【笔记】通过目标编码和分类损失实现的神经场分类器【ICLR2024】
这是一篇发表在 ICLR 2024 会议上的学术论文的阅读笔记,题为“Neural Field Classifiers via Target Encoding and Classification Loss”,作者来自北京交通大学和百度研究院。
为什么会找到这篇文章,因为文章的一个作者是HKUST一个基础实验室的,搞的是偏底层的算法理论,所以自然就顺下来了。但是看完之后发现并没有什么理论分析,几乎是纯实验。但是时间毕竟花了,顺便也了解了一下NeRF这个之前比较热点的方向。不过因为一直在搞NLP,我对此只能算是外行,只能说学过一点图形学和光追,毕竟CV和SLAM的技术栈超级庞大,所以也不打算花太多时间推公式了。
本文分为以下几个部分:
一、文章摘要
Neural field methods have seen great progress in various long-standing tasks in computer vision and computer graphics, including novel view synthesis and geometry reconstruction.
这是讲背景,神经场方法在CV和图形学中的许多长期任务又长足的进步了。
场是物理学概念,当然研究CV的肯定对此早已清楚,例如可以用多维函数f(x,y,z)表示某一个场。而所谓神经场,是利用nn的方法进行场相关的建模。
之后,作者介绍了NeRF方法,这就是一种神经场方法。现存的NeRF及其变种的方法都是回归模型,损失是连续的,而他们不拘泥于连续的优化目标,提出了一种离散化的方法。
当然,最近比较火的其实是Gaussian Splatting,只能说CV界变化确实是快。
二、贡献
1.提出了一个Neural Field Classifier (NFC) 的框架
2.在这个框架里,利用Target Encoding在最后一层将回归目标转换为多个二分类问题,最小化分类损失
3.经过实验,他们发现分类损失在视角合成(view synthesis)和几何重建(geometry reconstruction)上都取得了更好的效果。
NeRF基础
NeRF can efficiently represent a given scene by implicitly encoding volumetric density and color through a coordinatebased neural network (often referred to as a simple multilayer perceptron or MLP).
简介了NeRF这个神经网络的功能。它的效果是输入坐标和相机角度(共5个维度),预测得到颜色,而学习的权重是神经网络内的参数。假设已经学习完毕,它能够给出以下对颜色的结果:

其中σ是在3D空间中某个点的密度。
T 表示从某个点到射线另一端的累积透射率。它描述了光线在经过空间中某个路径时由于吸收和散射而衰减的程度。
C是颜色向量,是RGB的三通道表示。
这里是光线追踪的效果。当然文中并没有仔细介绍NeRF的内容,因为NeRF原文有25页,细节比本文的多很多。
损失函数:看起来没有什么特别的。

三、方法
C = (R, G, B) 是三通道的,RGB编码成二进制编码

思路很简单,是将RGB变成离散二进制,如将颜色值203编码为8位二进制数[1, 1, 0, 0, 1, 0, 1, 1]。训练完成后再解码回原来的颜色值。
正则项是二进制的交叉熵BCE(^C, C),

四、实验分析
4.1 结论
对比了四个已有的NeRF网络模型。这里不是提出了新的网络结构,而是对原来的回归输出全部改成了离散的输出。所以对比的方式是比较回归的输出和离散的输出下的区别。
这里就直接说原文了:量化结果(表1和表2)表明,NFC一致地改进了现有的三类神经场方法。定性结果在图3中展示。特别是,DVGO作为加速变体,有时在重建具有挑战性的场景时会遇到问题,但可以通过NFC得到显著增强;而普通NeRF,作为一种相对较慢的神经场方法,也可以通过NFC得到一致的增强。在Replica数据集上,DVGO的图像质量改进尤为令人印象深刻,实现了99.7%的峰值信噪比(PSNR)增益。鉴于在Replica中重建复杂场景的困难,如复杂对象中的复杂纹理模式、变化的光照条件和稀疏的训练视图,NFC相对于NFR(可能指另一种方法或技术)的优势变得更加明显。
4.2 指标
文中用了三个指标。PSNR, SSIM, LPIPS。简单解释如下:
PSNR,Peak Signal-To-Noise Ratio 峰值信噪比是基于MSE(Mean Squared Error,均方误差)的一个指标,MSE衡量的是原始图像与失真图像之间的平均误差平方。

SSIM是一个更先进的图像质量评估指标,它不仅考虑了亮度和对比度,还考虑了图像的结构信息。
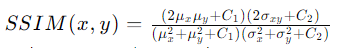
LPIPS的核心思想是将图像分割成小块(patches),然后使用深度网络来比较这些小块之间的感知差异。包括步骤为:1.将参考图像和待评估图像分割成小块。
2.使用预训练的深度学习模型提取这些小块的特征。
3.在特征空间中计算这些小块之间的距离。
4.将这些距离转换为一个整体的相似度分数。
LPIPS的分数越低,表示两幅图像之间的感知差异越小,图像质量越好。一般认为LPIPS能够更准确地模拟人类的视觉感知。
五、结论
总而言之,这是一篇偏工程向的论文,没有太多分析的结论。但是实验效果提升比较明显,而且至少做了四个实验。可能是看在工作量和适用性上被接收了。
也可能回归改离散这种看起来很简单的改进也是一种好的创新?希望有大佬能锐评一下。
六、问题
以下问题是不太熟悉这个领域的人(比如我)提的:
问题1:视角合成是什么意思,和几何重建是什么关系?另外一个常用的数据位姿没有出现?
视角合成是指从一组给定的图像(通常是从不同视角拍摄的)生成新的图像,这些新图像看起来就像是从一个全新的视角拍摄的。在视角合成的Demo中,就是左右上下移动摄像机看到的动图效果。
问题2:体素渲染是什么?跟多个图片合成的关系是什么?
在体素渲染中,整个三维场景或对象被表示为一个由体素组成的网格。每个体素包含有关其所在位置的信息,如颜色、密度等,这与使用多个二维图像来描述三维场景的原理相似。
体素渲染通常与光线追踪(Ray Tracing)技术结合使用,以模拟光线在三维空间中的传播和与物体的相互作用。通过追踪从相机(或观察者的眼睛)发出的光线,并计算它们与体素的交互,可以生成逼真的三维图像。
问题3:NeRF是一个神经网络,其输入和输出是什么?网络结构是什么样的?
3D空间点和2D的方向向量(θ,ϕ),表示从空间点到观察者的方向。
文中没有再重述NeRF论文中的网络结构。
问题4:文中的方法有提到对数据的预处理方式是什么吗?
没有,只提到了作目标编码(target encoding)的方法。在讨论的时候,只考虑了单一颜色值[0-255]。
问题5:既然文中所说是一个分类框架,且看文章所言是适用于已有的各个模型的修改,那么原来的模型都没有作离散化吗?
Yes,原来的各个模型都没有作直接的离散化,而是输出连续的颜色值后将其离散化。NFC框架的关键创新之处在于引入了目标编码(Target Encoding)模块,它将连续的目标值(如RGB颜色)编码为高维的离散表示。这样,原本的回归任务就被转换成了一个多标签分类任务。如将颜色值203编码为8位二进制数[1, 1, 0, 0, 1, 0, 1, 1]。然后,nn对每个二进制位进行分类,预测0或1。
问题6:输入是图片,是怎么知道光照在哪里的?
通过分析像素强度、颜色和纹理等推断出光照或相机的大致方向。
问题7:看到文中用了体素渲染,而且还讲到了光线和相机,也给出了公式,这里需要的先修的知识是什么?
光照和颜色理论:理解光线如何与物体表面相互作用,包括漫反射、镜面反射和透射等现象。
渲染方程:由James Kajiya提出的,描述如何在计算机图形学中模拟真实世界光照效果的方程。
体渲染:处理包含半透明或者完全透明物质的场景渲染,需要理解如何对体积数据进行采样和积分。
三维几何:欧拉角和变换矩阵,投影。
问题8:文章的贡献是什么?
主要贡献应该就1个,离散化。
但是文章把它掰开揉碎了,解释了三个贡献:提出了离散的学习目标,提出了转为目标的编码方式,第一个做了离散和连续的对比。
问题9:文中采用的评估指标包括了三个,如PSNR,而分类损失似乎跟它没有什么关系,那么是什么启发了要使用离散化的方法来优化PSNR呢?
文中并没有给出回答。
参考:
[1]Neural Field Classifiers via Target Encoding and Classification Loss. X Yang, Z Xie, X Zhou, B Liu, B Liu, Y Liu, H Wang, Y CAI, M Sun. https://arxiv.org/html/2403.01058v1
[2]视角合成的老方法 View interpolation for image synthesis
[3]【NeRF】动手训练新的三维场景 https://zhuanlan.zhihu.com/p/495652881
[4]新视角合成 https://zhuanlan.zhihu.com/p/486710656

 浙公网安备 33010602011771号
浙公网安备 33010602011771号