python3.7爬取唐探3,李焕英豆瓣短评,来一波词云秀
过完春节的最近几天,大家纷纷走进电影院,和家人或者朋友或者恋人一同观看好看的电影吧。听说大年初一第一天唐探3售出10万张电影票,比李焕英的多了3倍还多。不过最近几天大家对唐探3的期望大幅度下降了,而李焕英成为了一匹黑马,票房不断攀升。迎来了:再见,唐探3;你好,李焕英!的场面,下面让我们看看豆瓣影评里的各位伙伴的评论吧!
1 第三方包的安装
1.1wordcloud的安装:
https://www.lfd.uci.edu/~gohlke/pythonlibs/ 这个链接里面有很多第三方包,“ctrl+F"搜索就可以了
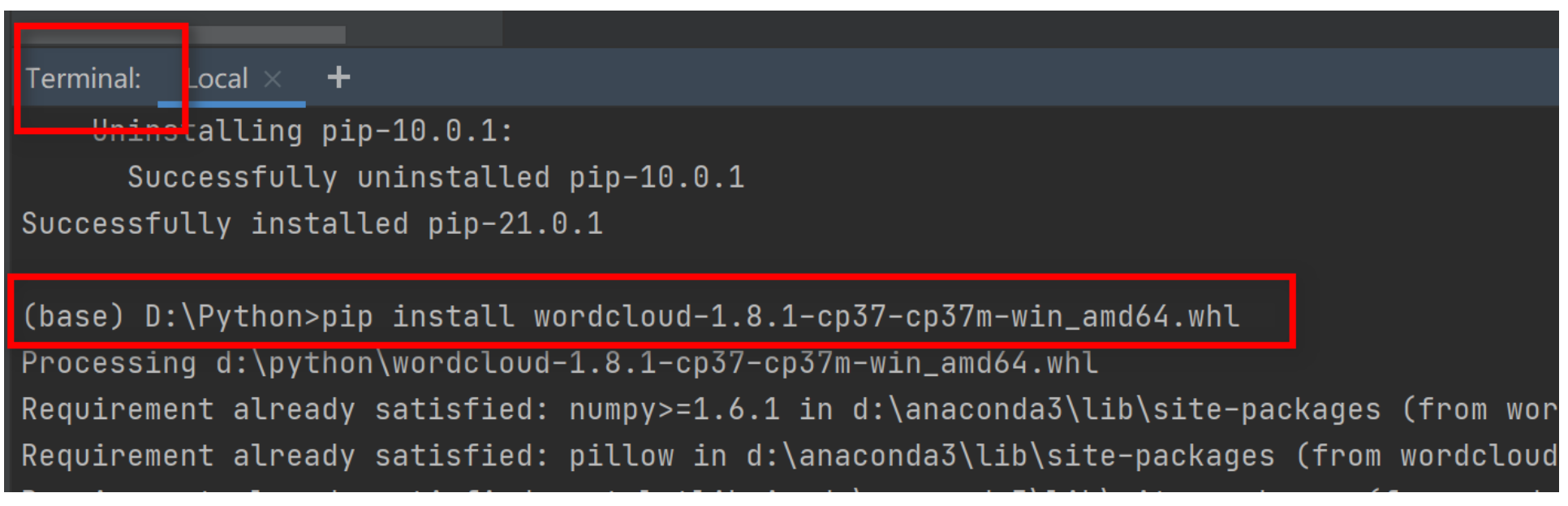
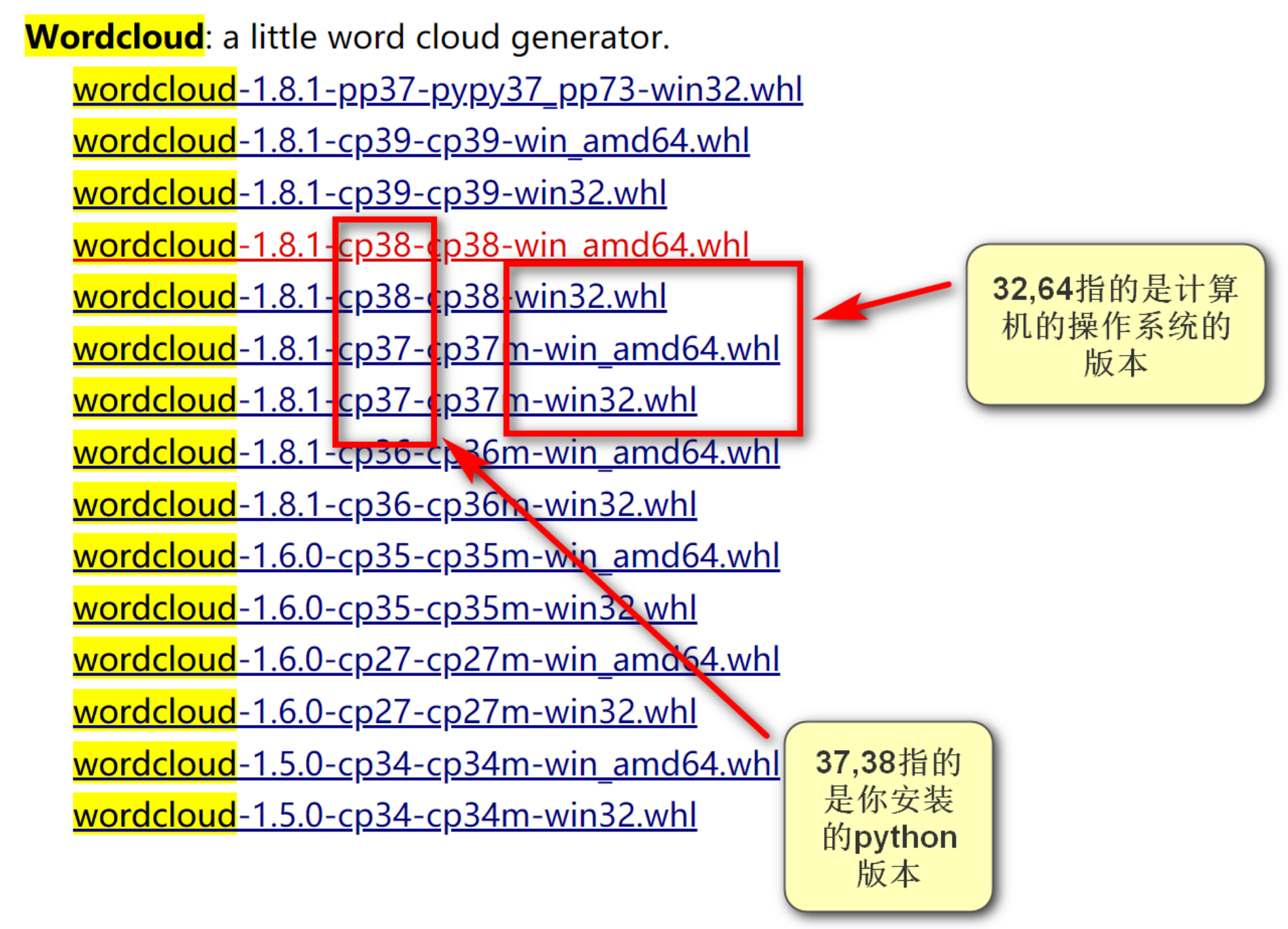 打开pycharm,在终端输入安装命令
打开pycharm,在终端输入安装命令
1.2jieba包的安装
jieba按照中文习惯把很多文字进行分词。
2 爬取豆瓣短评(以唐探3为例)
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P % (movie_id, (i - 1) * 20)
其中i代表当前页码,从0开始。
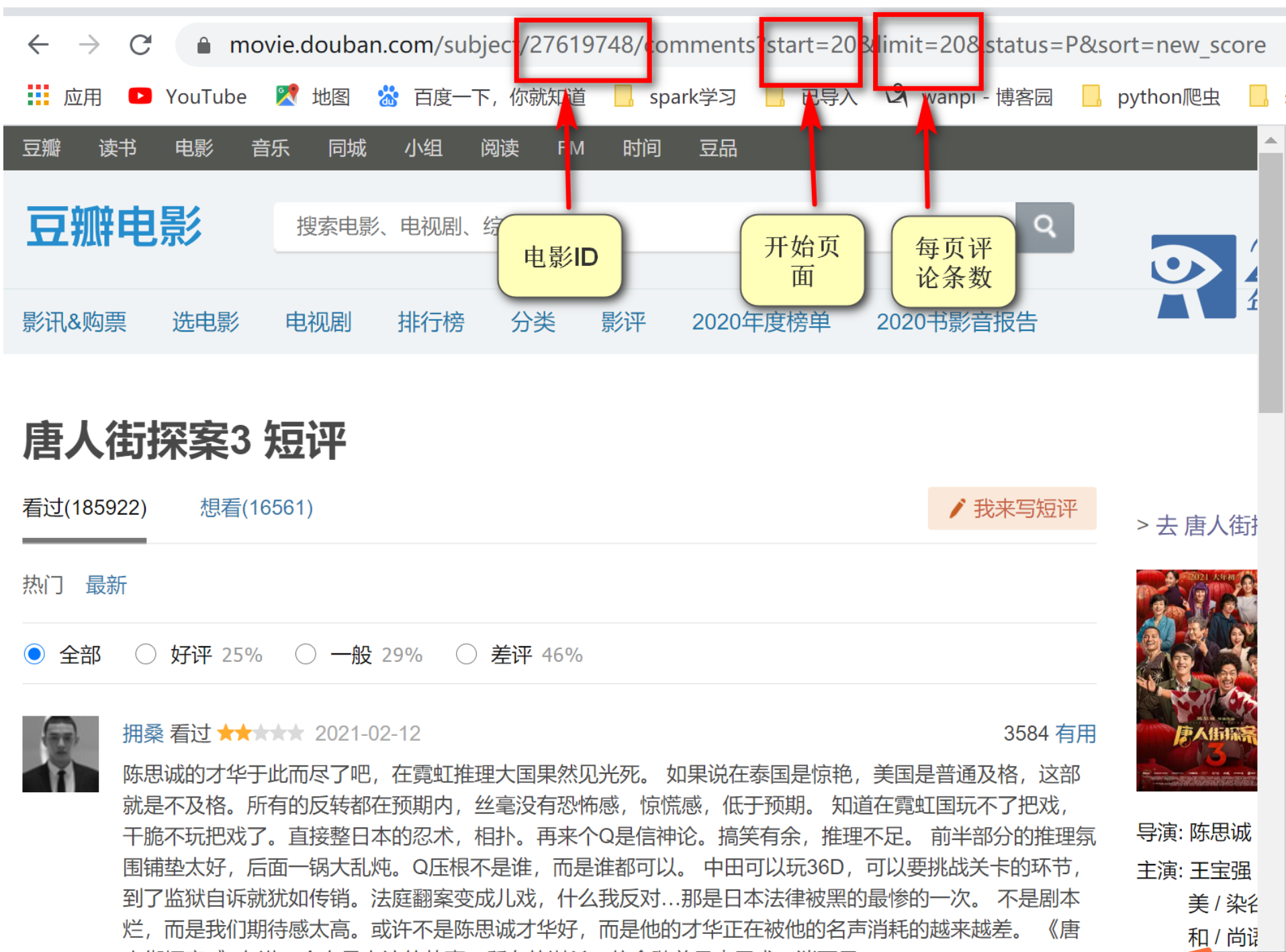
我们在谷歌浏览器右键,点击“检查”,查看源代码,找到短评的代码位置,查看位于哪个div,哪个标签下
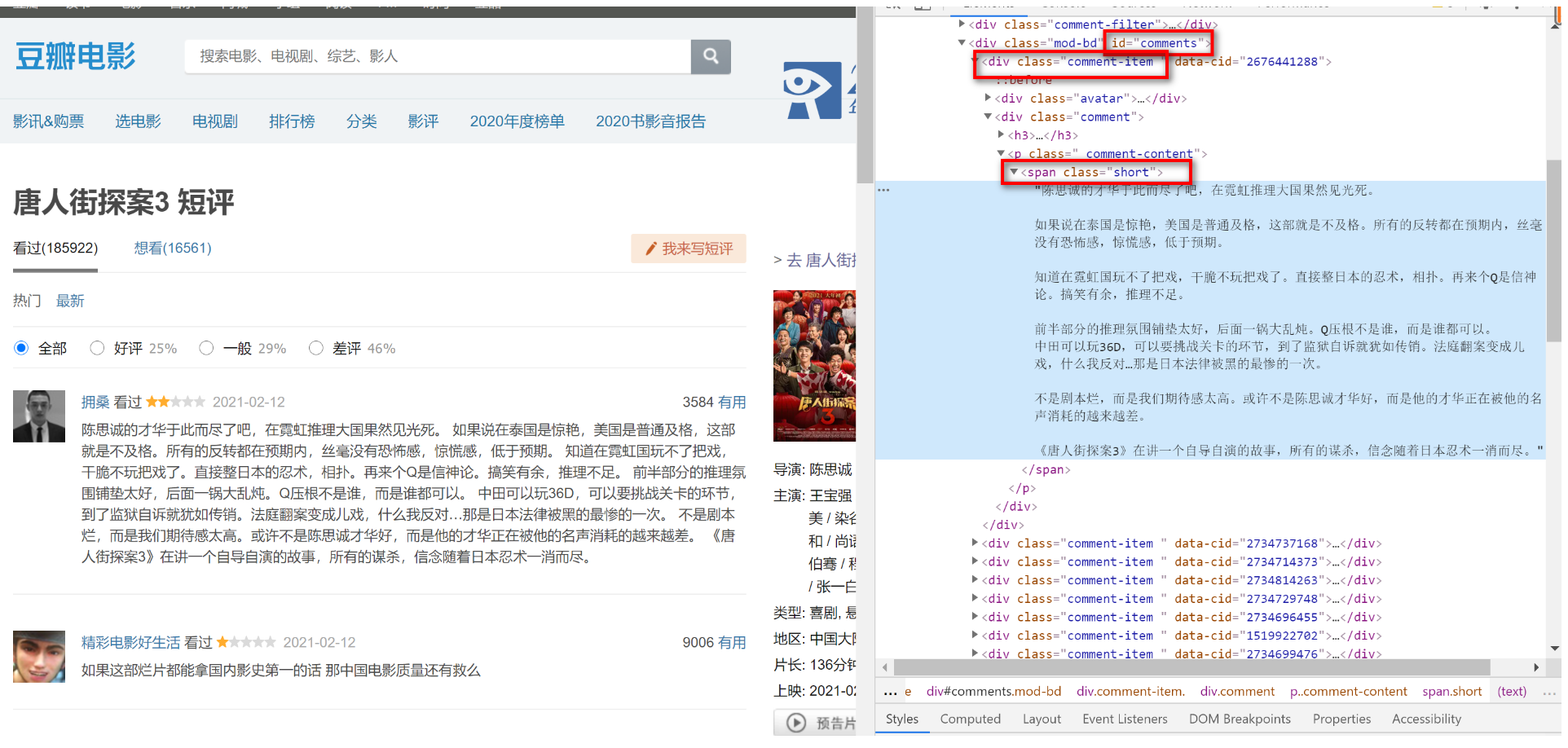
分析源码,可以看到评论在div[id=‘comments’]下的div[class=‘comment-item’]中的第一个span[class=‘short’]中,使用正则表达式提取短评内容,即代码为:
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P' \ % (movie_id, (i - 1) * 20) req = requests.get(url, headers=headers) req.encoding = 'utf-8' comments = re.findall('<span class="short">(.*)</span>', req.text)
with open(file_name, 'r', encoding='utf8') as f: word_list = jieba.cut(f.read()) result = " ".join(word_list) # 分词用 隔开
if icon_name is not None and len(icon_name) > 0: gen_stylecloud(text=result, icon_name=icon_name, font_path='simsun.ttc', output_name=pic) else: gen_stylecloud(text=result, font_path='simsun.ttc', output_name=pic)
完整代码如下:
# 分析豆瓣唐探3的影评,生成词云 # https://movie.douban.com/subject/27619748/comments?start=20&limit=20&status=P&sort=new_score # url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P '\ # % (movie_id, (i - 1) * 20) import requests from stylecloud import gen_stylecloud import jieba import re from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0' } def jieba_cloud(file_name, icon): with open(file_name, 'r', encoding='utf8') as f: word_list = jieba.cut(f.read()) result = " ".join(word_list) # 分词用 隔开 # 制作中文词云 icon_name = " " if icon == "1": icon_name = '' elif icon == "2": icon_name = "fas fa-dragon" elif icon == "3": icon_name = "fas fa-dog" elif icon == "4": icon_name = "fas fa-cat" elif icon == "5": icon_name = "fas fa-dove" elif icon == "6": icon_name = "fab fa-qq" pic = str(icon) + '.png' if icon_name is not None and len(icon_name) > 0: gen_stylecloud(text=result, icon_name=icon_name, font_path='simsun.ttc', output_name=pic) else: gen_stylecloud(text=result, font_path='simsun.ttc', output_name=pic) return pic def spider_comment(movie_id, page): comment_list = [] with open("douban.txt", "a+", encoding='utf-8') as f: for i in range(1,page+1): url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P' \ % (movie_id, (i - 1) * 20) req = requests.get(url, headers=headers) req.encoding = 'utf-8' comments = re.findall('<span class="short">(.*)</span>', req.text) f.writelines('\n'.join(comments)) print(comments) # 主函数 if __name__ == '__main__': movie_id = '27619748' page = 10 spider_comment(movie_id, page) jieba_cloud("douban.txt", "1") jieba_cloud("douban.txt", "2") jieba_cloud("douban.txt", "3") jieba_cloud("douban.txt", "4") jieba_cloud("douban.txt", "5") jieba_cloud("douban.txt", "6")
生成的douban.txt如下:(部分)
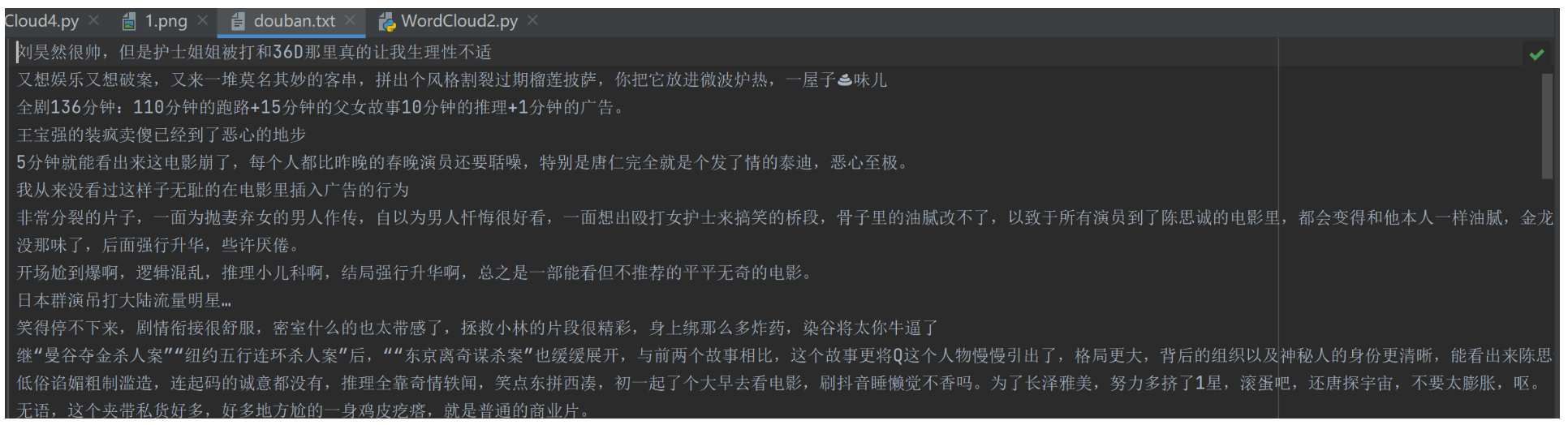



5 李焕英词云秀
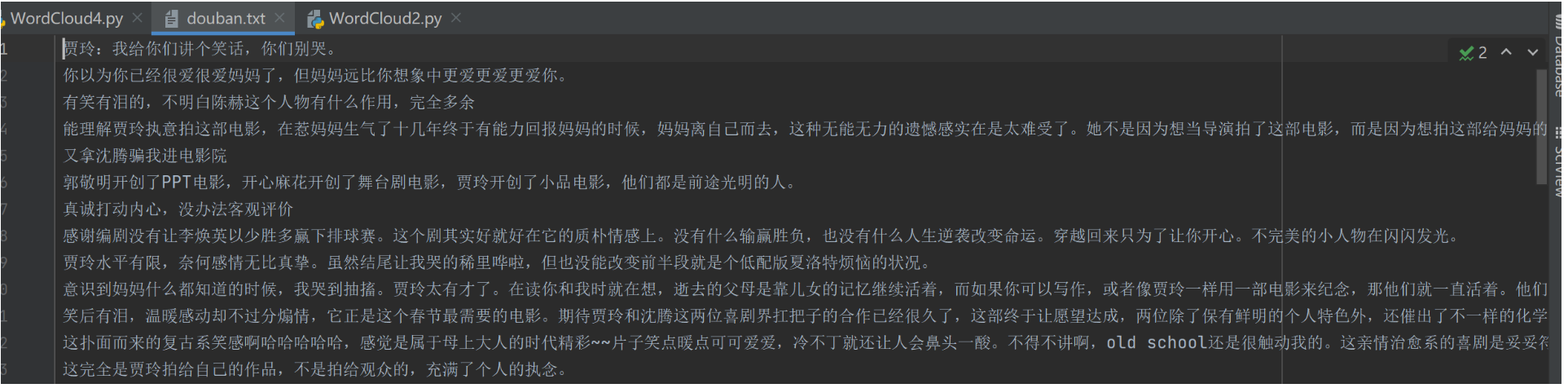
代码采用上面的,更换一下movie_id,结果如下:




 浙公网安备 33010602011771号
浙公网安备 33010602011771号