PDF格式简单分析
上周因需要编辑了下PDF,用了一两个试用软件,感觉文字版的PDF还是挺好编辑的。想要研究一下PDF格式。
0. 站在前辈的肩膀上
从前辈的文章和书籍了解到
-
PDF文件是一种文本和二进制混排的格式,二进制的内容来自于三个方面:1、图片;2、字体;3、压缩后的Post Script。
-
PDF文件正文由一系列对象组成, 每个对象前面都有一个对象编号(唯一)、生成号和一行上的 obj 关键字, 后面跟另一行的 endobj 关键字。例如:
1 0 obj << /Kids [2 0 R] /Count 1 /Type /Pages >> endobj在这里, 对象编号为 1, 生成号为 0 (几乎总是)。对象1的内容位于两行之间 1 0 obj 和 endobj 之间。在这种情况下, 它是字典
<</Kids [2 0 R] /Count 1 /Type /Pages >>。 -
对象:PDF对象包括5个基本对象以及3个复合对象
-
基本对象:
Boolean values 布尔值,true和false。Integers and real numbers 数值,包含整型和浮点型,例如 42和3.1415。
Strings 字符串,文字字符串包含在圆括号
()内,十六进制字符串包含在单尖括号<>内。Names 名称,由
/+字符串 组成,相同的名字表示相同的对象。Null 空对象,用关键字
null表示。上面是基础对象,可组合为复合对象:
-
复合对象
Array 数组,包含其他对象的有序集合,包含在方括号
[]内,元素可以是除了Stream类型外的所有类型,如[/xx false 1 (onion)]包含了四种类型,注:用空格分隔。Dictionary 字典,包含一个无序键值对的集合,包含在双尖括号
<< >>内。两个元素是一对,键是对象的名称,值是除了Stream外的所有类型。例如,<</Contents 4 0 R /Resources 5 0 R>>, 它将/Contents映射到间接引用4 0 R,以及/Resources映射到间接引用5 0 R。Stream 流,包含二进制数据,以及描述数据属性(如长度和压缩参数)的字典数据。PDF Stream由一个字典和一个字节流(流用于存储图像、字体等)组成,字典中定义了流的参数。字典中如果有
/Filter键,表示指定的过滤器类型,压缩过滤器FlateDecode最为常用。(下一节会看到没有压缩过滤器,采用XML的流对象)。补:Object Object 流对象类型,PDF 1.5中引入。以及其他的类型,以后遇到再补充。
-
间接引用
除了基本对象和复合对象,还有一种将对象链接在一起的方法:
Indirect reference 间接引用,它形成从一个对象到另一个对象的链接。
PDF 文件由对象图组成, 间接引用构成它们之间的链接。
-

图1 《PDF explained》文件结构->对象
-
PDF由四部分组成
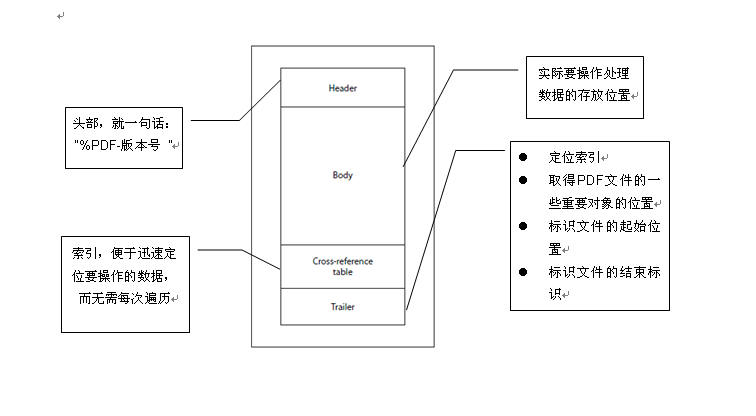
-
PDF 处理流程
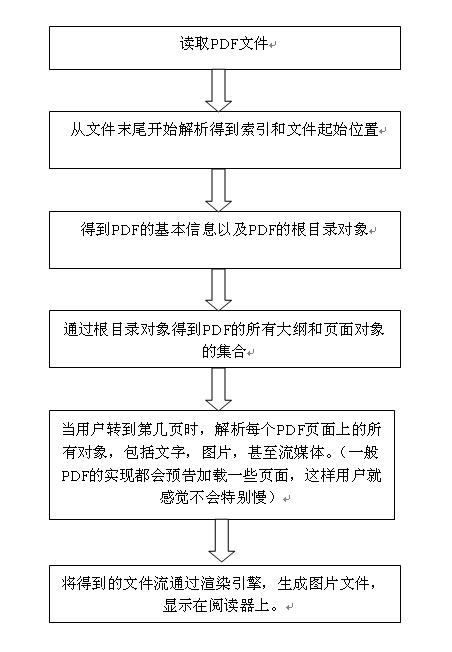
用一个实例来研究下结构。
1. Hello, PDF
为了研究精简的PDF文档结构,新建了一个PDF,内容就是Hello, PDF.。
图4 hello.pdf,一个 hello world级别的 PDF
用编辑器打开,查看文本,流对象不能查看,用...替换掉。文本为下面部分
%PDF-1.7
%����
1 0 obj
<</Pages 2 0 R /Type/Catalog/Metadata 8 0 R >>
endobj
4 0 obj
<</Resources<</Font<</FXF1 6 0 R >>>>/MediaBox[ 0 0 595.28 841.89]/Contents 7 0 R /Parent 2 0 R /Type/Page/CropBox[ 0 0 595.28 841.89]>>
endobj
7 0 obj
<</Length 86/Filter/FlateDecode>>stream
...
endstream
endobj
8 0 obj
<</Length 865/Type/Metadata/Subtype/XML>>stream
...
endstream
endobj
9 0 obj
<</Type /ObjStm /N 3/First 15/Length 224/Filter /FlateDecode>>stream
...
endstream
endobj
10 0 obj
<</Type /XRef/W[1 4 2]/Index[0 11]/Size 11/Filter /FlateDecode/DecodeParms<</Columns 7/Predictor 12>>/Length 64
/Root 1 0 R
/Info 3 0 R
/ID[<5E1FEDA5466E60C6D70D3004F5E43166><5E1FEDA5466E60C6D70D3004F5E43166>]>>stream
...
endstream
endobj
startxref
1662
%%EOF
简单分析:
Header
第一行 %PDF-1.7,%符号表示一个标题行,这里给出了文件的PDF版本号 1.7。
第二行 %����,%表示另一个标题行,乱码内容为大于127字节的二进制数据。由于PDF文件几乎总是包含二进制数据,因此如果更改行结尾(例如,如果文件通过FTP以文本模式传输),它们可能会损坏。 为了允许传统文件传输程序确定文件是二进制文件,通常在标头中包含一些字符代码高于127的字节。
Body
文件正文由一系列对象组成(上节有介绍),这里有6个对象,分别是
1 0 obj ... endobj
4 0 obj ... endobj
7 0 obj ... endobj
8 0 obj ... endobj
9 0 obj ... endobj
10 0 obj ... endobj
Cross-Reference Table
交叉引用表格式:
xref # 标识交叉引用表开始
0 14 # 说明下面对象编号是从0开始,总共有14个对象, 从 0 到 13
0000000000 65535 f # 第0个对象,规定生成号为65535,f 表示 free entry,对象不存在或者删除
0000003079 00000 n # 第1个对象,偏移地址为3079,生成号为0表示未被修改过, n 表示 in use
从 PDF 1.5 开始, 引入了一种新的机制, 通过允许将许多对象放入单个对象流 (整个流被压缩) 来进一步压缩 PDF 文件。同时, 引入了一种引用这些流中对象的新机制--交叉引用流(cross-reference streams)。
在本次测试中的PDF不存在关键字 xref开头的引用,只有基于流的引用,10 0 obj这个对象可能就是了。
交叉引用流格式是这样的: (现在只接触过 类型为 /XRef 和 /ObjStm 的交叉引用流对象)
x 0 obj
<</Type /XRef ...>>stream
...
endstream
endobj
x 0 obj
<</Type /ObjStm ...>>stream
...
endstream
endobj
Trailer
测试文本中没有看到Trailer关键字,类似
trailer # 标识文件尾trailer对象开始
<</Root 13 0 R # 表明根对象的对象号为13,即交叉表中的最后一个对象
/ID [<4E76CDCEDB1E2EC4AC47475DB4EE376E> <C8B1AEBC2C6615E39860F1C150A2847C>]
/Size 14 # 表明PDF文件的对象数目
/Info 8 0 R>>
以后遇到了再分析。
倒数第三行的 startxref,标明了交叉引用表的偏移地址,下面的数字1662代表了偏移量(相对于文件开始)。因为一个文档中可以有多个xref,所以这里要指明要从哪个xref开始进行解析这个文件。
1662的十六进制为67E, 将文件以十六进制格式打开,刚好是10 0 obj那个 xref 对象的开始位置。
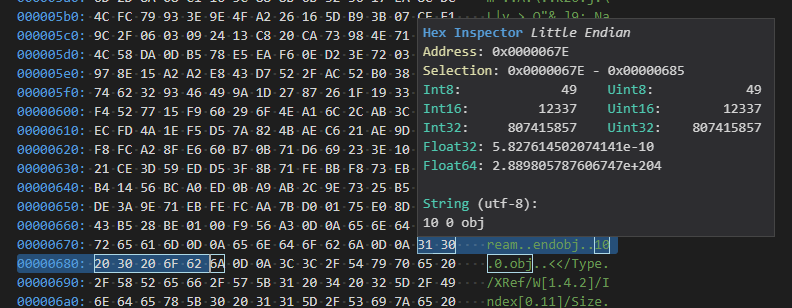
图5 16进制查看起始位置的对象
最后一行 %%EOF, 标识 PDF 文件结尾。
字典数据
从起始位置的对象10 0 obj分析。先看其中的字典数据,先格式化一下,按照我的理解简单标注
<<
/Type /XRef # 类型为xref,表示此对象是基于流的交叉引用表
/W[1 4 2] # W的值为数组 [1 4 2]
/Index[0 11] # Index 值为 [0 11]
/Size 11 # 文件数目?
/Filter /FlateDecode # 指定压缩算法,RFC1950,即ZLIB
/DecodeParms <</Columns 7/Predictor 12>>
/Length 64 # stream 的数据长度
/Root 1 0 R
/Info 3 0 R
/ID[<5E1FEDA5466E60C6D70D3004F5E43166><5E1FEDA5466E60C6D70D3004F5E43166>] # ID为数组,数组值为两个十六进制字符串,见到了<>(尖括号)内的的十六进制
>>
解析流
拿10 0 obj下的stream二进制数据,用zlib解压,没出来想要的结果。学习一下如何正确的解析流数据。
找到一串代码,修改后:
import re
import zlib
pdf = open("hello.pdf", "rb").read()
stream = re.compile(b'.*?FlateDecode.*?stream(.*?)endstream', re.S)
for s in re.findall(stream,pdf):
s = s.strip(b'\r\n')
try:
unzip_data = zlib.decompress(s)
stream = unzip_data.decode('UTF-8')
print(stream)
except Exception as e:
print(e)
二进制的流数据
上面的代码部分,从文件读取二进制数据,通过正则可以拿到流二进制数据,去掉头尾的\r\n,十六进制为0D0A
pdf = open("some_doc.pdf", "rb").read()
stream = re.compile(b'.*?FlateDecode.*?stream(.*?)endstream', re.S)
for s in re.findall(stream,pdf):
s = s.strip(b'\r\n')
print(s)
匹配到三条流数据:(对应的对象ID分别是7 9 10)
#(这里输出的是7 0 obj对象的流数据)
b'x\x9c+\xe4r\n\xe12P\x00\xc1\xa2t\x05\x08#\xc8\x1dH\x94+\xe8\xbbE\xb8\x19*\x18\x1a)\x84\xa4)\x18\x82% dH\xae\x82\xa1\xa5\x9e\xb1\x85\xa1\x82\x85\xa1\x91\x9e\xb1\x99\x99B\x88K\xb4\x86GjNN\xbe\x8eB\x80\x8b\x9b\x9efl\x88\x17\x97k\x08W \x17\x00\xad\x10\x14\x84'
#(这里输出的是9 0 obj对象的流数据)
b"x\x9cm\x8f\xcdJ\xc3P\x10\x85\x97\xbe\xc6\xec\x9a vn~L\xa3\x94@m-\x8a\x08\xc1\x16\\\x88\x8bk26\x17\xea\x8c\xdcL\xfcy\x93>\x9eO\xa2&\x16]\xb9;\x07\xce\xe1\x9c/\x06\x03\t$\x13\xc8 \xcas\x98Nq\xfd\xfeLX\xda\r\xb5x\xe5\xea\xf6\x0e\xd2>r\x03\xf78\x97\x8e\x15\xa2\xa2\xe8C\xd7R/\xacR\xb08\x8dMtb2\x93FI\x9a\x1d'\x87&\x1f\x193\n\xb1\xf4Rw\x15\xf9`)oN\xa1l,\xab<\xc1\x11\xec\xfdJ\x1e\xf5\xd5z\x82K\xae\xc6!\xae\x9dn)\xf8\xfc\xa2\x8f\xe6`\xb7\x0bq\xd6i#>\x10v\xc2!\xce=Y\xed\xd5?\x8bq\xfe\xbb\xf8s\xeb\xcc\xb6\xb4\x14V\xbc\xa0\xed\x0b\xa9\xab,\x9es%\xb5\xe3\r\xde:\x9eq\xeb\xfe\xfc\xaa{\xd0\x01u\xe0\x8d\xf6\xd4C\xb5(\xbe\x01\x00\xf9V\xa3"
#(这里输出的是10 0 obj对象的流数据)
b"x\x9ccb\x00\x81\xff\xff\x99\x18\x81\x94 ##\x98\xfe\xc1\xc0\xc0\x04\x16g`d\xfa\x0f$=\x19\xfe\x83\xe9u@q\x90\x04'\x90\x02\xf1\x9f0\xfc\x03q\x19\xe7B\xd4\xb3l\x80\xd0\x8c.\x0c\x0c\x00\x167\x0b\x9c"
如果没有从文件二进制中搜索或者想手动看特定的二进制流,就可以先复制十六进制数据之后转二进制。直接复制到代码中其实是十六进制的字符串,转二进制数据可以用 binascii 模块的 a2b_hex()
# 十六进制字符串转二进制
stream=b'789C63620081FFFF9918819420232398FEC1C0C00416676064FA0F243D19FE83E97540719004279002F19F30FC037119E742D4B36C80D08C2E0C0C0016370B9C' # 10 0 obj中流的十六进制数据
s2=binascii.a2b_hex(stream)
print(s2)
得到的二进制数据,和上面正则截取10 0 obj中的二进制流数据的是一样的
b"x\x9ccb\x00\x81\xff\xff\x99\x18\x81\x94 ##\x98\xfe\xc1\xc0\xc0\x04\x16g`d\xfa\x0f$=\x19\xfe\x83\xe9u@q\x90\x04'\x90\x02\xf1\x9f0\xfc\x03q\x19\xe7B\xd4\xb3l\x80\xd0\x8c.\x0c\x0c\x00\x167\x0b\x9c"
解压
直接用zlib模块进行解压:
unzip_data = zlib.decompress(s)
print(unzip_data)
解压后的三个对象数据为:
b'q\nBT\n0 0 0 rg 0 0 0 RG 0 w /FXF1 12 Tf 1 0 0 1 0 0 Tm 19.381 812.366 TD[(Hello, PDF.)]TJ\nET\nQ\n'
b"2 0 3 37 6 188 <</Type/Pages/Kids[ 4 0 R ]/Count 1>><</ModDate(D:20190604134653+08'00')/Producer(Foxit Phantom - Foxit Software Inc.)/Title(\xfe\xffe\xe0h\x07\x98\x98)/Author(onion)/CreationDate(D:20190604134628+08'00')>><</BaseFont/Helvetica/Encoding/WinAnsiEncoding/Subtype/Type1/Type/Font>>"
b'\x02\x00\x00\x00\x00\x00\xff\xff\x02\x01\x00\x00\x00\x11\x01\x01\x02\x01\x00\x00\x00\xf8\x00\x00\x02\x00\x00\x00\x00\x00\x00\x01\x02\xff\x00\x00\x00I\x00\xff\x02\xff\x00\x00\x00\xae\x00\x00\x02\x02\x00\x00\x00\t\x00\x02\x02\xff\x00\x00\x00\xe4\x00\xfe\x02\x00\x00\x00\x01\x9d\x00\x00\x02\x00\x00\x00\x04\xb0\x00\x00\x02\x00\x00\x00\x01D\x00\x00'
解压很顺利,再进行解码字符串操作:然而三个对象反应各不一样,各个分析。
对于7 0 obj数据,回顾下字典指定的参数 , 除了压缩参数/Filter/FlateDecode和长度之外,再无其他,直接解压解码正确,结果是:(格式就是这样,具体含义后面再做分析)
q
BT
0 0 0 rg 0 0 0 RG 0 w /FXF1 12 Tf 1 0 0 1 0 0 Tm 19.381 812.366 TD[(Hello, PDF.)]TJ
ET
Q
对于9 0 obj数据,字典数据参数有/Type /ObjStm /N 3/First 15/Length 224/Filter /FlateDecode,/Type 是ObjStm应该指的对象流数据,解码的时候有报错
'utf-8' codec can't decode byte 0xfe in position 140: invalid start byte
对应解压数据查看,发现0xfe出现在Title(\xfe\xffe\xe0h\x07\x98\x98), 报错原因就在这:Title里面的字符串不能用UTF-8编码正确解析,不知道是什么编码。由于对这个对象流数据不太了解,先暂时搁置,以后再来回顾。
对于10 0 obj数据,这个数据也不能正确解码,是因为除了/filter 参数,还有个 /DecodeParms 参数,这个是指数据加了PNG压缩算法的预处理(过滤)。接下来就来看看这个。
加过滤的流的解析
本小节图片和算法部分参考:PDF 参照流/交叉引用流对象(cross-reference stream)的解析方法
交叉引用流对象通常在存储之前都会进行压缩,而为了提高压缩率,会进行数据的预处理,这个预处理就称为过滤(filter)。读取时再进行反向的处理。
PNG规范中的过滤算法章节有说:
本章介绍可在压缩之前应用的过滤器算法。这些滤波器的目的是准备图像数据以实现最佳压缩。
虽然PDF不是图片,但是为实现最佳压缩,可以先使用过滤算法。
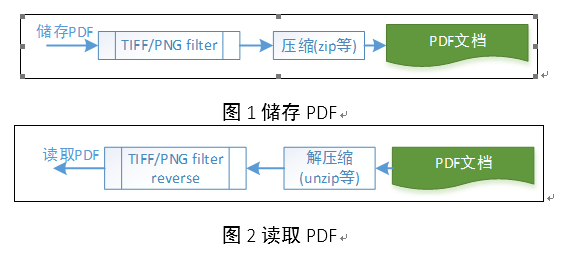
图6 带有PNG压缩算法的交叉引用流的压缩和过滤
所以,直接用zlib的zip解压算法解压后,还需要PNG过滤反转。
PNG过滤算法反转
要反转解压缩后
Up()过滤器的效果,请输出以下值:Up(x)+ Prior(x)
(计算的模256),其中
Prior()指的是先前扫描线的解码字节。
反转方法封装:
def show_hex_format(data, rows, columns):
""" 展示十六进制格式 """
for i in range(rows):
for j in range(columns):
print("%02x" % (data[i*columns+j]), end=" ")
print()
def filter_up_reverse(stream_data, columns, colors=1, bitsPerComponent=8):
""" PNG过滤器UP方法,反转方法 """
stream_data = bytearray(stream_data)
xref_data = []
data_len = len(stream_data)
width = columns*colors*bitsPerComponent//8
rows = data_len//(width+1)
show_hex_format(stream_data, rows, width+1)
cursor = 1
# 第一行处理,跳过
while cursor <= width:
xref_data.append(stream_data[cursor])
cursor += 1
for i in range(1, rows):
filter_type = stream_data[cursor]
cursor += 1
assert(filter_type == 2)
for j in range(width):
t = (stream_data[cursor]+stream_data[cursor-width-1]) % 256
stream_data[cursor] = t
xref_data.append(t)
cursor += 1
print("xref stream data:")
show_hex_format(xref_data, rows, width)
对于10 0 obj对象,使用filter_up_reverse(stream_unzip_data, 7) 调用,列宽为7来自/DecodeParms <</Columns 7/Predictor 12>> 的Columns属性,另外:Predictor属性代表过滤器采用UP方法,取上行的原始数据。show_hex_format()方法是为了方便查看十六进制以图片的行列排列的格式。
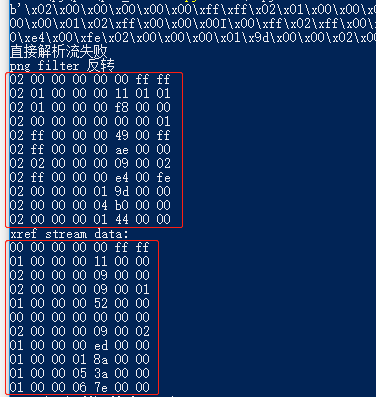
图7 反过滤 xref 数据
看图7,第一个框中是解压后的数据,第二个框中是反过滤的数据,即xref原始数据。
xref 交叉引用流数据分析
由于不知道解析的xref数据格式对不对,还一直去转,期待转成7 0 obj的那种可视化的字符格式,最后在 PDF 文件格式 文档中看到示例才反应过来,xref 流数据就是这样的格式。
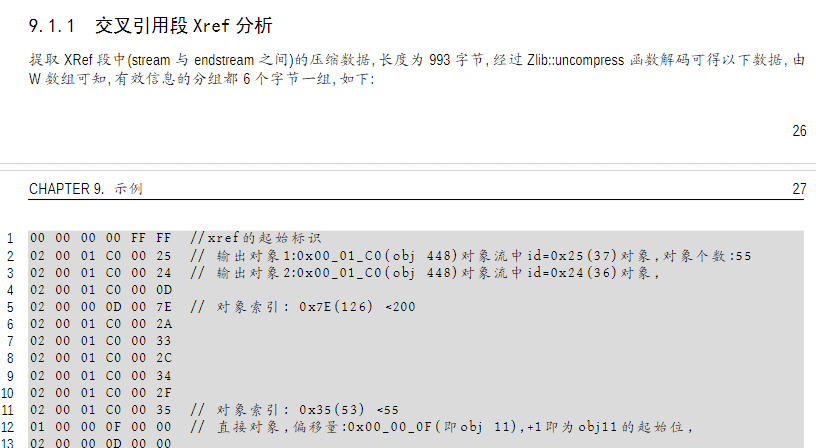
图8 xref数据分析示例

图9 交叉引用流 (xref strem) 的属性
三个位域的字节划分就来子属性W,W[1 4 2], 分别是第一个字节,中间四个字节,后两个字节。(1+4+2也对应到列宽为7字节)
分析10 0 obj的数据:
00 00 00 00 00 ff ff # xref 起始标识
01 00 00 00 11 00 00 # 直接对象,偏移量为0x11,查看该地址,对应 1 0 obj (对象ID:1)的起始位置
02 00 00 00 09 00 00 # 间接对象,对象id为9,索引0
02 00 00 00 09 00 01 # 间接对象,对象id为9,索引1
01 00 00 00 52 00 00 # 直接对象,偏移量为0x52,查看该地址,对应 4 0 obj 的起始位置
00 00 00 00 00 00 00
02 00 00 00 09 00 02 # 间接对象,对象id为9,索引2
01 00 00 00 ed 00 00 # 直接对象,偏移量为0xed,查看该地址,对应 7 0 obj 的起始位置
01 00 00 01 8a 00 00 # 直接对象,偏移量为0x18a,查看该地址,对应 8 0 obj 的起始位置
01 00 00 05 3a 00 00 # 直接对象,偏移量为0x53a,查看该地址,对应 9 0 obj 的起始位置
01 00 00 06 7e 00 00 # 直接对象,偏移量为0x67e,查看该地址,对应 10 0 obj 的起始位置
objStm 对象流数据分析
9 0 obj
<</Type /ObjStm /N 3/First 15/Length 224/Filter /FlateDecode>>stream
2 0 3 37 6 188 <</Type/Pages/Kids[ 4 0 R ]/Count 1>><</ModDate(D:20190610144818+08'00')/Producer(Foxit Phantom - Foxit Software Inc.)/Title(\xfe\xffe\xe0h\x07\x98\x98)/Author(onion)/CreationDate(D:20190610144753+08'00')>><</BaseFont/Helvetica/Encoding/WinAnsiEncoding/Subtype/Type1/Type/Font>>
endstream
endobj
对于9 0 obj,/Type 为/ObjStm,表示此对象为对象流数据。N表示流中的间接对象数(本例有3个对象),First表示解码流中第一个可压缩对象的偏移量(本例中代表解压数据后的15字节处为第一个对象)。
流中开始的2 0 3 37 6 188 是键值对表示的索引,键值对分别表示:对象ID和该对象在解码流中的字节偏移量。(例如:3 37 表示 对象3的偏移量为解压后数据的37字节处)
示例输出:(注:>>> 表示输出的数据)
print(stream_unzip_data) # 解压后的原始流数据
>>> b"2 0 3 37 6 188 <</Type/Pages/Kids[ 4 0 R ]/Count 1>><</ModDate(D:20190610144818+08'00')/Producer(Foxit Phantom - Foxit Software Inc.)/Title(\xfe\xffe\xe0h\x07\x98\x98)/Author(onion)/CreationDate(D:20190610144753+08'00')>><</BaseFont/Helvetica/Encoding/WinAnsiEncoding/Subtype/Type1/Type/Font>>"
stream_data_r = stream_unzip_data[15:] # 间接对象(所处的位置15)
print(stream_data_r)
>>> b"<</Type/Pages/Kids[ 4 0 R ]/Count 1>><</ModDate(D:20190610144818+08'00')/Producer(Foxit Phantom - Foxit Software Inc.)/Title(\xfe\xffe\xe0h\x07\x98\x98)/Author(onion)/CreationDate(D:20190610144753+08'00')>><</BaseFont/Helvetica/Encoding/WinAnsiEncoding/Subtype/Type1/Type/Font>>"
print("obj id:2 [0-36):", stream_data_r[:37]) # 对象ID:2,从0开始,到第二对象37之前即36
print("obj id:3 [37-187):",stream_data_r[37:188]) # 对象ID:3
print("obj id:6 [188-~):",stream_data_r[188:]) # 对象ID:6
>>> obj id:2 [0-36): b'<</Type/Pages/Kids[ 4 0 R ]/Count 1>>'
>>> obj id:3 [37-187): b"<</ModDate(D:20190610144818+08'00')/Producer(Foxit Phantom - Foxit Software Inc.)/Title(\xfe\xffe\xe0h\x07\x98\x98)/Author(onion)/CreationDate(D:20190610144753+08'00')>>"
>>> obj id:6 [188-~): b'<</BaseFont/Helvetica/Encoding/WinAnsiEncoding/Subtype/Type1/Type/Font>>'
最后的三个对象也对应到了上节 xref 数据的 02 00 00 00 09 00 [00,01,02] # 间接对象,对象id为9,索引0,1,2 。终于连起来了。
分析就到这里了。
初次与PDF的相遇,到这里就要说再见了。英语又锁死了这条科技树了。本来想要做一个简单编辑的,发现展示还有很长的路走(图像的绘制,字体加载)等等。未完待续

 浙公网安备 33010602011771号
浙公网安备 33010602011771号