k8s-scheduler源码分析
1.调度过程
-
K8S的scheduler的主要作用是将用户申请的pods调度到合适的node节点上。具体的来说,就是它通过监听API server提供的watch等接口,获取到未调度的pods和node的相关信息,通过对node的筛选,选择出最合适的也就是优先级最高的node节点,将其与pods进行绑定,并将绑定的结果固化到etcd中去。
-
kubernetes Scheduler 运行在 master 节点,它的核心功能是监听 apiserver 来获取 PodSpec.NodeName 为空的 pod,然后为每个这样的 pod 创建一个 binding 指示 pod 应该调度到哪个节点上。
从哪里读取还没有调度的 pod 呢?当然是 apiserver。怎么知道 pod 没有调度呢?它会向 apiserver 请求 spec.nodeName 字段为空的 pod,然后调度得到结果之后,把结果写入 apiserver。
-
Scheduler是Kubernetes的调度器,其作用是根据特定的调度算法和策略将Pod调度到指定的计算节点(Node)上,其做为单独的程序运行,启动之后会一直监听API Server,获取PodSpec.NodeName为空的Pod,对每个Pod都会创建一个绑定(binding)。
普通用户可以把Scheduler可理解为一个黑盒,黑盒的输入为待调度的Pod和全部计算节点的信息,经过黑盒内部的调度算法和策略处理,输出为最优的节点,而后将Pod调度该节点上 。
-
如果在预选(Predicates)过程中,如果所有的节点都不满足条件,Pod 会一直处在Pending 状态,直到有节点满足条件,这期间调度器会不断的重试。经过节点过滤后,如多个节点满足条件,会按照节点优先级(priorities)大小对节点排序,最后选择优先级最高的节点部署Pod。
-
优选(Priorities)
经过预选策略(Predicates)对节点过滤后,获取节点列表,再对符合需求的节点列表进行打分,最终选择Pod调度到一个分值最高的节点。Kubernetes用一组优先级函数处理每一个通过预选的节点(kubernetes/plugin/pkg/scheduler/algorithm/priorities中实现)。每一个优先级函数会返回一个0-10的分数,分数越高表示节点越优, 同时每一个函数也会对应一个表示权重的值。最终主机的得分用以下公式计算得出:
finalScoreNode = (weight1 * priorityFunc1) + (weight2 * priorityFunc2) + … + (weightn * priorityFuncn)
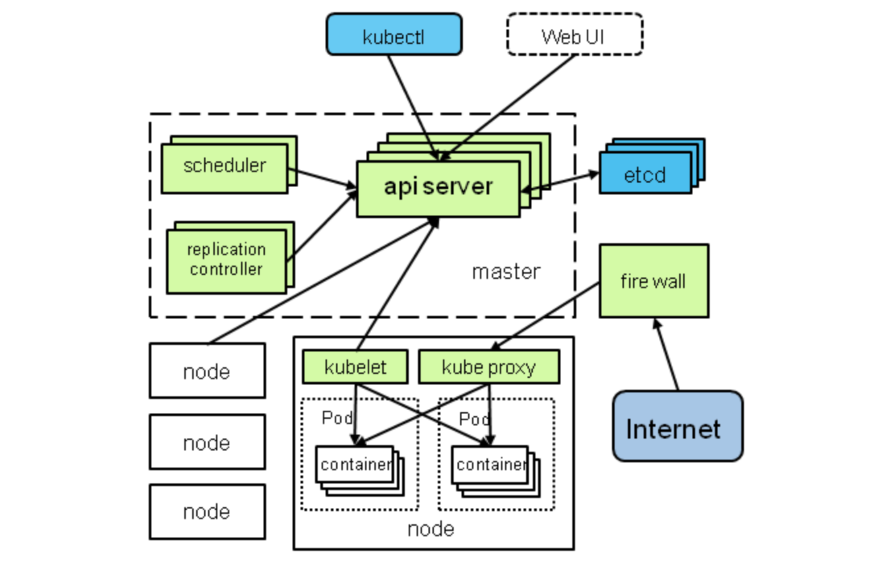
scheduler作为一个客户端,从apiserver中读取到需要分配的pod,和拥有的node,然后进行过滤和算分,最后把这个匹配信息通过apiserver写入到etcd里面,供下一步的kubelet去拉起pod使用。
调度的过程是这样的:
客户端通过 kuberctl 或者 apiserver 提交资源创建的请求,不管是 deployment、replicaset、job 还是 pod,最终都会产生要调度的 pod。
Scheduler它通过监听API server提供的watch等接口,获取到未调度的pods和node的相关信息,循环遍历地为每个 pod 分配节点
调度器会保存集群节点的信息。对每一个 pod,调度器先过滤掉不满足 pod 运行条件的节点,这个过程是 Predicate
通过过滤的节点,调度器会根据一定的算法給它们打分,确定它们的优先级顺序,并选择分数最高的节点作为结果
调度器根据最终选择出来的节点,将其与pods进行绑定,并将绑定的结果固化到etcd中去。

2.schedulerone
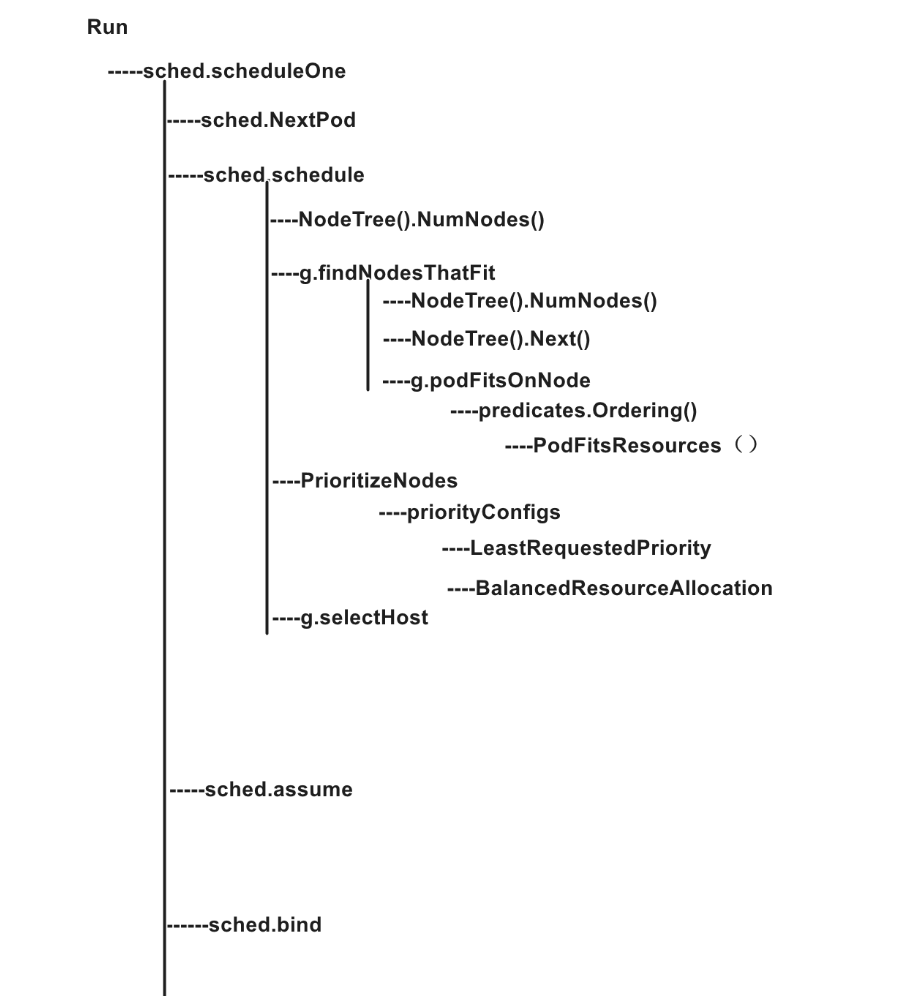
假设我们的集群通过创建 scheduler 的配置文件,加载默认的调度算法,通过启动时指定的 policy source 加载 config,已经初始化好了scheduler对象sched。现在我们开始调用run方法,这个run循环执行scheduleOne方法。
//k8s.io/kubernetes/pkg/scheduler/scheduler.go:313
func (sched *Scheduler) Run() {
if !sched.config.WaitForCacheSync() {
return
}
go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)
}
scheduleOne() 每次对一个 pod 进行调度,主要有以下步骤:
- 从 scheduler 调度队列中取出一个 pod,如果该 pod 处于删除状态则跳过
- 执行调度逻辑
sched.schedule()返回通过预算及优选算法过滤后选出的最佳 node - 如果过滤算法没有选出合适的 node,则返回 core.FitError
- 若没有合适的 node 会判断是否启用了抢占策略,若启用了则执行抢占机制
- pod 对应的 spec.NodeName 写上 scheduler 最终选择的 node,更新 scheduler cache
- 请求 apiserver 异步处理最终的绑定操作,写入到 etcd
//k8s.io/kubernetes/pkg/scheduler/scheduler.go:515
func (sched *Scheduler) scheduleOne() {
fwk := sched.Framework
//调用NextPod()方法,来获取下一个还未调度的pods的信息
pod := sched.NextPod()
if pod == nil {
return
}
// 1.判断pods是否已经被删除,如果已经被删除,那么直接返回
if pod.DeletionTimestamp != nil {
......
}
// 2.执行调度策略选择 node,来获取合适的node
start := time.Now()
pluginContext := framework.NewPluginContext()
scheduleResult, err := sched.schedule(pod, pluginContext)
if err != nil {
if fitError, ok := err.(*core.FitError); ok {
// 3.这里是调度失败的结果,如果调度失败了,那么他就会在一定的时间内将这个pods在此加载回调度的pods队列中。若启用抢占机制则执行
if sched.DisablePreemption {
......
} else {
preemptionStartTime := time.Now()
sched.preempt(pluginContext, fwk, pod, fitError)
......
}
......
metrics.PodScheduleFailures.Inc()
} else {
klog.Errorf("error selecting node for pod: %v", err)
metrics.PodScheduleErrors.Inc()
}
return
}
......
assumedPod := pod.DeepCopy()
allBound, err := sched.assumeVolumes(assumedPod, scheduleResult.SuggestedHost)
if err != nil {
klog.Errorf("error assuming volumes: %v", err)
metrics.PodScheduleErrors.Inc()
return
}
if sts := fwk.RunReservePlugins(pluginContext, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {
.....
}
// 4.为 pod 设置 NodeName 字段,更新 scheduler 缓存
//在选择出来合适的node节点的时候,先将这个node 的资源分配给它,但是暂时并不将其绑定,固化到etcd中,而是先将其存起来,但是这里注意,
//node的资源已经假设分给pods了,node的资源信息就发生了变化,这是为了可以多线程的往etcd中固化信息,可以提高效率。
//将 host 填入到 pod spec字段的nodename,假定分配到对应的节点上
err = sched.assume(assumedPod, scheduleResult.SuggestedHost)
if err != nil {
......
}
// 5.异步请求 apiserver,异步处理最终的绑定操作,写入到 etcd
go func() {
err := sched.bind(bindingCycleCtx, prof, assumedPod, scheduleResult.SuggestedHost, state)
if err != nil {
......
return
}
}
......
}
}()
}
3.scheduler
scheduleOne() 中通过调用 sched.schedule() 来执行预选与优选算法处理:
//k8s.io/kubernetes/pkg/scheduler/scheduler.go:337
func (sched *Scheduler) schedule(pod *v1.Pod, pluginContext *framework.PluginContext) (core.ScheduleResult, error) {
result, err := sched.Algorithm.Schedule(pod, pluginContext)
if err != nil {
......
}
return result, err
}
sched.Algorithm 是一个 interface,主要包含四个方法,GenericScheduler 是其具体的实现:
//k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go:131
type ScheduleAlgorithm interface {
Schedule(*v1.Pod, *framework.PluginContext) (scheduleResult ScheduleResult, err error)
Preempt(*framework.PluginContext, *v1.Pod, error) (selectedNode *v1.Node, preemptedPods []*v1.Pod, cleanupNominatedPods []*v1.Pod, err error)
Predicates() map[string]predicates.FitPredicate
Prioritizers() []priorities.PriorityConfig
}
Schedule():正常调度逻辑,包含预算与优选算法的执行Preempt():抢占策略,在 pod 调度发生失败的时候尝试抢占低优先级的 pod,函数返回发生抢占的 node,被 抢占的 pods 列表,nominated node name 需要被移除的 pods 列表以及 errorPredicates():predicates 算法列表Prioritizers():prioritizers 算法列表
Schedule的执行流程:
- 执行
g.findNodesThatFit()预选算法 - 执行 postfilter plugin
- 若 node 为 0 直接返回失败的 error,若 node 数为1 直接返回该 node
- 执行
g.priorityMetaProducer()获取 metaPrioritiesInterface,计算 pod 的metadata,检查该 node 上是否有相同 meta 的 pod - 执行
PrioritizeNodes()算法 - 执行
g.selectHost()通过得分选择一个最佳的 node
//k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go:186
func (g *genericScheduler) Schedule(pod *v1.Pod, pluginContext *framework.PluginContext) (result ScheduleResult, err error) {
......
// 1.获取 node 数量
numNodes := g.cache.NodeTree().NumNodes()
if numNodes == 0 {
return result, ErrNoNodesAvailable
}
// 2.执行预选过滤算法
startPredicateEvalTime := time.Now()
filteredNodes, failedPredicateMap, filteredNodesStatuses, err := g.findNodesThatFit(pluginContext, pod)
if err != nil {
return result, err
}
postfilterStatus := g.framework.RunPostFilterPlugins(pluginContext, pod, filteredNodes, filteredNodesStatuses)
if !postfilterStatus.IsSuccess() {
return result, postfilterStatus.AsError()
}
//没有可用节点,直接报错
if len(filteredNodes) == 0 {
......
}
startPriorityEvalTime := time.Now()
// 3.若只有一个 node 则直接返回该 node
if len(filteredNodes) == 1 {
return ScheduleResult{
SuggestedHost: filteredNodes[0].Name,
EvaluatedNodes: 1 + len(failedPredicateMap),
FeasibleNodes: 1,
}, nil
}
// 4.获取 pod meta 信息,执行优选算法
metaPrioritiesInterface := g.priorityMetaProducer(pod, g.nodeInfoSnapshot.NodeInfoMap)
priorityList, err := PrioritizeNodes(pod, g.nodeInfoSnapshot.NodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders, g.framework, pluginContext)
if err != nil {
return result, err
}
// 5.根据打分选择最佳的 node,selectHost先对每个pod调度到每个节点上的分值排序,选择出分数最高的
host, err := g.selectHost(priorityList)
trace.Step("Selecting host done")
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(filteredNodes) + len(failedPredicateMap),
FeasibleNodes: len(filteredNodes),
}, err
}
4.predicates 调度算法源码分析
predicates 算法主要是对集群中的 node 进行过滤,选出符合当前 pod 运行的 nodes。
默认的 predicates 过滤算法主要分为五种类型:
1、最重要的一种类型叫作 GeneralPredicates,主要考虑 kubernetes 资源是否能够满足,比如 CPU 和 Memory 是否足够,端口是否冲突、selector 是否匹配。包含 PodFitsResources、PodFitsHost、PodFitsHostPorts、PodMatchNodeSelector 四种策略,其具体含义如下所示:
- PodFitsHost:检查宿主机的名字是否跟 Pod 的 spec.nodeName 一致,只有匹配的节点才能运行 pod
- PodFitsHostPorts:检查 Pod 申请的宿主机端口(spec.nodePort)是不是跟已经被使用的端口有冲突,如果是,则不能调度
- PodMatchNodeSelector:检查 Pod 的 nodeSelector 或者 nodeAffinity 指定的节点是否与节点匹配等
- PodFitsResources:检查主机的资源是否满足 Pod 的需求,资源的计算是根据主机上运行 pod 请求的资源作为参考的,而不是以实际运行的资源数量。
findNodesThatFit() 是 predicates 策略的实际调用方法,调度器的输入是一个 pod(多个 pod 调度可以通过遍历来实现) 和多个节点,输出是一个节点,表示 pod 将被调度到这个节点上。其基本流程如下:
- 通过 cache 中的
NodeTree()不断获取下一个 node - 将当前 node 和 pod 传入
podFitsOnNode()方法中来判断当前 node 是否符合要求 - 如果当前 node 符合要求就将当前 node 加入预选节点的数组中
filtered - 如果当前 node 不满足要求,则加入到失败的数组中,并记录原因
- 通过
workqueue.ParallelizeUntil()并发执行checkNode()函数,一旦找到足够的可行节点数后就停止筛选更多节点 - 若配置了 extender 则再次进行过滤已筛选出的 node
- 最后返回满足调度条件的 node 列表,供下一步的优选操作
//k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go:464
func (g *genericScheduler) findNodesThatFit(pluginContext *framework.PluginContext, pod *v1.Pod) ([]*v1.Node, FailedPredicateMap, framework.NodeToStatusMap, error) {
//filtered 保存通过过滤的节点
var filtered []*v1.Node
//failedPredicateMap 保存过滤失败的节点,即不适合 pod 运行的节点,没有通过过滤的节点信息保存在 failedPredicateMap 字典中,key 是节点名,value 是失败原因的列表;
failedPredicateMap := FailedPredicateMap{}
filteredNodesStatuses := framework.NodeToStatusMap{}
if len(g.predicates) == 0 {
filtered = g.cache.ListNodes()
} else {
allNodes := int32(g.cache.NodeTree().NumNodes())
// 1.设定最多需要检查的节点数
numNodesToFind := g.numFeasibleNodesToFind(allNodes)
filtered = make([]*v1.Node, numNodesToFind)
......
// 2.获取该 pod 的 meta 值 ,利用metadataProducer函数来获取pods和node的信息
meta := g.predicateMetaProducer(pod, g.nodeInfoSnapshot.NodeInfoMap)
// 3.通过 cache 中的 `NodeTree()` 不断获取下一个 node
checkNode := func(i int) {
nodeName := g.cache.NodeTree().Next()
// 4.将当前 node 和 pod 传入`podFitsOnNode()` 方法中来判断当前 node 是否符合要求
fits, failedPredicates, status, err := g.podFitsOnNode(
......
)
if err != nil {
......
}
if fits {
length := atomic.AddInt32(&filteredLen, 1)
if length > numNodesToFind {
cancel()
atomic.AddInt32(&filteredLen, -1)
} else {
filtered[length-1] = g.nodeInfoSnapshot.NodeInfoMap[nodeName].Node()
}
} else {
......
}
}
// 5.启动 16 个 goroutine 并发执行 checkNode 函数
workqueue.ParallelizeUntil(ctx, 16, int(allNodes), checkNode)
filtered = filtered[:filteredLen]
if len(errs) > 0 {
......
}
}
// 6.若配置了 extender 则再次进行过滤
if len(filtered) > 0 && len(g.extenders) != 0 {
......
}
return filtered, failedPredicateMap, filteredNodesStatuses, nil
}
对于每个 pod,都要检查能否调度到集群中的所有节点上(只包括可调度的节点),而且多个判断逻辑之间是独立的,也就是说 pod 是否能否调度到某个 node 上和其他 node 无关(至少目前是这样的,如果这个假设不再成立,并发要考虑协调的问题),所以可以使用并发来提高性能。并发是通过 workQueue 来实现的,最大并发数量是 16,这个数字是 hard code。
pod 和 node 是否匹配是调用是 podFitsOnNode 函数来判断的:
podFitsOnNode()基本流程如下:
- 遍历已经注册好的预选策略predicates.Ordering(),按顺序执行对应的策略函数
- 遍历执行每个策略函数,并返回是否合适,预选失败的原因和错误
- 如果预选函数执行失败,则加入预选失败的数组中,直接返回,后面的预选函数不会再执行
- 如果该 node 上存在 nominated pod 则执行两次预选函数
因为引入了抢占机制,此处主要说明一下执行两次预选函数的原因:
第一次循环,若该 pod 为抢占者(nominatedPods),调度器会假设该 pod 已经运行在这个节点上,然后更新meta和nodeInfo,nominatedPods是指执行了抢占机制且已经分配到了 node(pod.Status.NominatedNodeName 已被设定) 但是还没有真正运行起来的 pod,然后再执行所有的预选函数。
第二次循环,不将nominatedPods加入到 node 内。
而只有这两遍 predicates 算法都能通过时,这个 pod 和 node 才会被认为是可以绑定(bind)的。这样做是因为考虑到 pod affinity 等策略的执行,如果当前的 pod 与nominatedPods有依赖关系就会有问题,因为nominatedPods不能保证一定可以调度且在已指定的 node 运行成功,也可能出现被其他高优先级的 pod 抢占等问题,关于抢占问题下篇会详细介绍。
//k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go:610
func (g *genericScheduler) podFitsOnNode(......) (bool, []predicates.PredicateFailureReason, *framework.Status, error) {
var failedPredicates []predicates.PredicateFailureReason
var status *framework.Status
podsAdded := false
for i := 0; i < 2; i++ {
metaToUse := meta
nodeInfoToUse := info
if i == 0 {
// 1.第一次循环加入 NominatedPods,计算 meta, nodeInfo
podsAdded, metaToUse, nodeInfoToUse = addNominatedPods(pod, meta, info, queue)
} else if !podsAdded || len(failedPredicates) != 0 {
break
}
// 2.按顺序执行所有预选函数
for _, predicateKey := range predicates.Ordering() {
var (
fit bool
reasons []predicates.PredicateFailureReason
err error
)
if predicate, exist := predicateFuncs[predicateKey]; exist {
fit, reasons, err = predicate(pod, metaToUse, nodeInfoToUse)
if err != nil {
return false, []predicates.PredicateFailureReason{}, nil, err
}
// 3.任何一个预选函数执行失败则直接返回
if !fit {
failedPredicates = append(failedPredicates, reasons...)
if !alwaysCheckAllPredicates {
klog.V(5).Infoln("since alwaysCheckAllPredicates has not been set, the predicate " +
"evaluation is short circuited and there are chances " +
"of other predicates failing as well.")
break
}
}
}
}
// 4.执行 Filter Plugin
status = g.framework.RunFilterPlugins(pluginContext, pod, info.Node().Name)
if !status.IsSuccess() && !status.IsUnschedulable() {
return false, failedPredicates, status, status.AsError()
}
}
return len(failedPredicates) == 0 && status.IsSuccess(), failedPredicates, status, nil
}
下面是资源判断的主要方法PodFitsResources():
func PodFitsResources(pod *v1.Pod, meta algorithm.PredicateMetadata, nodeInfo *schedulercache.NodeInfo) (bool, []algorithm.PredicateFailureReason, error) {
node := nodeInfo.Node()
if node == nil {
return false, nil, fmt.Errorf("node not found")
}
var predicateFails []algorithm.PredicateFailureReason
//判断node节点上的pods个数是否已经超出了允许分配的个数
allowedPodNumber := nodeInfo.AllowedPodNumber()
if len(nodeInfo.Pods())+1 > allowedPodNumber {
predicateFails = append(predicateFails, NewInsufficientResourceError(v1.ResourcePods, 1, int64(len(nodeInfo.Pods())), int64(allowedPodNumber)))
}
//获取pods的需求的资源
var podRequest *schedulercache.Resource
if predicateMeta, ok := meta.(*predicateMetadata); ok {
podRequest = predicateMeta.podRequest
} else {
// We couldn't parse metadata - fallback to computing it.
podRequest = GetResourceRequest(pod)
}
if podRequest.MilliCPU == 0 &&
podRequest.Memory == 0 &&
podRequest.NvidiaGPU == 0 &&
podRequest.EphemeralStorage == 0 &&
len(podRequest.ExtendedResources) == 0 &&
len(podRequest.HugePages) == 0 {
return len(predicateFails) == 0, predicateFails, nil
}
//对四个方面的进行判断,内存、cpu、Gpu、磁盘空间,这里就是简单的比较大小。
allocatable := nodeInfo.AllocatableResource()
if allocatable.MilliCPU < podRequest.MilliCPU+nodeInfo.RequestedResource().MilliCPU {
predicateFails = append(predicateFails, NewInsufficientResourceError(v1.ResourceCPU, podRequest.MilliCPU, nodeInfo.RequestedResource().MilliCPU, allocatable.MilliCPU))
}
if allocatable.Memory < podRequest.Memory+nodeInfo.RequestedResource().Memory {
predicateFails = append(predicateFails, NewInsufficientResourceError(v1.ResourceMemory, podRequest.Memory, nodeInfo.RequestedResource().Memory, allocatable.Memory))
}
if allocatable.NvidiaGPU < podRequest.NvidiaGPU+nodeInfo.RequestedResource().NvidiaGPU {
predicateFails = append(predicateFails, NewInsufficientResourceError(v1.ResourceNvidiaGPU, podRequest.NvidiaGPU, nodeInfo.RequestedResource().NvidiaGPU, allocatable.NvidiaGPU))
}
if allocatable.EphemeralStorage < podRequest.EphemeralStorage+nodeInfo.RequestedResource().EphemeralStorage {
predicateFails = append(predicateFails, NewInsufficientResourceError(v1.ResourceEphemeralStorage, podRequest.EphemeralStorage, nodeInfo.RequestedResource().EphemeralStorage, allocatable.EphemeralStorage))
}
..........
return len(predicateFails) == 0, predicateFails, nil
}
5.priorities 调度算法源码分析
对每个节点,priority 函数都会计算出来一个 0-10 之间的数字,表示 pod 放到该节点的合适程度,其中 10 表示非常合适,0 表示非常不合适。每个不同的优先级函数都有一个权重值,这个值为正数,最终的值为权重和优先级函数结果的乘积,而一个节点的权重就是所有优先级函数结果的加和。比如有两种优先级函数 priorityFunc1 和 priorityFunc2,对应的权重分别为 weight1 和 weight2,那么节点 A 的最终得分是:
finalScoreNodeA = (weight1 * priorityFunc1) + (weight2 * priorityFunc2)
执行 priorities 调度算法的逻辑是在 PrioritizeNodes()函数中,其目的是执行每个 priority 函数为 node 打分,分数为 0-10,其功能主要有:
PrioritizeNodes()通过并行运行各个优先级函数来对节点进行打分- 每个优先级函数会给节点打分,打分范围为 0-10 分,0 表示优先级最低的节点,10表示优先级最高的节点
- 每个优先级函数有各自的权重
- 优先级函数返回的节点分数乘以权重以获得加权分数
- 最后计算所有节点的总加权分数
//k8s.io/kubernetes/pkg/scheduler/core/generic_scheduler.go:691
func PrioritizeNodes(......) (schedulerapi.HostPriorityList, error) {
// 1.检查是否有自定义配置,如果没有选择优先级判断这一项,那么所有的节点的优先级是一样的,那就随机选择一个节点
if len(priorityConfigs) == 0 && len(extenders) == 0 {
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
for i := range nodes {
hostPriority, err := EqualPriorityMap(pod, meta, nodeNameToInfo[nodes[i].Name])
if err != nil {
return nil, err
}
result = append(result, hostPriority)
}
return result, nil
}
......
//建立一个二维数组来记录每个优先级算法对节点的打分情况,分值为0-10,node节点的最终分值是所有优先级算法分值的相加
results := make([]schedulerapi.HostPriorityList, len(priorityConfigs), len(priorityConfigs))
......
// 2.使用 workqueue 启动 16 个 goroutine ,从priorityConfigs中遍历其中的优先级算法,并打分
workqueue.ParallelizeUntil(context.TODO(), 16, len(nodes), func(index int) {
nodeInfo := nodeNameToInfo[nodes[index].Name]
for i := range priorityConfigs {
if priorityConfigs[i].Function != nil {
continue
}
var err error
results[i][index], err = priorityConfigs[i].Map(pod, meta, nodeInfo)
if err != nil {
appendError(err)
results[i][index].Host = nodes[index].Name
}
}
})
//等待所有计算结束
wg.Wait()
if len(errs) != 0 {
return schedulerapi.HostPriorityList{}, errors.NewAggregate(errs)
}
scoresMap, scoreStatus := framework.RunScorePlugins(pluginContext, pod, nodes)
if !scoreStatus.IsSuccess() {
return schedulerapi.HostPriorityList{}, scoreStatus.AsError()
}
//打分完之后,进行分数的汇总操作,为每个 node 汇总分数
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
for i := range nodes {
result = append(result, schedulerapi.HostPriority{Host: nodes[i].Name, Score: 0})
for j := range priorityConfigs {
result[i].Score += results[j][i].Score * priorityConfigs[j].Weight
}
for j := range scoresMap {
result[i].Score += scoresMap[j][i].Score
}
}
return result, nil
}
对于优先级函数,我们只讲解 LeastRequestedPriority 和 BalancedResourceAllocation 的实现,因为它们两个和资源密切相关。
- LeastRequestedPriority:最低请求优先级。根据 CPU 和内存的使用率来决定优先级,使用率越低优先级越高,也就是说优先调度到资源利用率低的节点,这个优先级函数能起到把负载尽量平均分到集群的节点上。默认权重为 1
- BalancedResourceAllocation:资源平衡分配。这个优先级函数会把 pod 分配到 CPU 和 memory 利用率差不多的节点(计算的时候会考虑当前 pod 一旦分配到节点的情况)。默认权重为 1
最小资源请求优先级函数会计算每个节点的资源利用率,它目前只考虑 CPU 和内存两种资源,而且两者权重相同,具体的资源公式为:
score = (CPU Usage rate * 10 + Memory Usage Rate * 10 )/2
利用率的计算一样,都是 (capacity - requested)/capacity,capacity 指节点上资源的容量,比如 CPU 的核数,内存的大小;requested 表示节点当前所有 pod 请求对应资源的总和。
平衡资源优先级函数会计算 CPU 和内存的平衡度,并尽量选择更均衡的节点。它会分别计算 CPU 和内存的,计算公式为:
10 - abs(cpuFraction - memoryFraction)*101
对应的 cpuFraction 和 memoryFraction 就是资源利用率
6.代码整体思路
参考链接:
kubernetes之Scheduler分析_纵横四海的博客-CSDN博客
https://blog.tianfeiyu.com/source-code-reading-notes/kubernetes/kube_scheduler_process.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号