在IDEA上运行spark时遇到的Q&A
问题:Could not locate executable null\bin\winutils.exe in the Hadoop binaries

解决:缺少winutils.exe程序。 Hadoop都是运行在Linux系统下的,在windows下的IDEA中运行mapreduce程序,要首先安装Windows下运行的支持插件。注意下载的winutils.exe要和你hadoop版本一致。
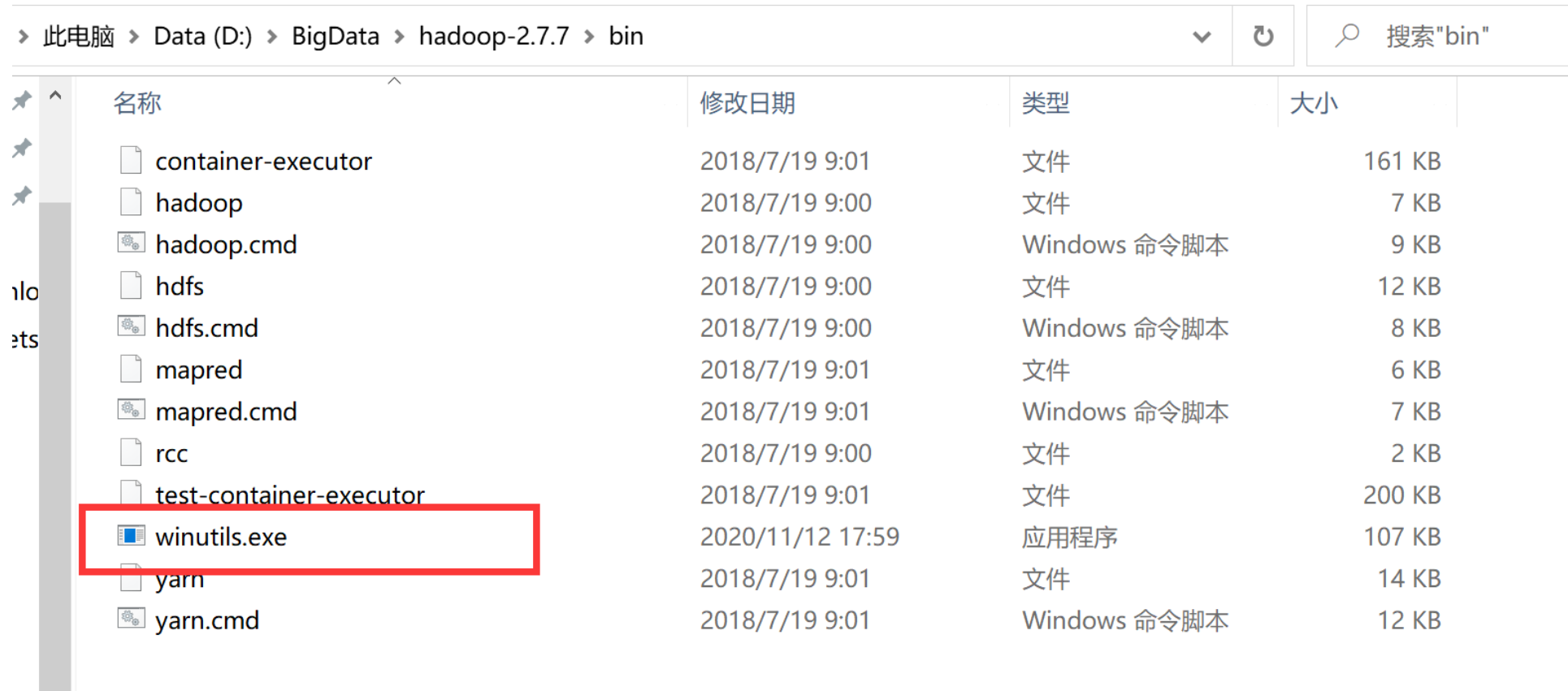
①:下载winutils.exe。hadoop-2.6.5至hadoop-3.2.1的winutils.exe见:https://github.com/cdarlint/winutils
然后把winutils.exe添加到你的hadoop安装包目录下的bin下:
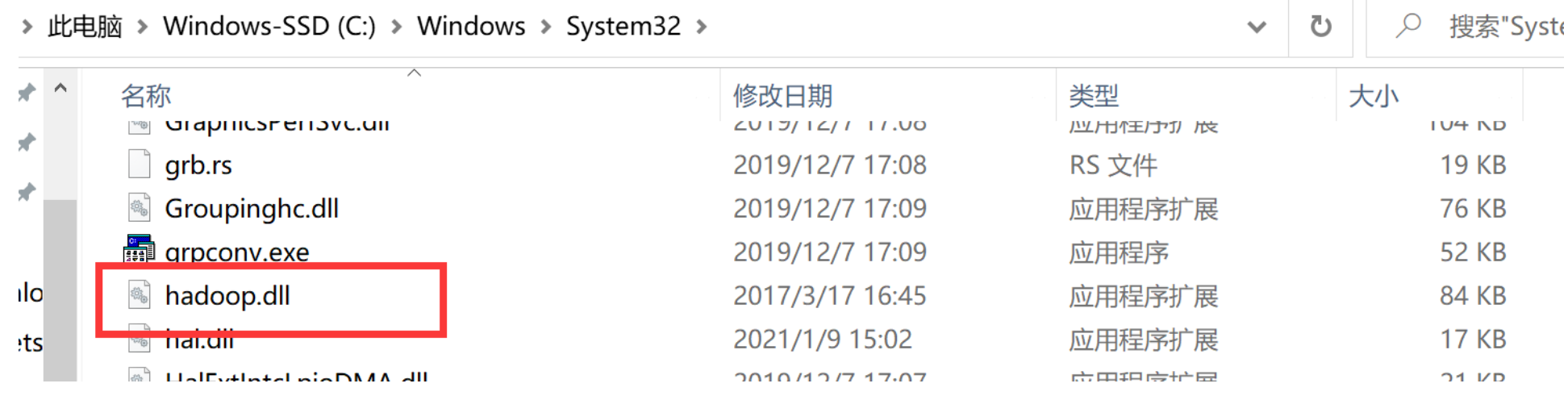
把hadoop.dll复制到C:\Windows\System32下:
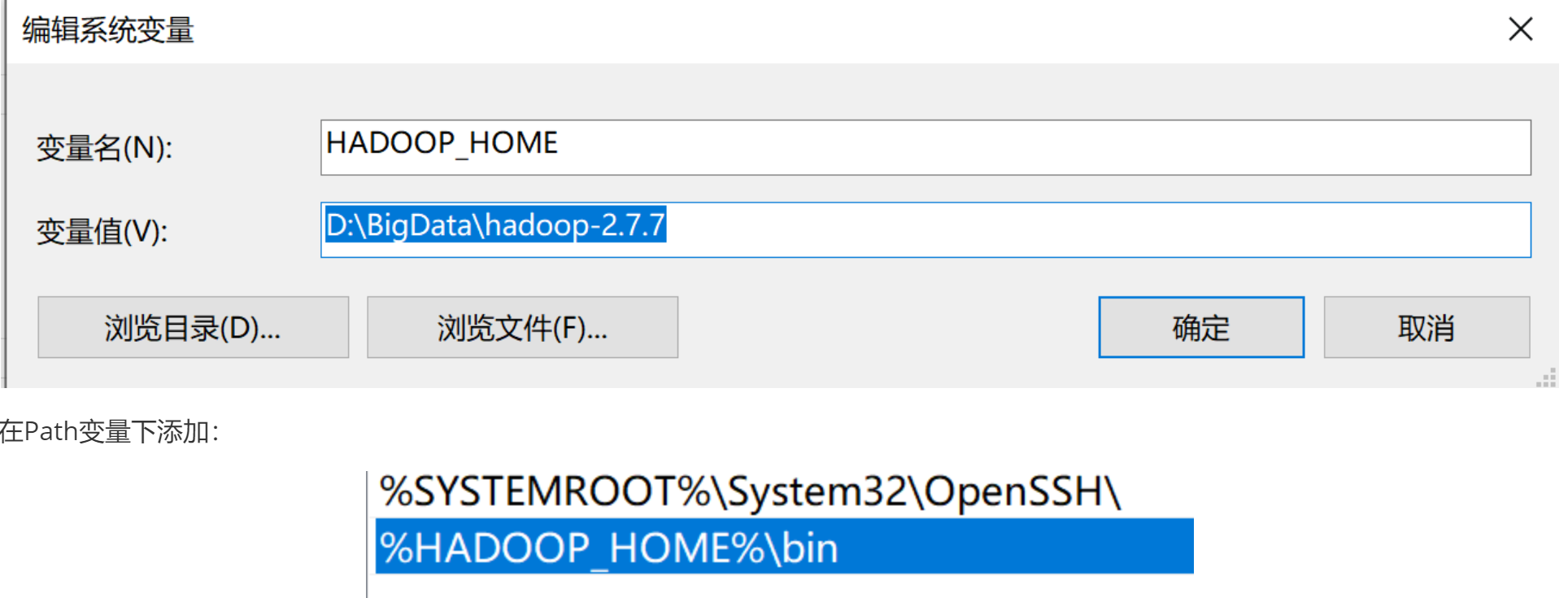
②:设置环境变量:HADOOOP_HOME
重启IDEA或者电脑就可以了!
参考链接:https://blog.csdn.net/weixin_41122339/article/details/81141913
2、问题:
解决办法:https://www.cnblogs.com/tijun/p/7562282.html
3、在windows电脑上:C:\Windows\System32\drivers\etc\hosts
配置主机名和IP的映射,例如:
8.129.26.6 master
4、问题:java.lang.NoSuchMethodError错误。com.fasterxml.jackson.module.scala.deser.BigDecimalDeserializer$.handledType()Ljava/lang/Class;

解决:有些时候明明有这个包,也有这个这个方法,但是仍然发生以上错误。其主要原因主要是jar包冲突导致,将jar包版本一致化,即可解决。
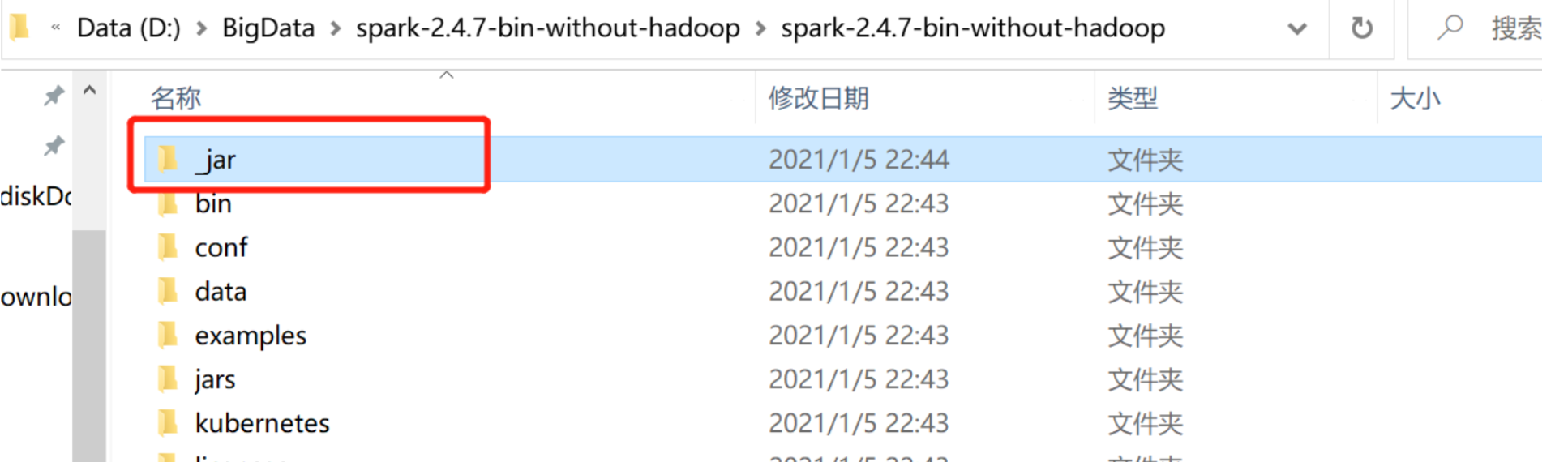
"D:\BigData\spark-2.4.7-bin-without-hadoop\spark-2.4.7-bin-without-hadoop\_jar"目录下的所有JAR包。(这个是你的spark安装包目录)一定注意不要引入下面的jars文件夹中的jar包,容易出现jar包冲突,报错。
5、问题:java.lang.ClassNotFoundException: org.apache.hadoop.mapred.JobConf

解决:出现此异常,就是缺少相关的依赖包,你检查一下以下四个依赖包是否齐全:
hadoop-common-2.7.2.jar
hadoop-mapreduce-client-common-2.7.2.jar
hadoop-mapreduce-client-jobclient-2.7.2.jar
添加依赖jar包,要给项目添加相关依赖包,否则会出错。
点击Idea的File菜单,然后点击“Project Structure”菜单,如下图所示:
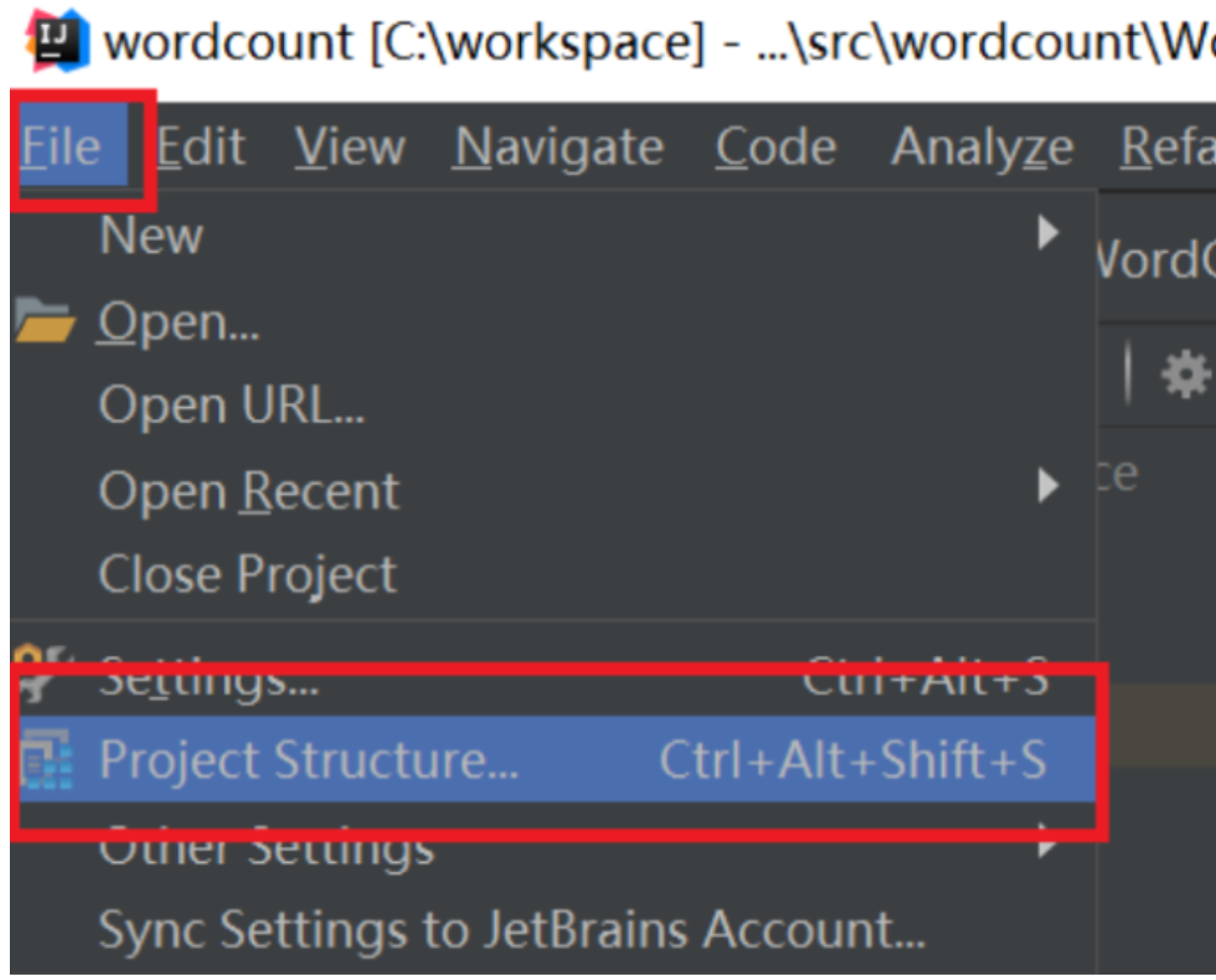
依次点击Modules和Dependencies,然后选择“+”的符号,如下图所示:
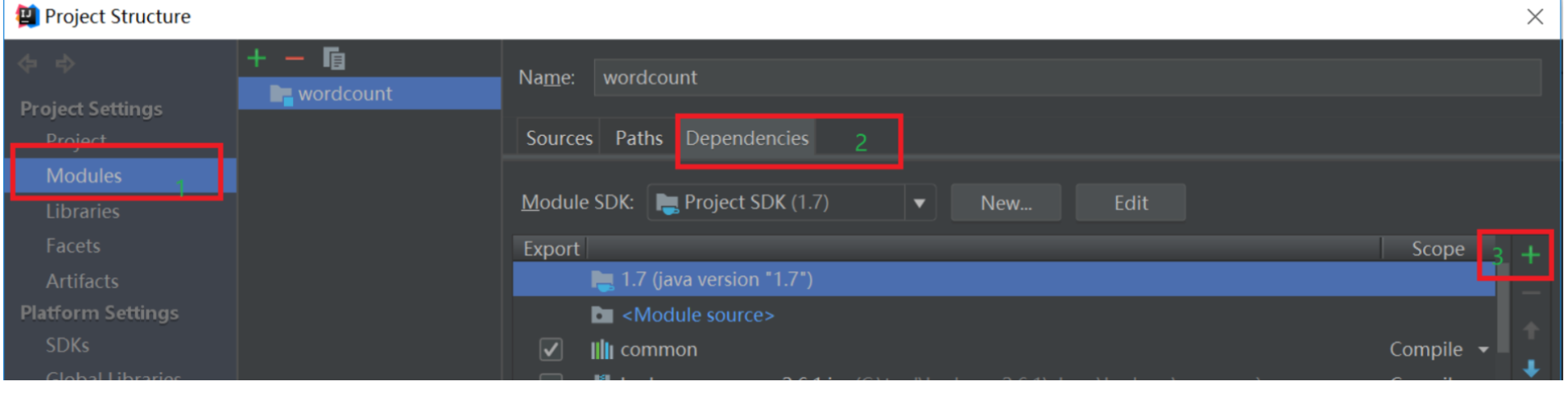
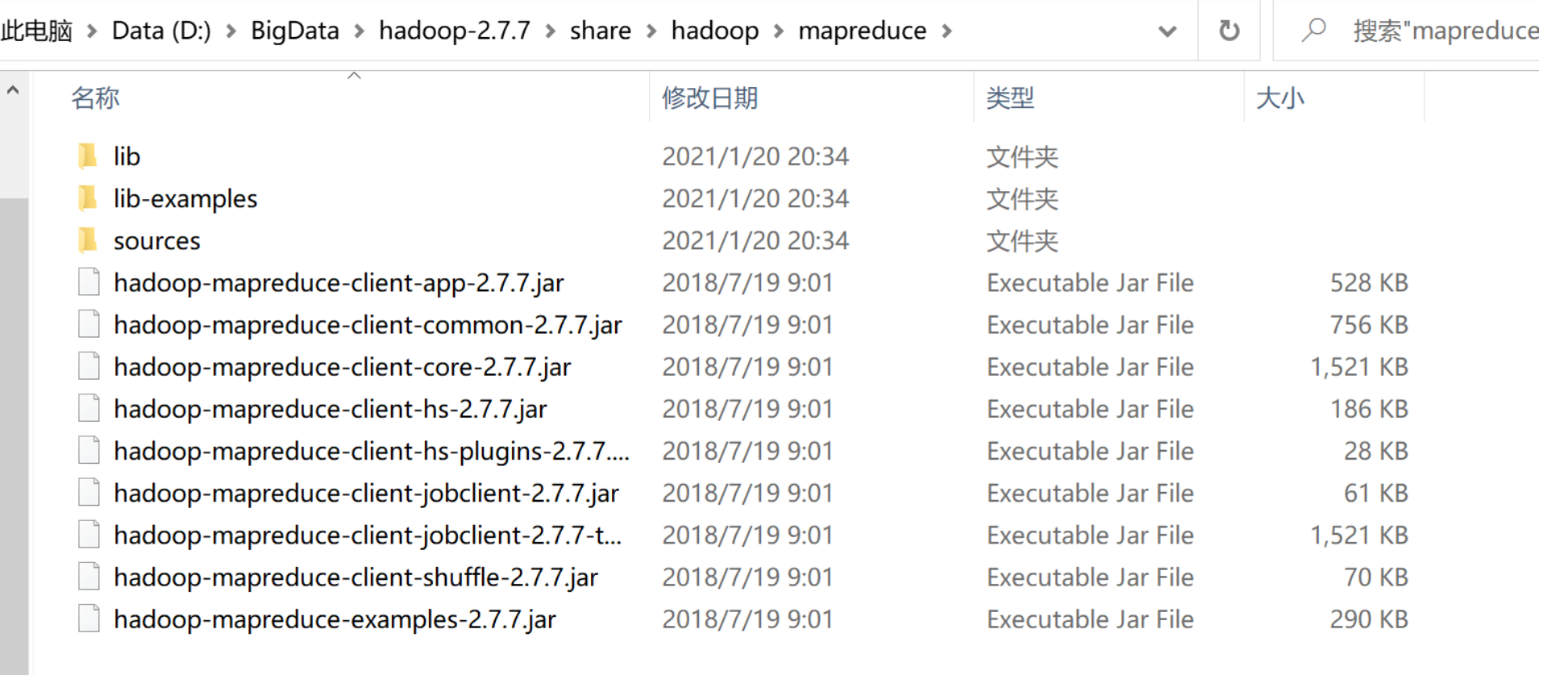
把你的hadoop安装包下的share->hadoop->mapreudce下的所有jar包和share->hadoop->mapreudce->lib下的所有jar包导入到项目中。
参考链接:https://mangocool.com/1464683020221.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号