

彻底理解线索二叉树
一、线索二叉树的原理
通过考察各种二叉链表,不管儿叉树的形态如何,空链域的个数总是多过非空链域的个数。准确的说,n各结点的二叉链表共有2n个链域,非空链域为n-1个,但其中的空链域却有n+1个。如下图所示。

因此,提出了一种方法,利用原来的空链域存放指针,指向树中其他结点。这种指针称为线索。
记ptr指向二叉链表中的一个结点,以下是建立线索的规则:
(1)如果ptr->lchild为空,则存放指向中序遍历序列中该结点的前驱结点。这个结点称为ptr的中序前驱;
(2)如果ptr->rchild为空,则存放指向中序遍历序列中该结点的后继结点。这个结点称为ptr的中序后继;
显然,在决定lchild是指向左孩子还是前驱,rchild是指向右孩子还是后继,需要一个区分标志的。因此,我们在每个结点再增设两个标志域ltag和rtag,注意ltag和rtag只是区分0或1数字的布尔型变量,其占用内存空间要小于像lchild和rchild的指针变量。结点结构如下所示。

其中:
(1)ltag为0时指向该结点的左孩子,为1时指向该结点的前驱;
(2)rtag为0时指向该结点的右孩子,为1时指向该结点的后继;
(3)因此对于上图的二叉链表图可以修改为下图的养子。

二、线索二叉树结构实现
二叉线索树存储结构定义如下:

线索化的实质就是将二叉链表中的空指针改为指向前驱或后继的线索。由于前驱和后继信息只有在遍历该二叉树时才能得到,所以,线索化的过程就是在遍历的过程中修改空指针的过程。
中序遍历线索化的递归函数代码如下:

上述代码除了//===之间的代码以外,和二叉树中序遍历的递归代码机会完全一样。只不过将打印结点的功能改成了线索化的功能。
中间部分代码做了这样的事情:
因为此时p结点的后继还没有访问到,因此只能对它的前驱结点pre的右指针rchild做判断,if(!pre->rchild)表示如果为空,则p就是pre的后继,于是pre->rchild = p,并且设置pre->rtag = Thread,完成后继结点的线索化。如图:
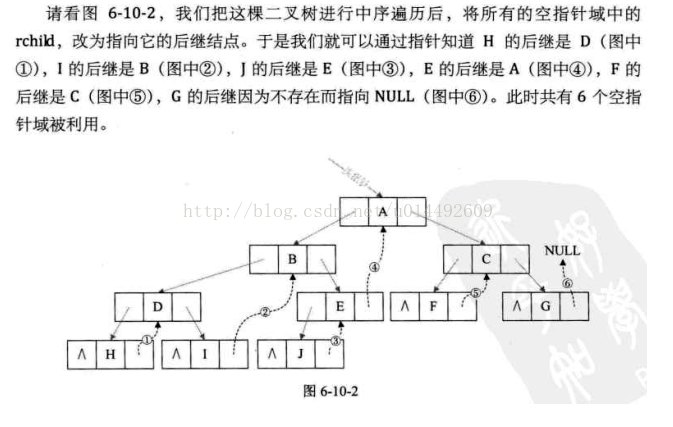
if(!p->lchild)表示如果某结点的左指针域为空,因为其前驱结点刚刚访问过,赋值了pre,所以可以将pre赋值给p->lchild,并修改p->ltag = Thread(也就是定义为1)以完成前驱结点的线索化。

完成前驱和后继的判断后,不要忘记当前结点p赋值给pre,以便于下一次使用。
有了线索二叉树后,对它进行遍历时,其实就等于操作一个双向链表结构。

和双向链表结点一样,在二叉树链表上添加一个头结点,如下图所示,并令其lchild域的指针指向二叉树的根结点(图中第一步),其rchild域的指针指向中序遍历访问时的最后一个结点(图中第二步)。反之,令二叉树的中序序列中第一个结点中,lchild域指针和最后一个结点的rchild域指针均指向头结点(图中第三和第四步)。这样的好处是:我们既可以从第一个结点起顺后继进行遍历,也可以从最后一个结点起顺前驱进行遍历。

转自:http://blog.csdn.net/u014492609/article/details/40477795

