


20190919-3 效能分析
此作业要求参见https://edu.cnblogs.com/campus/nenu/2019fall/homework/7628
git地址:https://e.coding.net/wangzw877/xiaonengfenxi.git
要求0 以 战争与和平 作为输入文件,重读向由文件系统读入。连续三次运行,给出每次消耗时间、CPU参数
使用命令行进入程序,输入如下命令:ptime wf -s < war_and_peace.txt进行连续三次测试。
测试结果截图如下:
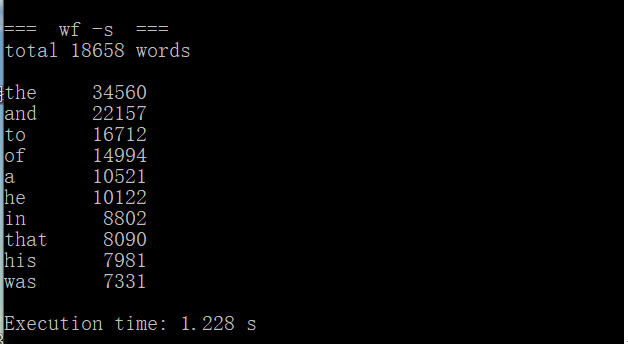
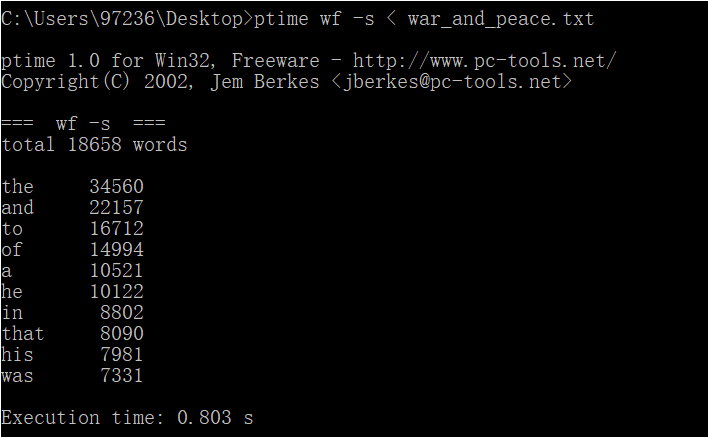
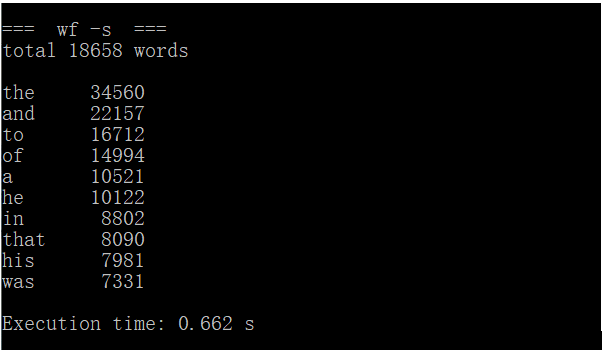
CPU参数:Intel(R) Core(TM) i5-7200U CPU @ 2.50GHz 2.70GHz
消耗时间汇总:
|
第一次运行时间 |
1.228s |
|
第二次运行时间 |
0.803s |
|
第三次运行时间 |
0.662s |
|
平均运行时间 |
0.898s |
要求1 给出你猜测程序的瓶颈。你认为优化会有最佳效果,或者在上周在此处做过优化 (或考虑到优化,因此更差的代码没有写出)
猜测的瓶颈:1.由文件重定向读入时遍历文档耗费大量时间来进行字母大小写和字符与符号的转换。
2.在通过正则表达式分割单词时消耗时间。
3.多次使用了count函数计数。
要求2 通过 profile 找出程序的瓶颈。给出程序运行中最花费时间的3个函数(或代码片断)。要求包括截图要求1 给出你猜测程序的瓶颈。你认为优化会有最佳效果,或者在上周在此处做过优化
使用命令行进入程序,输入如下命令:python -m cProfile -s time wf.py -s < war_and_peace.txt
运行结果分析截图如下:

使用时间最多的三个函数及运行次数:
|
函数名称 |
运行次数 |
运行时间 |
|
findall() |
1 |
0.206s |
|
count() |
2 |
0.142s |
|
read() |
1 |
0.036s |
要求3 根据瓶颈,"尽力而为"地优化程序性能
尝试封装count函数,进而减少collections.Counter()函数的调用次数。
优化前的代码片段:
def doSomeFileCount(path): print(path) f = open(path, encoding='utf-8') words = re.findall(r'[a-z0-9^-]+', f.read().lower()) collect = collections.Counter(words) num = 0 for i in collect: num += 1 print('total %d words\n' % num) result = collect.most_common(10) for j in result: print('%-8s%5d' % (j[0], j[1])) print('----') def doCountByPurText(inputText): words = re.findall(r'[a-z0-9^-]+', inputText.lower()) collect = collections.Counter(words) num = 0 for i in collect: num += 1 print('total %d words\n' % num) result = collect.most_common(10) for j in result: print('%-8s%5d' % (j[0], j[1])) collect = collections.Counter(words) num = 0 for i in collect: num += 1 print('total %d words\n' % num) result = collect.most_common(10) for j in result: print('%-8s%5d' % (j[0], j[1]))
优化后的代码:
def count(words): collect = collections.Counter(words) num = 0 for i in collect: num += 1 print('total %d words\n' % num) result = collect.most_common(10) for j in result: print('%-8s%5d' % (j[0], j[1]))
def doSomeFileCount(path): print(path) f = open(path, encoding='utf-8') words = re.findall(r'[a-z0-9^-]+', f.read().lower()) count(words) print('----') def doCountByPurText(inputText): words = re.findall(r'[a-z0-9^-]+', inputText.lower()) count(words)
要求4 再次 profile,给出在 要求1 中的最花费时间的3个函数此时的花费。要求包括截图
再次进行profile运行结果截图如下:
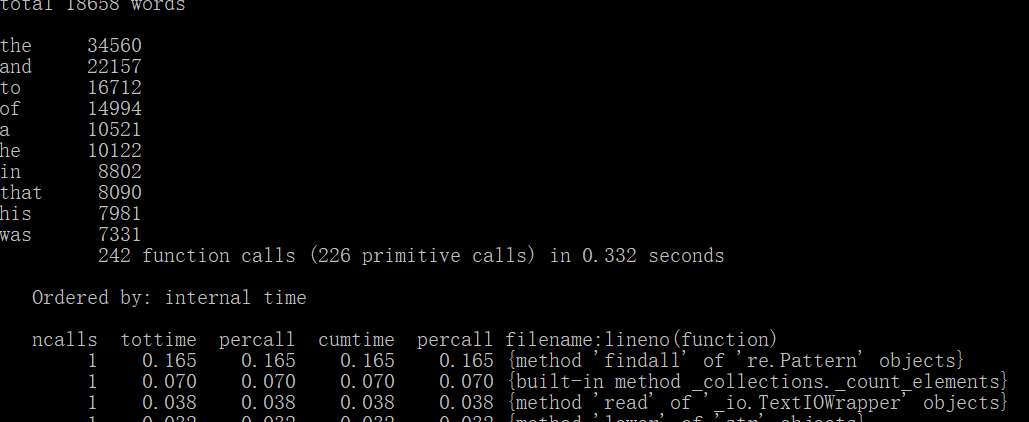
使用时间最多的三个函数及运行次数:
|
函数名称 |
运行次数 |
运行时间 |
|
findall() |
1 |
0.165s |
|
count() |
1 |
0.070s |
|
read() |
1 |
0.038s |
修改后再次使用命令行进入程序,输入如下命令:ptime wf -s < war_and_peace.txt进行连续三次测试。
测试结果截图如下:
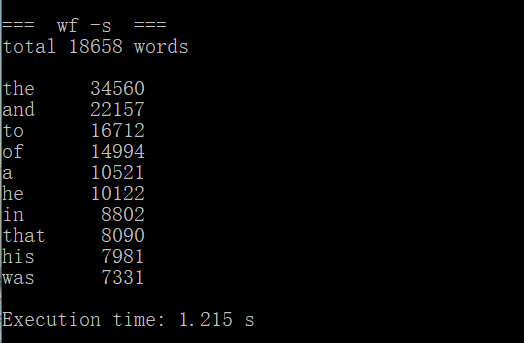
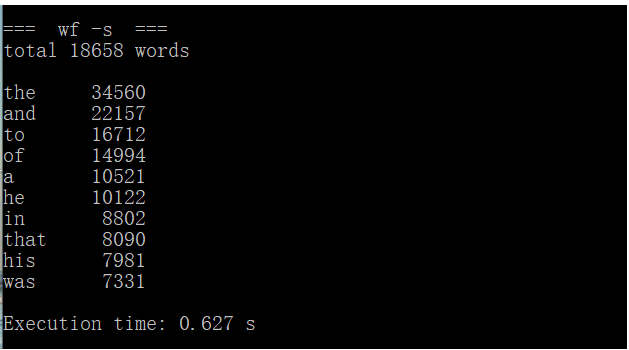
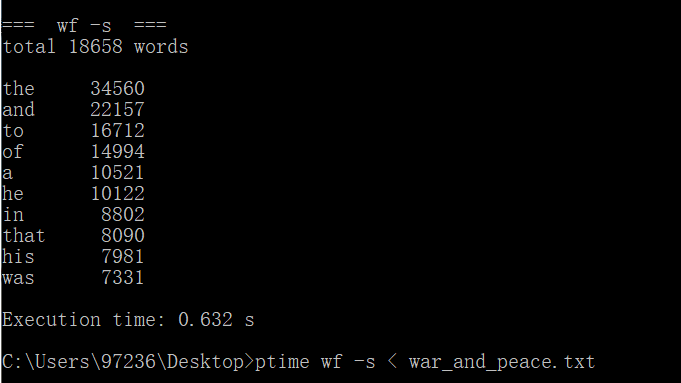
CPU参数:Intel(R) Core(TM) i5-7200U CPU @ 2.50GHz 2.70GHz
消耗时间汇总:
|
第一次运行时间 |
1.215s |
|
第二次运行时间 |
0.627s |
|
第三次运行时间 |
0.632s |
|
平均运行时间 |
0.824s |
运行时间由平均0.898s下降至0.824s。

