
[转载] Linux的Netfilter框架深度思考-对比Cisco的ACL
转自:http://blog.csdn.net/dog250/article/details/6572763
在前面
0.1.本文不涉及具体实现,也不涉及源代码,不剖析代码
0.2.本文不争辩Linux或者Cisco IOS不同版本之间的实现细节
0.3.本文不正确处请指出
Cisco无疑是网络领域的领跑者,而Linux则是最具活力的操作系统内核,Linux几乎可以实现网络方面的所有特性,然而肯定还有一定的优化空间,本文首先向Cisco看齐,然后从不同的角度分析Netfilter的对应特性,最终提出一个ip_conntrack的优化方案。
0.4.昨天女儿出生,她不哭也不闹,因此才能整理出这篇文档,这几天累坏了,但还是撑着整理了这篇文档
1.设计的异同
Netfilter是一个设计良好的框架,之所以说它是一个框架是因为它提供了最基本的底层支撑,而对于实现的关注度却没有那么高,这种底层支撑实际上就是其5个HOOK点:
PREROUTING:数据包进入网络层马上路由前
FORWARD:数据包路由之后确定要转发之后
INPUT:数据包路由之后确定要本地接收之后
OUTPUT:本地数据包发送(详情见附录4)
POSTROUTING:数据包马上发出去之前
1).HOOK点的设计:
Netfilter的hook点其实就是固定的“检查点”,这些检查点是内嵌于网络协议栈的,它将检查点无条件的安插在协议栈中,这些检查点的检查是无条件执行的 ;对比Cisco,我们知道其ACL也是经过精心设计的,但是其思想却和Netfilter截然相反,ACL并不是内嵌在协议栈的,而是一种“外部的列表”,策略包含在这些列表中,这些列表必须绑定在具体的接口上方能生效,除了绑定在接口上之外,检查的数据包的方向也要在绑定时指定,这说明ACL只是一个外接的策略,可以动态分派到任何需要数据包准入检查的地方。
2.数据流的异同-仅考虑转发情况
1).对于Cisco,数据包的通过路径如下: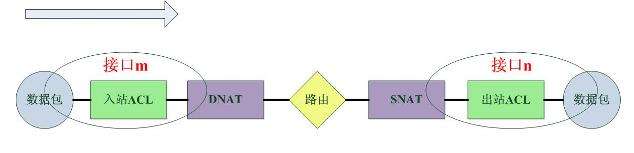
2).对于Linux的Netfilter,数据包的通过路径如下: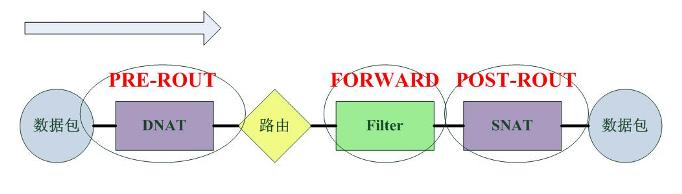
3.效率和灵活性
3.1.过滤的位置
从数据流的图示中可以看出Netfilter的数据包过滤发生在网络层,这实际上是一个很晚的时期,从安全性上考虑,很多攻击-特别是针对路由器/服务器本身的Dos攻击-此时已经形成了,一个有效的预防方式就是在更早的时候丢弃数据包,这也正是Cisco的策略:“在尽可能早的时候丢弃数据包”。而Cisco也正是这么做的,这个从上面的图示中可以看出。Cisco的过滤发生在路由之前。
3.2.过滤表的条目
由于Netfilter是内嵌在协议栈中的全局的过滤框架,加之其位置较高,很难对“哪些包应该匹配哪些策略”进行区分,而Cisco的ACL配置在网卡接口,并且指定了匹配数据包的方向,因此通过区分网卡接口和方向,最终一个数据包只需要经过“一部分而不是全部”的策略的匹配。比如从Ether0进入的数据包只会匹配配置在Ether0上入站方向的ACL。
3.3.NAT的位置
Netfilter的NAT发生在filter之前和之后,而Cisco的nat也发生在filter之中,这对二者filter策略的配置有很大的影响,对于使用Netfilter的系统,需要配置DNAT之后或者SNAT之前的地址,而对于Cisco,则需要配置DNAT之前或者SNAT之后的地址。
3.4.配置灵活性
3.4.1.Cisco的acl配置很灵活,甚至“配置到接口”,“指明方向”这一类信息都是外部的,十分符合UNIX哲学的KISS原则,但是在具体的配置上对工程师的要求更高一些,他们不仅仅要考虑匹配项等信息,而且还要考虑接口的规划。
3.4.2.Netfilter的设计更加集成化,它将接口和方向都统一地集成在了“匹配项”中,工程师只需要知道ip信息或者传输层信息就可以配置了,如果他们不关心接口,甚至不需要指明接口信息,实际上在iptables中,不使用-i和-o选项的有很多。
4.Netfilter优化
4.1.防火墙策略查找优化
4.1.1.综述
传统意义上,Netfilter将所有的规则按照配置的顺序线性排列在一起,每一个数据包都要经过所有的这些规则,这大大降低了效率,随着规则的增加,效率会近似线性的下降,如果能让一个数据包仅仅通过一部分的规则的匹配就比较好了。这就是说,我们要对规则进行分类,然后先将过往的数据包用高效的算法匹配到一个特定的分类,然后该数据包只需要再继续匹配该分类中规则就可以了。
分类实际山很简单,它基于一个再简单不过的解析几何事实:在一条线段上,一个点将整个线段分为3部分: 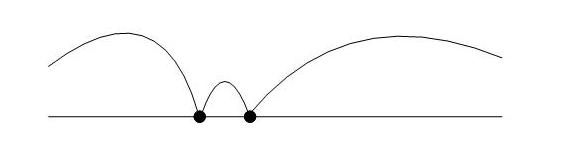
因此,任何一个匹配项都可以归结为一个所谓的“键值”,在该键值空间中,一定有某种顺序可供排序,那么一个键值,就能将这个键值空间分为三个部分:大于,等于,小于。一维空间如此,N维空间亦如此,只是更精确,这里N是我们挑选出来的匹配域。为了更好的理解下面的论述,先给出两幅图。传统意义的防火墙规则匹配操作如下图所示,它是平坦的:
而优化后的防火墙规则匹配操作如下图所示,它是分维度的: 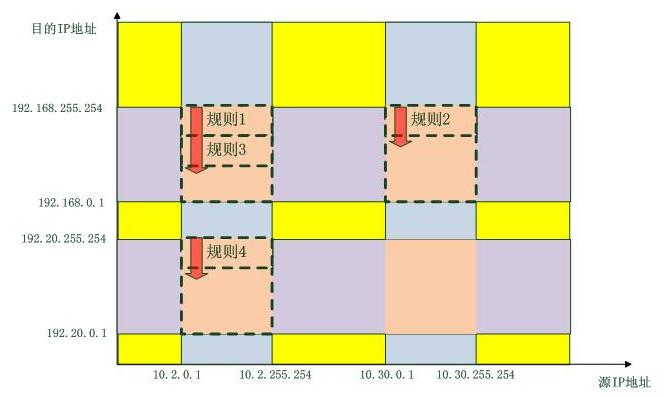
最终,只有虚线所围的区域有规则要匹配,只有数据包“掉进了”这些区域,才需要匹配规则,否则全部按照“策略”行事。当然,一个数据包不可能掉进两个区域。这里只考虑了源IP地址和目的IP地址这种二维的情形,如果加上第四层协议,端口等信息维度,匹配就更加精确了,并且,只要使用的“类”匹配算法足够精巧,操作是不会随着规则的增加而增加的,而这一部分内容正是我们马上就要讨论的内容
4.1.2.Cisco的优化策略
很多用过Cisco的人都知道,Cisco有一个叫做Turbo ACL的概念,这个Turbo ACL的要旨就是“不再用规则匹配数据包,而成为了使用数据包的信息查找需要匹配它的规则”。这就意味着在ACL插入系统的时候就要对其进行排序,然后数据包进入的时候,通过数据包的信息去查找排过续的规则集。
想了解Cisco的技术细节,直接浏览其官方网站的Support是很有必要的,这里有最直接的讲述,Cisco的技术Support有一个很好的地方,那就是它有情景分析。我下面就用那上面的例子来进行分析,基本上基于一篇文档:《TURBO ACL》。
Turbo ACL定义了一系列的匹配域,如下图所示: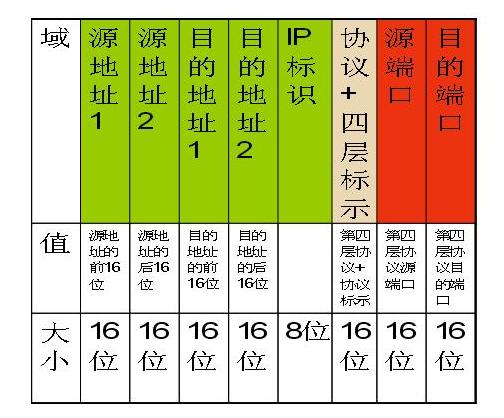
其中绿色的表示三层信息,红色的表示四层信息,粉色的表示第三层+第四层的信息。针对于每一个匹配域,都存在一个表,我们称为“值表”:
其中索引是为了查找和管理方便,而值则被填入规则中对应该表的匹配域的值,ACL位图指示该表的该记录匹配哪些ACL。因此,对于所有的匹配域,由于一共有8个匹配域,那么就有8个这样的表。为了更加容易理解,给出一个例子,首先看4条acl规则:
#access-list 101 deny tcp 192.168.1.0 0.0.0.255 192.168.2.0 0.0.0.255 eq telnet
#access-list 101 permit tcp 192.168.1.0 0.0.0.255 192.168.2.0 0.0.0.255 eq http
#access-list 101 deny tcp 192.168.1.0 0.0.0.255 192.168.3.0 0.0.0.255 eq http
#access-list 101 deny icmp 192.168.1.0 0.0.0.255 200.200.200.0 0.0.0.255
这些规则填入匹配域表格后,匹配域表格如下: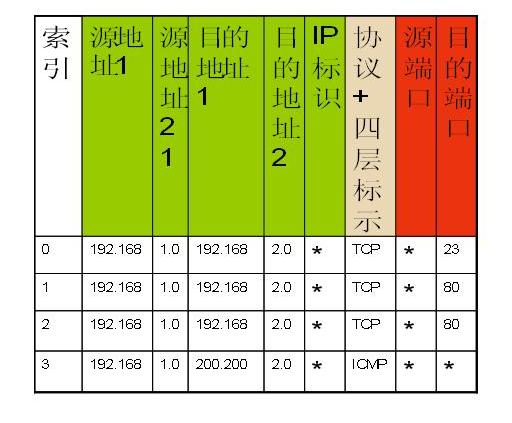
然后仅给出一个“源地址1”的值表:
到此为止,我们已经给出了所有的静态的数据结构,接下来就是具体的动态操作了,归为一种算法。Cisco的规则匹配算法是分层次的,并且是可并行运算的,因此它的效率极其高效,整个算法分为两大部分:
1).数据包基于所有匹配域的位图查找
这个步骤是可以并行的,比如可以同时在两个处理器上查找“源地址1”的值表和“源地址2”的值表,从而最大化CPU利用率,以最快的速度得到两个位图,算法对于采用何种查找算法没有规定,取决于添加ACL时如何将匹配域的值插入对应值表。另外,哪种查找快用哪种,这是不争的事实,我们一般很少有动态插入的,一般都是静态插入的,因此对数据插入的性能要求并不高,关键要素是查找。这个查找算法的查找效率非常重要,好的算法如果是O(1)的,那就意味着匹配规则的过程消耗的时间不会随着规则的增加而增加,事实上即使是O(n)的查找算法, 也将N次的匹配操作转化为了按照一个比例小得多的a*N次的查找操作,往往a是一个很小的且小于1的数字...
2).多个位图多次的AND操作
取多个结果的交集,最终得到一条或者几条ACE。这种位图的算法是Cisco惯用的用空间换时间的策略,传说中的256叉树使用的也是这样的策略。
下面给出操作的流程图: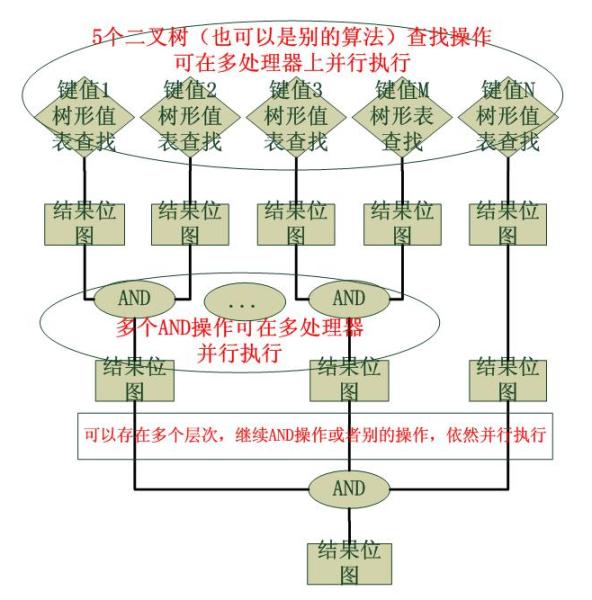
作为一个情景分析,我们考虑一个数据包到来,它的匹配域的值如下:
源地址1 : 192.168
源地址2 : 1.1
目的地址1 : 200.200
目的地址2 : 200.1
四层协议 : 0001 (ICMP)
针对此包的操作流程图如下,假设仅有上述举例的acl可用: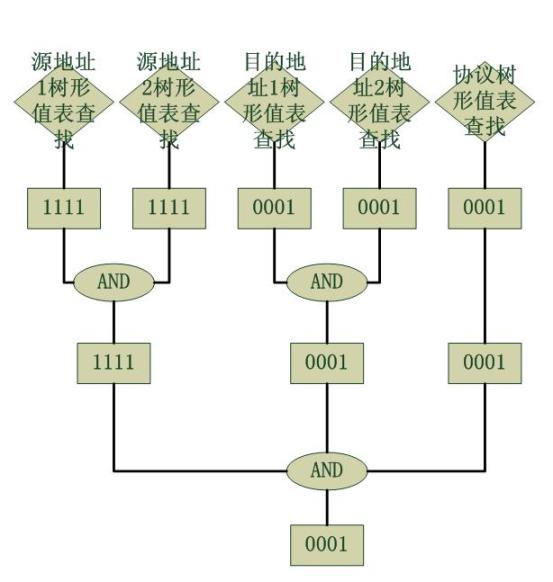
最终得到了0001,也就是仅有最后一条规则是匹配的。
这样我们就结束了Turbo ACL的讨论,接下来就要看看Linux的Netfilter有没有什么对等的优化策略
4.1.3.Netfilter的filter优化策略
Netfilter有一个项目,叫做nf-HiPAC ,它的代码极端复杂,文档极端稀缺,功能相比iptables更加有限,加之Linux面对巨量规则的需求不多,因此HiPAC的受用性不高,然而从理论的角度去分析一下它也是有好处的。虽然啃HiPAC的代码是一件很恐怖的事情,然而浏览一下它并不很难,最终我们发现,它的实现和Turbo ACL基本是一致的,也是基于数据包首先匹配匹配域从而先得到分类,它使用了几乎相同然而更多一些的匹配域,和Turbo ACL不同的是,它没有使用位图,因为Linux可能不允许以空间换时间,呵呵...
HiPAC没有使用位图,这是因为它根本不需要位图, 因为Cisco并行的同时得到了所有匹配域值表的位图,因此只要将它们AND,就能得到最终结果,可是HiPAC并不是并行操作的,而是串行的,HiPAC对于每一个匹配域也有一个值表,由于一系列的匹配域按照一定的顺序排列好,比如:源地址-目的地址-协议-源端口-目的端口,因此其值表也有这样的串接关系,见下面:
在找到目的地址的匹配之前,是不会匹配协议以及后面的匹配域的。具体的规则挂接在最后的匹配域值表中。HiPAC并没有保留原始的配置规则,然后通过位图找到它们,而是直接将规则挂接在了它“应该在”的位置。一个HiPAC的流程图如下: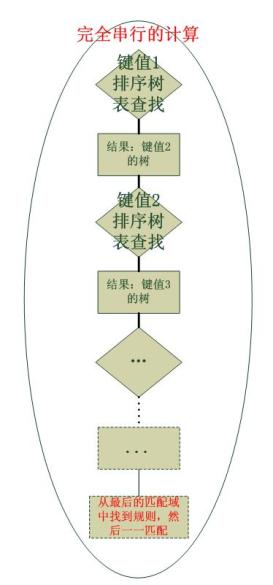
4.1.4.Cisco和Netfilter的对比
它们使用的查找算法十分一致,然而具体的操作却大相径庭,我们看到Cisco完全是在并行的处理,而Netfilter则一串到底。如果形象的理解,我们可以将整个操作比作在一个多维空间查找一个点。有两种方式:
1).N个维度同时向前推进,最终找到它们路径的相交区域;
2).先在第一个维度匹配,然后再匹配第二个维度...
我们发现,Cisco使用了第一个方法,而Netfilter使用了第二个。我想Netfilter不使用并行方式的原因有二:第一,Netfilter一般应用于Linux,而Linux是一个通用的操作系统,对于协议栈的支持只是其一部分功能而已,如果为协议栈引入并行机制,势必会造成一种不均衡的态势。第二,Linux一般情况下不会有成千上万的防火墙条目,而上述的优化算法在规则条目越多的情形下效果越明显。另外,对于Netfilter的nf-HiPAC的查找机制,又使得我想起了Linux的页表查找和路由表的trie树查找算法。
4.2.ip_conntrack优化
Netfilter的ip_conntrack模块实现了连接跟踪的功能,然而这个实现我总觉得有个美中不足的地方。那就是它对于IP分片的处理,Netfilter的ip_conntrack对于分段的处理就是合并分段,理由就是IP层是无连接的,而IP分段则无法得到第四层信息,因此为了得到第四层信息,必须等待所有分段到达,然后才能继续处理。这是个理由,并且说的很充分,然而我个人认为这肯定还是可以再优化的,我们可以再做一个层次来解决这件事,正如我们“仅仅保留一个流的五元素就能识别一个数据包是否属于该流”一样,我们也能为一个ip数据报保留一个“源ip/目的ip/协议/三层id”四元素,这四个元素唯一确定一个ip数据报(理由见附录) ,我们仅仅需要用一个ip分片匹配这四元素就能确定它属于哪个ip初始分片,而这也就知道了它属于哪个流,当然仅仅针对分段数据报保留这四元素即可,但是由于ip是不保证顺序的,如果到来的一个ip分片不是第一个分片,那怎么办?这个很简单,那只能等,等待第一个分片到来,得到四元素信息,然后再处理。
这里给出一个流程图,原因是也只能给出这个图了,这篇文档是在医院写的,我家小小估计快要出生了...回头有时间再改代码吧,如果哪位大侠看了,觉得有点意思并且感兴趣的话,请一定尝试一下,然后给内核的Netfilter组提交一个patch,小弟在此大谢:
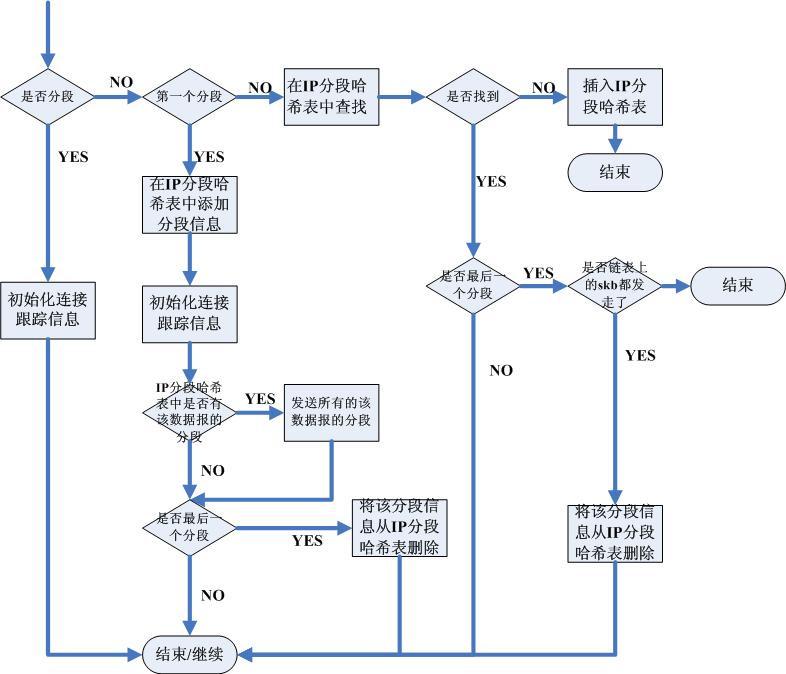
总之,nf-HIpac,采用串行(可以修正为并行)多维树查找算法,源于一种包分类算法,不再是规则匹配包,而成为了包寻找规则。维度的增加,约束相应增加,定位就更准确。查找所需的时间不管怎样要比依次匹配规则的时间更少,最终,最多只有一部分规则参与抉择。
4.3.基于优化后ip_conntrack的有状态防火墙
既然ip_conntrack被优化了,那它就不会为ip分片所累了(其实它原来就不会为其所累)。基于ip_conntrack实现一个有状态防火墙也不是一件难事,ip_conntrack中保留着该流第一个包到达时的数据包经过filter表时的匹配策略,具体来讲就是一个target,然后对于后续的包都直接按照这个target来执行。
然而这种防火墙究竟和HiPAC相比有何不同的,这种防火墙在PREROUTING时去匹配流,第一个数据包还在在filter中匹配规则,而HiPAC只需要在filter中匹配规则即可,对于大量连接而言,流匹配肯定会慢,然而如果有大量规则,HiPAC不会降速的,这正是它的优势所在,正和Cisco的Turbo ACL一样。
5.一个细节-防火墙对IP分片的处理
5.1.问题之所在
在RFC1858中指明了两类ip分片的攻击
1).TCP小包攻击
对于这类攻击,很容易理解,首先给出一个IP数据报分片的第一个片: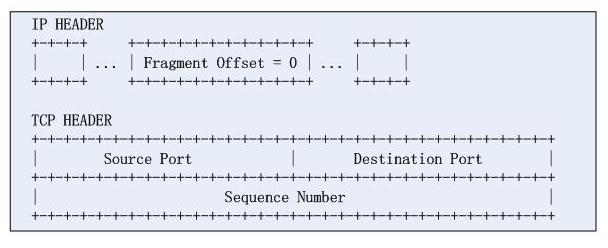
然后再看第二个片: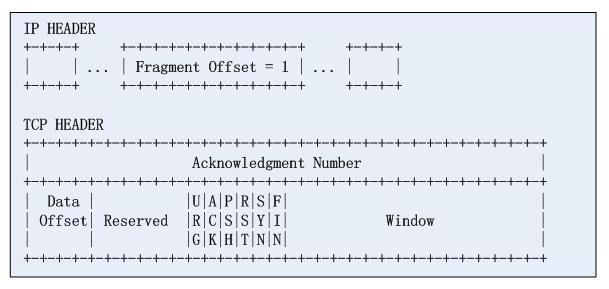
分片的offset字段指示了tcp载荷的偏移,这样,攻击者认为防火墙无法识别分段的第四层信息,从而成功的绕过了防火墙的检测,攻击要点在于,将一个完整的TCP协议头硬拆成两段,咋可好!。实际上很长一段时间,Cisco的ACL只要匹配到数据报分片的第三层信息并且规则是permit,那么是一律放过的。实际上,RFC1858中给出了解决方案,需要限制TCP载荷分片的最小值,这也是RFC的建议(然则Cisco并不一定遵守)。
2).TCP重叠攻击(依赖重组算法)
和1)相比,这是一种间接的攻击方式,请看第一个IP分片: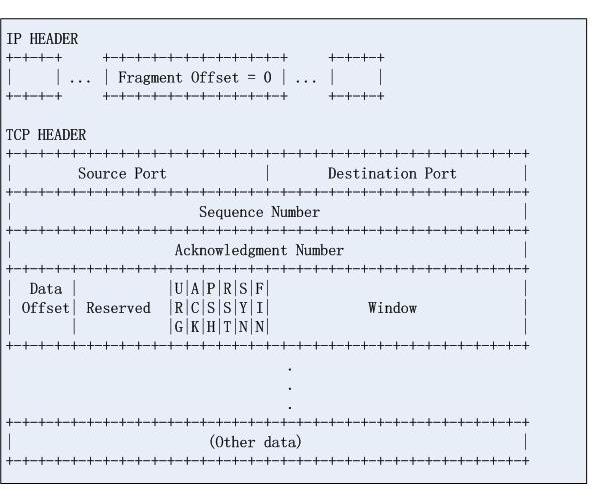
再看第二个分片:
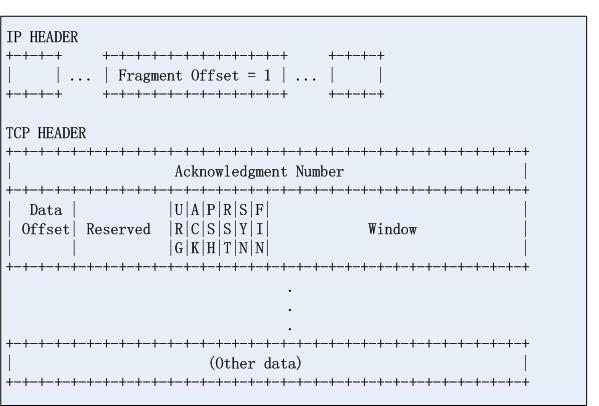
我们看到第一个都是正常的,只是第二个不正常,如果目的地主机的IP分片的合并算法有问题,第二个分片的信息就会覆盖掉第一个分片的tcp协议头信息,由于过滤规则无法从IP分段中获取四层信息,因此数据轻松绕过防火墙,从而实施攻击。标准并没有规定IP分片合并的具体约束,这是导致这个攻击得意存在的根本原因。
5.2.Cisco的处理
Cisco处理IP分片完全采用一种统一的方式,将是否允许其通过这件事完全交给了配置工程师们,它的流程图如下所示,流程图显示单个数据包匹配ACE的情形: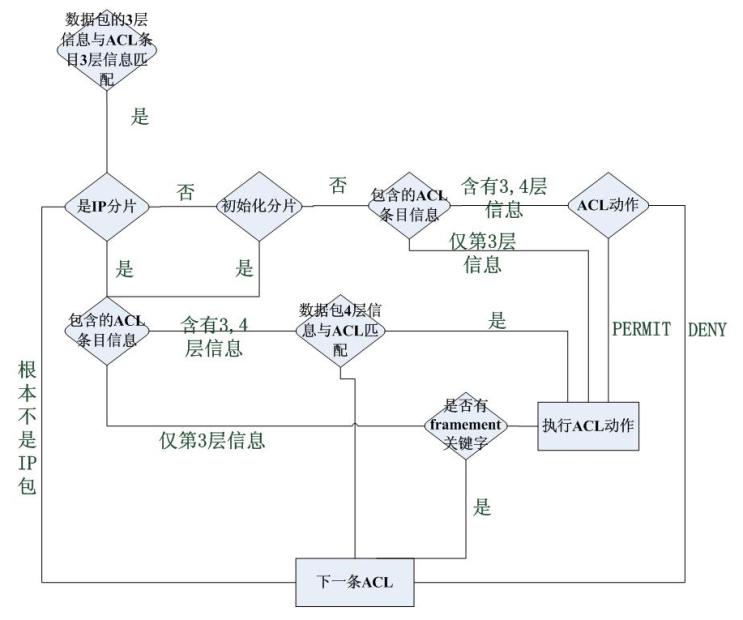
Cisco的工程师必须显示配置哪些分片不能通过。然而Cisco的IOS的新版本还是限制了RFC1858中提到的攻击分片的通过
5.3.Netfilter的处理
Netfilter直接禁止了RFC1858中提到的攻击分片的通过,流程图就不画了,给出一段代码即可:
- static int
- tcp_match(const struct sk_buff *skb,
- const struct net_device *in,
- const struct net_device *out,
- const void *matchinfo,
- int offset,
- int *hotdrop)
- {
- struct tcphdr tcph;
- const struct ipt_tcp *tcpinfo = matchinfo;
- if (offset) {
- if (offset == 1) {
- duprintf("Dropping evil TCP offset=1 frag./n");
- *hotdrop = 1; //不允许这样的包通过
- }
- return 0;
- }
- ...
- }
另外,Netfilter对于非第一个的IP分片,对于高于网络层的一切匹配项一律命中匹配,比如来了一个ip分片,对于tcp/udp的端口信息,一律匹配,然后直接执行target,这和Cisco的策略是不一样的,这一点从其流程图中可以看出来。
5.4.对比
不管是Cisco还是Netfilter,它们都将匹配项分为了两类,一类是隐含的匹配项,这些项只包含三层信息,另一类是明确匹配项,这类匹配项包含更高层的信息 -对于Linux的Netfilter而言,这类隐含匹配项不需要注册,而明确匹配项需要注册,Cisco的方式未知,但是猜测不是这样的,应该都需要或者都不要注册。对于Netfilter的filter和Cisco的ACL,都是在隐含匹配项匹配的基础上才匹配明确匹配项的,可以参见Cisco处理ACL的流程图以及Linux内核的Netfilter代码:
- do {
- //判断是否和隐含匹配项匹配,offset指示是否为ip分片
- if (ip_packet_match(ip, indev, outdev, &e->ip, offset)) {
- 针对每一个明确匹配项进行匹配,只要只要有一个不匹配,则跳到not-match,否则执行target。由于几乎所有注册的match对于ip分片都直接返回“匹配”,所有IP分片只需匹配隐含匹配则就算是匹配了。
- } else {
- not-match:
- 下一条规则
- }
- } while (还有其它规则)
6.总结
站在一个比较高的层面上仔细观测Linux和Cisco IOS的网络设计,IOS的优势更多的在于它将几乎所有的精力都用到了网络方面,IOS的内核机制实际上要比Linux的简单得多,然而它依托于一个总体的良好设计,使得几乎任何事情都可以被配置出来,在IOS中,任何策略都是配置出来的,虽然它有一个默认配置文件,然而那也是配置出来的。
而Linux的做法就完全不同,Linux的网络策略实际上是Netfilter和硬编码的结合,在Linux内核中(网络方面的代码),我们可以看到很多注释,这些注释大多数是Alan Cox 添加的,很多都是说“为了遵循RFCXXXX...”。当然,这种硬编码也是可以配置的,比如使用sysctl工具,然而它不能使用一个统一的工具来配置,比如你不能使用ip命令打开ip_forward...
我知道,使用Netfilter可以实现几乎Cisco IOS的所有功能,并且也可以做和IOS类似的优化,这正是Netfilter框架的优越性所在,然而虽然从外部看起来是一样的,但是要明白其实质是有很大差别的,另外Linux没有必要追赶Cisco IOS,这是没有意义的,即使做得比Cisco好,我相信大部分人还是会买Cisco的,因为市场的竞争中技术因素只占很小的一部分份额,正如很多人都在大搞Linux的Windows的兼容,这有必要吗,在Windows中有个注册表,Linux中就一定要有类似的吗?一切安好,在纯技术领域的讨论如果放到整个产品层面就会认为是倔强和顽固。
Netfilter框架设计的很好,每一个细节都值得细细品味,使用它,理解它,修改它,优化它,完善它,使用它...这是一个很不错的学习过程,你也可以试试。
附录
0.Netfilter到底属于谁?
0.1.Netfilter是一个框架 ,它是独立于Linux内核的,它有自己的网站:http://www.netfilter.org/
0.2.Netfilter拥有几乎无限的可扩展性, Liuux中使用的仅仅是它的一个很小的部分,大部分的内容作为可插拔的module处于待命状态
0.3.Netfilter的机制集成在Linux内核中, 然而它的策略扩展却处于一个独立的空间,我们说这种所谓的机制也仅仅是5个HOOK点。我们浏览netfilter.org就会知道,它里面融合了大量的策略,我们最熟悉的就是iptables了。上述提到的HiPAC也是Netfilter的扩展之一
0.4.足以看出,Netfilter有多强大,内核仅仅给出钩子点而已。 如果你嫌某些不好,你可以自己实现一个更好的
0.5.事实上,Netfilter中有很多的东西并没有集成在Linux内核。
1.一幅图:数据包的内核路径图
为了给出Linux内核中Netfilter的全景,给出一幅图,图中详细标示了其各个部分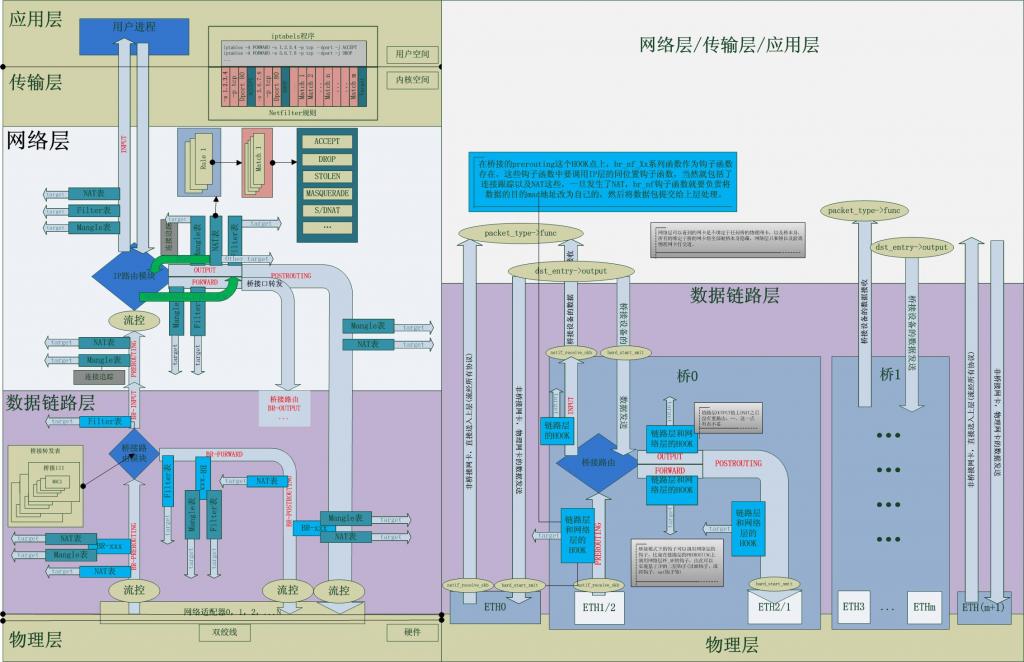
2.ip_conntrack优化中使用四元素的理由:
ip层给出了4元素,明确跟踪了一个IP数据报,实际上TCP/IP的每一个层次的协议头都会提供一些该层PDU的跟踪信息,由于IP层是基于报文的,因此其跟踪信息完全标示一个IP数据报,一个分片的IP数据报的所有报文片段的这些跟踪信息相同。理解这一点十分简单和直接,正如TCP/UDP协议的端口号信息加上更低层次的跟踪信息就能标示一个流一样-一个流标示一个会话,有很多的数据报组成。在RFC791(非常非常重要的IP协议RFC)中,明确的指明了这一点,《tcp/ip详解》中也指示了这一点:
“标识字段唯一地标识主机发送的每一份数据报。通常每发送一份报文它的值就会加1。”“RFC 791 [Postel 1981a]认为标识字段应该由让IP发送数据报的上层来选择。假设有两个连续的IP数据报,其中一个是由TCP生成的,而另一个是由UDP生成的,那么它们可能具有相同的标识字段。尽管这也可以照常工作(由重组算法来处理),但是在大多数从伯克利派生出来的系统中,每发送一个IP数据报,IP层都要把一个内核变量的值加1,不管交给IP的数据来自哪一层。内核变量的初始值根据系统引导时的时间来设置。”《TCP/IP详解(第一卷)》
3.conntrack-tools
首先声明:这不是Linux的错!也许,有时候,你的iptables规则清除了,然而数据包地址转换还在进行。这是ip_conntrack的chache引起的,然而这并不是问题,只要能使用工具解决的事情都不是问题,这个问题也能用工具解决,这个工具就是conntrack-tools,它能在任意时间删除任意的ip_conntrack的cache,具体怎么用,教你:1.下载;2.安装;3.man
4.Netfilter的HOOK点之OUTPUT位置设计
Netfilter中output这个hook点比较特殊,按照常理,output应该设计在路由前的,这也符合过滤尽量在早期发生的原则,然而我们发现Netfiler的output链却在路由之后,这里面到底有什么蹊跷呢?
4.1.output链在路由之后,侧重于“到底是容易被过滤还是容易没有路由”
4.2.过滤发生在路由之后,权衡点在于“可能没有路由还是可能被drop”。
4.3.skb的output函数是个回调函数,而这个回调函数是根据路由的结果以及路由策略设置的,因此最好将output链设置于路由之后, 这样就可以将ip的发送函数简单的写成:
- int __ip_local_out(struct sk_buff *skb)
- {
- struct iphdr *iph = ip_hdr(skb);
- iph->tot_len = htons(skb->len);
- ip_send_check(iph);
- return nf_hook(PF_INET, NF_INET_LOCAL_OUT, skb, NULL, skb->dst->dev,
- dst_output);
- }
- static inline int dst_output(struct sk_buff *skb)
- {
- return skb->dst->output(skb);
- }
注意,以上的dst是根据路由查找的结果初始化的。将DNAT挂在OUTPUT链上是没有问题的,因为DNAT改变了目的地址后,会重新路由,然后就会重新初始化dst字段,新的output函数也将获得。Netfilter将output确定在了路由之后以及在output上实施dnat保证了必定在路由之后确定skb的dst字段,否则dsk字段不确定的话,nf_hook函数就不好写了。
总结起来就一点,Linux的IP层往下的发送例程是“路由查找结果”决定的,因此只有在路由查找之后才可确定发送函数,才可以挂载继续发送的钩子。
5.Cisco IOS/H3C VRP/GNU Linux
04年那年,接触了华三的设备,随后又使用了Cisco的,大概2年后,我看到Linux的shell界面时,我还以为这是Cisco呢...IOS和VRP的操作界面很类似,它们都属于核心网络设备这一块,侧重于核心路由和防火墙,配置可以很难,但是一定要灵活,迎合各种需求,无可非议,VRP借鉴了Cisco-虽然它的内核是BSD化的,Linux属于一个通用操作系统,核心网络不是它的应用场合。
6.预防IP欺骗的基于RFC2827经典配置
(1) 任何进入网络的数据包不能把网络内部的地址作为源地址。
(2) 任何进入网络的数据包必须把网络内部的地址作为目的地址。
(3) 任何离开网络的数据包必须把网络内部的地址作为源地址。
(4) 任何离开网络的数据包不能把网络内部的地址作为目的地址。
(5) 任何进入或离开网络的数据包不能把一个私有地址(Private Address)或在RFC1918中列出的属于保留空间(包括10.x.x.x/8、172.16.x.x/12 或192.168.x.x/16 和网络回送地址127.0.0.0/8.)的地址作为源或目的地址。
(6) 阻塞任意源路由包或任何设置了IP选项的包。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号