【搜索引擎(四)】文本分类
Q1. 为什么搜索引擎要用到文本分类?
搜索引擎要处理海量文本,人工分类不现实,机器的自动分类对提高文本的分类效率至少起到了一个基准的效果。另外,文本分类跟搜索引擎系统可以进行信息互通,文本分类的输入是文本,输出可以是标签或者是否从属于某个分类。
Q2.文本分类基础算法
文本分类基础算法与机器学习、人工智能、数据挖掘中用到的算法都是联系紧密的,它从属的自然语言处理也正是人工智能的分支。你可能会想到文本分类肯定要用到基础的分类器,而且在更复杂的情况下可能还要用到人工智能的一些学习方法,比如双向LSTM和CNN。
目前来看,文本分类通常用的是有监督的学习方法,这不是说无监督就没有用了,只是为了精度的要求,有监督是比较靠谱的。另外,文本分类几乎都是按照数据挖掘的套路来做的,好像是抽取特征->训练->验证->分类。
分类器输入文本,输出标签(single-label or multi-label)。
Q3.文本分类的规模有多大?
文本分类的规模有大有小,但是这只是针对训练集来说,而实际分类的输入除了数目以外,单个的大小是没有太大差异的。
正文
无监督算法和有监督算法
一、有监督分类器
决策树
Bayes 分类器 Rocchio分类器
朴素贝叶斯分类器:计算
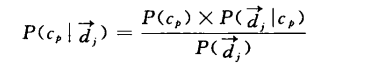 , 即给出文档dj,求它属于类别 cp的概率,概率最大的cp就是文档本分到的类别了。在概率论与数理统计中求这个概率的最大一般都是求对数然后偏导为0。
, 即给出文档dj,求它属于类别 cp的概率,概率最大的cp就是文档本分到的类别了。在概率论与数理统计中求这个概率的最大一般都是求对数然后偏导为0。
二、支持向量机
支持向量机是什么?从一般的教材说法来看,它是一个多维空间的平面方程,由法向量和点唯一确定。支持向量是指在这个空间内能够使该方程满足偏移常数为1的向量。
这个平面是由训练集确定参数,以实现分类间隔最大化的一个结果。
【在机器学习包sklearn中提供了它的实现,训练的特点是花的空间少但是时间特别长】
核函数:针对不同的输入向量,将它们映射到变换空间中所用到的函数,一般采用输入向量的乘积(或称点积)
有了支持向量机,就要用SVM的相应决策函数。
三、集成分类器
它是将不同的分类器(如前面说的SVM, DT, Bayes)的结果合成,构成更高精度的方法。
当然,怎么合成不是乱来的。怎么合理地合成引出了集成学习这一概念。
增强学习分类器叫做boost
Adaboost 是最早在论文中提到的将boost应用在文本分类的算法。此后又出现了一些算法。
历史发展: boost->Adaboost->AdaBoost。
四、无监督学习
特征选择和降维(一般用SVD, PCA)。
其他
文档分类的评价标准
Precision, Recall,F-标准,。
标准文档集
1. Reuters [21578] http://www.daviddlewis.com/resources/testcollections/reuters21578/, 2004年收集, (8.2 MB; 28.0 MB uncompressed, though I downloaede a file of 27 MB).
2. RCV Reuters Corpus Volumes 路透社新闻报道
3. OHSUMED 医学主题词, MEDICINE 数据库的子集
ftp://medir.ohsu.edu/pub/ohsumed (已失效)
http://davis.wpi.edu/xmdv/datasets/ohsumed.html TREC9 的文档过滤子竞赛
4. WebKB(超文本集合)
5. ACMDL(ACM-Digital-Library的一个子集), ODP
竞赛举例
CIKM竞赛, 2014年 Query Intent Detection
软件包
ID3 C4.5 [1311], [1313]
SVMLight[839], LibSVM[355], SVMPerf[840]
Bow[1104], Weka[1707]
参考会议
ICML, SIGKDD,SIGIR

 浙公网安备 33010602011771号
浙公网安备 33010602011771号