build tool
Build Tool(构建工具)
what:
构建工具能够帮助你创建一个可重复的、可靠的、携带的且不需要手动干预的构建。构建工具是一个可编程的工具,它能够让你以可执行和有序的任务来表达自动化需求。假设你想要编译源代码,将生成的class文件拷贝到某个目录,然后将该目录组装成可交付的软件。如下图所示,展示了所描述场景中任务和它们执行的顺序。

每个任务都代表着一个工作单元——例如,编译源代码。顺序是非常重要的。如果所需要的class文件没有被编译出来,那么你是不能够组建构件的。因此编译任务必须先被执行。
本质上,任务和它们的相互依赖被模块化成一个有向非循环图(DAG)。DAG是计算机科学的一种数据结构,包含下面两个元素:
节点:一个工作单元;就构建工具而言,它指的是一个任务(例如,编译源代码)。
有向边:有向边也叫作箭头,表示点节之间的关系。在这里,箭头表示依赖关系。如果一个任务的定义依赖于另一个任务,那么所依赖的任务就必须先被执行。发生这种情况常常是因为一个任务依赖于另一个任务的输出。这里有个例子——要执行任务“组装可交付软件”,你需要先执行任务“拷贝class文件到目录”和“编译源代码”。
每个节点都知道自己的执行状态。一个节点——表示一个任务——只能被执行一次。
作为开发人员,你没有必要和DAG图打交道。这个工作是由构建工具来完成的。
构建工具的剖析
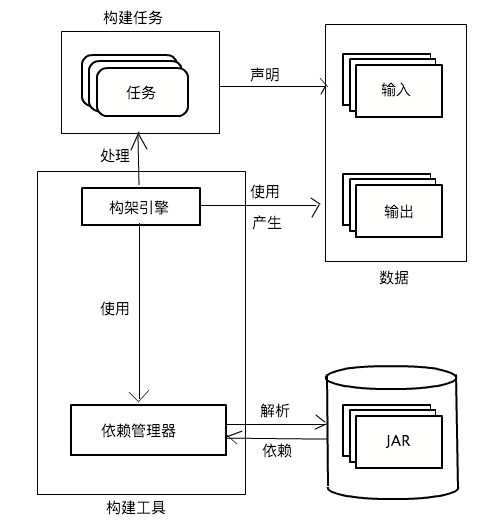
理解构建工具中组建的交互、构建逻辑和实际定义,以及输入输出的数据是非常重要的。让我们一起来探讨一下构建工具中每一个元素以及它们的职责。
1.构建文件
构建文件包含了构建所需的配置信息、定义外部依赖,例如第三方类库,还包含了以任务形式实现某个特殊目的的指令和它们的相互依赖关系。
就如前面的例子——编译源代码、拷贝class文件到目录以及组装构件——都可以定义在构建文件中。在通常情况下,会使用脚本语言来表达构建逻辑。这就是为什么一个构建文件也叫做构建脚本的原因。
2.构建的输入和输出
一个任务会接受一个输入,然后执行一系列步骤,最后产生一个输出。某些任务也需不需要输入,也不需要产生一个必要的输出。在复杂的任务依赖关系中,也许会使用一个依赖任务的输出作为输入。例如,我们将源代码文件作为输入,将它们编译为class文件,并组装成可交付软件作为输出。编译和组装过程各表示一个任务。只有先编译了源代码,组装可交付软件才有意义。因此两任务需要保证它们的顺序。
3.构建引擎
构建文件的一步步指令或者规则集必须被翻译成构建工具可以理解的内部模型。构建引擎会在运行时处理构建文件,解析任务之间的依赖,设置好执行做需要的全部配置。
一旦内部模型建立好了,引擎就会按照正常的顺序去执行一系列任务。某些构建工具还允许你通过API去访问这个模型,以便运行时获取构建信息。
4.构建管理器
依赖管理器用于处理你在build文件中声明的依赖定义,从工件仓库(例如,本地文件系统、一个FTP或者HTTP服务器)中解析它们,并使它们对项目可用。一来通常是指外部依赖,一种JAR文件形式的可重用类库(例如,Log4j对日志的支持)。该仓库就像依赖的储藏所,通过标识符和描述它们,例如名字和版本。一个典型的仓库可以是HTTP服务器或者本地文件系统。
许多类库还依赖于其他类库,这叫做传递依赖。依赖管理器可以通过存储在仓库中的元信息自动的解析传递依赖。但是一个构建工具并不要求提供这样的依赖管理组件。
how:
整个过程可以分成以下几个步骤:
- 编译源代码
- 运行单元测试和集成测试
- 执行静态代码分析、生成分析报告
- 创建发布版本
- 部署到目标环境
- 部署传递过程
- 执行冒烟测试和自动功能测试
虽然两者都是项目工具,但是maven现在已经是行业标准,Gradle是后起之秀,很多人对他的了解都是从android studio中得到的,Gradle抛弃了Maven的基于XML的繁琐配置,众所周知XML的阅读体验比较差,对于机器来说虽然容易识别,但毕竟是由人去维护的。取而代之的是Gradle采用了领域特定语言Groovy的配置,大大简化了构建代码的行数,比如在Maven中你要引入一个依赖:
<properties>
<kaptcha.version>2.3</kaptcha.version>
</properties>
<dependencies>
<dependency>
<groupId>com.google.code.kaptcha</groupId>
<artifactId>kaptcha</artifactId>
<version>${kaptcha.version}</version>
<classifier>jdk15</classifier>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
</dependencies>
然后我将其转换成Gradle脚本,结果是惊人的:
dependencies {
compile('org.springframework:spring-core:2.5.6')
compile('org.springframework:spring-beans:2.5.6')
compile('org.springframework:spring-context:2.5.6')
compile('com.google.code.kaptcha:kaptcha:2.3:jdk15')
testCompile('junit:junit:4.7')
}
Gradle给我最大的优点是两点。其一是简洁,基于Groovy的紧凑脚本实在让人爱不释手,在表述意图方面也没有什么不清晰的地方。其二是灵活,各种在Maven中难以下手的事情,在Gradle就是小菜一碟,比如修改现有的构建生命周期,几行配置就完成了,同样的事情,在Maven中你必须编写一个插件,那对于一个刚入门的用户来说,没个一两天几乎是不可能完成的任务。
why:
构建工具 —— 让项目变得自动化。
项目自动化对于团队的成功是非常的重要的。如今,发布时间对于市场变得比以前更重要了。能够以一种可重复、可持续的方式构建和交付软件是关键。接下来看一看项目自动化所带来的好处:
1.防止手动介入
不得不手动地执行每一步去实现和交付软件是耗时且易于犯错的。坦白地说,作为一个开发人员和管理员,比起编译过程和拷贝文件,还有更重要的事情要做。我们都是人,难免会犯错,而且手动加入还会占用你真正做实际事情的时间。软件开发过程中的任何一步都是能够且应该被自动化的。
2.创建可重复的构建
软件的构建通常都是有预定义和有序的步骤。比如,你需要先编译源代码,然后运行测试,最后组装可交付软件。你将需要每天一遍又一遍的重复运行相同的步骤。这应该和按一下按钮一样简单。无论是谁在运行该构建,构建过程的结果都应该是可重复的。
3.让构建携带
你可以发现,能够在IDE(集成开发环境)中运行的构建是非常有限的。首先,你必须将特定的产品安装在机器上。其次,IDE也许只适用于某一种操作系统。一个自动化构建不应该依赖于特定的运行环境才能工作,无论是操作系统还是IDE。最佳的方式应该是,自动化任务从命令行运行,它允许你在任何时间和任何一台想要运行构建的机器上运行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号