一个大规模爬虫的抓取实例
http://www.michaelnielsen.org/ddi/how-to-crawl-a-quarter-billion-webpages-in-40-hours/
一个大规模爬虫的抓取实例
本文是一篇大规模爬虫的文章的阅读笔记,记录了一个作者利用amazon集群在40个小时的时间里爬取2.5亿个网页的过程。
相关参数
page:2.5亿
cost:580 dollar
time:40 hours
machine:20 Amazon EC2
storage:总共抓取了1.69 TB
目的:
找到一个有用的网络子集,实践爬虫和分布式计算
技术实现:
分布式爬虫
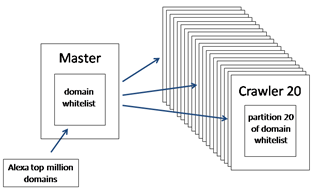
节点:Amazon EC2
集群控制:Fabric
语言:Python
爬取方式:
1)每个集群141个爬虫线程,从Alexa白名单[1]得到初始域名
选择141个是根据实验效果达到饱和确定的
2) 任务分配:哈希分配机器、哈希分配线程;
3)
从alexa开始,对每个网页抓取;
舍弃抓取的external link,其他的加入url frontier;
在url frontier中取出url,继续抓取;
log记录
问题:
1.url去重:大规模爬虫遇到的常见问题,可以用Bloom Filter(布隆过滤器)的库pybloomfiltermmap和redis,但是可能造成错误判断而舍弃应该抓取的url;redis的作用是存储为url设置的键值,其键-值为(url-下一次应抓取时间),这是为了遵循为了抓取的道德准则,避免对网站造成压力
2. 1)可预见的bug和不可预见的bug,如不规范的html。一般舍弃。解析页面一般用python的lxml库。
2)去除外链会导致一些不规则的子域名不能被加入爬取的流程,group.barclays.com
barclays.com的子域名;解决方法是tldextract library;
3. 同时抽取多个域名加入列表会导致流量负担,姑且称作clump problem;
解决方法是用单机的url frontier来代替全局的url frontier
4. url的存储方式遇到去重的问题,每个线程会消耗大量空间;
5. 分配线程跟机器的hash要用两个独立的函数或者用一个
6. 截断:因为有些html页面太大,需要截断。可以用网络的页面平均大小来估计应该截断的合理值,最后确定是200kb。
其他
进行爬取用到的相关价格:价格:512 dollars,节点 EC2,500 gigabytes,
Spot-instance:竞价实例是亚马逊出卖自己闲置资源的一种方式,出价高的拥有实例,价格比较划算。它可能是同样计算能力的实例价格的1/10。这是一个让人惊讶的数字。它的实体在13年底就估计达到了300万台。但是竞价实例可以随时被亚马逊回收。
threaded architecture和evented architecture是有区别的。本文采用的是threaded architecture。即:多线程爬虫跟异步爬虫的区别。
注:
[1] Alexa是一个亚马逊的子公司,用来发布网站的世界排名。可以通过该网站找到前100万的网址。
[2] 该爬虫可能会给单一站点带来很大的流量负担,所以为了防止被一些人轻率地滥用,作者无限期推迟发布代码(也即不发布)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号