered. // 按照优先级进行排序 sortPostProcessors(priorityOrderedPostProcessors, beanFactory); invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory); // Next, invoke the BeanFactoryPostProcessors that implement Ordered. List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>(); for (String postProcessorName : orderedPostProcessorNames) { orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class)); } // 按照order排序 sortPostProcessors(orderedPostProcessors, beanFactory); invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory); // Finally, invoke all other BeanFactoryPostProcessors. // 无序,直接调用 List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>(); for (String postProcessorName : nonOrderedPostProcessorNames) { nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class)); } invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory); // Clear cached merged bean definitions since the post-processors might have // modified the original metadata, e.g. replacing placeholders in values... beanFactory.clearMetadataCache(); }
从上面的方法中我们看到,对于BeanFactoryPostProcessor的处理主要分两种情况进行,一个 是对于BeanDefinitionRegistry类的特殊处理,另一种是对普通的BeanFactoryPostProcessor进行处理。而对于每种情况都需要考虑硬编码注入注册的后处理器以及通过配置注人的后处理器。
对于BeanDefinitionRegistry类型的处理类的处理主耍包括以下内容。
(1)对于硬编码注册的后处理器的处理,主要是通过AbstractApplicationContext中的添加处理器方法 addBeanFactoryPostProcessor 进行添加。
@Override public void addBeanFactoryPostProcessor(BeanFactoryPostProcessor postProcessor) { Assert.notNull(postProcessor, "BeanFactoryPostProcessor must not be null"); this.beanFactoryPostProcessors.add(postProcessor); }
添加后的后处理器会存放在beanFactoryPostProcessors中,而在处理BeanFactoryPostProcessor 时候会首先检测 beanFactoryPostProcessors 是否有数据。当然,BeanDefinitionRegistryPostProcessor 继承自BeanFactoryPostProcessor,不但有 BeanFactoryPostProcessor 的特性,同时还有自己定义 的个性化方法,也需要在此调用。所以,这里需要从beanFactoryPostProcessors中挑出 BeanDefinitionRegistryPostProcessor 的后处理器,并进行其 postProcessBeanDefinitionRegistry 方法的激活。
(2)记录后处理器主要使用了三个List完成。
- registryPostProcessors:记录通过硬编码方式注册的 BeanDefinitionRegistryPostProcessor 类型的处理器。
- regularPostProcessors:记录通过硬编码方式注册的BeanFactoryPostProcessor类型的处理器。
- registryPostProcessorBeans:记录通过配置方式注册的 BeanDefinitionRegistryPostProcessor 类型的处理器。
(3)对以上所记录的List中的后处理器进行统一调用BeanFactoryPostProcessor的 postProcessBeanFactory 方法。
(4)对 beanFactoryPostProccssors 中非 BeanDefinitionRegistryPostProcessor 类型的后处理器进行统一的 BeanFactoryPostProcessor 的 postProcessBeanFactory 方法调用。
(5)普通 beanFactory 处理。
BeanDefinitionRegistryPostProcessor 只对 BeanDefinitionRegistry 类型的 ConfigurableListableBeanFactory有效,所以如果判断所示的beanFactory并不是BeanDefinitionRegistry,那么便可以忽略 BeanDefinitionRegistryPostProcessor,而直接处理 BeanFactoryPostProcessor,当然获取的方式与上面的获取类似。
这里需要提到的是,对于硬编码方式手动添加的后处理器是不需要做任何排序的,但是在配置文件中读取的处理器,Spring并不保证读取的顺序。所以,为了保证用户的调用顺序的要求,Spring对于后处理器的调用支持按照PriorityOrdered或者Ordered的顺序调用。
二、注册BeanPostProcessor
上文中提到了BeanFactoryPostProccssors 的调用,现在我们来探索下 BeanPostProcessor , 但是这里并不是调用,而是注册。真正的调用其实是在 bean 的实例化阶段进行的。这是一个很重要的步骤,也是很多功能 BeanFactory 不支持的重要原因。 Spring 中大部分功能都是通过后处理器的方式进行扩展的,这是 Spring 框架的一个特性,但是在 BeanFactory 中其实并没有实现后处理器的自动注册,所以在调用的时候如果没有进行手动注册其实是不能使用的。但是在 ApplicationContext 中却添加了自动注册功能,如自定义这样一个后处理器:
public class MyInstantiationAwareBeanPostProcessor implements InstantiationAwareBeanPostProcessor { @Nullable @Override public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException { System.out.println("====="); return null; } }
在配置文件中添加配置:
<bean class="org.cellphone.uc.MyInstantiationAwareBeanPostProcessor"/>
那么使用BeanFactory方式进行Spring的bean的加载时是不会有任何改变的,但是使用ApplicationContext方式获取bean的时候会在获取每个bean时打印出“=====”,而这个特性就是在registerBeanPostProcessors方法中完成的。
我们继续探索registerBeanPostProcessors的方法实现。
public static void registerBeanPostProcessors( ConfigurableListableBeanFactory beanFactory, AbstractApplicationContext applicationContext) { String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanPostProcessor.class, true, false); // Register BeanPostProcessorChecker that logs an info message when // a bean is created during BeanPostProcessor instantiation, i.e. when // a bean is not eligible for getting processed by all BeanPostProcessors. /** * BeanPostProcessorChecker是一个普通的信息打印,可能会有些情况, * 当Spring配置中的后处理器还没有被注册就已经开始了bean的初始化时 * 便会打印出BeanPostProcessorChecker中设定的信息 */ int beanProcessorTargetCount = beanFactory.getBeanPostProcessorCount() + 1 + postProcessorNames.length; beanFactory.addBeanPostProcessor(new BeanPostProcessorChecker(beanFactory, beanProcessorTargetCount)); // Separate between BeanPostProcessors that implement PriorityOrdered, // Ordered, and the rest. // 使用PriorityOrdered保证有序 List<BeanPostProcessor> priorityOrderedPostProcessors = new ArrayList<>(); List<BeanPostProcessor> internalPostProcessors = new ArrayList<>(); // 使用Ordered保证有序 List<String> orderedPostProcessorNames = new ArrayList<>(); // 无序BeanPostProcessor List<String> nonOrderedPostProcessorNames = new ArrayList<>(); for (String ppName : postProcessorNames) { if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) { BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class); priorityOrderedPostProcessors.add(pp); if (pp instanceof MergedBeanDefinitionPostProcessor) { internalPostProcessors.add(pp); } } else if (beanFactory.isTypeMatch(ppName, Ordered.class)) { orderedPostProcessorNames.add(ppName); } else { nonOrderedPostProcessorNames.add(ppName); } } // First, register the BeanPostProcessors that implement PriorityOrdered. // 第一步,注册所有实现PriorityOrdered的BeanPostProcessor sortPostProcessors(priorityOrderedPostProcessors, beanFactory); registerBeanPostProcessors(beanFactory, priorityOrderedPostProcessors); // Next, register the BeanPostProcessors that implement Ordered. // 第二步,注册所有实现Ordered的BeanPostProcessor List<BeanPostProcessor> orderedPostProcessors = new ArrayList<>(); for (String ppName : orderedPostProcessorNames) { BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class); orderedPostProcessors.add(pp); if (pp instanceof MergedBeanDefinitionPostProcessor) { internalPostProcessors.add(pp); } } sortPostProcessors(orderedPostProcessors, beanFactory); registerBeanPostProcessors(beanFactory, orderedPostProcessors); // Now, register all regular BeanPostProcessors. // 第三步,注册所有无序的BeanPostProcessor List<BeanPostProcessor> nonOrderedPostProcessors = new ArrayList<>(); for (String ppName : nonOrderedPostProcessorNames) { BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class); nonOrderedPostProcessors.add(pp); if (pp instanceof MergedBeanDefinitionPostProcessor) { internalPostProcessors.add(pp); } } registerBeanPostProcessors(beanFactory, nonOrderedPostProcessors); // Finally, re-register all internal BeanPostProcessors. // 第四步,注册所有MergedBeanDefinitionPostProcessor类型的BeanPostProcessor,并非重复注册, // 在beanFactory .addBeanPostProcessor中会先移除已经存在的BeanPostProcessor sortPostProcessors(internalPostProcessors, beanFactory); registerBeanPostProcessors(beanFactory, internalPostProcessors); // Re-register post-processor for detecting inner beans as ApplicationListeners, // moving it to the end of the processor chain (for picking up proxies etc). // 添加ApplicationListener探测器 beanFactory.addBeanPostProcessor(new ApplicationListenerDetector(applicationContext)); }
配合源码以及注释,在registerBeanPostProcessors方法中所做的逻辑相信大家已经很清楚了,我们再做一下总结。
首先我们会发现,对于BeanPostProcessor的处理与BeanFactoryPostProcessor的处理极为相似,但是似乎又有些不一样的地方。经过反复的对比发现,对于BeanFactoryPostProcessor 的处理要区分两种情况,一种方式是通过硬编码方式的处理,另一种是通过配置文件方式的处理。那么为什么在BeanPostProcessor的处理中只考虑了配置文件的方式而不考虑硬编码的方式呢? 提出这个问题,还是因为读者没有完全理解两者实现的功能。对于BeanFactoryPostProcessor 的处理,不但要实现注册功能,而且还要实现对后处理器的激活操作,所以需要载人配罝中的定义,并进行激活;而对于BeanPostProcessor并不需要马上调用,再说,硬编码的方式实现的功能是将后处理器提取并调用,这里并不需要调用,当然不需要考虑硬编码的方式了,这里的功能只需要将配置文件的BeanPostProcessor提取出来并注册进入beanFactory就可以了。
对于beanFactory的注册,也不是直接注册就可以的。在Spring中支持对BeanPostProcessor的排序,比如根据PriorityOrdered进行排序、根据Ordered进行排序或者无序,而Spring在BeanPostProcessor的激活顺序的时候也会考虑对于顺序的问题而先进行排序。
这里可能有个地方读者不是很理解,对于internalPostProcessors中存储的后处理器也就是 MergedBeanDefinitionPostProcessor类型的处理器,在代码中似乎是被重复调用了,如:
for (String ppName : postProcessorNames) { if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) { BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class); priorityOrderedPostProcessors.add(pp); if (pp instanceof MergedBeanDefinitionPostProcessor) { internalPostProcessors.add(pp); } } else if (beanFactory.isTypeMatch(ppName, Ordered.class)) { orderedPostProcessorNames.add(ppName); } else { nonOrderedPostProcessorNames.add(ppName); } }
其实不是,我们可以看看对于registerBeanPostProcessors方法的实现方式。
/** * Register the given BeanPostProcessor beans. */ private static void registerBeanPostProcessors( ConfigurableListableBeanFactory beanFactory, List<BeanPostProcessor> postProcessors) { for (BeanPostProcessor postProcessor : postProcessors) { beanFactory.addBeanPostProcessor(postProcessor); } }
@Override public void addBeanPostProcessor(BeanPostProcessor beanPostProcessor) { Assert.notNull(beanPostProcessor, "BeanPostProcessor must not be null"); this.beanPostProcessors.remove(beanPostProcessor); this.beanPostProcessors.add(beanPostProcessor); if (beanPostProcessor instanceof InstantiationAwareBeanPostProcessor) { this.hasInstantiationAwareBeanPostProcessors = true; } if (beanPostProcessor instanceof DestructionAwareBeanPostProcessor) { this.hasDestructionAwareBeanPostProcessors = true; } }
可以看到,在registerBeanPostProcessors方法的实现中其实已经确保了beanPostProcessor的唯一性,个人猜想,之所以选择在registerBeanPostProcessors中没有进行重复移除操作或许是为了保持分类的效果,使逻辑更为清晰吧。
三、初始化消息资源
在进行这段函数的解析之前,我们同样先来回顾Spring国际化的使用方法。
假设我们正在开发一个支持多国语言的Web应用程序,要求系统能够根据客户端的系统的语言类型返回对应的界面:英文的操作系统返回英文界面,而中文的操作系统则返回中文界面一一这便是典型的il8n国际化问题。对于有国际化要求的应用系统,我们不能简单地采用硬编码的方式编写用户界面信息、报错信息等内容,而必须为这些需要国际化的信息进行特殊处理。简单来说,就是为每种语言提供一套相应的资源文件,并以规范化命名的方式保存在特定的目录中,由系统自动根据客户端语言选择适合的资源文件。
“国际化信息”也称为“本地化信息”,一般需要两个条件才可以确定一个特定类型的本地化信息,它们分別是“语言类型”和“国家/地区的类型”。如中文本地化信息既有中国大陆地区的中文,又有中国台湾地区、中国香港地区的中文,还有新加坡地区的中文。Java通过 java.util.Locale类表示一个本地化对象,它允许通过语言参数和国家/地区参数创建一个确定的本地化对象。
java.util.Locale是表示语言和国家/地区信息的本地化类,它是创建国际化应用的基础。下 面给出几个创建本地化对象的示例:
// 带有语言和国家/地区信息的本地化对象 Locale locale1 = new Locale("zh","CN"); // 只有语言信息的本地化对象 Locale locale2 = new Locale("zh"); // 等同于Locale("zh", "CN") Locale locale3 = Locale.CHINA; // 等同于Locale("zh") Locale locale4 = Locale.CHINESE; // 获取本地系统默认的本地化对象 Locale locale5 = Locale.getDefault();
JDK的java.util包中提供了几个支持本地化的格式化操作工具类:NumberFormat、 DateFormat、MessageFormat,而在Spring中的国际化资源操作也非是对于这些类的封装操作,我们仅仅介绍下MessageFormat的用法以帮助大家回顾:
// 信息格式化串 String pattern1 = "{0},你好!你于{1}在工商银行存入{2}元。"; String pattern2 = "At, {1, time, short} On {1, date, long}, {0} paid {2, number, currency}."; // 用于动态替换占位符的参数 Object[] params = {"John", new GregorianCalendar().getTime(), 1.0E3}; // 使用默认本地化对象格式化信息 String msg1 = MessageFormat.format(pattern1, params); // 使用指定的本地化对象格式化信息 MessageFormat mf = new MessageFormat(pattern2, Locale.US); String msg2 = mf.format(params); System.out.println(msg1); System.out.println(msg2);
Spring定义了访问国际化信息的MessageSource接口,并提供了几个易用的实现类。MessageSource分别被HierarchicalMessageSource和ApplicationContext接口扩展,这里我们主要看一下HierarchicalMessageSource接口的几个实现类,如下图所示:
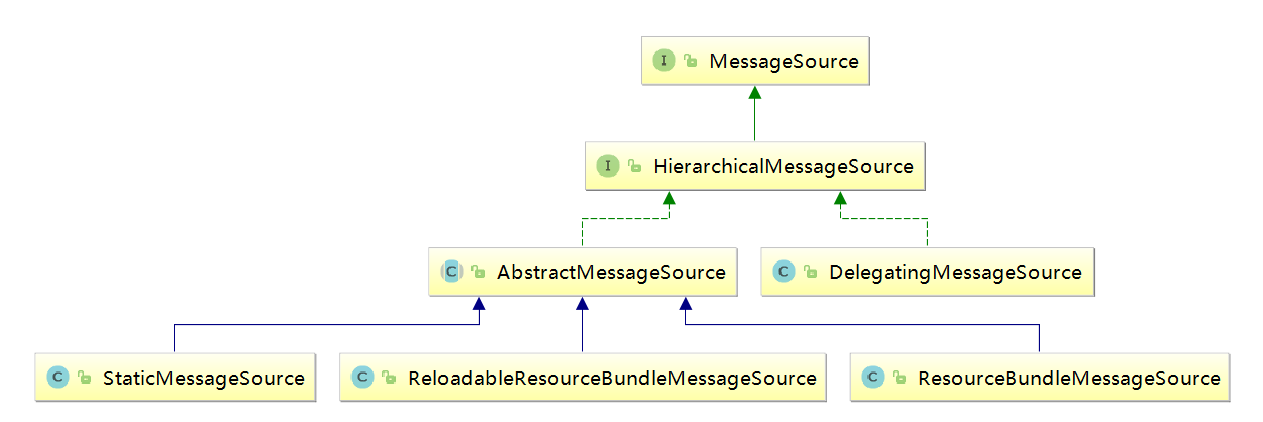
HierarchicalMessageSource接口最终要的两个实现类是ResourceBundleMessageSource和ReloadableResourceBundleMessageSource。他们基于Java的ResourceBundle基础类实现,允许仅通过资源名加载国际化资源。ReloadableResourceBundleMessageSource提供了定时刷新功能,允许在不重启系统的情况下,更新资源信息。StaticMessageSource主要用于程序测试,它允许通过编程的方式提供同际化信息。而DelegatingMessageSource是为方便操作父MessageSource而提供的代理类。仅仅举例ResourceBundleMessageSource的实现方式。
(1)定义资源文件。
- messages.properties (默认:英文),内容仅一句:test=test
- messages_zh_CN.properties (简体中文):test=测试
然后 cmd,打开命令行窗口,输入 native2ascii -encoding gbk C:\messages_zh_CN.properties C:\messages_zh_CN_tem.properties,并将 C:\messages_zh_CN_tem.properties 中的内容替换到 messages_zh_CN.properties 中,这样 messages_zh_CN.properties 文件就存放的是转码后的内容了,比较简单。
(2)定义配置文件。
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource"> <property name="basenames"> <list> <value>test/message</value> </list> </property> </bean>
其中,这个Bean的ID必须命名为messageSource,否则会抛出NoSuchMessageException 异常。
(3)使用。通过ApplicationContext访问国际化信息。
String[] configs = {"applicationContext.xml"};
ApplicationContext ctx = new ClassPathXmlApplicationContext(configs);
// 直接通过容器访问国际化信息
Object[] params = {"John", new GregorianCalendar().getTime()};
String str1 = ctx.getMessage("test", params, Locale.US);
String str2 = ctx.getMessage("test", params, Locale.CHINA);
System.out.println(str1);
System.out.println(str2);
了解了Spring 国际化的使用后便可以进行源码的分析了。
在initMessageSource中的方法主要功能是提取配置中定义的messageSource,并将其记录在Spring的容器中,也就是AbstractApplicationContext中。当然,如果用户未设置资源文件的话,Spring中也提供了默认的配置DdegatingMessageSource。
在initMessageSource中获取白定义资源文件的方式为beanFactory.getBean(MESSAGE_ SOURCE_BEAN_NAME,MessageSource.class),在这里 Spring 使用了硬编码的方式硬性规定了子定义资源文件必须为message,否则便会获取不到自定义资源配置,这也是为什么之前提到 Bean的id如果不为message会抛出异常。
/** * Initialize the MessageSource. * Use parent's if none defined in this context. */ protected void initMessageSource() { ConfigurableListableBeanFactory beanFactory = getBeanFactory(); if (beanFactory.containsLocalBean(MESSAGE_SOURCE_BEAN_NAME)) { // 如果在配置中已经配置了messageSource,那么将messageSource提取并记录在this.messageSource this.messageSource = beanFactory.getBean(MESSAGE_SOURCE_BEAN_NAME, MessageSource.class); // Make MessageSource aware of parent MessageSource. if (this.parent != null && this.messageSource instanceof HierarchicalMessageSource) { HierarchicalMessageSource hms = (HierarchicalMessageSource) this.messageSource; if (hms.getParentMessageSource() == null) { // Only set parent context as parent MessageSource if no parent MessageSource // registered already. hms.setParentMessageSource(getInternalParentMessageSource()); } } if (logger.isTraceEnabled()) { logger.trace("Using MessageSource [" + this.messageSource + "]"); } } else { // Use empty MessageSource to be able to accept getMessage calls. // 如果用户并没有定义配置文件,那么使用临时的DelegatingMessageSource以便于作为调用getMessage方法的返回 DelegatingMessageSource dms = new DelegatingMessageSource(); dms.setParentMessageSource(getInternalParentMessageSource()); this.messageSource = dms; beanFactory.registerSingleton(MESSAGE_SOURCE_BEAN_NAME, this.messageSource); if (logger.isTraceEnabled()) { logger.trace("Unable to locate MessageSource with name '" + MESSAGE_SOURCE_BEAN_NAME + "': using default [" + this.messageSource + "]"); } } }
通过读取并将自定义资源文件配置记录在容器中,那么就可以在获取资源文件的时候直接使用了,例如,在AbstractApplicationContext中的获取资源文件属性的方法:
@Override public String getMessage(String code, @Nullable Object[] args, Locale locale) throws NoSuchMessageException { return getMessageSource().getMessage(code, args, locale); }
其中的getMessageSource()方法正是获取了之前定义的自定义资源配置。
四、初始化ApplicationEventMulticaster
在讲解Spring的事件传播器之前,我们还是先来看一下Spring的事件监听的简单用法。
(1)定义监听事件。
public class TestEvent extends ApplicationEvent { private String msg; /** * Create a new ApplicationEvent. * * @param source the object on which the event initially occurred (never {@code null}) */ public TestEvent(Object source) { super(source); } public TestEvent(Object source, String msg) { super(source); this.msg = msg; } public void print() { System.out.println(msg); } }
(2)定义监听器。
public class TestListener implements ApplicationListener { @Override public void onApplicationEvent(ApplicationEvent event) { if (event instanceof TestEvent) { TestEvent testEvent = (TestEvent) event; testEvent.print(); } } }
(3)添加配置文件。
<bean id="testListener" class="org.cellphone.uc.TestListener"/>
(4)测试。
public static void main(String[] args) { ApplicationContext context = new ClassPathXmlApplicationContext("spring/beans-test.xml"); TestEvent event = new TestEvent("hello", "msg"); context.publishEvent(event); }
当程序运行时,Spring 会将发出的 TestEvent 事件转给我们自定义的 TestListener 进行进一步处理。
或许很多人一下子会反映出设计模式中的观察者模式,这确实是个典型的应用,可以在比较关心的事件结束后及时处理。那么我们看看 ApplicationEventMulticaster 是如何被初始化的,以确保功能的正确运行。
initApplicationEventMulticaster的方式比较简单,无非考虑两种情况。
- 如果用户自定义了事件广播器,那么使用用户自定义的事件广播器。
- 如果用户没有自定义事件广播器,那么使用默认的 ApplicationEventMulticaster。
/** * Initialize the ApplicationEventMulticaster. * Uses SimpleApplicationEventMulticaster if none defined in the context. * @see org.springframework.context.event.SimpleApplicationEventMulticaster */ protected void initApplicationEventMulticaster() { ConfigurableListableBeanFactory beanFactory = getBeanFactory(); if (beanFactory.containsLocalBean(APPLICATION_EVENT_MULTICASTER_BEAN_NAME)) { this.applicationEventMulticaster = beanFactory.getBean(APPLICATION_EVENT_MULTICASTER_BEAN_NAME, ApplicationEventMulticaster.class); if (logger.isTraceEnabled()) { logger.trace("Using ApplicationEventMulticaster [" + this.applicationEventMulticaster + "]"); } } else { this.applicationEventMulticaster = new SimpleApplicationEventMulticaster(beanFactory); beanFactory.registerSingleton(APPLICATION_EVENT_MULTICASTER_BEAN_NAME, this.applicationEventMulticaster); if (logger.isTraceEnabled()) { logger.trace("Unable to locate ApplicationEventMulticaster with name '" + APPLICATION_EVENT_MULTICASTER_BEAN_NAME + "': using default [" + this.applicationEventMulticaster + "]"); } } }
按照之前介绍的顺序及逻辑,我们推断,作为广播器,一定是用于存放监听器并在合适的时候调用监听器,那么我们不妨进入默认的广播器实现SimpleApplicationEventMulticaster来一探究竟。
@Override public void multicastEvent(ApplicationEvent event) { multicastEvent(event, resolveDefaultEventType(event)); } @Override public void multicastEvent(final ApplicationEvent event, @Nullable ResolvableType eventType) { ResolvableType type = (eventType != null ? eventType : resolveDefaultEventType(event)); for (final ApplicationListener<?> listener : getApplicationListeners(event, type)) { Executor executor = getTaskExecutor(); if (executor != null) { executor.execute(() -> invokeListener(listener, event)); } else { invokeListener(listener, event); } } } /** * Invoke the given listener with the given event. * @param listener the ApplicationListener to invoke * @param event the current event to propagate * @since 4.1 */ protected void invokeListener(ApplicationListener<?> listener, ApplicationEvent event) { ErrorHandler errorHandler = getErrorHandler(); if (errorHandler != null) { try { doInvokeListener(listener, event); } catch (Throwable err) { errorHandler.handleError(err); } } else { doInvokeListener(listener, event); } } @SuppressWarnings({"unchecked", "rawtypes"}) private void doInvokeListener(ApplicationListener listener, ApplicationEvent event) { try { listener.onApplicationEvent(event); } catch (ClassCastException ex) { String msg = ex.getMessage(); if (msg == null || matchesClassCastMessage(msg, event.getClass().getName())) { // Possibly a lambda-defined listener which we could not resolve the generic event type for // -> let's suppress the exception and just log a debug message. Log logger = LogFactory.getLog(getClass()); if (logger.isDebugEnabled()) { logger.debug("Non-matching event type for listener: " + listener, ex); } } else { throw ex; } } }
可以推断,当产生Spring事件的时候会默认使用SimpleApplicationEventMulticaster的multicastEvent来广播事件,遍历所有监听器,并使用监听器中的onApplicationEvent来进行监听器的处理。而对于每个监听器来说其实都可以获取到产生的事件,但是是否进行处理则由事件监听器来决定。
五、注册监听器
之前在介绍Spring的广播器时反复提到了事件监听器,那么在Spring注册监听器的时候又做了哪些逻辑操作呢?
/** * Add beans that implement ApplicationListener as listeners. * Doesn't affect other listeners, which can be added without being beans. */ protected void registerListeners() { // Register statically specified listeners first. // 硬编码方式注册的监听器处理 for (ApplicationListener<?> listener : getApplicationListeners()) { getApplicationEventMulticaster().addApplicationListener(listener); } // Do not initialize FactoryBeans here: We need to leave all regular beans // uninitialized to let post-processors apply to them! // 配置文件注册的监听器处理 String[] listenerBeanNames = getBeanNamesForType(ApplicationListener.class, true, false); for (String listenerBeanName : listenerBeanNames) { getApplicationEventMulticaster().addApplicationListenerBean(listenerBeanName); } // Publish early application events now that we finally have a multicaster... Set<ApplicationEvent> earlyEventsToProcess = this.earlyApplicationEvents; this.earlyApplicationEvents = null; if (earlyEventsToProcess != null) { for (ApplicationEvent earlyEvent : earlyEventsToProcess) { getApplicationEventMulticaster().multicastEvent(earlyEvent); } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号