



文本过滤涉及到以下知识:
正则表达式、find、grep、awk、sed、合并与分割(sort、uniq、join、cut、paste、split)。
正则表达式:

基本元字符集及其含义:

匹配IP地址:

find:

示例如下:
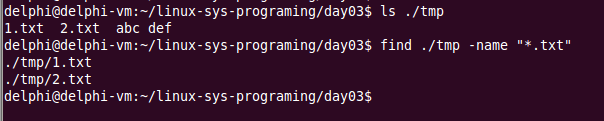





find命令练习实例:

find和xargs一起使用:


find和grep联合使用时,find会把所有找到的条目一次性传递给grep,有多少条就开多少个进程。
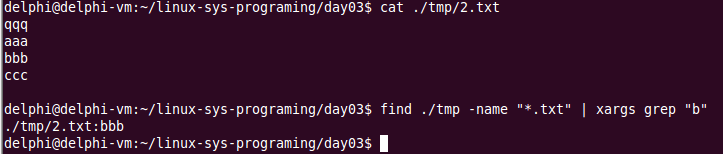
grep用法:
示例如下:

grep是检索行用的。awk是检索列,sed进行字符替换。 三者经常联合使用。
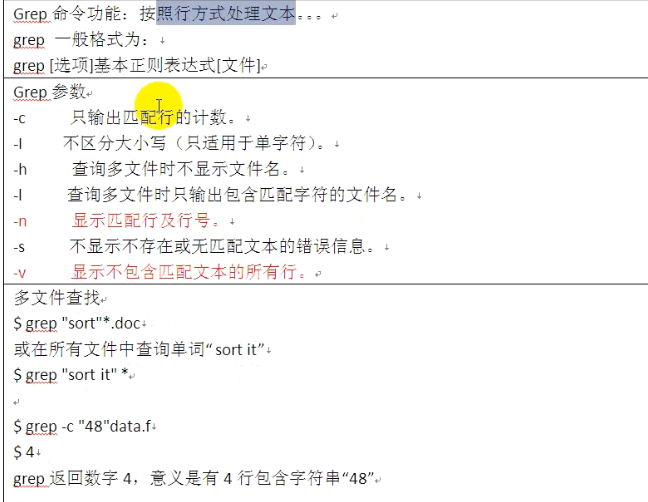
grep的正则表达式模式:
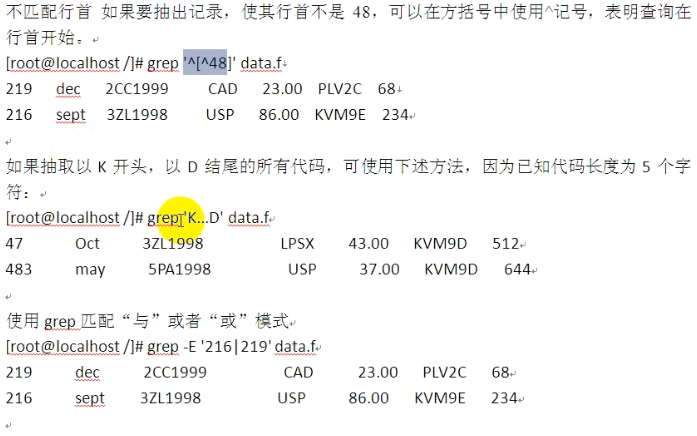
grep原理总结:

awk命令:
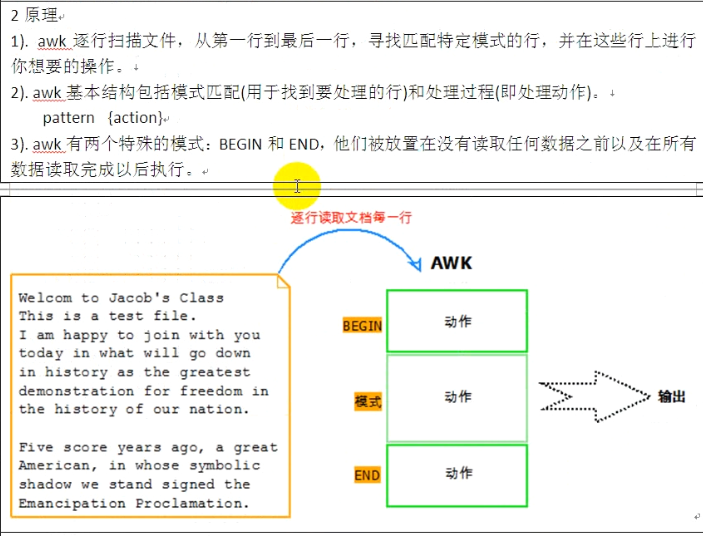
awk有三种调用模式:

示例程序如下:
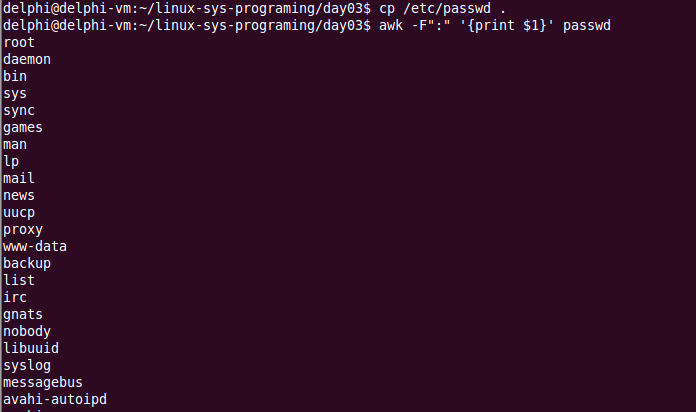
awk打印了passwd文件的第一列,-F参数表示文件中的分隔符,在本例中是冒号:,花括号里面表示打印第一列。
打印第一列和第三列,并且中间空一个制表符,如下所示:

打印第三列大于500的,如下:


grep与awk联合使用示例:


$0代表打印一整行。
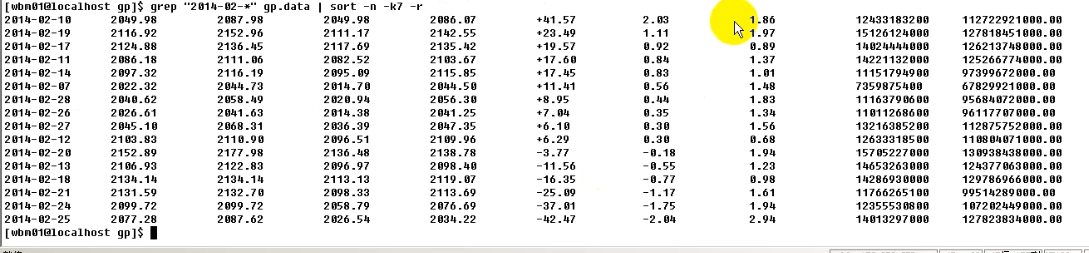
带排序的grep与awk联合使用:
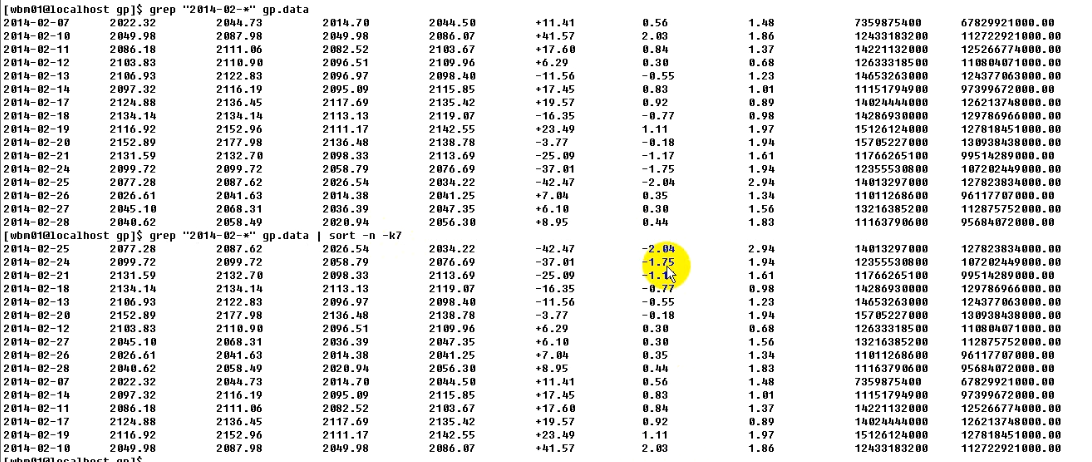
其中-n代表按数字方式, -k7代表按照第7列排序。

tail代表从最后一行开始取。sort加上-r表示逆序,如下:

sed提取数据,如下:
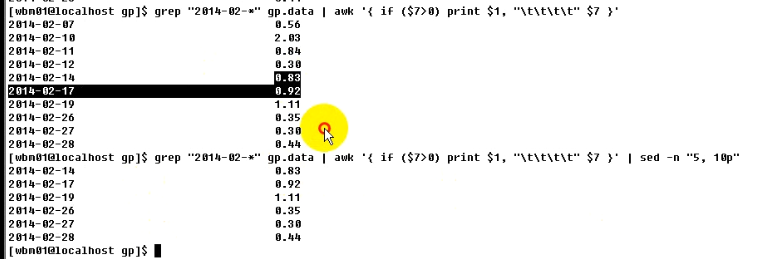
其中sed表示提取第5-10行的数据,p表示打印出来。


sed命令:
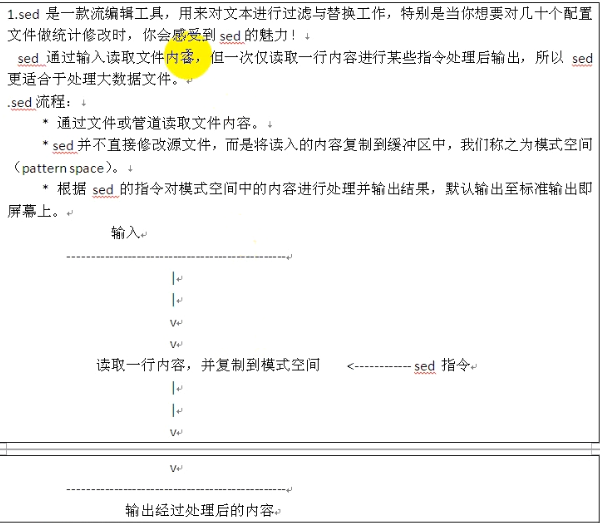
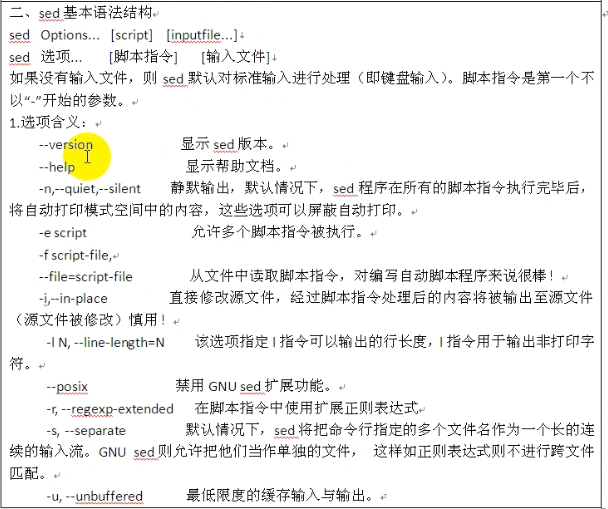

只带一个'p'表示打印所有行,包括空行。

sed后的2表示从第二行开始打印,一直打印到含有bb的行,p表示打印。
打印空行,=表示第几行,如下:

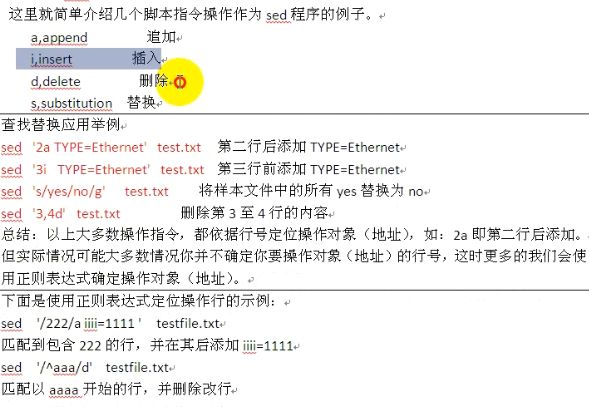


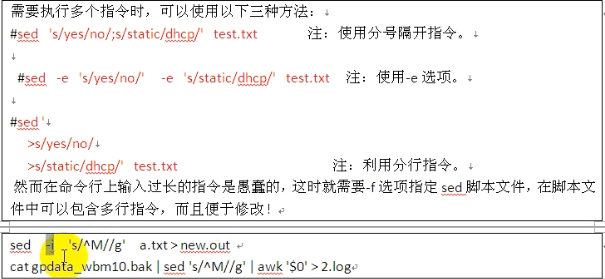
sed中的-i表示覆盖掉原来的文件,就是会对源文件进行修改。

sed的主要两个用途:
1、按照一个范围(第几行到第几行)提取数据
2、sed的主要用法是编辑功能,对提取的数据进行修改、替换、删除、插入等
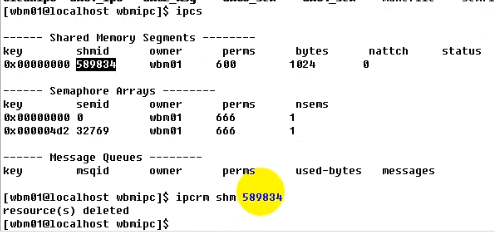
ipcs进程间通信工具,这是一个命令,可以使用man ipcs查看其具体使用方法。
ipcrm可以删除共享内存,如下所示:
ipcclean脚本:



