进程调度
总览
进程调度的总览图如下,当进程被标记为运行状态时,会加入到就绪队列中;队列中的调度实体(进程)维护自己的虚拟时间,该虚拟时间与就绪队列虚拟时间的差值作为红黑树的键值,将调度实体存入红黑树中,其中左下节点为键值最小的节点,最急需被调度,越向右节点的优先级越低;

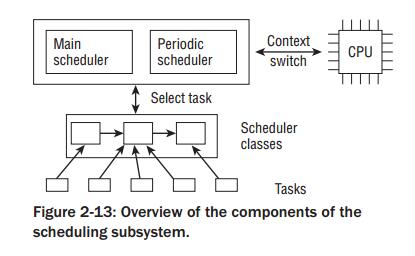
调度子系统总图如下,进程调度激活有两种方式:一种是直接的,如进程打算睡眠或者其他原因放弃CPU;另一种是通过周期性机制,以固定的频率运行,不时的检测是否有必要进行进程切换;
当需要进行切换时,调度器调用调度类中实现的代理方法,从就绪队列中选取一个进程,并完成任务切换;
这里调度器本身不涉及任何进程管理,工作都会委托给调度器类(比如完全公平调度器类);
数据结构
task_struct成员
一些进程调度相关的成员如下:
1 /* 2 动态优先级,调度器考虑的优先级,比如进程需要提高优先级, 3 而保证静态优先级和普通优先级不受影响,则使用该字段 4 */ 5 int prio; 6 /* 静态优先级,进程启动时分配,也可以通过系统调用修改 */ 7 int static_prio; 8 /* 普通优先级,基于静态优先级和调度策略计算得出,子进程会集成父进程的普通优先级 */ 9 int normal_prio; 10 /* 实时优先级,这个值越大优先级越高,不同于nice值 */ 11 unsigned int rt_priority; 12 13 /* 该进程所属的调度器类 */ 14 const struct sched_class *sched_class; 15 /* 调度实体 */ 16 struct sched_entity se; 17 /* 实时调度实体 */ 18 struct sched_rt_entity rt; 19 20 /* 21 调度策略 22 23 SCHED_NORMAL-普通进程 24 SCHED_BATCH-用于次要进程,用于非交互,cpu使用密集的批处理进程 25 SCHED_IDLE-用于次要进程,该类进程重要性比较低,对应的权重总是最小的 26 27 上面三个为完全公平调度器使用 28 29 SCHED_RR-实现了循环方法 30 SCHED_FIFO-使用先进先出机制 31 32 上面两个为实时调度器使用 33 */ 34 unsigned int policy; 35 int nr_cpus_allowed; 36 /* 位域,用于限制该进程可以在哪些cpu上运行 */ 37 cpumask_t cpus_allowed;
调度器类
调度器类定义了一些函数,调度类实例实现这些函数,当调度放生时,会实际调用实例的调度类函数来执行具体的调度任务;
1 struct sched_class { 2 const struct sched_class *next; 3 4 /* 向就绪队列添加新进程 */ 5 void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags); 6 /* 进程从就绪队列中移除 */ 7 void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags); 8 /* 自愿放弃处理器 */ 9 void (*yield_task) (struct rq *rq); 10 bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt); 11 12 /* 新进程抢占当前进程 */ 13 void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags); 14 15 /* 选择下一个将要运行的进程 */ 16 struct task_struct * (*pick_next_task) (struct rq *rq, 17 struct task_struct *prev, 18 struct rq_flags *rf); 19 20 /* 一个进程代替当前进程之前调用 */ 21 void (*put_prev_task) (struct rq *rq, struct task_struct *p); 22 23 /* 调度策略发生变化时调用 */ 24 void (*set_curr_task) (struct rq *rq); 25 /* 每次激活周期性调度时调用 */ 26 void (*task_tick) (struct rq *rq, struct task_struct *p, int queued); 27 void (*task_fork) (struct task_struct *p); 28 void (*task_dead) (struct task_struct *p); 29 30 void (*switched_from) (struct rq *this_rq, struct task_struct *task); 31 void (*switched_to) (struct rq *this_rq, struct task_struct *task); 32 void (*prio_changed) (struct rq *this_rq, struct task_struct *task, 33 int oldprio); 34 35 unsigned int (*get_rr_interval) (struct rq *rq, 36 struct task_struct *task); 37 38 void (*update_curr) (struct rq *rq); 39 40 #define TASK_SET_GROUP 0 41 #define TASK_MOVE_GROUP 1 42 43 #ifdef CONFIG_FAIR_GROUP_SCHED 44 void (*task_change_group) (struct task_struct *p, int type); 45 #endif 46 };
就绪队列
就绪队列是核心调度器管理活动进程的主要数据结构,每个cpu都有自身的调度队列,每个进程只出现在一个调度队列中;多个cpu同时运行一个进程是不可能的,注意,但不同cpu可以同时运行由一个进程产生的多个线程;
就绪队列中嵌入了特定调度类的子就绪队列,用于管理调度的进程;
1 struct rq { 2 3 /* 队列上可运行的进程数 */ 4 unsigned int nr_running; 5 6 #define CPU_LOAD_IDX_MAX 5 7 unsigned long cpu_load[CPU_LOAD_IDX_MAX]; 8 9 10 /* 就绪队列的当前负荷 */ 11 struct load_weight load; 12 13 14 /* 子就绪队列 */ 15 struct cfs_rq cfs; 16 struct rt_rq rt; 17 struct dl_rq dl; 18 19 /* 当前运行进程和idle进程 */ 20 struct task_struct *curr, *idle, *stop; 21 }
系统中所有就绪队列都在runqueues数组中,该数组中的每个队列都对应着一个cpu,即每个cpu一个就绪队列;
1 DECLARE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
调度实体
调度器可以调度比进程更一般的实体,在每个task_struct都嵌入了该实体的一个实例,所以进程是可调度的实体;
1 struct sched_entity { 2 /* For load-balancing: */ 3 /* 实体的权重,决定了各个实体占总负荷的比例 */ 4 struct load_weight load; 5 /* 红黑树节点 */ 6 struct rb_node run_node; 7 struct list_head group_node; 8 /* 标志当前实体是否在调度器上调度 */ 9 unsigned int on_rq; 10 11 /* 调度开始时间 */ 12 u64 exec_start; 13 /* 进程运行消耗的时间 */ 14 u64 sum_exec_runtime; 15 /* 进程消耗的虚拟时间 */ 16 u64 vruntime; 17 /* 上一次调度进程消耗的时间 */ 18 u64 prev_sum_exec_runtime; 19 20 u64 nr_migrations; 21 22 struct sched_statistics statistics; 23 };
处理优先级
优先级的内核表示
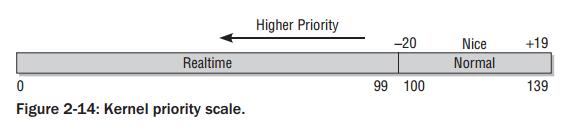
用户空间可以使用nice值设置进程的静态优先级,内部会调用nice系统调用;nice值在[-20,19]之间,值越低表明优先级越高;
内核使用一个简单的数值范围[0-139]来表示内部优先级,同样是值越低,优先级越高;[0-99]范围的值专供实时进程使用,普通进程的nice值[-20,19]映射到范围[100,139];实时进程的优先级总比普通进程更高;
计算优先级
各种类型优先级的计算如下表

计算负荷权重
进程的重要性不仅由优先级指定,而且还需要考虑保存在task_struct->se.load中的负荷权重;
内核不仅维护了负荷权重本身,还维护了一组数值,用于计算被负荷权重除的结果;
一般概念为,进程每降低一个nice值,则多获得10%的cpu时间,每升高一个nice值,则放弃10%的cpu时间;为执行该策略,内核将优先级转换为权重值;
如下图所示,内核使用范围[-20,19]的每个nice值都对应一项权重值;
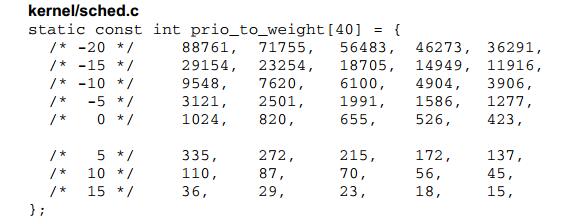
另外,不仅进程,就绪队列也关联到一个负荷权重,每次进程被加到就绪队列时,内核会将进程的权重值加到就绪队列的权重中;
核心调度器
调度器的实现基于两个函数:周期性调度器函数和主调度器函数;这两个函数根据现有进程的优先级分配CPU时间;
周期性调度器
周期性调度器在scheduler_tick中实现,如果系统正在活动中,内核会按照频率HZ自动调用该函数;如果没有进程在等待调度,也可以关闭调度器减少消耗;
周期性调度函数完成两个任务:
1. 管理内核中与整个系统和各个进程调度相关的统计量;
2. 激活负责当前进程调度类的周期性调度方法;
调度器实际上最终调用的是调度类实现的task_tick函数,如,完全公平调度器会在该方法中检查是否进程已经运行太长时间,以避免过程的延迟;
如果当前进程应该被重新调度,那么调度器类方法会在task_struct中设置TIF_NEED_RESCHED标志,以表示该请求,而内核会在接下来的适当时机完成该请求;
主调度器
内核中很多地方,如果要将cpu分配给与当前活动进程不同的另一个进程,都会直接调用主调度函数(schedule);在从系统调用返回之后,内核也会简称当前进程是否设置了重新调度标志TIF_NEED_RESCHED,如果设置了,内核会调用schedule;该函数假定当前活动进程一定会被另一个进程取代;
schedule函数首先确定当前就绪队列,保存当前活动进程;然后使用调度器类的函数选择下一个应该执行的进程,最后执行硬件级别的进程切换;
1 static void __sched notrace __schedule(bool preempt) 2 { 3 struct task_struct *prev, *next; 4 unsigned long *switch_count; 5 struct rq_flags rf; 6 struct rq *rq; 7 int cpu; 8 9 /* 获取cpu */ 10 cpu = smp_processor_id(); 11 /* 获取cpu对应的就绪队列 */ 12 rq = cpu_rq(cpu); 13 /* 保存当前活动的进程 */ 14 prev = rq->curr; 15 16 schedule_debug(prev); 17 18 if (sched_feat(HRTICK)) 19 hrtick_clear(rq); 20 21 local_irq_disable(); 22 rcu_note_context_switch(preempt); 23 24 /* 25 * Make sure that signal_pending_state()->signal_pending() below 26 * can't be reordered with __set_current_state(TASK_INTERRUPTIBLE) 27 * done by the caller to avoid the race with signal_wake_up(). 28 */ 29 smp_mb__before_spinlock(); 30 rq_lock(rq, &rf); 31 32 /* Promote REQ to ACT */ 33 rq->clock_update_flags <<= 1; 34 update_rq_clock(rq); 35 36 switch_count = &prev->nivcsw; 37 if (!preempt && prev->state) { 38 /* 可中断睡眠状态,有接收信号,则提升为运行进程 */ 39 if (unlikely(signal_pending_state(prev->state, prev))) { 40 prev->state = TASK_RUNNING; 41 } else { 42 /* 进程停止活动,会调用dequeue */ 43 deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK); 44 prev->on_rq = 0; 45 46 if (prev->in_iowait) { 47 atomic_inc(&rq->nr_iowait); 48 delayacct_blkio_start(); 49 } 50 51 /* 52 * If a worker went to sleep, notify and ask workqueue 53 * whether it wants to wake up a task to maintain 54 * concurrency. 55 */ 56 if (prev->flags & PF_WQ_WORKER) { 57 struct task_struct *to_wakeup; 58 59 to_wakeup = wq_worker_sleeping(prev); 60 if (to_wakeup) 61 try_to_wake_up_local(to_wakeup, &rf); 62 } 63 } 64 switch_count = &prev->nvcsw; 65 } 66 67 /* 选择下一个应该执行的进程 */ 68 next = pick_next_task(rq, prev, &rf); 69 clear_tsk_need_resched(prev); 70 clear_preempt_need_resched(); 71 72 /* 选择新进程之后,进行上下文切换 */ 73 if (likely(prev != next)) { 74 rq->nr_switches++; 75 rq->curr = next; 76 ++*switch_count; 77 78 trace_sched_switch(preempt, prev, next); 79 80 /* Also unlocks the rq: */ 81 /* 特定体系结构的上下文切换 */ 82 rq = context_switch(rq, prev, next, &rf); 83 } else { 84 rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP); 85 rq_unlock_irq(rq, &rf); 86 } 87 88 balance_callback(rq); 89 }
上下文切换
内核选择新进程之后,必须处理与多任务相关的技术细节,这些细节称为上下文切换;
上下文切换本身通过调用两个特定于处理器的函数完成:
1. switch_mm更换通过task_struct->mm描述的内存管理上下文;该工作的细节取决于处理器,主要包括加载页表,刷出地址转换后备缓冲器,向内存管理单元提供新的信息;
2. switch_to切换处理器寄存器内容和内核栈;
由于用户空间的寄存器内容会在进入核心态时保存在内核栈上,在上下文切换期间无需显示的操作;而因为每个进程首先都是从黑心态开始执行,在返回到用户空间时,会使用内核栈是哪个保存的值自动回复寄存器数据;
内核线程没有自身的用户空间内存上下文,可能在某个随机进程地址空间的上部执行;其task_struct->mm设置为NULL;从当前进程借来的地址空间记录在active_mm中;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号