

python多线程迁移db2数仓9T数据
shell迁移脚本
tb=$1
echo $(date +%Y-%m-%d\ %H:%M:%S)",$tb begin"
db2 connect to sjckdb
db2 "declare c1 cursor database dbtest user admin using admin for select * from $tb"
db2 "load from c1 of cursor insert into $tb nonrecoverable"
db2 terminate
echo $(date +%Y-%m-%d\ %H:%M:%S)",$tb end"
导出需要迁移的数据库名文件,9条示例
TEST.DATE_TABLE
TEST.PROC_DEPENDENCIES
TEST.SY_TABLE
TEST.T1
TEST.T2
TEST.TEST_DETAIL
TEST.TEST_INFO
TEST.TEST_TB
TEST.TEST1
python多线程迁移脚本
# coding:utf-8
from datetime import datetime
from queue import Queue
import threading
import os
"""
python环境,2.7,redhat6.6自带
2.7是Queue,3.6是queue
"""
threadNum = 5
del_path = "/Data/datamove/tables.del"
sh_path = "/Data/datamove/db2.sh"
class MyThread(threading.Thread):
def __init__(self, func):
threading.Thread.__init__(self)
self.func = func
def run(self):
self.func()
def exeShell():
global lock
while True:
lock.acquire()
if q.qsize() != 0:
print("queue size:" + str(q.qsize()))
p = q.get() # 获得任务
tb = del_file[qsize - 1 - q.qsize()]
lock.release()
try:
tb_begin = datetime.now()
print(tb + ",begin time:" + str(tb_begin))
# 执行shell脚本
command = "sh " + sh_path + " " + tb
result = os.popen(command).read().strip()
print(result)
tb_end = datetime.now()
print(tb + ",end time:" + str(tb_end))
except Exception as e:
print(Exception, ":", e)
else:
lock.release()
break
if __name__ == '__main__':
task_begin = datetime.now()
print("db2 begin time:" + str(task_begin))
file = open(del_path, 'r')
del_file = file.read().splitlines()
q = Queue()
threads = []
lock = threading.Lock()
for p in range(len(del_file)):
q.put(p + 1)
qsize = q.qsize()
print("qsize:" + str(qsize))
for i in range(threadNum):
thread = MyThread(exeShell)
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
task_end = datetime.now()
print("db2 end time:" + str(task_end))
生产环境迁移
需要迁移的数据总量将近9T,总共6000多张表,按照表记录数从大到小生成表名文件。最先处理的都是数据量在亿级别的大表
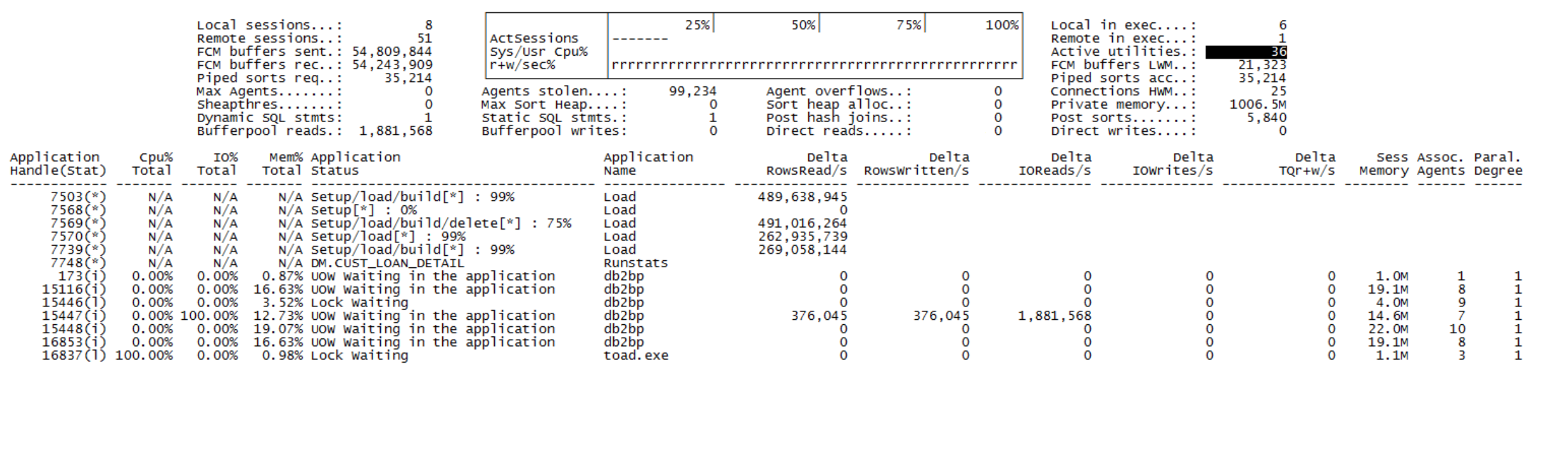
服务器性能监控
top查看每个cpu使用率在70,80%左右。iptraf查看网络带宽,使用的是千兆网卡,但是服务器的性能一般,写延迟比较严重,平均传输速度在100M/s左右。

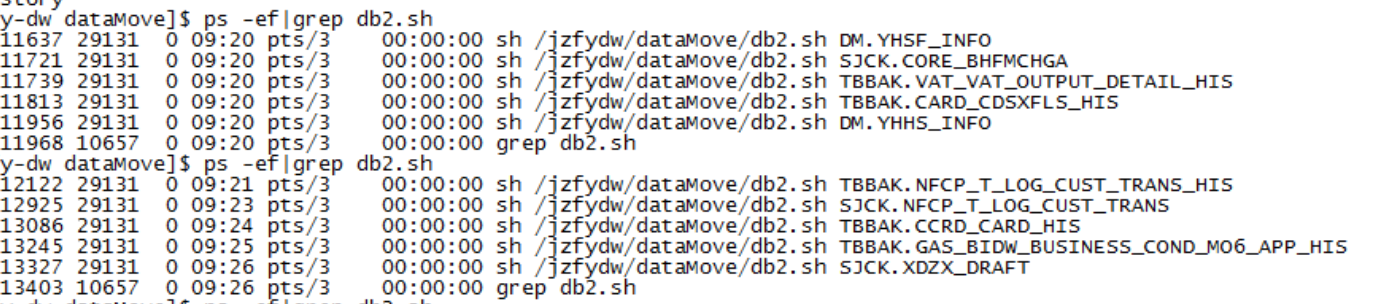
分析生成的日志文件
截取生成的部分日志文件为例,迁移成功的总条数是6.7亿,单表迁移画的时间将近1个半小时

日志分析
分析日志文件,输出行数前20的表的总记录数,还有花的时间
('SJCK.IMBS_T_CKSY_NSZMX', {'rows': 2066145603, 'difftime': '2时14分56秒'})
('SJCK.CORE_BYFTJRN_BEFORE_20190410', {'rows': 1073442051, 'difftime': '6时22分06秒'})
('DM.ACCT_MON_BAL', {'rows': 853552497, 'difftime': '2时51分55秒'})
('TBBAK.EPAY_ONLINESUBTRANS_HIS', {'rows': 758638974, 'difftime': '6时36分25秒'})
('DM.SMK_CARD_NEW', {'rows': 677450435, 'difftime': '1时16分55秒'})
('SJCK.CORE_BYFTJRN', {'rows': 589965163, 'difftime': '4时27分42秒'})
('TBBAK.CORE_BDFMHQAC_HIS', {'rows': 489643216, 'difftime': '1时41分52秒'})
('DM.CUST_LOAN_AVG', {'rows': 469622371, 'difftime': '1时03分52秒'})
('TBBAK.GAS_BI_CUX_LOAN_CHECK_DTL_V_HIS', {'rows': 437729919, 'difftime': '2时14分03秒'})
('DM.SMK_CARD_NEW_2015', {'rows': 395618719, 'difftime': '2时08分55秒'})
('TBBAK.CORE_BVFMFWLA_HIS', {'rows': 358681746, 'difftime': '1时02分19秒'})
('DM.SMK_CARD_NEW_2017', {'rows': 356939973, 'difftime': '1时08分23秒'})
('TBBAK.ZFB_T_ALI_JRNL_HIS', {'rows': 337809062, 'difftime': '1时57分22秒'})
('DM.SMK_CARD_NEW_2016', {'rows': 332844968, 'difftime': '0时30分53秒'})
('TBBAK.NFCP_KNB_CBDL_HIS', {'rows': 326577205, 'difftime': '1时11分46秒'})
('AML.FACTOR_WAREHOUSE_RESULT', {'rows': 154395676, 'difftime': '0时07分08秒'})
('LDJS.HXKH_DETAIL_LDJS', {'rows': 142164641, 'difftime': '0时05分28秒'})
('SJCK.CORE_BLFMRQWB', {'rows': 138158975, 'difftime': '0时23分33秒'})
('TBBAK.CORE_BLFMRQWB_HIS', {'rows': 138158975, 'difftime': '0时39分58秒'})
('TBBAK.CORE_BWFMDCIM_HIS', {'rows': 135799839, 'difftime': '0时40分50秒'})
可以看出越前面的大表画的时间越长,但是也有部分例外,推测是开始线程数太高,多线程资源竞争导致变慢。后续对于前面的大表,用较小线程数来跑;后面规模在百万级别或以下的小表,可以用较大线程数来跑。优化执行效率
posted on 2019-09-17 19:14 OneLi算法分享社区 阅读(445) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号