openstack-mitaka版本DRV基础
一、基础知识
1.1 路由
1.1.1 策略路由
使用 ip rule 操作路由策略数据库 基于策略的路由比传统路由在功能上更强大,使用更灵活,它使网络管理员不仅能够根据目的地址而且能够根据报文大小、应用或IP源地址等属性来选择转发路径。
ip rule 命令:
Usage: ip rule [ list | add | del ] SELECTOR ACTION (add 添加;del 删除; llist 列表)
SELECTOR := [ from PREFIX 数据包源地址] [ to PREFIX 数据包目的地址] [ tos TOS 服务类型][ dev STRING 物理接口] [ pref NUMBER ] [fwmark MARK iptables 标签]
ACTION := [ table TABLE_ID 指定所使用的路由表] [ nat ADDRESS 网络地址转换][ prohibit 丢弃该表| reject 拒绝该包| unreachable 丢弃该包]
[ flowid CLASSID ]
TABLE_ID := [ local | main | default | new | NUMBER ]例子:
ip rule add from 192.203.80/24 table inr.ruhep prio 220 来自源地址为192.203.80/24的数据包 通过路由表 inr.ruhep 路由
ip rule add from 193.233.7.83 nat 192.203.80.144 table 1 prio 320 把源地址为193.233.7.83的数据报的源地址转换为192.203.80.144,并通过表1进行路由在 Linux 系统启动时,内核会为路由策略数据库配置三条缺省的规则:
- 0 匹配任何条件 查询路由表local(ID 255) 路由表local是一个特殊的路由表,包含对于本地和广播地址的高优先级控制路由。rule 0非常特殊,不能被删除或者覆盖。
- 32766 匹配任何条件 查询路由表main(ID 254) 路由表main(ID 254)是一个通常的表,包含所有的无策略路由。系统管理员可以删除或者使用另外的规则覆盖这条规则。
- 32767 匹配任何条件 查询路由表default(ID 253) 路由表default(ID 253)是一个空表,它是为一些后续处理保留的。对于前面的缺省策略没有匹配到的数据包,系统使用这个策略进行处理。这个规则也可以删除。
不要混淆路由表和策略:规则指向路由表,多个规则可以引用一个路由表,而且某些路由表可以没有策略指向它。如果系统管理员删除了指向某个路由表的所有规则,这个表就没有用了,但是仍然存在,直到里面的所有路由都被删除,它才会消失。
1.1.2 路由表 (使用 ip route 命令操作静态路由表)
所谓路由表,指的是路由器或者其他互联网网络设备上存储的表,该表中存有到达特定网络终端的路径,在某些情况下,还有一些与这些路径相关的度量。路由器的主要工作就是为经过路由器的每个数据包寻找一条最佳的传输路径,并将该数据有效地传送到目的站点。由此可见,选择最佳路径的策略即路由算法是路由器的关键所在。为了完成这项工作,在路由器中保存着各种传输路径的相关数据——路由表(Routing Table),供路由选择时使用,表中包含的信息决定了数据转发的策略。打个比方,路由表就像我们平时使用的地图一样,标识着各种路线,路由表中保存着子网的标志信息、网上路由器的个数和下一个路由器的名字等内容。路由表根据其建立的方法,可以分为动态路由表和静态路由表。
linux 系统中,可以自定义从 1-252个路由表,其中,linux系统维护了4个路由表:
0#表: 系统保留表
253#表: defulte table 没特别指定的默认路由都放在改表
254#表: main table 没指明路由表的所有路由放在该表
255#表: locale table 保存本地接口地址,广播地址、NAT地址 由系统维护,用户不得更改路由表的查看可有以下二种方法:
ip route list table table_number
ip route list table table_name路由表序号和表名的对应关系在 /etc/iproute2/rt_tables 文件中,可手动编辑。路由表添加完毕即时生效,下面为实例:
ip route add default via 192.168.1.1 table 1 在一号表中添加默认路由为192.168.1.1
ip route add 192.168.0.0/24 via 192.168.1.2 table 1 在一号表中添加一条到192.168.0.0网段的路由为192.168.1.2Destination Netmask Gateway Interface Metric
0.0.0.0 0.0.0.0 192.168.123.254 192.168.123.88 1 #缺省路由,目的地址不在本路由表中的数据包,经过本机的 192.168.123.88 接口发到下一个路由器 192.168.123.254
127.0.0.0 255.0.0.0 127.0.0.1 127.0.0.1 1 #发给本机的网络包
192.168.123.0 255.255.255.0 192.168.123.68 192.168.123.68 1 #直连路由。目的地址为 192.168.123.0/24 的包发到本机 192.168.123.88 接口
192.168.123.88 255.255.255.255 127.0.0.1 127.0.0.1 1 #目的地址为 192.168.123.88的包是发给本机的包
192.168.123.255 255.255.255.255 192.168.123.88 192.168.123.88 1 #广播包的网段是 192.168.123.0/24,经过 192.168.123.88 接口发出去
224.0.0.0 224.0.0.0 192.168.123.88 192.168.123.88 1 #多播包,经过 192.168.123.88 接口发出去
255.255.255.255 255.255.255.255 192.168.123.68 192.168.123.68 1 #全网广播包
Default Gateway: 192.168.123.254各字段说明:
- destination:目的网段
- mask:与网络目标地址相关联的网掩码(又称之为子网掩码)。子网掩码对于 IP 网络地址可以是一适当的子网掩码,对于主机路由是 255.255.255.255 ,对于默认路由是 0.0.0.0。如果忽略,则使用子网掩码 255.255.255.255。定义路由时由于目标地址和子网掩码之间的关系,目标地址不能比它对应的子网掩码更为详细。换句话说,如果子网掩码的一位是 0,则目标地址中的对应位就不能设置为 1。
- interface:到达该目的地的本路由器的出口ip
- gateway: 下一跳路由器入口的 ip,路由器通过 interface 和 gateway 定义一调到下一个路由器的链路。通常情况下,interface 和 gateway 是同一网段的metric 跳数,该条路由记录的质量,一般情况下,如果有多条到达相同目的地的路由记录,路由器会采用metric值小的那条路由
主机路由:机路由是路由选择表中指向单个IP地址或主机名的路由记录。主机路由的Flags字段为H。
Destination Gateway Genmask Flags Metric Ref Use Iface
----------- ------- ------- ----- ------ --- --- -----
10.0.0.10 192.168.1.1 255.255.255.255 UH 0 0 0 eth0网络路由:网络路由是代表主机可以到达的网络。网络路由的Flags字段为N。例如,在下面的示例中,本地主机将发送到网络192.19.12的数据包转发到IP地址为192.168.1.1的路由器。
Destination Gateway Genmask Flags Metric Ref Use Iface
----------- ------- ------- ----- ----- --- --- -----
192.19.12 192.168.1.1 255.255.255.0 UN 0 0 0 eth0默认路由:当主机不能在路由表中查找到目标主机的IP地址或网络路由时,数据包就被发送到默认路由(默认网关)上。默认路由的Flags字段为G。
Destination Gateway Genmask Flags Metric Ref Use Iface
----------- ------- ------- ----- ------ --- --- -----
default 192.168.1.1 0.0.0.0 UG 0 0 0 eth0设置和查看路由表都可以用 route 命令,设置内核路由表的命令格式是:route [add|del] [-net|-host] target [netmask Nm] [gw Gw] [[dev] If]
其中:
- add : 添加一条路由规则,del : 删除一条路由规则,-net : 目的地址是一个网络,-host : 目的地址是一个主机,target : 目的网络或主机
- netmask : 目的地址的网络掩码,gw : 路由数据包通过的网关,dev : 为路由指定的网络接口
比如:
route add 0.0.0.0 mask 0.0.0.0 192.168.12.1
route add 10.41.0.0 mask 255.255.0.0 10.27.0.1 metric 7关于 src 属性:
当一个主机有多个网卡配置了多个 IP 的时候,对于它产生的网络包,可以在路由选择时设置源 IP 地址。比如:
ip route add 78.22.45.0/24 via 10.45.22.1 src 10.45.22.12 (发到 78.22.45.0/24 网段的网络包,下一跳的路由器 IP 是 10.45.22.1,包的源IP地址设为10.45.22.12)。要注意的是,src 选项只会影响该 host 上产生的网络包。如果是一个被路由的外来包,明显地它已经带有了一个源 IP 地址,这时候,src 参数的配置对它没有任何影响,除非你使用 NAT 来改变它。对 Neutron 来说,qrouter 和 qif namespace 中的路由表中的 src 都没有实际意义,因为它们只会处理外来的网络包。
1.1.3 路由分类之静态路由
静态路由是指由用户或网络管理员手工配置的路由信息。当网络的拓扑结构或链路的状态发生变化时,网络管理员需要手工去修改路由表中相关的静态路由信息。静态路由信息在缺省情况下是私有的,不会传递给其他的路由器。当然,网管员也可以通过对路由器进行设置使之成为共享的。静态路由一般适用于比较简单的网络环境,在这样的环境中,网络管理员易于清楚地了解网络的拓扑结构,便于设置正确的路由信息。
![image]http://images0.cnblogs.com/blog2015/697113/201508/111608091458962.jpg)
以上面的拓扑结构为例,在没有配置路由的情况下,计算机1 和 2 无法互相通信,因为 1 发给 2 的包在到达路由器 A 后,它不知道怎么转发它。B 也同样。管理员可以配置如下的静态路由来实现 1 和 2 之间的通信:
计算机配置默认网关:
计算机1 上:route add default gw 192.168.1.1
计算机2 上:route add default gw 192.168.3.1路由器配置:
R1 上:ip route 192.168.3.0 255.255.255.0 f0/1 (意思为:目标网络地址为 192.168.3.0/24 的数据包,经过 f0/1 端口发出)
R2 上:ip route 192.168.1.0 255.255.255.0 f0/1 (意思为:目标网络地址为 192.168.1.0/24 的数据包,经过 f0/1 端口发出)或者
R1 上:ip route 192.168.3.0 255.255.255.0 192.168.2.2 (意思为:要去 192.168.3.0/24 的数据包,下一路由器 IP 地址为 192.168.2.2)
R2 上:ip route 192.168.1.0 255.255.255.0 192.168.2.11.1.4 路由分类之动态路由
动态路由是指路由器能够自动地建立自己的路由表,并且能够根据实际情况的变化适时地进行调整。它是与静态路由相对的一个概念,指路由器能够根据路由器之间的交换的特定路由信息自动地建立自己的路由表,并且能够根据链路和节点的变化适时地进行自动调整。当网络中节点或节点间的链路发生故障,或存在其它可用路由时,动态路由可以自行选择最佳的可用路由并继续转发报文。
常见的动态路由协议有以下几个:路由信息协议(RIP)、OSPF(Open Shortest Path First开放式最短路径优先)、IS-IS(Intermediate System-to-Intermediate System,中间系统到中间系统)、边界网关协议(BGP)是运行于 TCP 上的一种自治系统的路由协议。
1.1.5 ip rule,ip route,iptables 三者之间的关系
以一例子来说明:公司内网要求192.168.0.100 以内的使用 10.0.0.1 网关上网 (电信),其他IP使用 20.0.0.1 (网通)上网。
- 首先要在网关服务器上添加一个默认路由,当然这个指向是绝大多数的IP的出口网关:ip route add default gw 20.0.0.1
- 之后通过 ip route 添加一个路由表:ip route add table 3 via 10.0.0.1 dev ethX (ethx 是 10.0.0.1 所在的网卡, 3 是路由表的编号)
- 之后添加 ip rule 规则:ip rule add fwmark 3 table 3 (fwmark 3 是标记,table 3 是路由表3 上边。 意思就是凡事标记了 3 的数据使用 table3 路由表)
- 之后使用 iptables 给相应的数据打上标记:iptables -A PREROUTING -t mangle -i eth0 -s 192.168.0.1 - 192.168.0.100 -j MARK --set-mark 3 因为 mangle 的处理是优先于 nat 和 fiter 表的,所以在数据包到达之后先打上标记,之后再通过 ip rule 规则,对应的数据包使用相应的路由表进行路由,最后读取路由表信息,将数据包送出网关。
 这里可以看出 Netfilter 处理网络包的先后顺序:接收网络包,先 DNAT,然后查路由策略,查路由策略指定的路由表做路由,然后 SNAT,再发出网络包。
这里可以看出 Netfilter 处理网络包的先后顺序:接收网络包,先 DNAT,然后查路由策略,查路由策略指定的路由表做路由,然后 SNAT,再发出网络包。
1.1.6 Traceroute 工具
我们在 linux 机器上,使用 traceroute 来获知从你的计算机到互联网另一端的主机是走的什么路径。当然每次数据包由某一同样的出发点(source)到达某一同样的目的地(destination)走的路径可能会不一样,但基本上来说大部分时候所走的路由是相同的。在 MS Windows 中该工具为 tracert。 在大多数情况下,我们会在linux主机系统下,直接执行命令行:traceroute hostname;而在Windows系统下是执行tracert的命令: tracert hostname。
命令格式:traceroute [参数] [主机]
命令功能:traceroute 指令让你追踪网络数据包的路由途径,预设数据包大小是 40Bytes,用户可另行设置。
具体参数格式:traceroute [-dFlnrvx][-f<存活数值>][-g<网关>...][-i<网络界面>][-m<存活数值>][-p<通信端口>][-s<来源地址>][-t<服务类型>][-w<超时秒数>][主机名称或IP地址][数据包大小]
命令参数:
-d 使用Socket层级的排错功能,-f 设置第一个检测数据包的存活数值TTL的大小,-F 设置勿离断位,-g 设置来源路由网关,最多可设置8个,-i 使用指定的网络界面送出数据包,-I 使用ICMP回应取代UDP资料信息,-m 设置检测数据包的最大存活数值TTL的大小,-n 直接使用IP地址而非主机名称。
-p 设置UDP传输协议的通信端口,-r 忽略普通的Routing Table,直接将数据包送到远端主机上,-s 设置本地主机送出数据包的IP地址,-t 设置检测数据包的TOS数值。
-v 详细显示指令的执行过程,-w 设置等待远端主机回报的时间,-x 开启或关闭数据包的正确性检验。[root@localhost ~]# traceroute www.baidu.com
traceroute to www.baidu.com (61.135.169.125), 30 hops max, 40 byte packets
192.168.74.2 (192.168.74.2) 2.606 ms 2.771 ms 2.950 ms
211.151.56.57 (211.151.56.57) 0.596 ms 0.598 ms 0.591 ms
211.151.227.206 (211.151.227.206) 0.546 ms 0.544 ms 0.538 ms
210.77.139.145 (210.77.139.145) 0.710 ms 0.748 ms 0.801 ms
202.106.42.101 (202.106.42.101) 6.759 ms 6.945 ms 7.107 ms
61.148.154.97 (61.148.154.97) 718.908 ms * bt-228-025.bta.net.cn (202.106.228.25) 5.177 ms
124.65.58.213 (124.65.58.213) 4.343 ms 4.336 ms 4.367 ms
202.106.35.190 (202.106.35.190) 1.795 ms 61.148.156.138 (61.148.156.138) 1.899 ms 1.951 ms
* * *
* * *说明:
记录按序列号从1开始,每个纪录就是一跳 ,每跳表示一个网关,我们看到每行有三个时间,单位是 ms,其实就是 -q 的默认参数。 探测数据包向每个网关发送三个数据包后,网关响应后返回的时间;如果您用 traceroute -q 4 www.58.com ,表示向每个网关发送4个数据包。 有时我们 traceroute 一台主机时,会看到有一些行是以星号表示的。出现这样的情况,可能是防火墙封掉了ICMP 的返回信息,所以我们得不到什么相关的数据包返回数据。 有时我们在某一网关处延时比较长,有可能是某台网关比较阻塞,也可能是物理设备本身的原因。当然如果某台 DNS 出现问题时,不能解析主机名、域名时,也会 有延时长的现象;您可以加-n 参数来避免DNS解析,以IP格式输出数据。 如果在局域网中的不同网段之间,我们可以通过 traceroute 来排查问题所在,是主机的问题还是网关的问题。如果我们通过远程来访问某台服务器遇到问题时,我们用到traceroute 追踪数据包所经过的网关,提交IDC服务商,也有助于解决问题;但目前看来在国内解决这样的问题是比较困难的,就是我们发现问题所在,IDC服务商也不可能帮助我们解决。
二、Neutron 的传统和 DVR Router
2.1 传统(Legacy) Router
Neutron 对虚拟三层网络的实现是通过其 L3 Agent (neutron-l3-agent)。该 Agent 利用 Linux IP 栈、route 和 iptables 来实现内网内不同网络内的虚机之间的网络流量,以及虚机和外网之间网络流量的路由和转发。为了在同一个Linux 系统上支持可能的 IP 地址空间重叠,它使用了 Linux network namespace 来提供隔离的转发上下文。
2.1.1 基础知识
2.1.1.1 Linux network namespace
在二层网络上,VLAN 可以将一个物理交换机分割成几个独立的虚拟交换机。类似地,在三层网络上,Linux network namespace(netns) 可以将一个物理三层网络分割成几个独立的虚拟三层网络。
Network namespace (netns)从 Linux 2.6.24 版本开始添加,直到 2.6.29 添加完成。每个 netns 拥有独立的 (virtual)network devices, IP addresses, IP routing tables, /proc/net directory, ports 等等。新创建的 netns 默认只包含 loopback device。除了这个设备,每个 network device,不管是物理的还是虚拟的网卡还是网桥等,都只能存在于一个 netns。而且,连接物理硬件的物理设备只能存在于 root netns。其它普通的网络设备可以被创建和添加到某个 netns。
使用 ip 命令来操作 netns。
#添加 network namespace
ip netnas add <network namespace name>
#Example:
ip netns add nstest
#列表所有 netns
ip netns list
#删除某 netns
ip netns delete <network namespace name>
#在 network namespace 中运行命令
ip netns exec <network namespace name> <command>
#Example using the namespace from above:
ip netns exec nstest ip addr
#添加 virtual interfaces 到 network namespace
ip link add veth-a type veth peer name veth-b #创建一对虚拟网卡veth-a 和 veth-b,两者由一根虚拟网线连接
#将 veth-b 添加到 network namespace
ip link set veth-b netns nstest
#设置 VI 的 IP 地址
#defaut namespace 中
ip addr add 10.0.0.1/24 dev veth-a
ip link set dev veth-a up
# namespace nstest 中
ip netns exec nstest ip addr add 10.0.0.2/24 dev veth-b
ip netns exec nstest ip link set dev veth-b up
#互通
# ping 10.1.1.1
PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data.
bytes from 10.1.1.1: icmp_seq=1 ttl=64 time=0.087 ms
# ip netns exec netns1 ping 10.1.1.2
PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data.
bytes from 10.1.1.2: icmp_seq=1 ttl=64 time=0.054 ms
#查看路由表和 iptbales
# ip netns exec netns1 route
# ip netns exec netns1 iptables -L2.1.1.2 namespace 间的通信
(1)一种简单的方式是使用 Linux veth pair 来实现两个 network namespace 之间的通信:
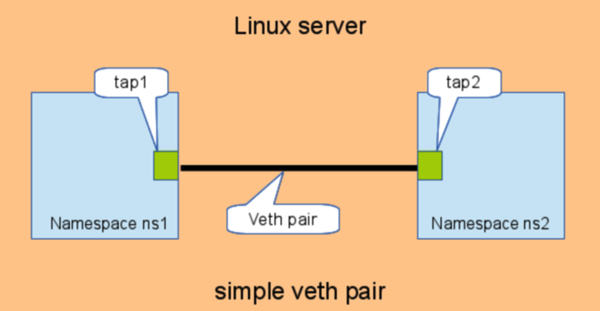 (2)当有两个以上的 network namespace 之间需要通信时,需要使用一个虚机交换机,和两个 veth pair。传统的方式是 Linux bridge:
(2)当有两个以上的 network namespace 之间需要通信时,需要使用一个虚机交换机,和两个 veth pair。传统的方式是 Linux bridge:
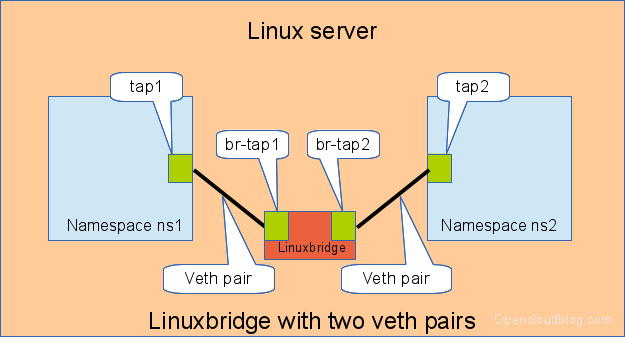
你也可以使用 Open vSwitch:
(3)再一种方式是使用 Open vSwitch 和 OVS internal ports:
veth (irtual Ethernet interfaces) 设备:这是一种成对出现的特殊网络设备,它们象一根管道一样连接在一起。VETH 设备总是成对出现,送到一端请求发送的数据总是从另一端以请求接受的形式出现。该设备不能被用户程序直接操作,但使用起来比较简单。创建并配置正确后,向其一端输入数据,VETH 会改变数据的方向并将其送入内核网络核心,完成数据的注入。在另一端能读到此数据。
关于几种方式的性能比较,这篇文章也给出了它的测试结论:
- 使用 OVS patch ports:性能更好
- 不要使用 Linux veth pairs:它会带来明显的性能下降 在 Neutron 中,可以使用配置项 ovs_use_veth 来配置是否使用 veth,默认为 false,表示默认使用 OVS internal port。
2.1.1.3 iptables基础
netfilter/iptables(简称为iptables)组成 Linux 平台下的包过滤防火墙。其中,iptables 是一个 linux 用户空间(userspace)模块,位于/sbin/iptables,用户可以使用它来操作防火墙表中的规则。真正实现防火墙功能的是 netfilter,它是一个 linux 内核模块,做实际的包过滤。实际上,除了 iptables 以外,还有很多类似的用户空间工具。
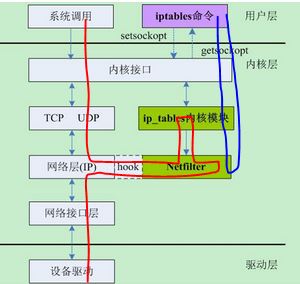
- Netfilter 是一套数据包过滤框架,在处理 IP 数据包时 hook 了5个关键钩子。通过这5个关键点来实现各种功能,比如firewall/ips。
- ip_tables 是真正的内核防火墙模块,通过把自己的函数注入到 Netfilter 的框架中来实现的防火墙功能.
- Netfilter 提供了最基本的底层支撑,具体的功能实现只要注册自己的函数就可以了,这样保证了协议栈的纯净与可扩展性.通过上图可以看出 netfilter 与 iptables是分离的.
- 数据包从左边进入IP协议栈,进行 IP 校验以后,数据包被第一个钩子函数 PRE_ROUTING 处理。
- 然后就进入路由模块,由其决定该数据包是转发出去还是送给本机。
- 若该数据包是送给本机的,则要经过钩子函数 LOCAL_IN 处理后传递给本机的上层协议;若该数据包应该被转发,则它将被钩子函数 FORWARD 处理,然后还要经钩子函数 POST_ROUTING 处理后才能传输到网络。
- 本机进程产生的数据包要先经过钩子函数 LOCAL_OUT 处理后,再进行路由选择处理,然后经过钩子函数POST_ROUTING处理后再发送到网络。
netfilter 使用表(table)和 链(chain)来组织网络包的处理规则(rule)。它默认定义了以下表和链:

- PREROUTING Hook 依次调用 Managle 和 Nat 的 PREOUTING 链中的规则来处理网络包
- LOCAL_IN Hook 依次调用 MANGLE 和 Filter 的 INPUT 链中的规则来过滤网络包
- LOCAL_OUT Hook 依次调用 Mangle,Nat,Filter 表的 Output 链中的规则来过滤网络包
- FORWARD Hook 依次调用 Mangle 和 Filter 表的 FORWARD 链中的规则来过滤网络包
- POST_ROUTING Hook 依次调用 Managle 和 Nat 表的 POSTROUTING 链中的规则来处理网络包
对 Neutron Virtual Router 所使用的 filter 表来说,它的三个链 INPUT, FORWARD, 和 OUTPUT 是分开的。一个数据包,根据其源和目的地址,只能被其中的某一个处理。
- 如果数据包的目的地址是本机,那它被 INPUT 处理。
- 如果数据包的源地址是本机,那它被 OUTPUT 处理。
- 如果源地址和目的地址都是别的机器,那它被 FORWARD 链处理。
图中的 ”路由判断“ 即判断包的目的地址。如果目的地址不是本机的地址,那它就是需要被路由的包;如果目的地址是本机的,那么被filter 的 INPUT 处理后,被主机的某个程序处理。该程序如果需要发回响应包的话,其源地址肯定是本机的,所有它会被 filter 的 OUTPUT 链处理。该包不一定会出网卡,因为可能会走 loopback,它又会回到本机,重新走封包进入的过程。
iptables 是一个 CLI 类型的 Linux 用户空间工具,它使得系统管理员能够配置netfile 表(tables)中的链和规则。Linux 使用不同的内核模块和应用来管理不同的网络协议iptable 适用于 ipv4,ip6tables 适用于 ipv6,arptables 适用于 ARP,ebtables 适用于网络帧。iptales 需要管理员权限。
规则(rules)其实就是网络管理员预定义的条件,规则一般的定义为“如果数据包头符合这样的条件,就这样处理这个数据包”。规则存储在内核空间的信息包过滤表中,这些规则分别指定了源地址、目的地址、传输协议(如TCP、UDP、ICMP)和服务类型(如HTTP、FTP和SMTP)等。当数据包与规则匹配时,iptables就根据规则所定义的方法来处理这些数据包,如放行(accept)、拒绝(reject)和丢弃(drop)等。配置防火墙的主要工作就是添加、修改和删除这些规则。
操作 iptables 服务:
/etc/init.d/iptables start/stop/restart2.1.1.4 iptables操作
iptables 各命令选项:
- -p, --protocol protocol: tcp, udp, udplite, icmp, esp, ah, sctp 之一
- -s, --source address[/mask] a network name, a hostname, a network IP address (with /mask), or a plain IP address.
- -d, --destination address[/mask][,...]:同 -s
- -j, --jump target:match 后的 target。
- -g, --goto chain
- [!] -i, --in-interface name:连接进来的 interface 名称。!表示否。
- [!] -o, --out-interface name
- 其中 -j:
当数据包进入后,会依次比照 iptables 中的每条规则,直到有一条规则可以对该报文进行匹配,这时该报文将被执行"ACCEPT","DORP","REJECT" 或者其它动作,除 REDIRECT 外,执行完后停止跟余下的 iptables 规则匹配。
- -ACCEPT: 将封包放行,进行完此处理动作后,将不再比对其它规则,直接跳往下一个规则链。
- -REJECT: 拦阻该封包,并传送封包通知对方。
- -DROP: 丢弃封包不予处理,进行完此处理动作后,将不再比对其它规则,直接中断过滤程序。
- -DNAT:DNAT 改写封包目的地 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将会直接跳往下一个规则链。
- -REDIRECT: 将封包重新导向到另一个端口(PNAT),进行完此处理动作后,将会继续比对其它规则。
- -SNAT: 改写封包来源 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将直接跳往下一个规则链。
- -RETURN:中断当前链,返回调用链或者默认的policy。
一些例子:
- iptables -A INPUT -s 10.10.10.10 -j DROP #丢弃从 10.10.10.10 主机来的所有包
- iptables -A INPUT -s 10.10.10.0/24 -j DROP #丢弃从 10.10.10.0/24 网段进来所有包
- iptables -A INPUT -p tcp --dport ssh -s 10.10.10.10 -j DROP # 如果协议是 tcp,目标端口是 ssh 端口,源IP 为 10.10.10.10,那么丢弃它
- iptables -A INPUT -i virbr0 -p udp -m udp --dport 53 -j ACCEPT #接受从 virbr0 进来的所有目标端口 53 的 udp 包
- iptables -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT #接受 RELEASED 和 ESTABLISHED 状态的连接。Linux 3.7 以后,--state 被替换成了 --conntrack
- iptables -A FORWARD -d 192.168.122.0/24 -o virbr0 -m state --state RELATED,ESTABLISHED -j ACCEPT #转发时接受这些包
- iptables -A FORWARD -p icmp -j ACCEPT #转发时接受所有 ICMP 路由包。
- iptables -A INPUT -i lo -j ACCEPT #使用 -i 过滤从 lo 设备进来的包
- iptables -A INPUT -i eth0 -j ACCEPT #使用 -i 过滤从网卡 eth0 进来的包。不指定网卡的话表示所有网卡
封包过滤实现的是针对安全方面的策略,通常我们遵循“凡是没有明确允许的都是禁止的”这样的原则来设计安全策略:首先禁止所有的东西,然后根据需要再开启必要的部分。 Neutron 主要用到 filter 表和 nat 表,其中, filter 用来实现安全组(Security Group)和 防火墙(FWaas);nat 主要用来实现 router
2.1.1.5 iptables之nat
可以使用 iptables nat 表来实现网络地址转换(NAT)。NAT 包括 SNAT (源地址转换)和 DNAT (目的地址转换)。两者的区别在于做地址转换是在路由前还是路由后: (1)SNAT:路由 - 转换 - 发出
- 封包先经过 PREROUTING,检查目的 IP 是不是本网段的地址。是的话,走路径A。
- 如果不是,则开始查询路由表,查找到相应路由条目后(查找路由的过程在 PREROUTING 和 FORWARD 之间),经过 FORWARD 链进行转发,再通过 postrouting 时进行NAT转换。 从这里可以看出,SNAT转换的步骤在 POSTROUTING 链上实现, PREROUTING 只是用来做路由选择。因此,要做 SNAT 的话,需要添加 POSTROUTING 规则,使用 “-j SNAT -to-source”。比如:
iptables -t nat -A POSTROUTING -s 192.168.252.0/24 -j SNAT -to-source 100.100.100.1(2)DNAT:转换 - 路由- 发出
DNAT 的功能正好和 SNAT 相反,源地址不变,目的地址发生改变。DNAT 可以用作 PNAT,可以将一个 IP 的端口转换成另一个IP的另外一个端口号,经常用于内网服务器映射到公网,用来隐藏服务器的真实地址。DNAT 的具体数据流向:
- 在 DNAT 中,NAT 是在 PREROUTING 上做的。在数据进入主机后,路由选择过程是在 PREROUTING 和 FORWARD 之间的,所以应该先做地址转换之后,再进行路由选择,而后经过 FORWARD,最后从 POSTROUTING 出去。
- 因此,要做 DNAT,需要添加 PREROUTING 规则,使用 “-j DNAT --to-destination”。比如:
iptables -t nat -A PREROUTING -d 100.100.100.1 -p tcp --dport 80 -j DNAT --to-destination 192.168.252.1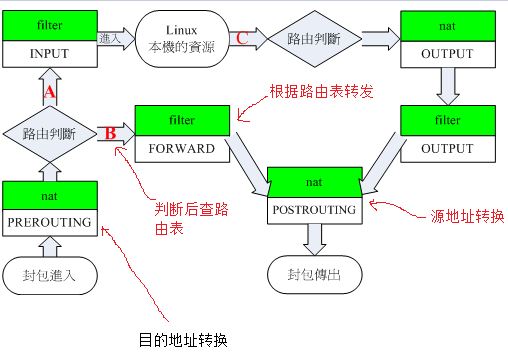
有一类比较特殊的 DNAT 是使用 “-j REDIRECT” 做端口号转换:
## Send incoming port-80 web traffic to our squid (transparent) proxy
iptables -t nat -A PREROUTING -i eth1 -p tcp --dport 80-j REDIRECT --to-port 31282.1.1.6 route (Linux 路由表)
Linux 系统的 route 命令用于显示和操作 IP 路由表,它的主要作用是创建一个静态路由来指定一个主机或者一个网络通过一个网络接口,如eth0。
route [-CFvnee]
route [-v] [-A family] add [-net|-host] target [netmask Nm] [gw Gw] [metric N] [mss M] [window W] [irtt I] [reject] [mod] [dyn] [rein-
state] [[dev] If]
route [-v] [-A family] del [-net|-host] target [gw Gw] [netmask Nm] [metric N] [[dev] If]
例子:
route add -net 224.0.0.0 netmask 240.0.0.0 dev eth0 #增加一条经过 eth0 到达 244.0.0.0 的路由
route add -net 224.0.0.0 netmask 240.0.0.0 reject #增加一条屏蔽的路由,目的地址为224.x.x.x将被拒绝。
route del -net 224.0.0.0 netmask 240.0.0.0
route del -net 224.0.0.0 netmask 240.0.0.0 reject
route del default gw 192.168.120.240
route add default gw 192.168.120.2402.1.1.7 路由器的辅助(Secondary) IP
先来看一个 Virutal Router 的 interface 的 ip 配置:
42: qg-3c8d6a68-97: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether fa:16:3e:2e:5b:23 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.110/24 brd 192.168.1.255 scope global qg-3c8d6a68-97
valid_lft forever preferred_lft forever
inet 192.168.1.104/32 brd 192.168.1.104 scope global qg-3c8d6a68-97
valid_lft forever preferred_lft forever
inet6 fe80::f816:3eff:fe2e:5b23/64 scope link
valid_lft forever preferred_lft forever<BROADCAST,UP,LOWER_UP>:端口的各种状态
UP: device is functioning (enabled 状态,可通过 ip * up/down 设置。)
BROADCAST: device can send traffic to all hosts on the link (能够发广播)
MULTICAST: device can perform and receive multicast packets (能够发多播)
ALLMULTI: device receives all multicast packets on the link (能够接收多播)
PROMISC: device receives all traffic on the link (接收所有的traffic)
LOWER_UP:the state of the Ethernet link(表示线已接上)inet/brd/scope:IP 地址及子网掩码,广播地址,作用域
注意到这个interface有两个静态 IP 地址。第一个是主要的(primary)IP,第二个是辅助的( secondary) 的 IP。当一个网卡配置了静态IP后,你可以添加secondary IP 给它。这样它就拥有了多个 IP 地址了。Secondary IP 不可以通过 DHCP 分配。它所有的IP 地址都关联到它唯一的一个 MAC 地址上。那为什么需要 secondary IP 地址呢? 路由器有个 Secondary IP 的概念,这个特性可以创建逻辑子网,也就是说在一个物理网口上连接两个子网,比如这个网口接到一台交换机上,如 果这个网口没有配置Secondary IP的话,那么这台交换机只能连接一个网段的主机,比如 192.168.1.1/24,但是,如果它配置了Secondary IP,那么就可以连接两个网段的主机,比如 192.168.1.1/24 和 10.0.0.1/24。
#增加 secondary IP
ip netns exec qrouter-e438bebe-6795-4b68-a613-ec0df38d3064 ip a add dev qg-3c8d6a68-97 192.168.1.105/32 brd 192.168.1.105
ip addr add dev veth-a 1.1.1.1/24 # 增加secondary ip地址
#删除 secondar IP
ip netns exec qrouter-e438bebe-6795-4b68-a613-ec0df38d3064 ip addr del 192.168.1.104/32 dev qg-3c8d6a68-972.1.1.8 Gratuitous ARP
Gratuitous ARP也称为 免费ARP,无故ARP。Gratuitous ARP不同于一般的ARP请求,它并非期待得到IP对应的MAC地址,而是当主机启动的时候,将发送一个Gratuitous arp请求,即请求自己的IP地址的MAC地址。它常用于三个用途:
- Change of L2 address:通告自己改变了 MAC 地址。以 ARP Response 的形式发送广播,它通常只是为了把自己的ARP信息通告/更新给局域网全体,这种Response不需要别人请求,是自己主动发送的通告。报文结构如下当一个网络设备的 MAC 地址发生改变时,发送该设备的 Gratuitous ARP,通知所在广播域内的已经包含该 IP 地址在其 ARP 表中的机器去更新它的 ARP 条目。
- Duplicate address detection:重复 MAC 地址检测。以 ARP Request的形式发送广播,请求自己的MAC地址,目的是探测局域网中是否有跟自己IP地址相同的主机,也就是常说的IP冲突。发送主机并不需要一定收到此请求的回答。如果收到一个回答,表示网络中存在与自身IP相同的主机。如果没有收到应答,则表示本机所使用的IP与网络中其它主机并不冲突。
- Virtual IP:用于一组服务器做 failover 时通知周围的机器新生效的 IP 地址的 MAC。
s1@controller:~$ arp
Address HWtype HWaddress Flags Mask Iface
192.168.1.104 ether fa:16:3e:2e:5b:23 C eth0 # floating ip地址
192.168.1.110 ether fa:16:3e:2e:5b:23 C eth0 # floating ip地址
192.168.1.111 ether fa:16:3e:2e:5b:23 C eth0 # floating ip地址2.1.2 非DVR Neutron L3 Agent 的实现原理
每个 L3 Agent 运行在一个 network namespace 中,每个 namespace 由 qrouter-<router-UUID>命名,比如 qrouter-e506f8fe-3260-4880-bd06-32246225aeae。网络节点如果不支持 Linux namespace 的话,只能运行一个 Virtual Router。也可以通过设置配置项 use_namespaces = True/False 来使用或者不使用 namespace。
Neutron L3 Agent 负责路由(routing)、浮动 IP 分配(floatingip allocation), 地址转换(SNAT/DNAT)和 Security Group 管理(Blueprint 在这里。在后面的文章中打算和 Nova 中的 Security Group 一起分析)。
Router 作为浮动 IP 地址的ARP Proxy
虚机的浮动 IP 其实不是真实网卡的 IP 地址,而是一个虚拟的地址。那么,使用浮动 IP 和虚机通信的机器怎么获得 MAC 地址呢?Router 在这个过程中作为一个 ARP Proxy,其 IP 协议栈会向 ARP 广播请求回应浮动 IP 对应所在的外部端口的 MAC 地址。下面的例子中,该 router 挂接的子网内有两个浮动 IP,L3 Agent 都将它们添加到 Router 的外部端口 qg-3c8d6a68-97 上:
42: qg-3c8d6a68-97: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether fa:16:3e:2e:5b:23 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.110/24 brd 192.168.1.255 scope global qg-3c8d6a68-97
valid_lft forever preferred_lft forever
inet 192.168.1.104/32 brd 192.168.1.104 scope global qg-3c8d6a68-97
valid_lft forever preferred_lft forever
inet 192.168.1.111/32 brd 192.168.1.111 scope global qg-3c8d6a68-97
valid_lft forever preferred_lft forever
inet6 fe80::f816:3eff:fe2e:5b23/64 scope link
valid_lft forever preferred_lft forever这么做的目的,由于外网中的机器和虚机浮动 IP 是同一个网段的,外网中的机器通过浮动 IP 访问虚机之前,需要通过 ARP 获取该浮动 IP 的 MAC 地址。浮动IP 其实是个虚机IP,没有对应一个网络设备,因此,Neutron 将它们添加到 external port 上,共享 external port 的 MAC 地址。这样,在 router network namespace IP 协议栈收到 ARP 广播后,就可以该 IP 对应 的 MAC 地址,然后外网中的虚机就会使用该 MAC 作为目的 MAC 地址直接向 router 的 external port 端口发送网络帧。查询外网机器的 arp table,即可看到 192.168.1.104 的 MAC 为 qg-3c8d6a68-97 的 MAC 地址。也就是说,外部端口上的所有 IP 的 MAC 地址都相同。这时候,其实 router 充当了一个 ARP Proxy 的角色。
Router
一个 Virtual Router 连接几个 subnet 就会有几个 virtual interface。每个 interface 的地址是该 subnet 的 gateway 地址。比如:
root@network:/home/s1# ip netns exec qrouter-e438bebe-6795-4b68-a613-ec0df38d3064 ip addr
33: qr-2aa928c9-e8: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default #IP 设为它连接的子网的 Gateway IP
link/ether fa:16:3e:90:e5:50 brd ff:ff:ff:ff:ff:ff
inet 91.1.180.1/24 brd 91.1.180.255 scope global qr-2aa928c9-e8
37: qr-a5c6ed86-c1: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether fa:16:3e:87:40:f3 brd ff:ff:ff:ff:ff:ff
inet 81.1.180.1/24 brd 81.1.180.255 scope global qr-a5c6ed86-c1
48: qg-3c8d6a68-97: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether fa:16:3e:2e:5b:23 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.110/24 brd 192.168.1.255 scope global qg-3c8d6a68-97L3 Agent 在启动时设置如下的路由规则:
root@network:/home/s1# ip netns exec qrouter-e438bebe-6795-4b68-a613-ec0df38d3064 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.1.1 0.0.0.0 UG 0 0 0 qg-3c8d6a68-97
81.1.180.0 0.0.0.0 255.255.255.0 U 0 0 0 qr-a5c6ed86-c1 #到哪个网段的traffic发到相应的 interface
91.1.180.0 0.0.0.0 255.255.255.0 U 0 0 0 qr-2aa928c9-e8
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 qg-3c8d6a68-97虚机的 IP 栈在发现数据包的目的虚机的 IP 地址不在自己网段的话,会将其发到 Router 上对应其 subnet 的 Virtual Interface。然后,Virtual Router 根据配置的路由规则和目的IP地址,将包转发到目的端口发出。
源地址转换 SNAT
在没有设置浮动 IP 时,当主机访问外网时,需要将主机的固定 IP 转换成外网网段的 gateway 的 IP 地址,以免暴露内部 IP 地址。其做法是 Neutron 在 iptables 表中增加了 POSTROUTING 链。
root@network:/home/s1# ip netns exec qrouter-e438bebe-6795-4b68-a613-ec0df38d3064 iptables -t nat -S
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
-N neutron-l3-agent-OUTPUT #Neutorn 增加的 chain
-N neutron-l3-agent-POSTROUTING #Neutorn 增加的 SNAT chain
-N neutron-l3-agent-PREROUTING
-N neutron-l3-agent-float-snat #Neutorn 增加的 SNAT chain
-N neutron-l3-agent-snat #Neutorn 增加的 SNAT chain
-N neutron-postrouting-bottom #Neutorn 增加的 SNAT chain
-A PREROUTING -j neutron-l3-agent-PREROUTING
-A OUTPUT -j neutron-l3-agent-OUTPUT
-A POSTROUTING -j neutron-l3-agent-POSTROUTING #(1)将 SNAT chain 转到自定义的 neutron-l3-agent-POSTROUTING
-A POSTROUTING -j neutron-postrouting-bottom #(3)将 SNAT chain 转到自定义的 neutron-postrouting-bottom
-A neutron-l3-agent-POSTROUTING ! -i qg-3c8d6a68-97 ! -o qg-3c8d6a68-97 -m conntrack ! --ctstate DNAT -j ACCEPT #(2)如果出口或者入口不是 qg-3c8d6a68-97 并且状态不是 DNAT 的都接受
-A neutron-l3-agent-snat -j neutron-l3-agent-float-snat
-A neutron-l3-agent-snat -s 91.1.180.0/24 -j SNAT --to-source 192.168.1.110 #(5)将 91.1.180.0/24 网段的IP 转为 192.168.1.110
-A neutron-l3-agent-snat -s 81.1.180.0/24 -j SNAT --to-source 192.168.1.110 #(5)将 91.1.180.0/24 网段的IP 转为 192.168.1.110
-A neutron-postrouting-bottom -j neutron-l3-agent-snat #(4)再转到 neutron-l3-agent-snat实验
- 在 router 的连接 81.1.180.12 网段 interface 上:
root@network:/home/s1# ip netns exec qrouter-e438bebe-6795-4b68-a613-ec0df38d3064 tcpdump -envi qr-a5c6ed86-c1 -vvv
tcpdump: listening on qr-a5c6ed86-c1, link-type EN10MB (Ethernet), capture size 65535 bytes
^C17:42:48.904820 fa:16:3e:2b:3e:2a > fa:16:3e:87:40:f3, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 64, id 28892, offset 0, flags [DF], proto ICMP (1), length 84)
81.1.180.12 > 192.168.1.15: ICMP echo request, id 32769, seq 0, length 64
17:42:48.906601 fa:16:3e:87:40:f3 > fa:16:3e:2b:3e:2a, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 24799, offset 0, flags [none], proto ICMP (1), length 84)
192.168.1.15 > 81.1.180.12: ICMP echo reply, id 32769, seq 0, length 64
17:42:49.906238 fa:16:3e:2b:3e:2a > fa:16:3e:87:40:f3, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 64, id 28893, offset 0, flags [DF], proto ICMP (1), length 84)2、 在 route 的连接 192.168.1.15 网段 interface 上
root@network:/home/s1# ip netns exec qrouter-e438bebe-6795-4b68-a613-ec0df38d3064 tcpdump -envi qg-3c8d6a68-97 -vvv
tcpdump: listening on qg-3c8d6a68-97, link-type EN10MB (Ethernet), capture size 65535 bytes
^C17:44:47.661916 fa:16:3e:2e:5b:23 > 08:00:27:c7:cf:ca, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 63, id 28896, offset 0, flags [DF], proto ICMP (1), length 84)
192.168.1.110 > 192.168.1.15: ICMP echo request, id 33281, seq 0, length 64
17:44:47.663300 08:00:27:c7:cf:ca > fa:16:3e:2e:5b:23, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 64, id 36308, offset 0, flags [none], proto ICMP (1), length 84)
192.168.1.15 > 192.168.1.110: ICMP echo reply, id 33281, seq 0, length 64可见在外网网段的 interface 收到数据包之前,SRC IP 已经被替换成了外网网段的 Gateway IP 了。
目的地址转换 DNAT
要使外网内的机器能访问虚机,需要设置虚机的浮动IP。浮动 IP 在 Virtual Router 连接的 external network 的 subnet 内分配。注意浮动 IP 只有在 Virtual Router 上配置了 External network subnet gateway 才有意义。
每个浮动 IP 唯一对应一个 Router:浮动IP -> 关联的 Port -> 所在的 Subnet -> 包含该 subnet 以及 external subnet 的 Router。创建浮动 IP 时,在 Neutron 完成数据库操作来分配浮动IP后,它通过 RPC 来通知该浮动IP对应的 router 去设置该浮动IP对应的 iptables 规则。上面的例子中,固定IP 为 ‘192.168.10.26’ 的虚机可以在外网中使用浮动 IP ‘10.8.127.11’ 来访问了。
外网访问虚机时,目的 IP 地址为虚机的浮动 IP 地址,因此,必须由 iptables 将其转化为固定 IP 地址,然后再将它路由到虚机。我们需要关注的是 iptables 的 nat 表的 PREOUTING chain:
root@network:/home/s1# ip netns exec qrouter-e438bebe-6795-4b68-a613-ec0df38d3064 iptables -t nat -S
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
-N neutron-l3-agent-OUTPUT
-N neutron-l3-agent-PREROUTING #neutron 增加的 DNAT chain
-A PREROUTING -j neutron-l3-agent-PREROUTING # DNAT 由 neutron 新增的 chain 负责处理
-A OUTPUT -j neutron-l3-agent-OUTPUT
-A neutron-l3-agent-OUTPUT -d 192.168.1.104/32 -j DNAT --to-destination #本机访问浮动IP 修改为固定 IP
-A neutron-l3-agent-PREROUTING -d 169.254.169.254/32 -p tcp -m tcp --dport 80 -j REDIRECT --to-ports 9697 #将虚机访问 metadata server 的 traffic 端口由 80 改到 9697(由配置项 metadata_port 设置,默认为 9697),那里有 application 在监听。具体内容很深,可以参考这篇文章。
-A neutron-l3-agent-PREROUTING -d 192.168.1.104/32 -j DNAT --to-destination 91.1.180.14 #到浮动IP的traffic的目的IP 换成虚机的固定 IP每个浮动 IP,增加三个规则:
-A neutron-l3-agent-PREROUTING -d <floatingip> -j DNAT --to-destination <fixedip> #从别的机器上访问虚机,DST IP 由浮动IP改为固定IP
-A neutron-l3-agent-OUTPUT -d <floatingip> -j DNAT --to <fixedip> #从本机访问虚机,Dst IP 由浮动IP该为访问固定IP
-A neutron-l3-agent-float-snat -s <fixedip> -j SNAT --to <floatingip> #虚机访问外网,将Src IP 由固定IP改为浮动IP这里可以看到当设置了浮动 IP 以后,SNAT 不在使用 External Gateway 的 IP 了,而是使用浮动 IP 。虽然 entires 依然存在,但是因为 neutron-l3-agent-float-snat 比 neutron-l3-agent-snat 靠前而得到执行。
-A neutron-l3-agent-float-snat -s 91.1.180.14/32 -j SNAT --to-source 192.168.1.104
-A neutron-l3-agent-snat -j neutron-l3-agent-float-snat
-A neutron-l3-agent-snat -s 91.1.180.0/24 -j SNAT --to-source 192.168.1.110
-A neutron-l3-agent-snat -s 81.1.180.0/24 -j SNAT --to-source 192.168.1.110
-A neutron-postrouting-bottom -j neutron-l3-agent-snatL3 Agent iptables 完整流程
该实验中使用 “ iptables -t nat -L -nv” 命令来查看每个链上匹配到的数据包数目。
虚拟机1.1.1.3 去ping 2.2.2.4
三、安装配置
3.1 控制节点配置
vim /etc/neutron/neutron.conf
[DEFAULT]
router_distributed = true
vim /etc/neutron/plugins/ml2/ml2_conf.ini
mechanism_drivers = openvswitch,l2population
extension_drivers = port_security
vim /etc/neutron/plugins/ml2/openvswitch_agent.ini
[agent]
tunnel_types = gre,vxlan
enable_distributed_routing = True
l2_population = True
arp_responder = True
vim /etc/neutron/l3_agent.ini
[DEFAULT]
interface_driver = neutron.agent.linux.interface.OVSInterfaceDriver
external_network_bridge =
agent_mode = dvr_snat
vim /etc/neutron/dhcp_agent.ini
[DEFAULT]
interface_driver = neutron.agent.linux.interface.OVSInterfaceDriver
enable_isolated_metadata = True
vim /etc/openstack-dashboard/local_settings
'enable_distributed_router': True,
# 重启控制节点neutron相关服务,重启httpd服务
openstack-service restart neutron
systemctl restart httpd3.2 计算节点配置
yum install openstack-neutron -y
vim /etc/neutron/plugins/ml2/ml2_conf.ini
[ml2]
mechanism_drivers = openvswitch,l2population
vim /etc/neutron/plugins/ml2/openvswitch_agent.ini
[agent]
l2_population = True
enable_distributed_routing = True
arp_responder = True
vim /etc/neutron/l3_agent.ini
[DEFAULT]
interface_driver = openvswitch
external_network_bridge =
agent_mode = dvr
# 重启neutron相关服务
ovs-vsctl add-br br-ex
ovs-vsctl add-port br-ex ens160
ovs-vsctl set port br-ex tag=101
[root@compute01 ~]# cat /etc/sysconfig/network-scripts/ifcfg-br-ex
DEVICE=br-ex
DEVICETYPE=ovs
TYPE=OVSBridge
#TYPE=OVSIntPort
BOOTPROTO=static
IPADDR=192.168.10.104
NETMASK=255.255.255.0
GATEWAY=192.168.10.1
DNS1=218.2.135.1
DNS2=218.2.2.2
ONBOOT=yes
#OVS_OPTIONS="tag=101"
[root@compute01 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens160
TYPE=OVSPort
DEVICETYPE=ovs
OVS_BRIDGE=br-ex
NAME=ens160
DEVICE=ens160
ONBOOT=yes
openstack-service restart neutron3.3 迁移到DVR网络 迁移到 DVR 模式。使得新添加的 l3-agent 能够管理 router,(如果是先 enabled DVR,再建立网络和 router,忽略这一步),具体操作如下: 在控制节点上执行如下操作:
neutron router-update --admin_state_up=False router01
neutron router-update --distributed=True router01
neutron router-update --admin_state_up=True router01查看 router 是否已经和三个 l3-agent 对应
neutron l3-agent-list-hosting-router router01四、DVR 说明
在 Neutron 的网络环境中,跨子网的虚机通信是需要通过 Neutron 的路由器。这既包括不同子网的虚拟机之间的通信,又包括虚拟机与外网之间的通信。在 DVR 被提出之前, 由于 Neutron 的 legacy router 只会部署在网络节点上,因此会造成网络节点的流量过大,从而产生了两个问题,其一是网络节点将成为整个 Neutron 网络的瓶颈,其二是网络节点单点失败的问题。在这样的背景下,OpenStack 社区在 Juno 版本里正式引入了 DVR(Distributed Virtual Router)。DVR,顾名思义就是 Neutron 的 router 将不单单部署在网络节点上,所有启动了 Neutron L3 Agent 的节点,都会在必要时在节点上创建 Neutron router 对应的 namepsace,并更新与 DVR router 相关的 Openflow 规则,从而完成 DVR router 在该节点上的部署。在计算节点上部署了 DVR router 后,E-W 方向上的流量不再需要将数据包发送到网络节点后再转发,而是有本地的 DVR router 直接进行跨子网的转发;N-S 方向上,对于绑定了 floating IP 的虚机,其与外网通信时的数据包也将直接通过本地的 DVR router 进行转发。从而,Neutron 网络上的一些流量被分摊开,有效地减少了网络节点上的流量;通信不再必须通过网络节点,也提升了 Neutron 网络的抗单点失败的能力。
4.1 DVR 对 L3 Agent 的影响
通过使用 DVR,三层的转发(L3 Forwarding)和 NAT 功能都会被分布到计算节点上,这意味着计算节点也有了网络节点的功能。但是,DVR 依然不能消除集中式的 Virtual Router,这是为了节省宝贵的 IPV4 公网地址,所有依然将 SNAT 放在网络节点上提供(在没有floating ip 地址的情况下)。这样,计算和网络节点就看起来如下:
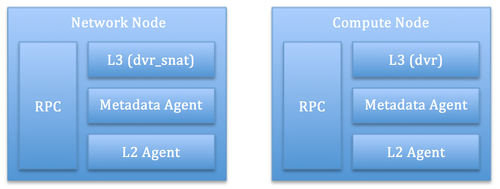
网络节点:提供 南-北 SNAT,即在不使用浮动 IP 时,虚机访问外网的网络得经过网络节点。也就是说,网络节点依然必须走传统的 HA 解决方法,比如 VRRP 和 PeaceMaker。但可惜的是,Juno 版本不支持同时使用 HA 和 DVR。 计算节点:提供 南-北 DNAT, 即外网访问虚机的网络流量得经过计算节点;以及 东-西 转发,即虚机之间的网络经过计算节点。因为所有计算节点的参与,这部分的网络处理负载也就自然地被均衡了。
4.2 DVR 对 L2 Agent 的影响
DVR 对 L2 Agent 的影响主要有:
DVR 新创建安的各个 network namespace 需要被 plug 到 OVS bridge OVS flows 需要更新来支持 DVR
4.1 E-W 方向上的虚拟机通信情况
不能网络之间数据包传递: 在非 DVR 的情况,数据是要通过网络节点才能相互传递数据包;在 DVR 的情况,数据包是直接在两个计算节点上传递。
当在虚拟机 VM1里面去 ping VM2 的 IP 的时候,数据包先转到宿主机的网桥 br-int 上,数据先传到那个和 VM1 的 port 匹配的 port 端口上,转到网关所在的那个端口,再转到 namespace 里,找到网关所在的端口,再转回 br-int,然后通过 br-int 上面的 patch-tun 端口传递到 br-tun 这个网桥上,在 br-tun 网桥上的对应的端口通过 vxlan 传递数据包到 VM2 所在的宿主机的 br-tun 上的对应端口,再通过 patch-int 传到 br-int 上的 patch-tun,通过 br-int 上的与 VM2 对应的 port 端口,把数据传递给 VM2,完成数据包的传递。简单的可以写成 vm1->br-int->namespace->br-int>br-tun->tunnel>br-tun->br-int->vm2。
4.1.1 下面演示不通计算节点之间不通网络之间的通信
1、在虚拟机配置文件中可以查看虚拟机eth0口连接的tap设备,以及tap设备所在的linuxbridge交换机。
例如id是03b3c647-a8b0-4b8d-89d8-290fbdaecfc4的配置文件
<interface type="bridge">
<mac address="fa:16:3e:25:87:ea"/>
<model type="virtio"/>
<driver name="qemu"/>
<source bridge="qbr930ad37f-32"/>
<target dev="tap930ad37f-32"/>
</interface>在计算节点使用
[root@compute01 03b3c647-a8b0-4b8d-89d8-290fbdaecfc4]# brctl show
bridge name bridge id STP enabled interfaces
qbr02fa8e4f-8d 8000.c24d83d59909 no qvb02fa8e4f-8d
tap02fa8e4f-8d
qbr1eabcbca-d4 8000.ce6dfbc236fe no qvb1eabcbca-d4
tap1eabcbca-d4
qbr930ad37f-32 8000.2e79aa6f9c52 no qvb930ad37f-32
tap930ad37f-32
qbr957f7874-7f 8000.627f99ca15fc no qvb957f7874-7f
tap957f7874-7f上面可以看到qbr930ad37f-32的2个接口其中在VM配置文件中可以知道 tap930ad37f-32 一头连接虚拟机的。从上面brctl show的结果中看到tap930ad37f-32设备的另一头是连接到qbr930ad37f-32 linux bridge中的。其中 qvb930ad37f-32也是连接到qbr930ad37f-32 linux bridge中的。
etho---tap930ad37f-32--qbr930ad37f-32--qvb930ad37f-32 下面使用 ip link | grep qvb930ad37f-32 的互联口。
[root@compute01 03b3c647-a8b0-4b8d-89d8-290fbdaecfc4]# ip link | grep qvb930ad37f-32
22: qvo930ad37f-32@qvb930ad37f-32: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1450 qdisc noqueue master ovs-system state UP mode DEFAULT qlen 1000
23: qvb930ad37f-32@qvo930ad37f-32: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1450 qdisc noqueue master qbr930ad37f-32 state UP mode DEFAULT qlen 1000可以看到qvb930ad37f-32互联口是qvo930ad37f-32。下面使用 ovs-vsctl show可以看到所述的ovs。
[root@compute01 03b3c647-a8b0-4b8d-89d8-290fbdaecfc4]# ovs-vsctl show
62251de4-bc03-4692-a65d-ff4186bfbed5
Bridge br-int
fail_mode: secure
Port int-br-ex
Interface int-br-ex
type: patch
options: {peer=phy-br-ex}
Port br-int
Interface br-int
type: internal
Port "qvo930ad37f-32" # 可以看到在br-int的ovs中,tag=3
tag: 3
Interface "qvo930ad37f-32"[root@compute01 03b3c647-a8b0-4b8d-89d8-290fbdaecfc4]# ovs-vsctl show
62251de4-bc03-4692-a65d-ff4186bfbed5
Bridge br-int
fail_mode: secure
Port int-br-ex
Interface int-br-ex
type: patch
options: {peer=phy-br-ex}
Port "qvoa41d661f-ce"
tag: 1
Interface "qvoa41d661f-ce"
error: "could not open network device qvoa41d661f-ce (No such device)"
Port br-int
Interface br-int
type: internal
Port "qvo930ad37f-32"
tag: 3
Interface "qvo930ad37f-32"
Port "qvo1eabcbca-d4"
tag: 2
Interface "qvo1eabcbca-d4"
Port "qvo02fa8e4f-8d"
tag: 2
Interface "qvo02fa8e4f-8d"
Port "fg-6cbb6e89-99"
tag: 1
Interface "fg-6cbb6e89-99"
type: internal
Port "qvo957f7874-7f"
tag: 3
Interface "qvo957f7874-7f"
Port "qr-31e1983b-9c" # 连接到计算节点路由器的namespace中
tag: 3
Interface "qr-31e1983b-9c"
type: internal
Port patch-tun
Interface patch-tun
type: patch
options: {peer=patch-int}
Port "qr-9a0d8f69-87" # 连接到计算节点路由器的namespace中
tag: 2
Interface "qr-9a0d8f69-87"
type: internal[root@compute01 ~]# ip netns exec qrouter-b6fca4c7-8e60-4bac-b53f-185b77c8e9b4 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: rfp-b6fca4c7-8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether 5e:3a:ed:7f:e6:cf brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 169.254.106.114/31 scope global rfp-b6fca4c7-8
valid_lft forever preferred_lft forever
inet6 fe80::5c3a:edff:fe7f:e6cf/64 scope link
valid_lft forever preferred_lft forever
24: qr-31e1983b-9c: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN qlen 1000
link/ether fa:16:3e:16:52:21 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.1/24 brd 10.0.0.255 scope global qr-31e1983b-9c
valid_lft forever preferred_lft forever
inet6 fe80::f816:3eff:fe16:5221/64 scope link
valid_lft forever preferred_lft forever
25: qr-9a0d8f69-87: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN qlen 1000
link/ether fa:16:3e:f6:28:37 brd ff:ff:ff:ff:ff:ff
inet 172.16.10.1/24 brd 172.16.10.255 scope global qr-9a0d8f69-87
valid_lft forever preferred_lft forever
inet6 fe80::f816:3eff:fef6:2837/64 scope link
valid_lft forever preferred_lft forever可以看到上面2个qr是链接到路由器的namespace中去的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}