
运维监控: vmstat 命令
一、简介
vmstat(VirtualMeomoryStatistics,虚拟内存统计)从英文名中可以看出,他主要是Linux中监控内存的常用工具,可对操作系统的虚拟内存、进程、CPU等的整体情况进行监视。
二、用法
2.1 安装软件
[root@localhost ~]# yum -y install sysstat
2.2 格式
[root@localhost ~]# vmstat -h Usage: vmstat [options] [delay [count]] # 常用参数 vmstat [-a] [-n] [-S unit] [delay [ count]] vmstat [-s] [-n] [-S unit] vmstat [-m] [-n] [delay [ count]] vmstat [-d] [-n] [delay [ count]] vmstat [-p disk partition] [-n] [delay [ count]] vmstat [-f] vmstat [-V]
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
2.3 输出字段说明

vmstat 命令的输出
|
有关此命令的更多详细说明,请参见 vmstat(1M) 手册页。
三、演示
使用 vmstat -n 命令以秒为时间间隔单位收集虚拟内存统计信息。
其中,n 是两次报告之间的间隔秒数。如以 2 秒为间隔收集的统计信息显示如下
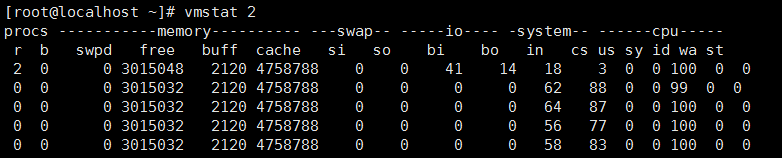
使用 vmstat delay count 命令以秒为时间间隔单位收集虚拟内存统计信息。
每隔 1 秒采集一次,采集 3 次

使用 vmstat 指定单位输出结果
指定 MB 单位输出结果(参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes))
[root@localhost ~]# vmstat -S M 1 3

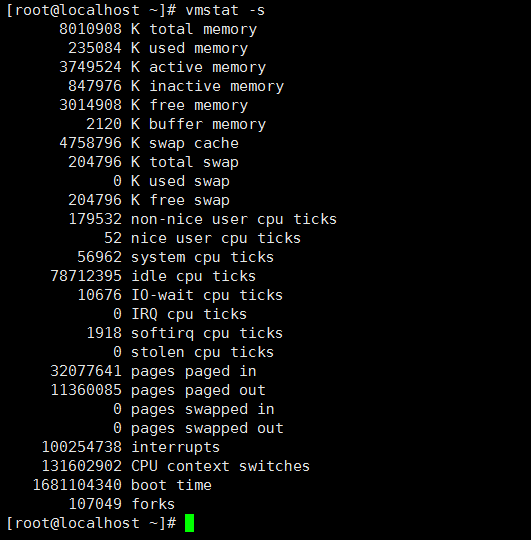
运行 vmstat -s 命令,以表格方式显示自上次引导系统以来发生的系统事件数和内存状态。
[root@localhost ~]# vmstat -s
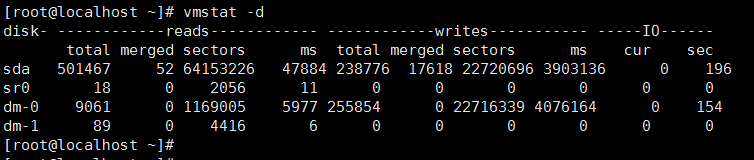
查看磁盘的读/写
指定单位进行查看
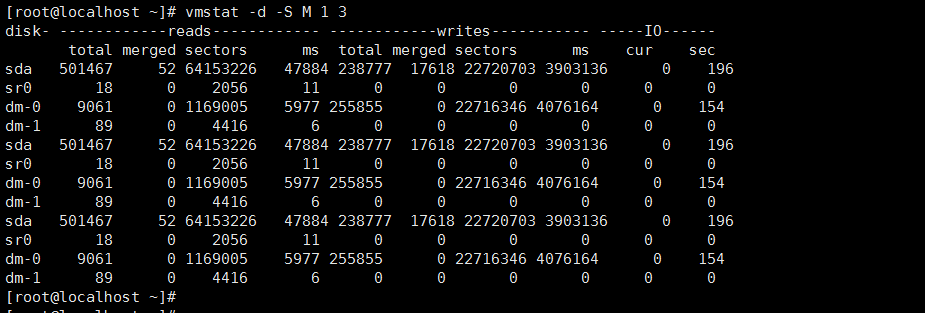
参数说明
读
total: 成功读取的总数
merged: 分组读取(产生一个 IO)
sectors: 成功读取的扇区数
ms: 读取花费的毫秒
写
total 成功写入的总数
merged 分组写入(产生一个 IO)
sectors 成功写入的扇区数
ms 写花费的毫秒
IO
cur 正在进行的IO
sec IO花费的秒数
四、压力测试
进行一个写入的压力测试,并实时观察vmstat结果
# 测试20G数据写入
[root@localhost ~]# sync;time -p bash -c "(dd if=/dev/zero of=test.dd bs=1M count=2000 oflag=dsync)"

物理内存不足时:
- swpd 不为0时,表示开始使用swpd
- si、so 大于 0 开始从硬盘中读取,表示机器的物理内存不足了。
表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。(大于0,关注内存泄漏,结合si和so看,如果si和so为0,也没关系)
常见问题及解决办法
如果r经常大于4,且id经常少于40,表示cpu的负荷很重。
如果pi,po长期不等于0,表示内存不足。
如果disk经常不等于0,且在b中的队列大于3,表示io性能不好。
1、如果在processes中运行的序列(process r)是连续的大于在系统中的CPU的个数表示系统现在运行比较慢,有多数的进程等待CPU。
2、如果r的输出数大于系统中可用CPU个数的4倍的话,则系统面临着CPU短缺的问题,或者是CPU的速率过低,系统中有多数的进程在等待CPU,造成系统中进程运行过慢。
3、如果空闲时间(cpu id)持续为0并且系统时间(cpu sy)是用户时间的两倍(cpu us)系统则面临着CPU资源的短缺。当发生以上问题的时候请先调整应用程序对CPU的占用情况.使得应用程序能够更有效的使用CPU.同时可以考虑增加更多的CPU.关于CPU的使用情况还可以结合mpstat, ps aux top prstat –a等等一些相应的命令来综合考虑关于具体的CPU的使用情况,和哪些进程在占用大量的CPU时间.一般情况下,应用程序的问题会比较大一些.比如一些sql语句不合理等等都会造成这样的现象.
内存问题现象:
内存的瓶颈是由scan rate (sr)来决定的.scan rate是通过每秒的始终算法来进行页扫描的.如果scan rate(sr)连续的大于每秒200页则表示可能存在内存缺陷.同样的如果page项中的pi和po这两栏表示每秒页面的调入的页数和每秒调出的页数.如果该值经常为非零值,也有可能存在内存的瓶颈,当然,如果个别的时候不为0的话,属于正常的页面调度这个是虚拟内存的主要原理.
解决办法:
1.调节applications & servers使得对内存和cache的使用更加有效.
2.增加系统的内存.
3. Implement priority paging in s in pre solaris 8 versions by adding line "set priority paging=1" in /etc/system. Remove this line if upgrading from Solaris 7 to 8 & retaining old /etc/system file.
关于内存的使用情况还可以结ps aux top prstat –a等等一些相应的命令来综合考虑关于具体的内存的使用情况,和那些进程在占用大量的内存.一般情况下,如果内存的占用率比较高,但是,CPU的占用很低的时候,可以考虑是有很多的应用程序占用了内存没有释放,但是,并没有占用CPU时间,可以考虑应用程序,对于未占用CPU时间和一些后台的程序,释放内存的占用。
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
5.常见性能问题分析
IO/CPU/men连锁反应
IO/CPU/men连锁反应 1、free急剧下降 2、buff和cache被回收下降,但也无济于事 3、依旧需要使用大量swap交换分区swpd 4、等待进程数,b增多 5、读写IO,bi bo增多 6、si so大于0开始从硬盘中读取 7、cpu等待时间用于 IO等待,wa增加
内存不足
1、开始使用swpd,swpd不为0
2、si so大于0开始从硬盘中读取
io瓶颈
1、读写IO,bi bo增多超过2000
2、cpu等待时间用于 IO等待,wa增加 超过20
3、sy 系统调用时间长,IO操作频繁会导致增加 >30%
4、wa io等待时间长
iowait% <20% 良好
iowait% <35% 一般
iowait% >50%
5、进一步使用 iostat 观察
CPU瓶颈:load,vmstat中r列
5.1 反应为CPU队列长度
5.2 一段时间内,CPU正在处理和等待CPU处理的进程数之和,直接反应了CPU的使用和申请情况。
5.3 理想的load average:核数*CPU数*0.7
CPU个数查看:grep 'physical id' /proc/cpuinfo | sort -u
核数查看:grep 'core id' /proc/cpuinfo | sort -u | wc -l
5.4 超过这个值就说明已经是CPU瓶颈了
CPU瓶颈
1.us 用户CPU时间高超过90%
涉及到web服务器,cs 每秒上下文切换次数
例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
1.cs可以对apache和nginx线程和进程数限制起到一定的参考作用
2.我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了
较好的趋势:主要是 swap使用少,swpd数值低。si so分页读取写入数值趋近于零
6.其他说明:
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt 等待IO CPU时间。
转载自:https://blog.csdn.net/gcc001224/article/details/125313217

 浙公网安备 33010602011771号
浙公网安备 33010602011771号