


02-python基础语法_1.输入输出,注释,变量,if条件判断,while循环语句,编码,字符串格式化,运算符
4-1-1 Python基础语法
(一).Outline
1.编码的初识
1.1四种编码
1.2四种编码的应用 + 单位换算
1.3编码和解码的初识 ---- 之python解释器的编码
1.4编码和解码的初识 ---- 之文件的编码 +2者综上小结.
2.编码进阶
2.1Python解释器是如何承上启下,将python代码执行起来的:
2.2如何进行str编码方式的转换:用encode!!
2.3如何对bytes类型的数据进行解码:
2.4编码和解码 **
3.Linux上一种特殊的运行代码文件(执行脚本)的方法-- 加上环境头文件,在Linux中,以指定解释器的路径,方便以后查找。
4.输出 - print( )
5.变量
6.输入 - input()
7.注释
8.if条件语句--6种
9.while循环语句
9.1while循环
9.2关键字 -break
9.3关键字 -continue
9.4while else结构
10.运算符
(二).Content
1.编码的初识
1.1四种编码
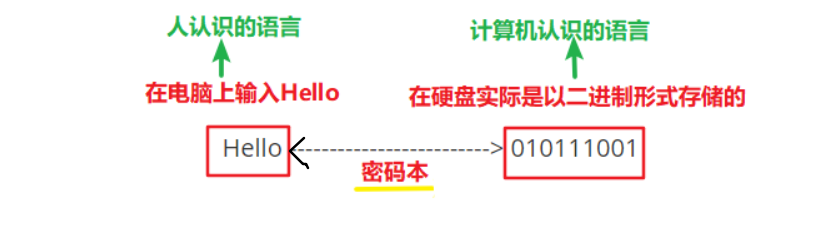
密码本:就是01010110 二进制与 文字之间的对应关系。
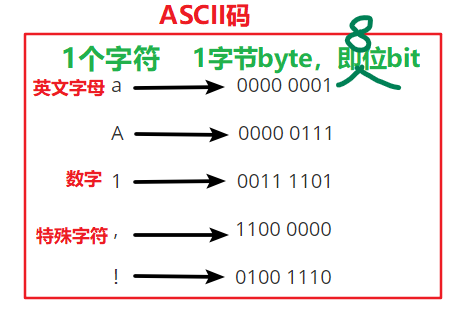
1.最早ASCII码:只包含:英文字母,数字,特殊字符。用8位表示1个字符,即共有2的8次方种排列组合,即可表示256个字符。
2.万国码Unicode:包含世界上所有的语言文字。用32位表示1个字符,即共可表示2的32次方种字符。
ps:创始之初,unicode叫ecs2,1个字符只占2个字节,未能包含所有语言;
后来扩充,改名为ecs4,1个字符占4个字节,包括世界上的所有语言。

两者综上:同样的字符,用ASCII码和万国码存储在电脑硬盘中,占用的硬盘空间差距显著。
ASCII码: Unicode:
eg:H 8bit(位) 32bit(位)
H 01000001 00000000 00000000 00000000 01000001
L 11000100 00000000 00000000 00100001 11000100
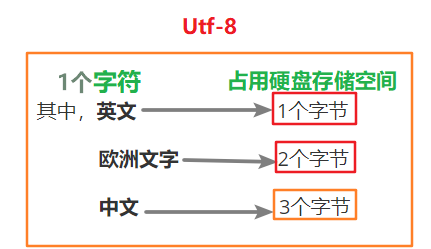
3.Utf-8:为了解决万国码占用存储空间大的问题,Utf-8应运而生,它对万国码进行了压缩,只保留万国码中的有效字节( 以8位为单位,总bit(位)数为8的倍数位 )。仍包含世界上所有的语言文字,只是占用的存储空间少了。

utf-8中,二进制与文字的对应关系为:
4.gbk编码 -- 又叫国标,是专门为亚洲人创作的一种编码方式。包含英文,中文,数字,特殊字符.

1.2四种编码的应用 + 单位换算
应用:
a.在数据传输 and 在硬盘中保存时,一般会用utf-8或gbk等除万国码以外的其他编码(因为占用的空间和资源少);
b.在内存中做计算时,一般会用Unicode编码,因为用它的话,每个字符所占用的长度相同(即占用字节相同,都是32位),便于计算。
c.切记:以后你自己写项目做开发的时候,一定要用utf-8!方便以后扩展。
(因为一些最新的开源组件大部分是外国人写的,他们用的utf-8,如果你用gbk的话,拿过来不能用!)。关于utf-8中文字符占用3个字节的问题,在开源组件面前,我们可以容忍它这个缺点(占用内存稍大一点。
单位换算:
8bit = 1Byte
1024Byte = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB # 常⽤到TB就够了。
1024TB = 1PB
1024TB = 1EB
1024EB = 1ZB
1024ZB = 1YB
1024YB = 1NB
1024NB = 1DB
1.3python解释器的编码
写在前面:python解释器的编码方式决定了用哪种编码方式去打开代码文件(脚本).
python3x默认Utf-8编码。
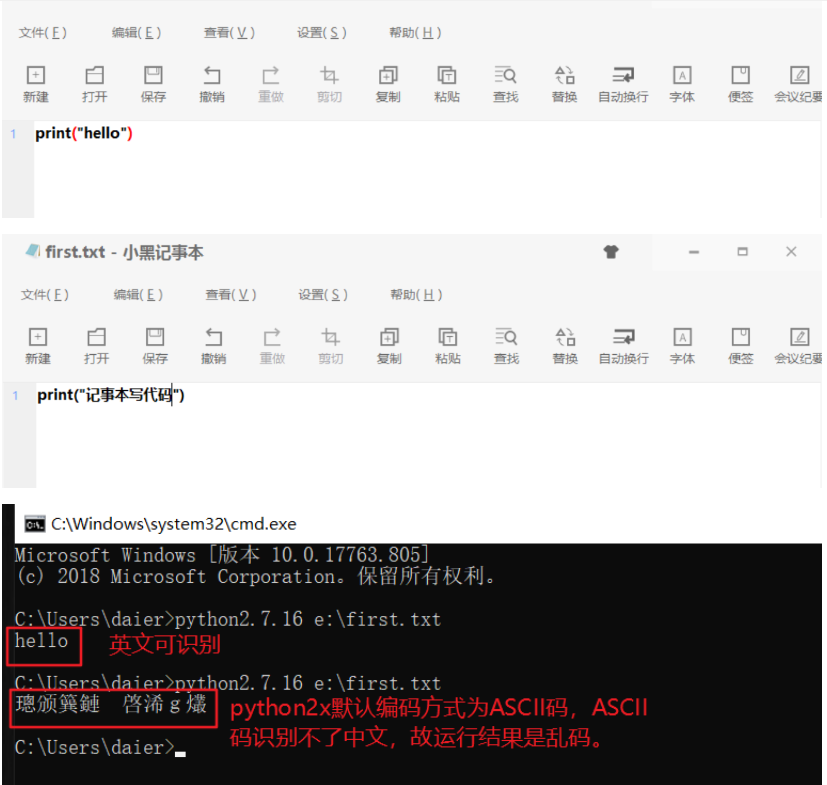
python2x默认ASCII码;弊端:用它打开并运行你写的代码时,识别不了代码文件里的中文,需自己指定编码方式为utf-8才能识别,即python2可以自己修改其编码方式. (因为utf-8是万国码的压缩版,可识别世界上的所有语言.)
eg:例子详情见02环境搭建2.1.3第一个python脚本之错误二.
如何指定python解释器的编码方式: 在代码文件头部加上一个"头文件":

此时,python2x解释器就可以以utf-8的编码方式去打开你的代码文件(不管文件里是什么语言都能识别),然后将文件内容识别后加载到内存,在内存里将代码运行起来,并执行结果.
结论:以后写代码时,不管你写的是python2语法还是python3语法,也不管你打算用python2X还是python3X去运行你的代码文件,都要在文件头部加上它! ! !即以后python解释器统一用utf-8的编码方式去打开代码文件.
(因为,如此一来,以后不管你再用2x还是3x去运行你的脚本,都不会出现乱码.即此时你的脚本既支持python2x又支持python3x.)
1.4文件的编码
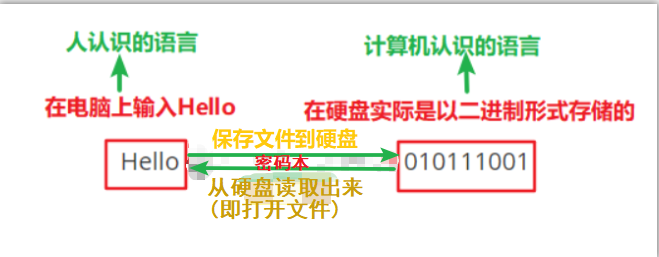
写在前面:文件的编码决定了以哪种编码方式保存文件.
以哪种编码方式写入硬盘(保存文件),就要用哪种编码方式从硬盘读取出来(打开文件).
即以哪种编码方式保存文件,就要用哪种编码方式打开文件,否则会出现乱码.
eg1:以普通文本文件为例:
用notepad++去写文件,因为它可以自由选择文件的编码方式.记事本操作起来相对麻烦.
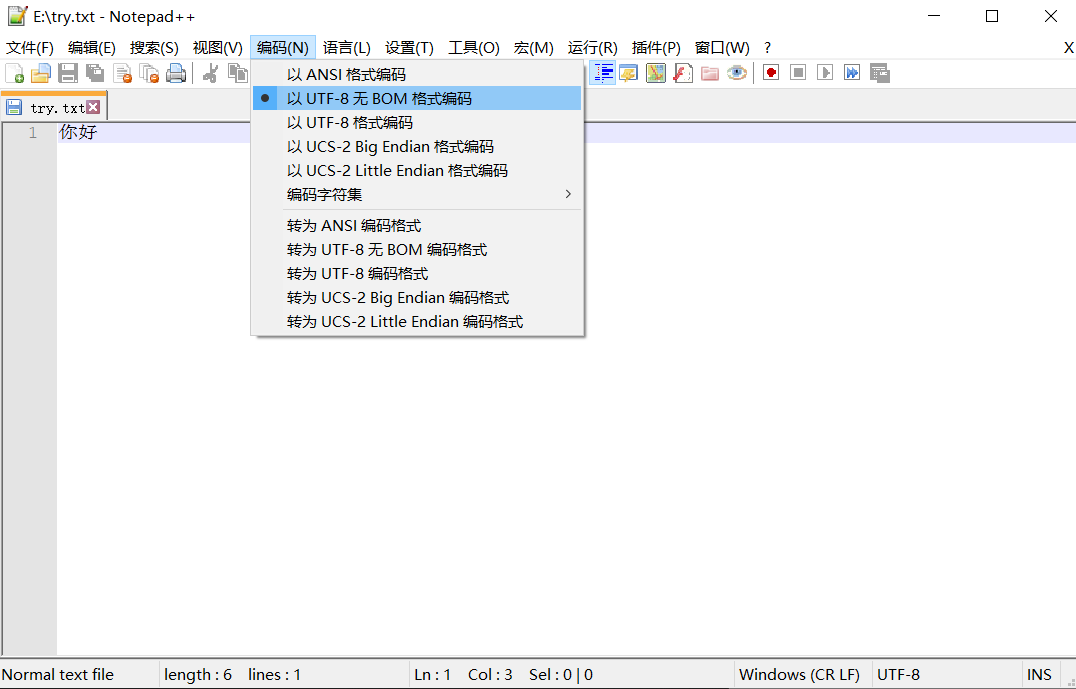
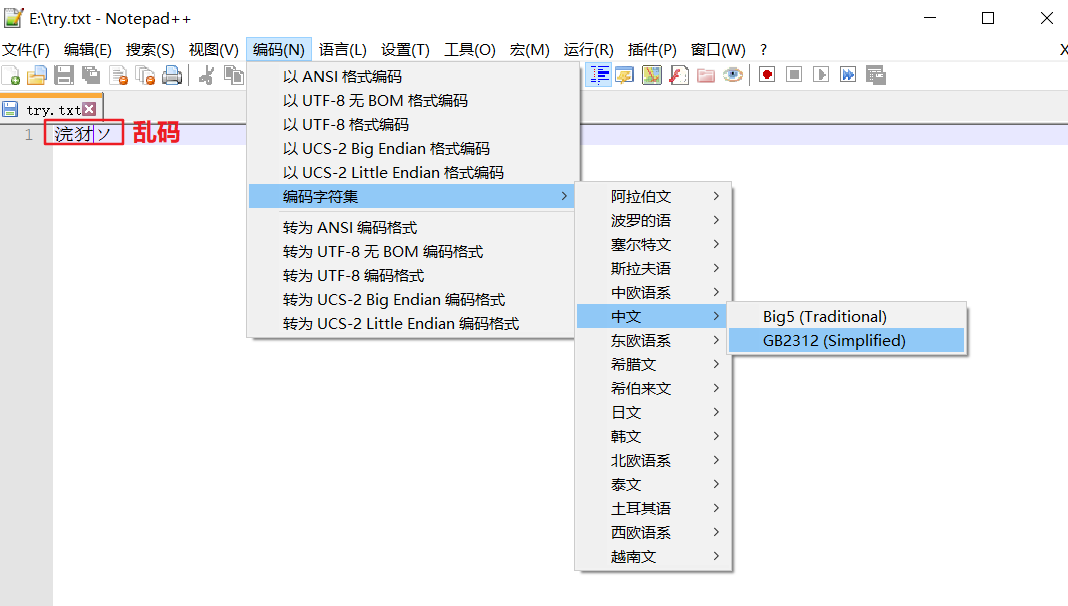
在e:\盘用notepad++文本编辑器新建一个文本文件---->写入内容,并保存(notepad++默认编码方式为utf-8)---->关闭文件,分别以utf-8和gb2312去打开文件,会看到用gb2312编码方式打开的文件,内容是乱码.这是由于保存文件的编码方式和打开文件的编码方式2者不统一导致的.
以utf-8编码方式去打开文件:
以gb2312编码方式去打开文件:
eg2:以代码文件为例:
ps:例子详情见02环境搭建2.1.3第一个python脚本之错误一.
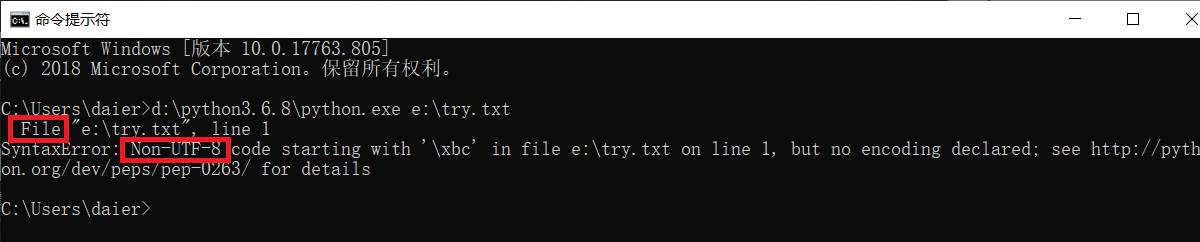
用python3x去运行脚本,回车后报错-见下图,是因为你写的这个代码文件(脚本)的编码方式与python3x解释器的编码方式不统一,需更改编码方式, 使2者统一后再交给解释器去运行。
python3x解释器:默认utf-8(可识别所有语言文字)。故,需将代码文件的编码方式改为utf-8再保存。即,保存文件的编码方式要和打开该文件的python解释器的编码方式统一,否则会报错!
以记事本为例,更改txt代码文件的编码方式:
a.先找到这个文件
b.打开方式选记事本
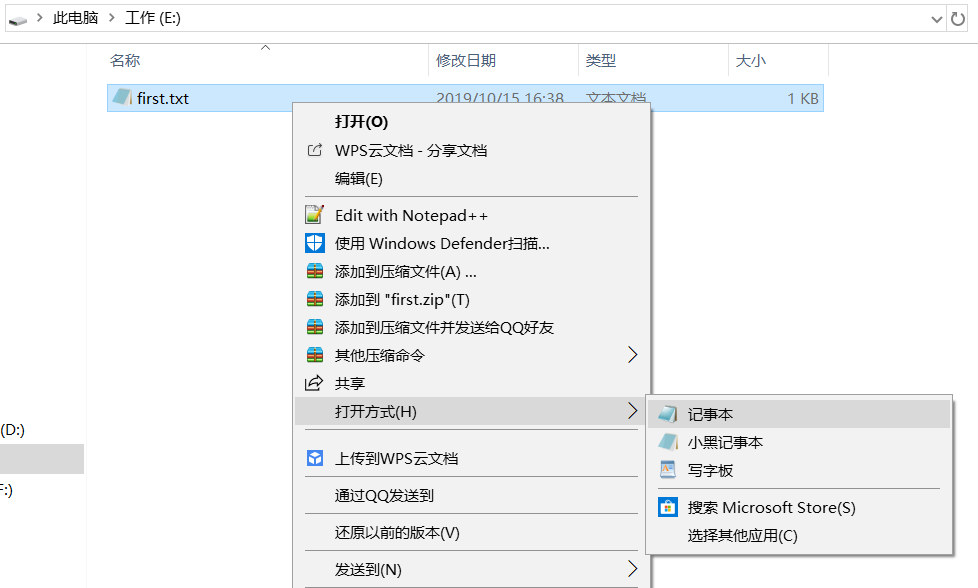
c.打开后,文件--->另存为,若用Python3去运行此脚本,则应将此脚本的编码方式改为utf-8,保存。
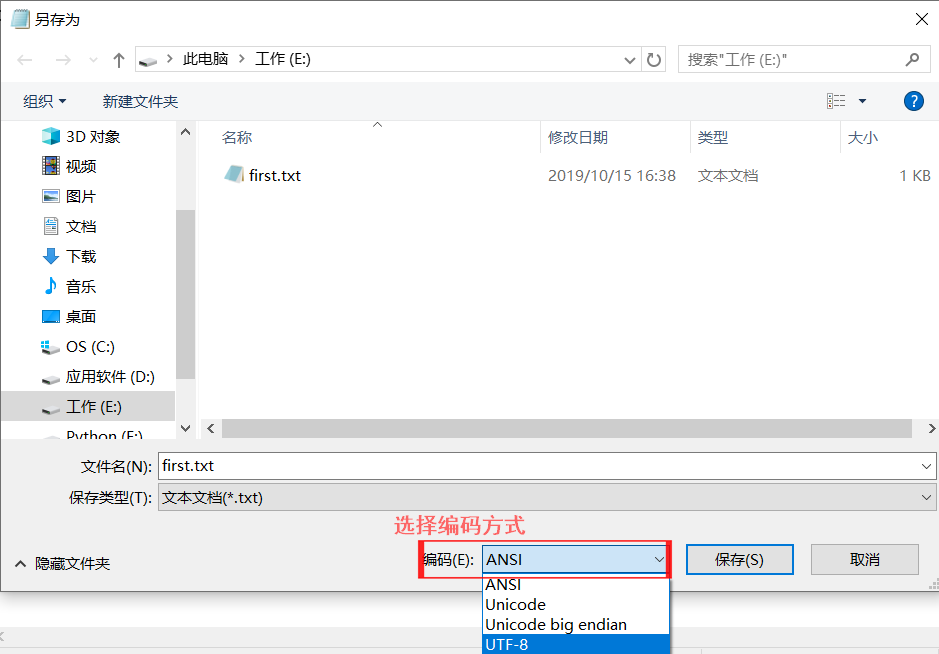
d.再在windows窗口输入cmd,进入python交互式环境去运行即可。
结论:对于文件来说,以哪种编码方式保存文件,就要用哪种编码方式打开文件,否则会出现乱码;
代码文件也是文件,以哪种编码方式保存文件,就要用python解释器的哪种编码方式打开文件,否则运行结果会报错;
故,以后写代码(脚本),保存文件时一定要用utf-8编码方式.因为,4.1.2中已指出以后不管用python2x语法写代码,还是用python3x语法写代码,均会在代码文件头部加上头文件以指定python解释器的编码方式为utf-8.如此,2者的编码方式均规定用utf-8,运行结果才不会报错.
综上:编码和解码(的编码方式)要一致!!即用哪种编码方式编写(保存)的代码,就要用哪种编码方式去打开and运行这些代码。
由1.3和1.4可知,以后写代码时,务必使python解释器的编码方式(即打开代码文件的编码方式;python2:ascii码,python3:utf-8,均需加头文件!)与你写的代码文件(脚本)的编码方式(即保存代码文件的编码方式)一致!
我们默认以后2者均统一用utf-8编码!(因为utf-8强大,可识别任何语言且占用存储空间少)
2.编码进阶
2.1Python解释器是如何承上启下,将python代码执行起来的:
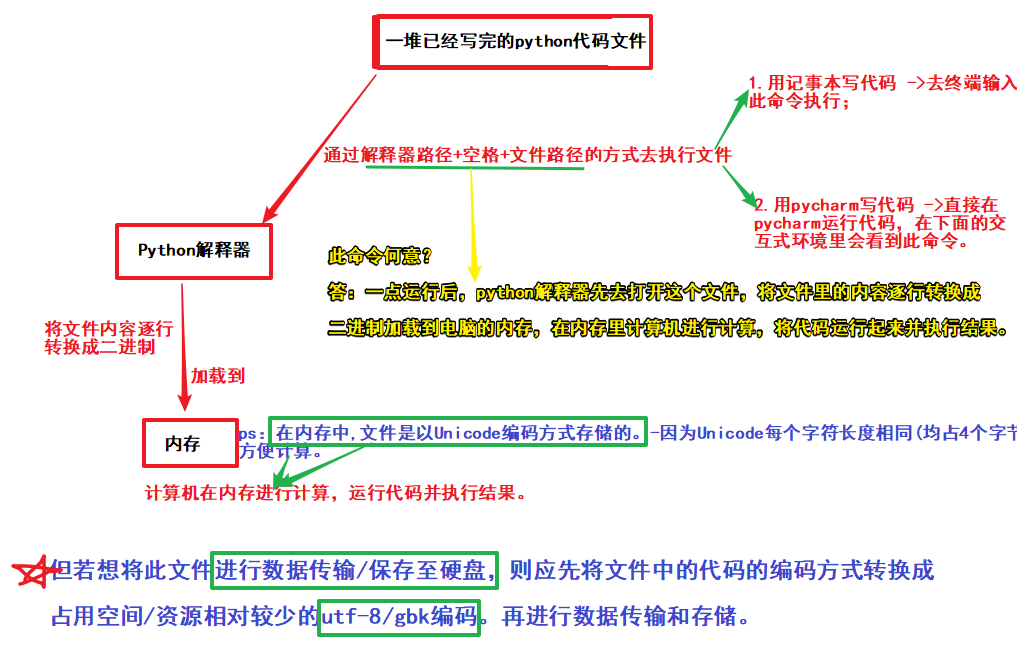
ps:在程序运行阶段,使用的是unicode编码(因为便于计算机进行计算);
在程序进行数据传输和存储时,使用的是utf-8/gbk编码(因为utf-8/gbk在数据传输/存储过程中,占用的空间和资源少)。
在python中可以把文字信息进行编码. 编码之后的内容就可以进行传输or存储了。
2.2 如何进行str编码方式的转换:用encode!!
即如何将str的Unicode编码 -->utf-8/gbk编码,以进行传输和存储:
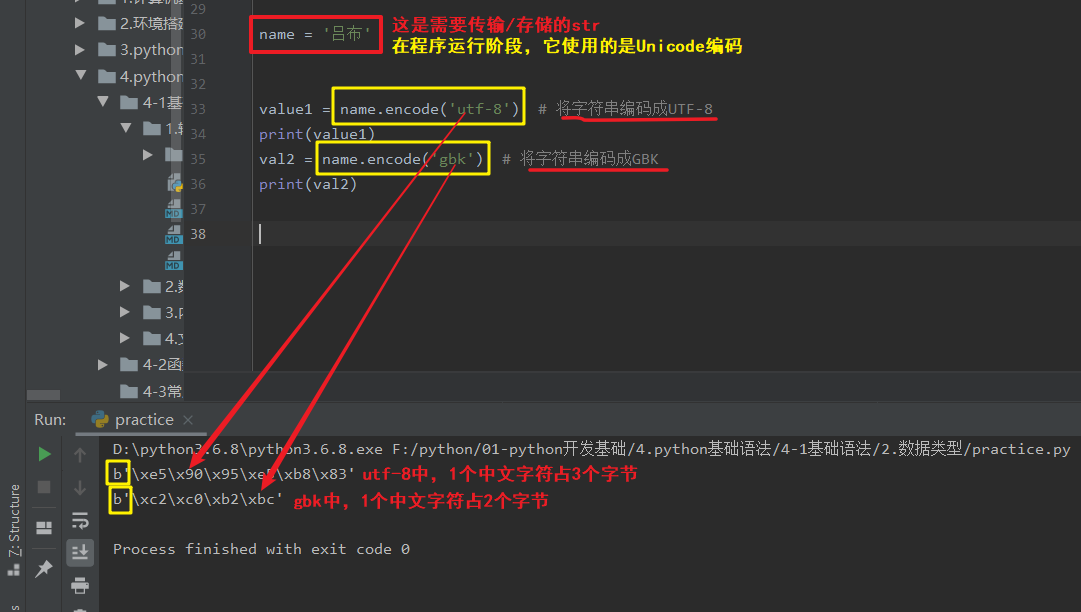
# 当str是中文时,编码之后的结果根据编码方式的不同,编码结果也不同.utf-8:1中文占3字节;gbk:1中文占2字节
name = '吕布'
value1 = name.encode('utf-8') # 将字符串编码成UTF-8
print(value1)
val2 = name.encode('gbk') # 将字符串编码成GBK
print(val2)
结果:b'\xe5\x90\x95\xe5\xb8\x83'
结果:b'\xc2\xc0\xb2\xbc'
# 当str是英文时,编码之后的结果和源字符串一致。
name = 'xiaokeai'
value1 = name.encode('utf-8') # 将字符串编码成UTF-8
print(value1)
val2 = name.encode('gbk') # 将字符串编码成GBK
print(val2)
结果:b'xiaokeai'
结果:b'xiaokeai'
ps-1:编码之后的数据是bytes类型的数据。
其实,还是原来的数据。只是经过编码之后表现形式发生了改变而已。
bytes的表现形式:
- 英文: b’xiaokeai’ 英文的表现形式和字符串没什么两样;
- 中文:b'\xe5\x90\x95 这是一个汉字的UTF-8的bytes表现形式。
- 中文:b'\xc2\xc0 这是一个汉字的gbk的bytes表现形式。
ps-2:encode的作用:是将用Unicode编码的字符串转换成utf-8/gbk编码的字符串,以用来进行str的数据传输/将其保存至硬盘。(即encode的作用是用来进行str编码方式的转换的。)
ps-3:何时用encode:在将str保存至硬盘/进行str的数据传输时,会用到encode。因为需要转换str的编码方式。
ps-4:编码格式:str.encode('utf-8/gbk')
ps-5:encode转换编码方式后,数据类型变成了bytes类型。即在str进行数据传输/存储时是以bytes的形式存在的。
2.3 如何对bytes类型的数据进行解码:
即如何将bytes的utf-8/gbk编码 -->str的Unicode编码,以进行解码还原:
ps:在网络传输和硬盘存储的时候我们python是保存和存储的bytes 类型。
那么在对方接收的时候,也是接收的bytes类型的数据。我们可以使⽤decode()来进行解码操作,
把bytes类型的数据还原回我们熟悉的字符串:
name = '吕布'
value = name.encode('utf-8') # 将字符串编码成UTF-8
print(value)
# 结果:b'\xe5\x90\x95\xe5\xb8\x83'
value2 = b'\xe5\x90\x95\xe5\xb8\x83'.decode('utf-8') # 将bytes类型解码(还原)成我们认识的str
print(value2)
# 结果:吕布
注意:1.见到认识(str)的就编码,见到不认识(bytes类型)的就解码还原成我们认识的。
2.用什么编码的,就再用什么解码
2.4编码和解码
示例:str的GBK -->UTF-8,中间需要一个桥梁:Unicode。
见到1个str,先用gbk编码,获得bytes类型数据;再用gbk对bytes解码,还原为原str;再对此str进行utf-8编码。
s = "我是文字"
# 1th: 我们这样可以获取到GBK的文字
bs = s.encode("GBK")
print(bs) # 结果:b'\xce\xd2\xca\xc7\xce\xc4\xd7\xd6'
# 2th: 把GBK转换成UTF-8
# 首先要把GBK转换成unicode. 也就是需要解码
s = bs.decode("GBK") # 将gbk的bytes类型进行解码还原 -ps:用什么编码的,就再用什么解码。
print(s) # 结果:我是文字
# 然后需要将解码后的str重新编码成UTF-8
bss = s.encode("UTF-8") # 重新编码
print(bss) # 结果:b'\xe6\x88\x91\xe6\x98\xaf\xe6\x96\x87\xe5\xad\x97'
3.在代码文件中加上环境头文件,用于在linux中指定解释器路径.
ps:环境头只在linux上生效。
3.1在windows和Linux电脑终端(小黑框)执行1个python脚本(代码文件)的2种不同的执行(运行代码的)方法:
一种2者通用,一种只适用于linux系统。
e:\盘有一个python脚本(代码文件),文件名为a.py,文件内容如下:
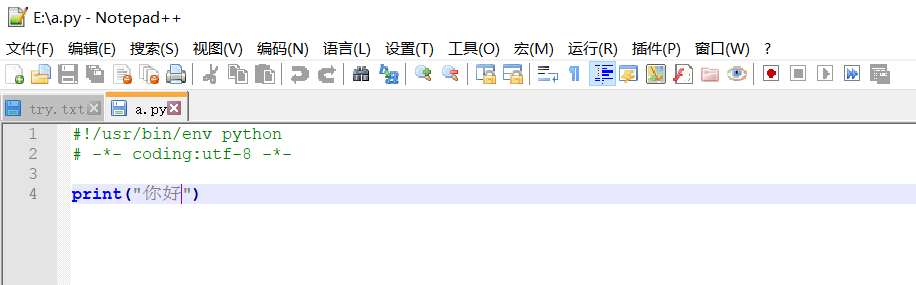
1.在电脑终端(小黑框)执行(运行)这个python脚本的通用方法(windows/liunx均适用):
在电脑终端,输入命令:
a.添加环境变量后:解释器名称+空格+代码文件的路径;
b.未添加环境变量:解释器路径+空格+代码文件的路径。
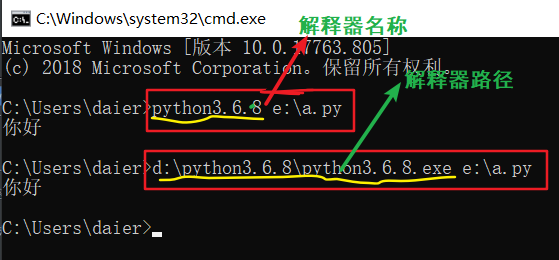
2.在Linux上,电脑终端(小黑框)执行(运行)这个python脚本的方法(仅适用于Linux系统):
首先,在你的代码文件的第一行要加上1个环境头文件:#!usr/bin/env python;
然后,去Linux系统的电脑终端运行它:
在Linux电脑终端输入如下2步,以运行python脚本:

即:代码文件(脚本)第一行#!usr/bin/env python 的作用是:在Linux中指定python解释器的路径。以后每次再需要找解释器时,不再需要输入解释器的路径,而只需输入./即可。即以后每次在运行文件时,只需输入./+空格+文件名 即可,不再需要输入解释器路径+空格+文件名。(ps:这个环境头文件类似于在windows中添加环境变量。)
ps-1:用这种方法去执行python脚本的话,有一个小细节要注意,就是在Linux电脑终端输入执行命令时,是./ + 文件名 ,而通用方法中的执行命令是 解释器名称+空格+文件路径(在windows系统添加环境变量后)。
ps-2:#!/usr/bin/env python中的python是指:用于执行这个文件的解释器。eg:你的python3.6.8.exe。
则环境头应写为:#!/usr/bin/env python3.6.8 !!!
3.2如何在pycharm中给每个py文件设置头文件模板:
1th:在任意.py文件下,点file -->setting:

2th: 在setting下搜索template(模板) -->找到file and code template -->找到python script(解释器) -->在右边输入要设置的模板代码 -->apply(申请) -->ok;
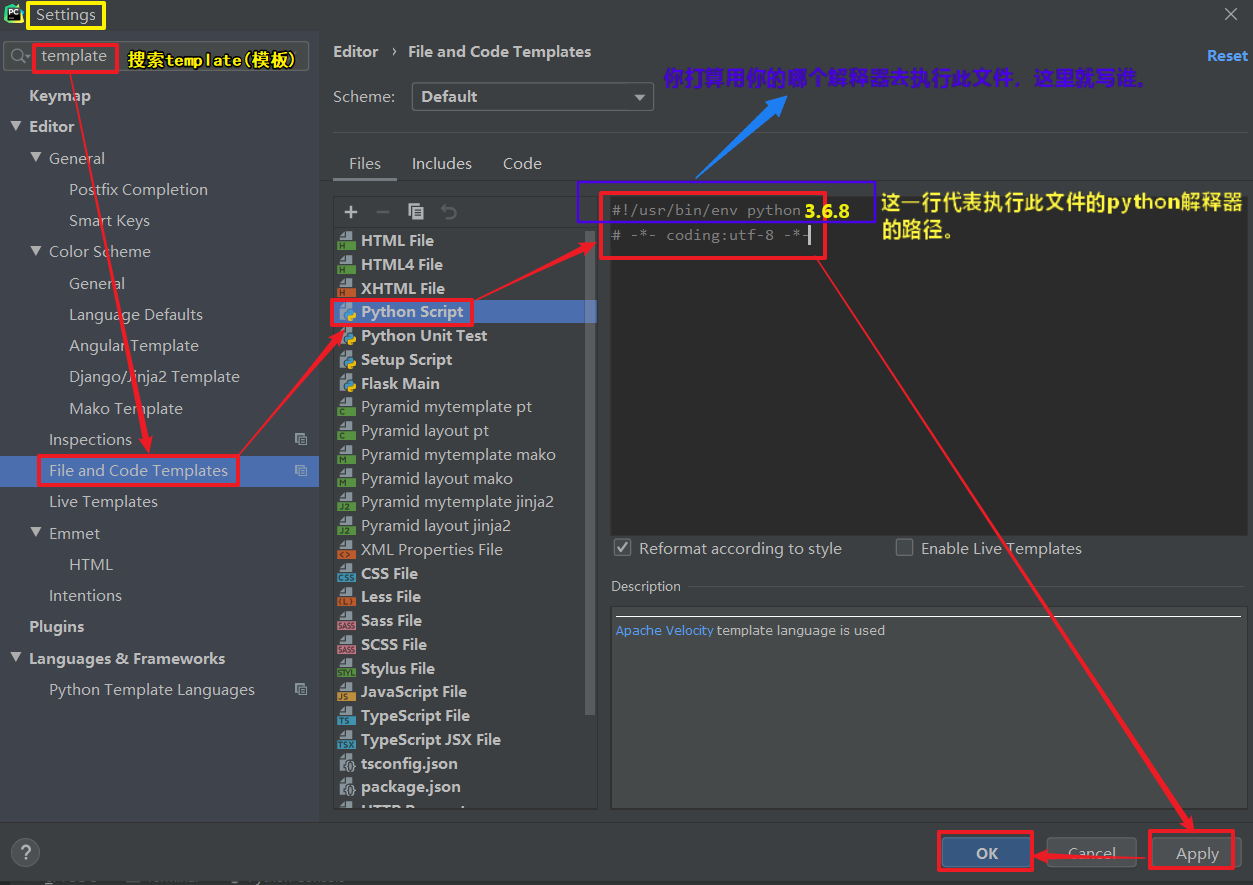
3th:去创建一个新的.py文件,会自动生成刚刚设置的模板代码。

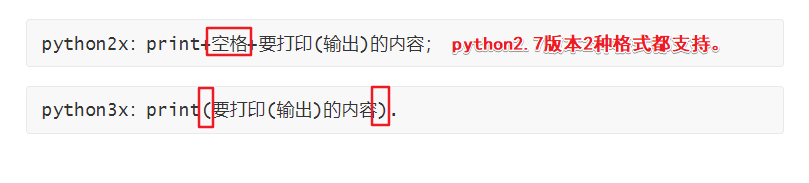
4.输出 - print( )
print( 放你想要输出(打印)的东西 )
py2x和py3x在此语法上的区别:
5.变量
5.1给变量赋值
变量存在的意义:使代码简洁;方便以后值的调用(为某个值创建一个"外号",以后在使用此值的时候可通过此外号直接调用).
给变量赋值的含义:是将等号右边的内容进行运算后,将运算结果赋值给等号左边。

5.2给同一个变量,进行多次赋值

变量的小高级:
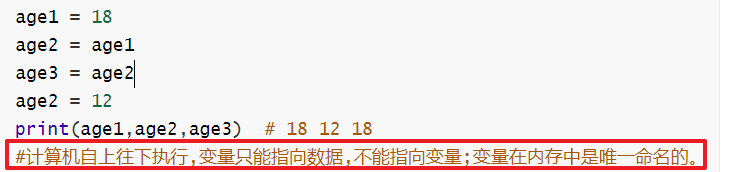
内存图----后补。
5.3变量命名规范 -- 三大要求+三个建议+一个注意.
三大要求:
1.变量名中只能包含:字母、数字、下划线(3选1\2\全选);ps:即不能使用中文。
2.不能以数字开头;
3.不能是python的关键字;
python关键字包括:平时常用的这些关键字input、print、true等,+ Python的32个内置关键字。

ps:python的32个内置关键字and所有内置函数见统一整理文件。
三个建议:
1.见名知意;eg:name = "吕布",sex = "男";
2.建议用下划线连接;eg:lvbu_sister = "小小维";
注:在python中,变量不建议使用驼峰体。eg:LvbuSister = "小小维",Java中通常会使用驼峰体去连接变量。
3.变量名不能太长;
一个注意:变量名区分大小写!(ps:只有驼峰体时才会出现大小写。python中不建议用驼峰体,故此项作废。)
#变量练习题:
x8 = 100 # True
b__ = 12 # True
4g = 32 # False 不能以数字开头
_ = 11 # True
*r = 12 # False 只能由数字,字母,下划线任意组合
r3t4 = 10 # True
t_ = 66 # True
true = 9 # False 不能是python关键字
print = 12 # False 不能是python内置关键字
input = 2 # False 不能是python关键字
6.输入 - input()
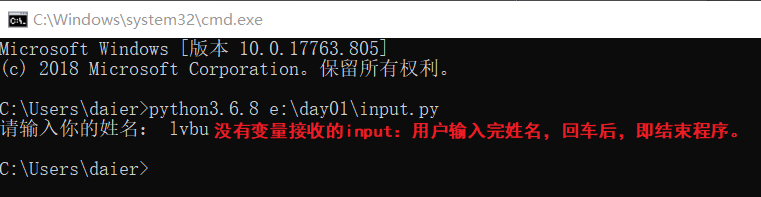
写在前面:input()获取的全部都是字符串类型。即,接收它的变量的数据类型全部都是str。
a.input前没有变量接收(它本身)

运行结果如下:
b.有变量接收

c.input前有变量接收,并输出(打印)此变量。 (以后经常这么用)

示例:
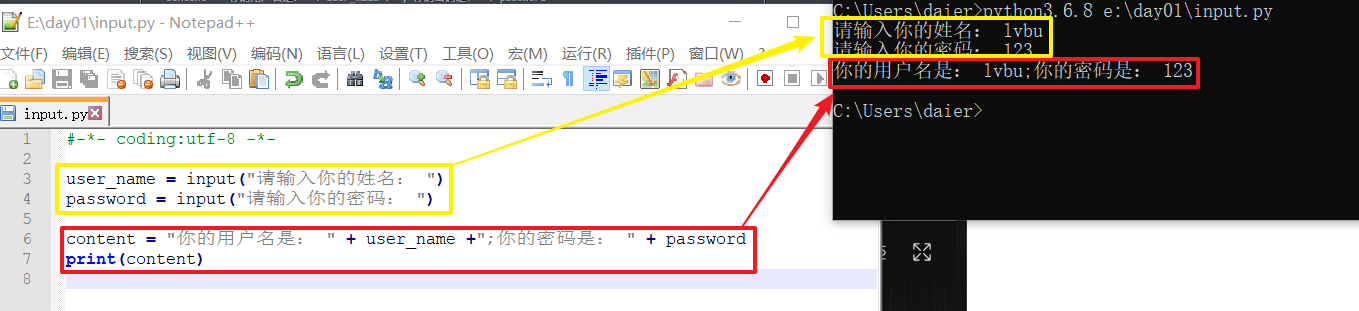
py版本区别:

7.注释
# 单行注释
"""
多行注释
"""
或
'''
多行注释
'''
ps-1:三引号可以用来排错。
ps-2:写在文件头部的注释,是用来对此文件进行解释说明的。
8. if条件判断语句--6种
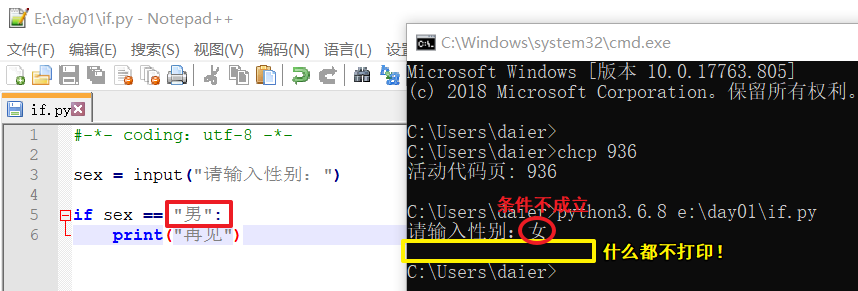
0.单独if #满足条件,打印结果;条件不成立,则什么都不打印! #可选0!
if 条件:
结果
示例:
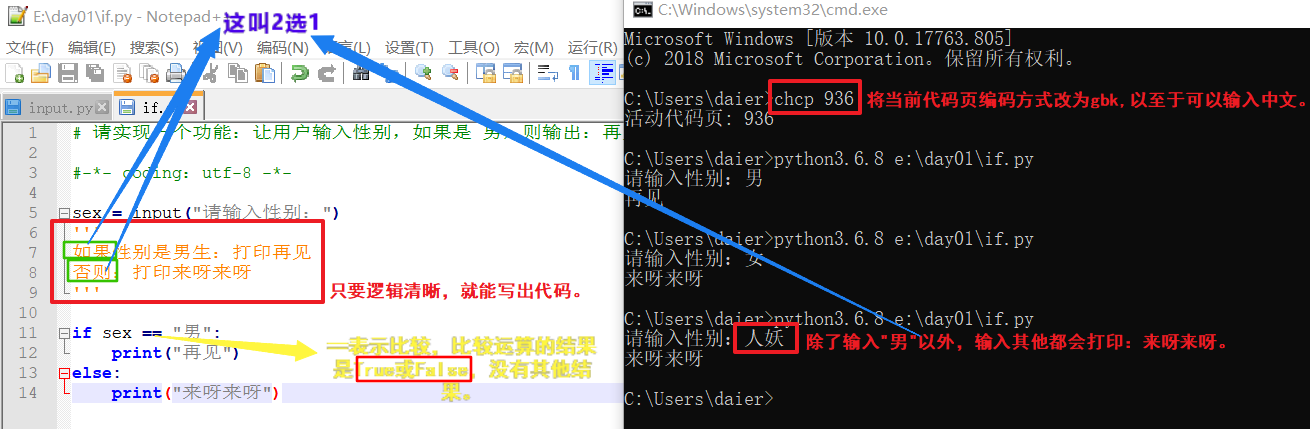
1. if else 二选一。 #2个里面必须选1个!
if 条件:
结果1
else:
结果2
示例:
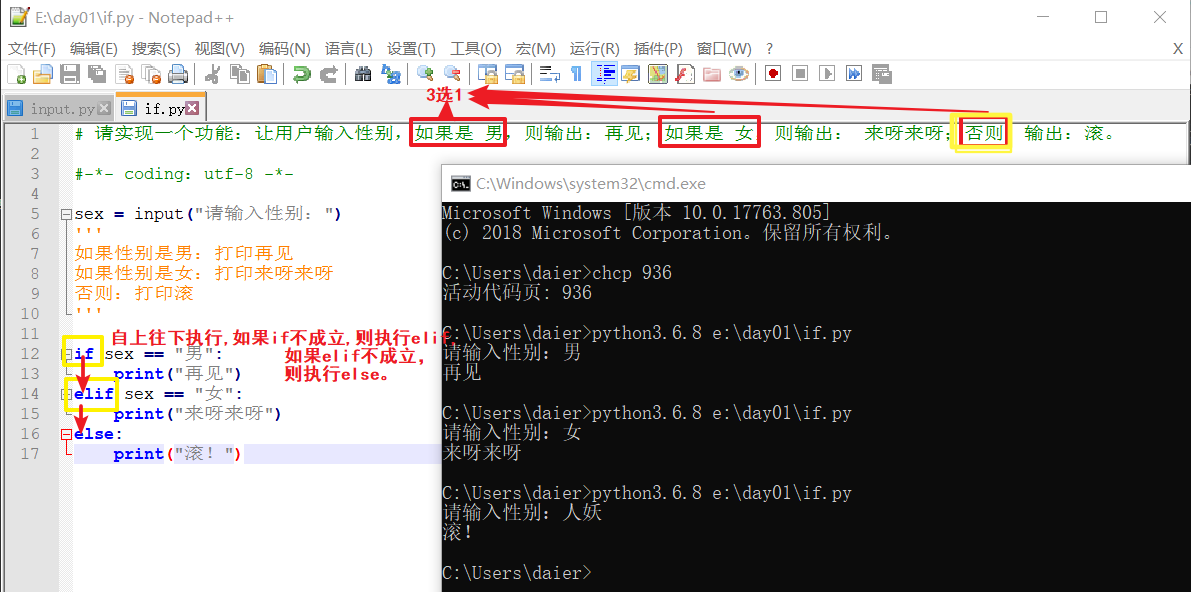
2.if elif elif...else多选一。 #多个里面必须选一个!
2.1 三选一
if 条件:
结果1
elif 条件:
结果2
else:
结果3
2.2 多选一
if 条件:
结果1
elif 条件:
结果2
elif 条件:
结果3
...
else:
结果n
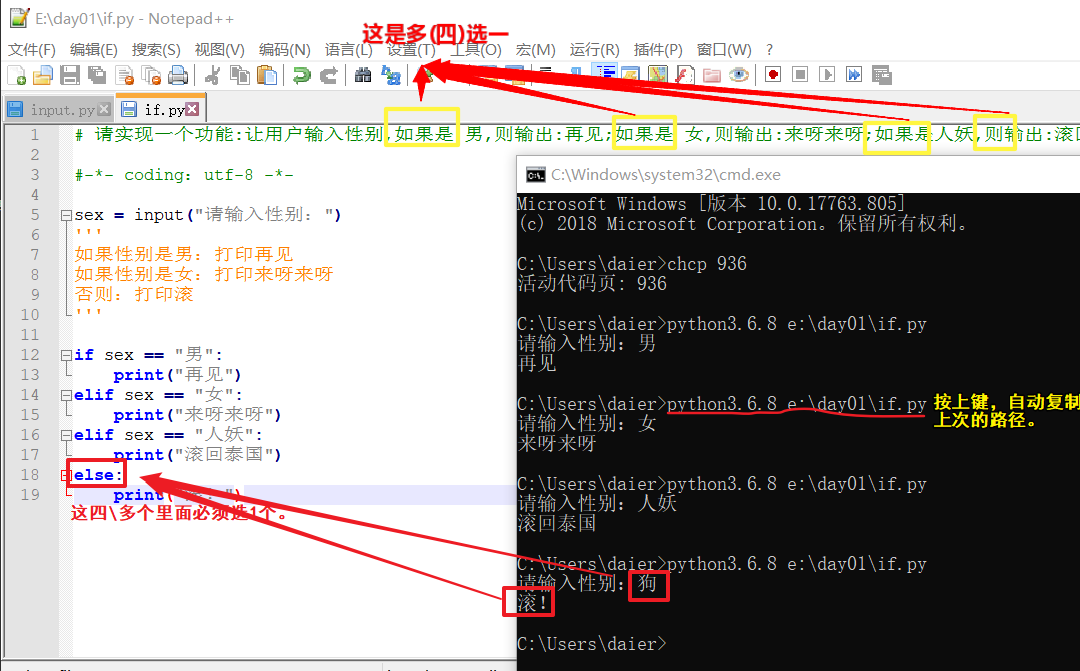
3.if elif elif...多选一\多选零。 #多个里面选一个\一个也不选! #可选0!
if 条件:
结果1
elif 条件:
结果2
elif 条件:
结果3
...
(ps:之所以会一个也不选,是因为计算机自上往下执行,在if 条件不成立,elif条件也不成立,下面的elif 条件通通不成立的情况下,这段程序会结束--什么都不打印。结束后会继续执行下面与它平行的同级语句。注:如果第一个条件满足,则下面的语句一个也不执行!)
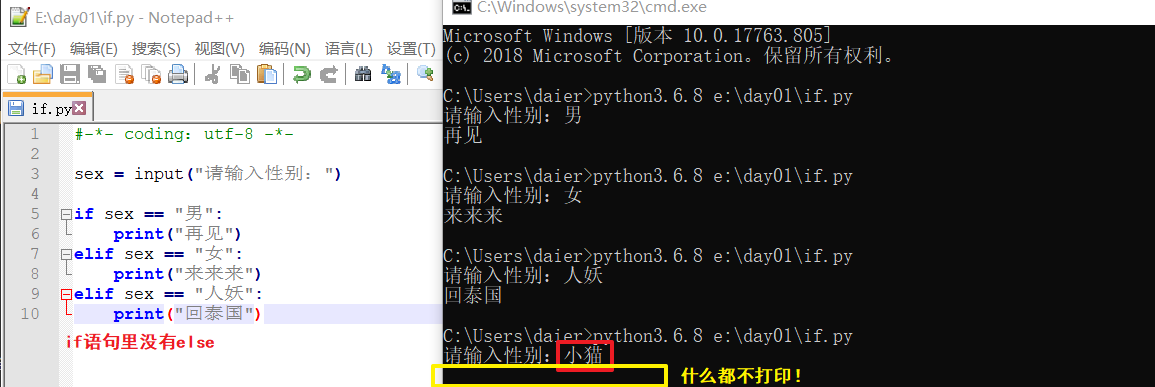
4.if if if ...多选任意。 #多个里面选任意个 or 一个也不选
if 条件:
结果
if 条件:
结果
if 条件: #多个if彼此平行,执行时互不干扰
结果
...
5.if嵌套 #工作中,条件嵌套层数不要太多!否则,你的逻辑存在问题。
if 条件:
if 条件:
结果1
else:
结果2
else:
结果
示例:10086
message = '''欢迎致电10086 #换行的字符串,三引号。
1.话费查询;
2.流量查询;
3.业务办理;
4.人工服务。'''
print(message) #要先显示内容,才能让用户选择。
index = int(input('请输入你要选择的服务:')) # 注意int包一下。
if index == 1: # 条件处用的是比较运算符。
print('话费查询')
elif index == 2:
print('流量查询')
elif index == 3:
content = """业务办理 #if嵌套的第二层。
1.修改密码;
2.更改套餐;
3.宽带业务"""
print(content) #依然是先显示内容,再让用户选择。
num = int(input('请输入要办理的业务:'))
if num == 1:
print('修改密码')
elif num == 2:
print('更改套餐')
elif num == 3:
print('宽带业务')
else:
print('输入错误,请重新输入')
elif index == 4:
print('人工服务')
else:
print('输入错误,请重新输入') #逻辑要严谨。
注意:
a.if后面的条件,全部都是比较运算!用==,>=,<=,或其他比较运算符。
b.与if elif...平齐的其他程序不属于if条件判断里的部分。2者是同一级的程序。执行完if条件判断语句后,计算机会继续向下执行跟它同一级的程序。

c. ** 如果if条件判断语句里没有else,则在条件均不满足的情况下,可以什么都不打印**,即一个也不选!
eg:单独if--条件不成立的情况;if elif elif...多个条件均不成立的情况;if if if...多个条件均不成立的情况。此3者均什么都不打印! 示例见上。
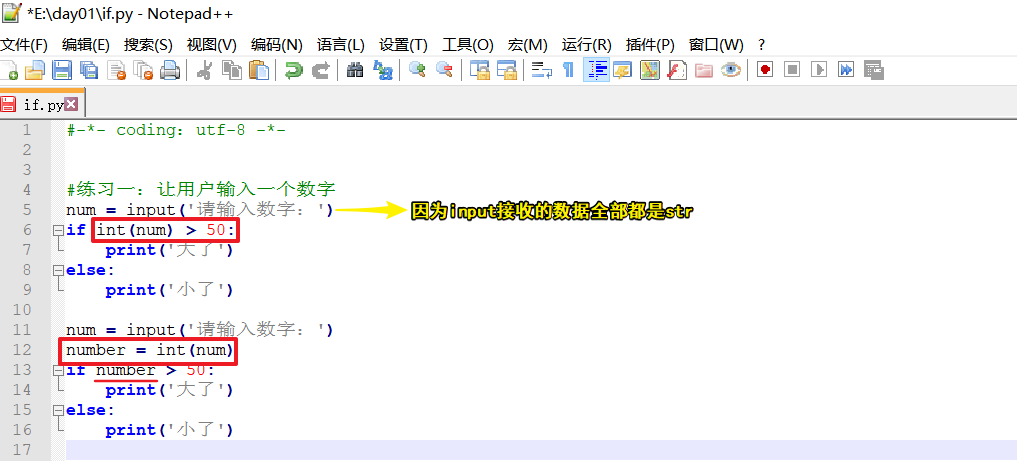
d. 当比较运算符2边的数据有1边是接收input()的变量,1边是数字时,需将此变量用int包一下,换成int类型后,再做比较。否则报错。
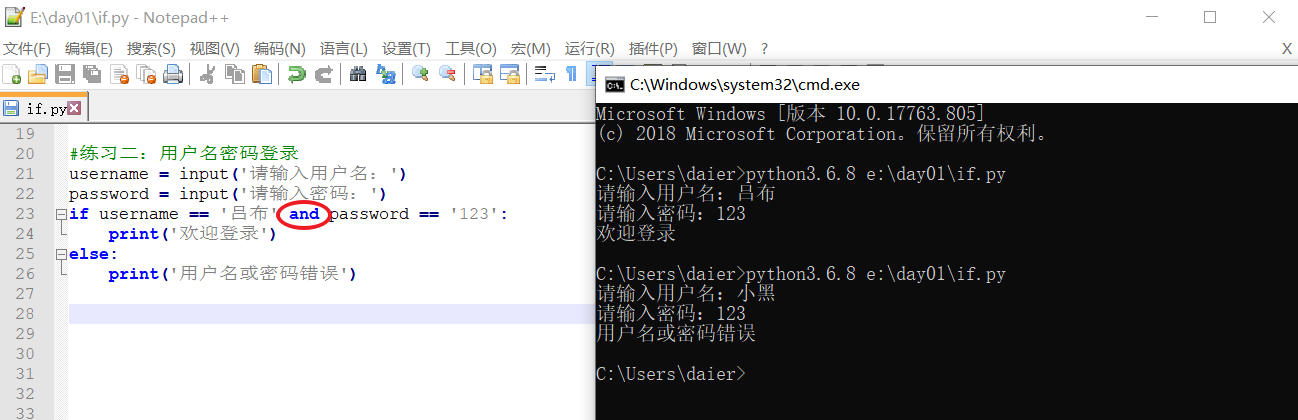
e. 在写if 条件这一行时,可以使用and,表并列(即需要同时满足2者,条件才成立)。
f.如果while循环体中的if里含有break,则else可以省去不写。以减少一行代码量。
count = 1
while count <= 3:
print(count)
user = input('请输入用户名:')
password = input('请输入密码:')
if user == '吕布' and password == '123456':
print('登录成功')
break
print('用户或密码错误') # 此处,便可省略else:
if count == 3:
print('3次机会已用完')
break
count += 1
练习题:
需求:根据成绩的不同显示不同的级别。
思路(伪代码):
成绩 = int(input('请输入成绩:')) # =是赋值运算
如果 成绩 >= 90: # >=是比较运算
print A
如果 成绩 >= 90:
print B
如果 成绩 >= 70:
print C
如果 成绩是其他:
print 其他
代码:
score = input("请输入你的分数:") #变量命名时不要用拼音!要用能见名知意的英文。
new_score = int(score) #1,2两步可以写一起:score = int(input("请输入你的分数:"))
if new_score >= 90: #if条件处均是比较!!== or >= or <=
print("A")
elif new_score >= 80:
print("B")
elif new_score >= 70:
print("C")
else:
print("其他")
#注:elif 90 > new_score >= 80: 此种写法思路严谨,但没必要。因为对于if elif...来讲,是自上往下执行的,前面的成立则不会再执行下面的。
9.while循环语句
9.1while循环语句
# 基本结构:
while 条件:
循环体
ps-1:while后加条件。条件处可以是True,也可以是比较运算<,<=,>等。
1.条件是True,死循环。
while True:
print('人生苦短,我用python')
# True的另一种表达方式。死循环。
while 1>0:
print('人生苦短,我用python')
while 1>0 and 2>1:
print('人生苦短,我用python')
while 1: # 这种更简洁,也比True运算的快。
print('人生苦短,我用python')
2.条件是比较运算,有限循环。-由此以限制循环次数。
示例:用while循环打印1-10
count = 1
while count <= 10: # 条件是比较运算
print(count)
count = count + 1
ps-2:与while平行的行与之同级,不属于while循环结构。(while else除外)
示例:请通过循环,让count每次循环都+1
count = 1 #count初始值与while同级
while True:
print(count) #print在前,可以打印到起始的1
count = count + 1
错误示例:
while True:
count = 1 #每次进入循环体后,count都被重新赋值为1。
print(count)
count = count + 1 #故此行无用。
练习题:
1.请通过循环,让count每次循环都打印奇数
count = 1
while True:
print(count)
count = count + 2
2.请通过循环,打印1 2 3 ...10
count = 1
while count <= 10:
print(count) # 先打印再自加
count = count + 1
print('结束')
或
count = 1
while count < 11:
print(count)
count = count + 1
print('结束')
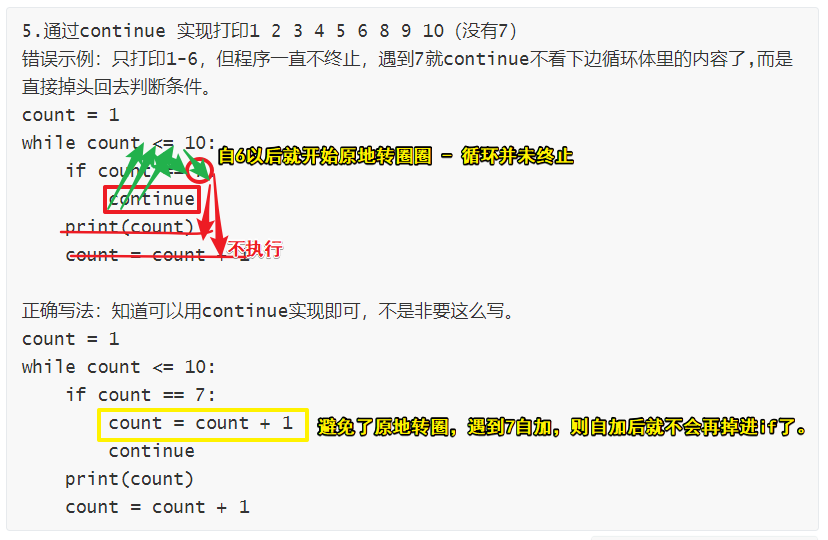
3.请通过循环,打印1 2 3 4 5 6 8 9 10 (没有7)
法一:推荐(因为代码量少,且实现了需求)
思路:只有在count != 7时,才打印。
count = 1
while count <= 10:
if count != 7: # != 比较运算符
print(count)
count = count + 1 # 只有在循环体里自加,count才会逐渐递增。
法二:引出pass占位符
思路:遇到7就pass,不是7就打印。
count = 1
while count <= 10:
if count == 7:
pass # pass 占位符
else:
print(count)
count = count + 1
法三:用continue 开阔思路(并不推荐)
count = 1
while count <= 10:
if count == 7:
count = count + 1
continue
print(count)
count = count + 1
法四:笨方法 - 拆分去写 开阔思路
count = 1
while count <= 6:
print(count)
count = count +1
count = 8
while count <= 10:
print(count)
count = count + 1
错误示例:只打印1-6
count = 1
while count <= 10 and count != 7: # 因为到7时,不满足条件会自动跳出循环体。
print(count)
count = count + 1
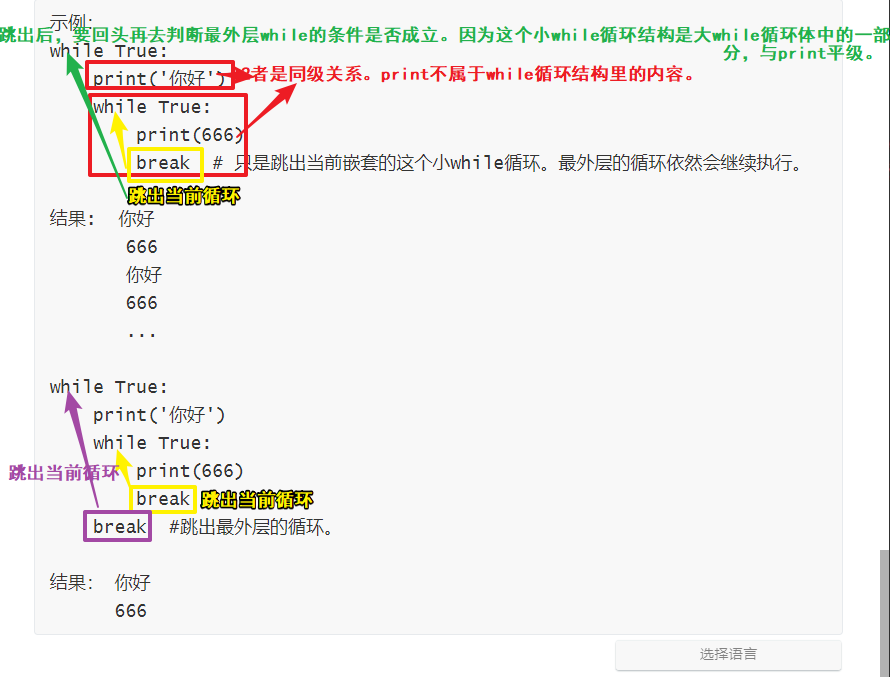
9.2关键字 - break
break - 中止/跳出 当前循环
# 示例:
while True:
print(666)
print('结束') # 打印不到它,因为上面是死循环。
更正:在循环体里加上break,则循环1次后中止循环,打印‘结束’。
while True:
print(666)
break
print('结束')
练习题:
4.通过break 实现打印1-10
count = 1
while True:
print(count)
if count == 10:
break
count = count + 1
print('结束')
注:break - 跳出(中止)当前循环,不是跳出所有循环
9.3关键字 - continue
定义:continue - 本次循环如果遇到continue,则不再继续往下走,而是回到while条件位置重新判断条件是否成立。

练习题:
9.4while else结构(了解)
定义:当不再满足while后的条件时 or 条件=False时,触发else (即执行else里的内容)。
# 示例:
count = 1
while count <= 3:
print(count)
count = count + 1
else: # 当不再满足while后的条件时 or 条件=False时,触发。
print('else代码块')
print('666')
print('结束')
结果:
1
2
3
else代码块
666
结束
注:判断else是否执/触发,只看while后的条件是否还成立即可。

10.运算符
10.1算数运算符
以下假设变量:a=10,b=20
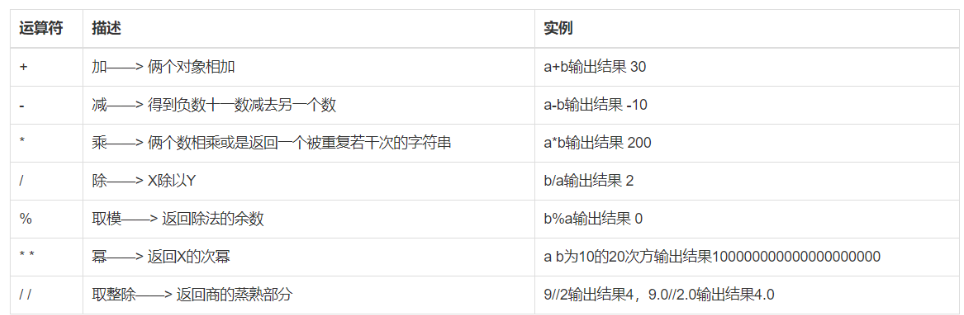
ps:注意 %(取余) 和 //(取整)。
ps:/是普通的除法,//是取整(即只取商的整数部分)
练习题:
1.打印1-100之间的奇数。
法一:取余 -推荐
count = 1
while count <= 100:
if count % 2 == 1:
print(count)
count += 1
法二:自加2 -开阔思路
count = 1
while count <= 100:
print(count)
count = count + 2
2.打印1-100所有数的和
total = 0
count = 1
while count <= 100:
total = total + count
count = count + 1
print(total)
# 5050
3.打印1-2+3-4+5....-100
total = 0
count = 1
while count <= 100:
if count % 2 == 1:
total = total + count
else:
total = total - count
count = count + 1
print(total)
# -50
10.2比较运算符
以下假设变量:a=10,b=20
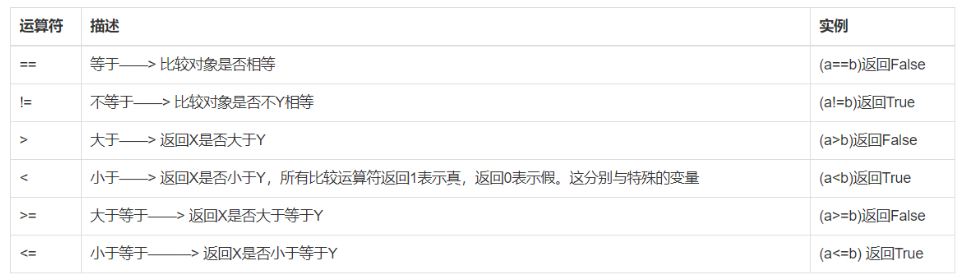
ps-1:if条件语句的条件处一定是比较运算。
ps-2:比较运算的结果是bool值(True/False)。
10.3赋值运算符
以下假设变量:a=10,b=20

(ps:由于格式问题,图上显示出来后有些是错的,知道咋回事就行。)
10.4逻辑运算符 **
10.4.1一般情况下 - 看真。
(适用情形:and/or/not 前后是比较运算)
and:两边都真才是真。
print(1 > 0 and 3 > 1) # True
print(1 > 2 and 3 > 1) # False
or:1边是真则为真。
print(1 > 0 or 3 > 1) #True
print(1 > 2 or 3 > 9) #False
not:取反
print(not 1 > 0) #False
10.4.2二般情况下(面试 and 看源码时) - 看取决于谁。**
(适用情形:and/or/not 前后是2个数,而非比较运算。)
ps:对于 1 or 9 而言,在进行计算时,计算机会默认将 or 前后的数字转换成bool值。但输出的结果不是bool,而是它本身。

a.and - 从左到右看,取决于假/后真的一方。
形如 value = 1 and 9,
判断依据:
左为真,value = 右;
左为假,value = 左;
遇到多个and,则从左到右依次按上述依据判断。
(分析:如何记忆:看取决于谁+假+从左到右看,取决于谁值就是谁。
and:2边都真才是真,1边是假则为假。
故 - 从左到右看,左边是真,则取决于右,值就=右;从左到右看,左边是假,则真取决于左,值就=左。)
# 示例:
value = 1 and 9
print(value) # 9 从左到右,取决于后真
value = 1 and 0
print(value) # 0 取决于后真
value = 0 and 7
print(value) # 0 取决于假
value = 0 and ''
print(value) # 0 取决于假
value = 1 and 0 and 9
print(value) # 0 从左到右,2个一组,依次判断。
b.or - 从左到右看,取决于真的一方。
形如 value = 1 or 9,
判断依据:
左为真,value = 左;
左为假,value = 右;
遇到多个or,则从左到右依次按上述依据判断。
(分析:如何记忆:看取决于谁+真+从左到右看,取决于谁值就是谁。
or:1边是真则为真。
故 - 从左到右看,左边是真,则取决于左,值就=左;从左到右看,左边是假,则真取决于右,值就=右。)
# 示例:
value = 1 or 9
print(value) # 1 从左到右,取决于真
value = 0 or 9
print(value) # 9 取决于真
value = 0 or ''
print('---->',value,'<---') # ----> <--- 取决于真/后假
value = 0 or 9 or 8
= 9 or 8
= 9
print(value) # 9 从左到右,2个一组,依次判断。
c.既有and又有or - 先看优先级。
优先级:( ) > not > and > or,同一优先级从左往右计算。
# Iterview相关
# 示例1:二般情况 - 逻辑前后是数字
value = 0 or 4 and 3 or 7 or 9 and 6
= 0 or (4 and 3) or 7 or (9 and 6) # 先标出优先级
= 0 or 3 or 7 or 6
= 3 or 7 or 6
= 3
# 示例2:二般情况 - 逻辑一边是数字一边bool
# 优先级:比较运算 > 逻辑运算,逻辑运算里 not > and > or
6 or 2 > 1 答案:6
=6 or True # 先算出比较运算的结果
=6
3 or 2 > 1 答案:3
0 or 5 < 4 答案:False
5 < 4 or 3 答案:False
2 > 1 or 6 答案;True
3 and 2 > 1 答案:True
0 and 3 > 1 答案:0
2 > 1 and 3 答案:3
3 > 1 and 0 答案:0
3 > 1 and 2 or 2 < 3 and 3 and 4 or 3 > 2 答案:2
=True and 2 or True and 3 and 4 or True # 先算出比较运算的结果
=(True and 2) or (True and 3 and 4) or True # 再算逻辑运算 优先级:()>and>not>or
=2 or 4 or True
=2
# 示例3:一般情况 - 逻辑前后是比较
# 优先级:比较运算 > 逻辑运算,逻辑运算里 not > and > or
value = 3 > 4 or 4 < 3 and 1 == 1
= (3 > 4) or (4 < 3) and (1 == 1) # 先标出优先级
= False or (False and True)
= False or False
= False
value = 1 < 2 and 3 < 4 or 1 > 2
= (1 < 2) and (3 < 4) or (1 > 2)
= (True and True) or False
= True or False
= False
value = not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
= not (2 > 1) and (3 < 4) or (4 > 5) and (2 > 1) and (9 > 8) or (7 < 6)
= (not True) and True or False and True and True or False
= (False and True) or (False and True and True) or False
= False or False or False
= False
10.5成员运算符
- in
- not in
判断子元素/子序列是否在原字符串(字典,列表,集合)中:
例如:
print('a' in 'yyyy') # False
print('朱' in '吕布姓朱') # True
print('a' not in 'yyyy') # True
示例:让用户输入信息,如果用户输入的信息包含敏感字符,则让其一直输入。直到输入信息中不包含敏感字符为止。
while True:
content = input('请输入内容:')
if '你胖了' in content:
print('包含敏感字符,请重新输入')
else:
print(content)
break
10.6运算符的优先级(了解)
posted on 2019-06-07 20:31 insensate_stone 阅读(283) 评论(0) 编辑 收藏 举报
