
CNN(卷积神经网络)
Tensorflow 中文社区
http://www.tensorfly.cn/tfdoc/tutorials/deep_cnn.html

卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN),CNN可以有效的降低反馈神经网络(传统神经网络)的复杂性,常见的CNN结构有LeNet-5、AlexNet、ZFNet、VGGNet、GoogleNet、ResNet等等,其中在LVSVRC2015冠军 ResNet是AlexNet的20多倍,是VGGNet的8倍;从这些结构来讲CNN发展的一个方向就是层次的增加,通过这种方式可以利用增加的非线性得出目标函数的近似结构,同时得出更好的特征表达,但是这种方式导致了网络整体复杂性的增加,使网络更加难以优化,很容易过拟合。
小插曲
LeNet:最早用于数字识别的CNN
AlexNet:2012年ILSVRC比赛冠军,远超第二名的CNN,比LeNet更深,用多层小卷积叠加来替换单个的大卷积
ZF Net:2013ILSVRC冠军
GoogleNet:2014ILSVRC冠军
VGGNet:2014ILSVRC比赛中算法模型,效果率低于GoogleNet
ResNet:2015ILSVRC冠军,结构修正以适应更深层次的CNN训练
CNN 主要应用
CNN的应用主要是在图像分类和物品识别等应用场景应用比较多
CNN 主要结构

CNN-Input Layer
和神经网络/机器学习一样,需要对输入的数据需要进行预处理操作,需要进行预处理的主要原因是:
1.输入数据单位不一样,可能会导致神经网络收敛速度慢,训练时间长
2.数据范围大的输入在模式分类中的作用可能偏大,而数据范围小的作用就有可能偏小
3.由于神经网络中存在的激活函数是有值域限制的,因此需要将网络训练的目标数据映射到激活函数的值域
4·S形激活函数在(0,1)区间以外区域很平缓,区分度太小。例如S形函数f(X),f(100)与f(5)只相差0.0067
白化 (预处理) 使得学习算法的输入具有如下性质
1.特征之间相关性较低
2.所有特征具有相同的方差。
常见3种数据预处理方式
◆去均值
将输入数据的各个维度中心化到0
◆归一化
将输入数据的各个维度的幅度归一化到同样的范围
◆PCA/白化 最常用是这个
1.用PCA降维
2.白化是对数据的每个特征抽上的幅度归一化
CNN CONV Layer
卷积计算层:CONV Layer
1.局部关联:每个神经元看做一个filter
2.窗口(receptive field)滑动,filter对局部数据进行计算
3.相关概念
深度: depth
步长:stride
填充值:zero-padding
4.参数共享机制:假设每个神经元连接数据窗的权重是固定的
5.固定每个神经元的连接权重,可以将神经元看成一个模板;也就是每个神经元只关注一个特性
6.需要计算的权重个数会大大的减少
7.一组固定的权重和不同窗口内数据能内积:卷积
有关概念解释
局部关联:局部数据识别
窗口滑动:滑动预先设定步长,移动位置来得到下一个窗口
深度:转换次数(结果产生的depth)
步长:设定每一移动多少
填充值:可以再矩阵的周边添加一些扩充值(目的是解决图片输入不规整)
CONV 过程参考
http://cs231n.github.io/assets/conv-demo/index.html
CNN-ReLU Layer
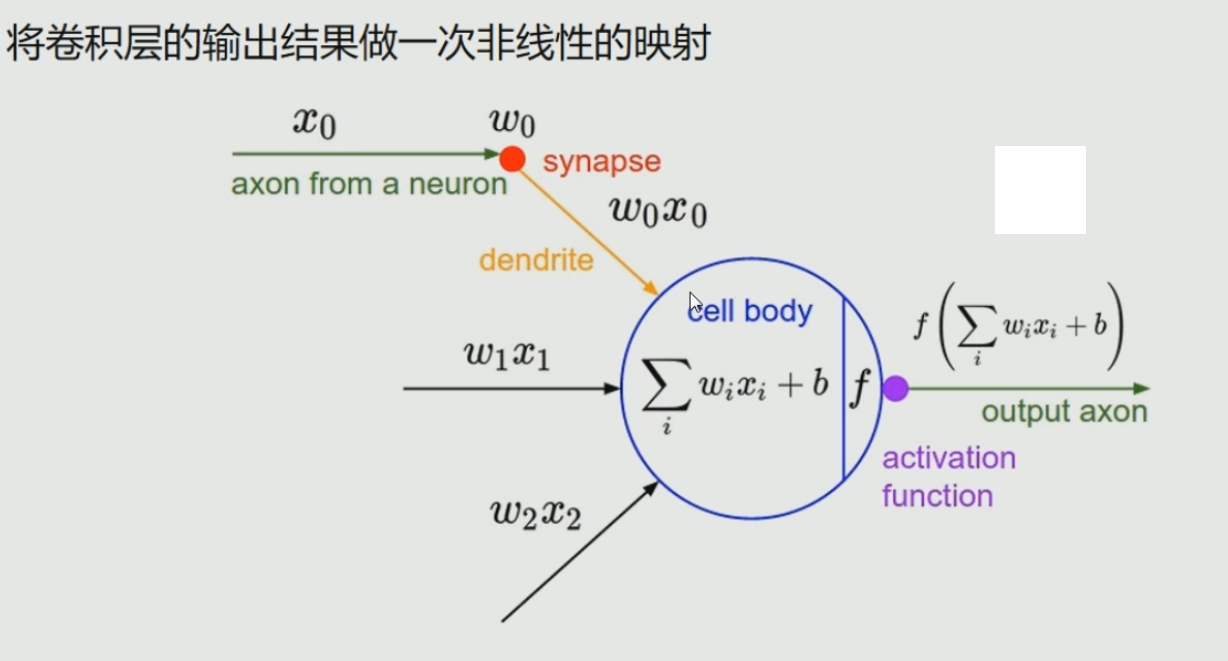
常用非线性映射函数
Sigmoid(S形函数) 用在全连接层
Tanh(双曲正切,双S形函数) 用在全链接层
ReLU 用在卷积层
Leaky ReLU
ELU 用在卷积层
Maxout
使用映射函数,来完成非线性的映射
(1)双s和s函数用于全连接层
(2)ReLu用于卷积计算层(迭代较快,只是效果不佳)
(3)普遍使用ELU
(4)Maxout:使用最大值来设置值
激励层建议
1.CNN尽量不要使用sigmoid,如果要使用,建议只在全连接层使用
2.首先使用RELU,因为迭代速度快,但是有可能效果不佳
3.如果使用RELU失效的情况下,考虑使用Leaky ReLu或者Maxout,此时一般情况都可以解决的
4.tanh激活函数在某些情况下有比较好的效果,但是应用场景比较少
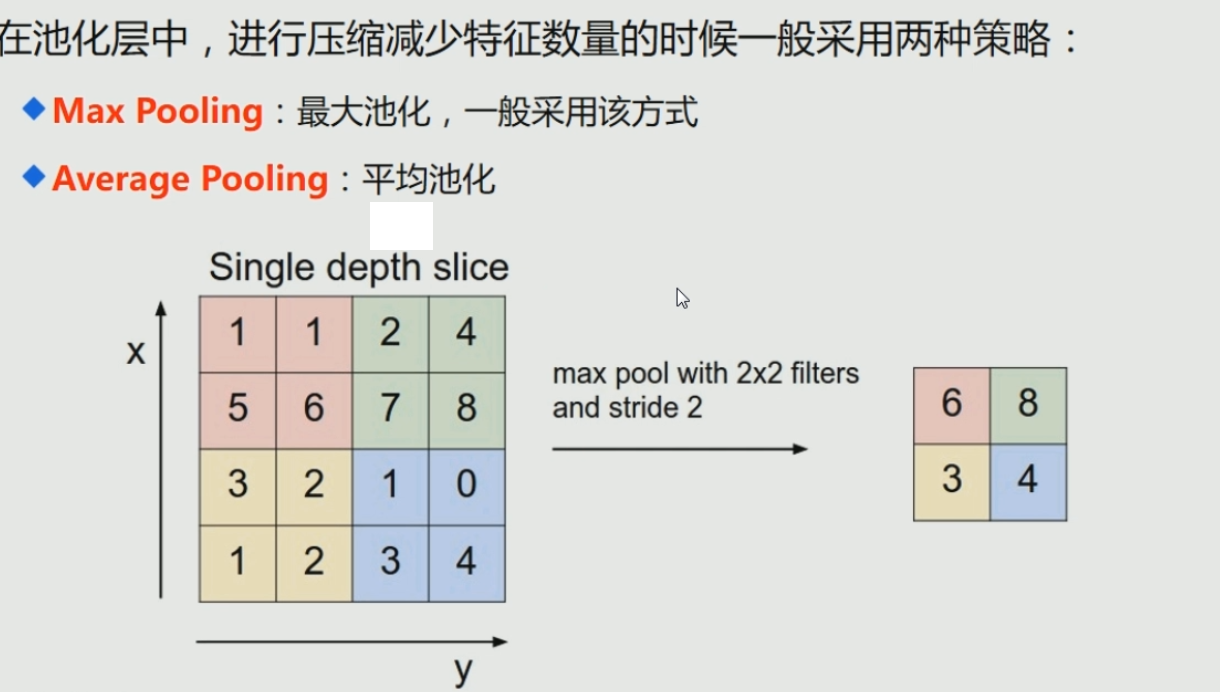
CNN-Pooling Layer
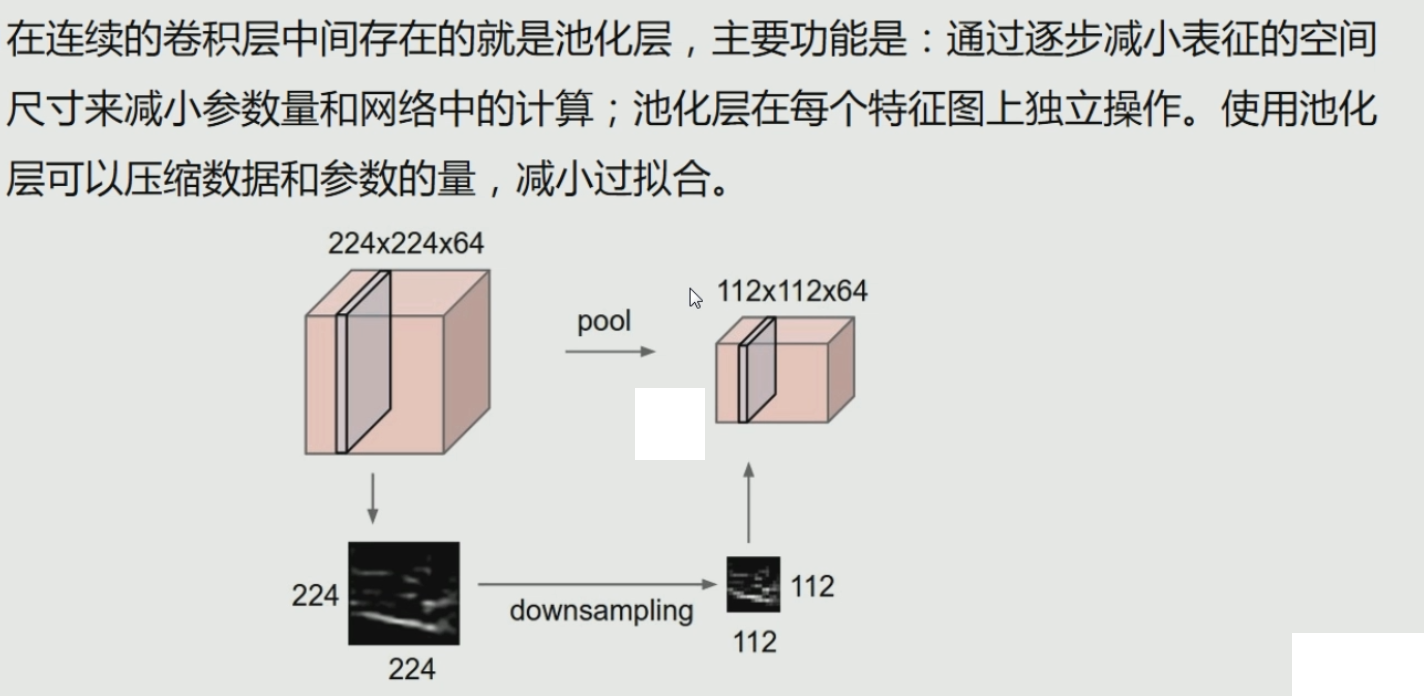
在连续的卷积层中间存在的就是池化层,
主要功能是:通过逐步减小表征的空间尺寸来减小参数量和网络中的计算;
池化层在每个特征图上独立操作。
使用池化层可以压缩数据和参数的量,减小过拟合。
CNN-FC 对数据汇总计算
类似传统神经网络中的结构,FC层中的神经元连接着之前层次的所有激活输出;
换一句话来讲的话,就是两层之间所有神经元都有权重连接;
通常情况下,在CNN中,FC层只会在尾部出现

卷积神经网络的优缺点
优点
共享卷积核(共享参数),对高维数据的处理没有压力
无需选择特征属性,只要训练好权重,即可得到特征值
深层次的网络抽取图像信息比较丰富,表达效果好
缺点
需要调参,需要大量样本,训练迭代次数比较多,最好使用GPU训练
物理含义不明确,从每层输出中很难看出含义来
手写体 mnist
# coding:utf-8
# 导入本次需要的模块
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
from tensorflow.examples.tutorials.mnist import input_data
# number 1 to 10 data
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
def compute_accuracy(v_xs, v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1})
correct_prediction = tf.equal(tf.argmax(y_pre, 1), tf.argmax(v_ys, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1})
return result
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
# stride[1, x_movement, y_movement, 1]
# Must have strides[0] = strides[3] =1
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding="SAME") # padding="SAME"用零填充边界
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# #################处理图片##################################
# define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None, 784]) # 28*28
ys = tf.placeholder(tf.float32, [None, 10])
# 定义dropout的输入,解决过拟合问题
keep_prob = tf.placeholder(tf.float32)
# 处理xs,把xs的形状变成[-1,28,28,1]
# -1代表先不考虑输入的图片例子多少这个维度。
# 后面的1是channel的数量,因为我们输入的图片是黑白的,因此channel是1。如果是RGB图像,那么channel就是3.
x_image = tf.reshape(xs, [-1, 28, 28, 1])
# print(x_image.shape) #[n_samples, 28,28,1]
# #################处理图片##################################
## convl layer ##
W_conv1 = weight_variable([5, 5, 1, 32]) # kernel 5*5, channel is 1, out size 32
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # output size 28*28*32
h_pool1 = max_pool_2x2(h_conv1) # output size 14*14*32
## conv2 layer ##
W_conv2 = weight_variable([5, 5, 32, 64]) # kernel 5*5, in size 32, out size 64
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # output size 14*14*64
h_pool2 = max_pool_2x2(h_conv2) # output size 7*7*64
## funcl layer ##
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
# [n_samples,7,7,64]->>[n_samples, 7*7*64]
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
## func2 layer ##
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# #################优化神经网络##################################
# the error between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), reduction_indices=[1])) # loss
train_step = tf.train.GradientDescentOptimizer(1e-4).minimize(cross_entropy)
# train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
sess = tf.Session()
# important step
sess.run(tf.global_variables_initializer())
# #################优化神经网络##################################
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: 0.5})
if i % 50 == 0:
# print(sess.run(prediction,feed_dict={xs:batch_xs}))
print(compute_accuracy(mnist.test.images, mnist.test.labels))
参考文献
https://blog.csdn.net/ice_actor/article/details/78648780
https://blog.csdn.net/program_developer/article/details/80369989
posted on 2019-04-06 23:00 Indian_Mysore 阅读(666) 评论(2) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号