【ACL Review】消极想法的认知重建:通过人类与语言模型的交互
1.论文背景
本论文是一篇ACL 2023的论文《Cognitive Reframing of Negative Thoughts through Human-Language Model Interaction》,主要讲的是一个人类-语言模型交互的工具。
本文(这篇笔记)的组织形式是顺读文章,从头到尾捋一遍逻辑,作为一片笔记。
2.内容分析
2.1 摘要

直接翻译:克服消极想法的一种行之有效的治疗技术是用更有希望的“重构想法”取代它们。
Reframing看起来不是很好理解,翻译为“重构”。therapy是疗法。
简单来讲,文中是提出了一种方法,帮助人们修正自己的认知和想法。最后的结论是跟预想的一样,更高的同情或者积极的重构,比过度积极的想法更能让人接受。
看到这里,如果是计算机类的同学可能又要嘀咕:这又是没什么技巧的心灵鸡汤吧。确实,第一感觉,ACL确实无愧于故事会的调侃。
但是既然是一个会议,应该也要允许不同人呈现的价值。兼容并包是科研人必备的胸怀。例如本文之中到底是怎么量化一个指标的?
往下看
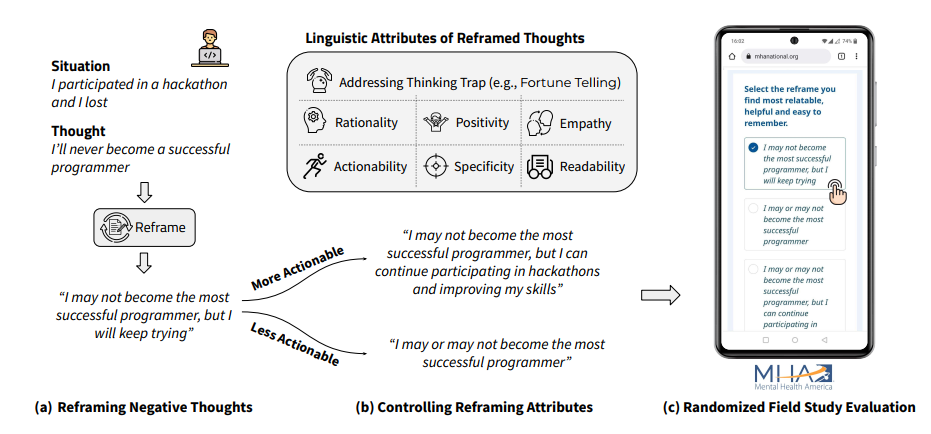
这里给了个图,比较直观,在一个场景下和人的内心活动下,把内心活动改写陈述,以使得人们有更好的认知。
为了量化这个指标,定义了六个属性/指标。重新生成新的语句,并评估它在六个属性下的效果。
Q: 这里的指标有点拍脑袋想出来的,不过本来也是比较主观的研究,所以我们看看下面是不是有在主观下的量化。
想要判定哪些因素会影响重构,语言模型是怎么帮助人们的。
2.2 问题和定义
定义了文本内容的行动力,理智,积极性,同情度,明确度,可读性六个方面。

认知陷阱。如:设想其他人的想法;极端化;最差预估;预测未来等。这个指标的含义是用了评价一个想法是否陷入了认知陷阱,陷入程度越高,显然越不好。
数据集的标记,是收集了原始语句,和reframe过的语句,打上相应的标签。它是自己构建的数据集。
Q: 事实上,自己构建数据集应该是ok的,但是在一篇文章里又做了收集数据,又加了自己做了一些标记,那重点可能就容易分散了。而且从数据集合来看,规模是相当小的。
招募的人群是通过华盛顿大学的相关机构发布公告而来的。
Q:评估的人群应该是美国的,对于不同文化背景和社会心理的其他国家,是不是有相同的分析过程和结论也需要打个问号。
数据的收集是从人群中访问并得到的,数据量级不超过1000。数据的格式是场景(Situation)和想法(Thought)。给出的输出是R(Reframe)。
2.3 度量方法
回顾一下1+6个指标:认知陷阱,理智性,积极性,同情度,行动力,明确度,可读性
1)认知陷阱:用多标签分类任务,这些数据是专家标记的,并用来微调GPT-3模型。这是一个心理学类的研究,所以心理学家的知识会派上用场。当然这里说心理学家,并没有说专家一定有多么神奇,但是在一个研究领域有过训练的
人会遵循类似的研究规范,也容易和其他人以类似的语言进行交流和沟通。
2)理智性:根据场景和陈述,多次递归地生成解释(如解释的解释),用一个论证强度的度量公式判断解释跟事实的复合程度;推理强度的公式RS没有给出具体的计算公式(在附录里)。
思路是根据给GPT类模型两种prompt,用以估计假设合理或不合理的概率。
Q: 这里RS让人看不懂,如果有进一步的解释就好了。而且注意到利用了GPT-3预测单词的方式来给出分类的概率,所以GPT-3应该是指那个开源的版本。
3)积极性:也是转成了分类任务,可以用RoBERTa分类器进行情感分析。
4)同情度:用分类器给同情心分级。
5)行动力:把它变成一个二分类问题,一类是有明确行动的,一类是没有的。利用了语言模型的prompt,给出下一个动作的候选集合,如果给出的候选集合的动作更多样化,则说明是模糊的。
6)明确度:利用embedding判断R跟S,T的相似度。
7)可读性:用已有的CLI指标评估。
Q: 这里有好几个都是利用了语言模型的能力自动生成并用embedding评估它们的相似度。可以看到这也是LLM成为热点之后经常出现的方法(生成样例+embedding)。方法是比较简单,但是也依赖于语言模型的能力,一定程度上削减了可复现性。
5.2节内容:

这一节讲了如何生成reframe的场景和想法。作者指出他们直接利用上下文学习无法达到很好的reframe生成质量,因此他们采用了基于检索的上下文学习方法。(简单来讲这个就是生成多个采用一个最好的)这个是可以理解的,其实就是生成多个取前k个并用相似度找到最匹配的结果。但是这里似乎没有说明是怎么评估reframe的生成质量的,直接用了最简单的cosine相似度,并不能很让人信服。也许这是一个约定俗成的方法,但是这里并没有给出解释。
5.3节讲的是利用控制变量法生成reframe。根据之前生成的S,T对,可以给GPT-3一些指定样例的提示,让GPT-3自己学习在某个属性上的高低的区别,然后让GPT-3根据输入R生成变化的R。
也就是说如果已经有了一个想法,我们想把它转换成一个更加消极,但是其他指标保持不变的想法;或者更加有行动力而其他指标不变,可以通过GPT-3直接生成样例R。这也是一个神奇的应用,前提是语言模型的能力
真的可以通过简单的prompt做到学习到一个简单的样例中蕴含的语义。
问题:尽管从直觉上看,GPT-3可以学到两个样例的差别,但是语言模型是否真的能根据这个差别生成合适的样例,也值得怀疑。另外,如果每个属性只有两种类别的样例,那是否意味着没有办法生成更多样的数据?
6节讲了评测指标。用了BLEU指标,但是没有说明为什么要用这个指标。它是想评估语言还是这个生成模型的功能?BLEU是语言翻译的指标,在这里使用是不是意味着作者把这个任务当作是一个翻译任务呢?也就是换句话说,文章的开头所讲是为了把描述生成为积极的想法。但是到了后面,先不说数据集正确答案的来源和可靠性,任务似乎就变成了一个翻译模型,但是又没有解释这个指标的意义。
7节标题是Randomized Field Study。在大型心理健康平台上部署了模型。
从上文可以看到,每个属性都用到了一个模型,部署到一个平台上的意思,应该是指这个平台用了他们的算法并且在线上验证了。根据文章所说,参与者样本有2000多名。
问题:这里的Randomized Field Study起名似乎有点随意了,可能让人误解为条件随机场(CRF)。从下文可以看到,这里的含义应该是指在随机样本下一些指标对评估指标的影响。
7.2节 哪种语言的属性在认知重建上的作用最好。
从图表来看,平均而言的,更理性的想法跟相关性呈正相关;更有行动力和明确性的想法跟有帮助呈现正相关,等等。
这里的疑问是,似乎跟我们的认知是一样的。但是如果以平均值作为度量,是不是意味着不同的人的差异会被抹掉?如果不想被抹掉,做多分类,那么是否可能会错误的使用一个群体的平均值去评估个人对不同指标的偏好?
8节,解释了数据集的来源,包括100个手写的场景和想法。本文的研究方法是人类-语言模型交互工具,并且作者宣称它是可扩展的。当然作者在这里并没有说明是哪方面的scalable。如果是微调语言模型以产生不同指标,那么在指标变多的情况下,是不是还能产生比较精准的生成效果,还是有疑问的。而且手工设计prompt本身可能也不是很scalable。
9节,伦理研究
主要就是介绍了进行这项研究需要的许可,以及防止生成有害内容的方式。跟一般的技术文章不太一样。
3.优点
尽管内容可能不是很硬核,但是在社会效益上还是比较有意义的。而且分析和度量的工作量也是足够的(个人感觉)。
4.关联论文
LEFT BLANK
Reference
Cognitive Reframing of Negative Thoughts through Human-Language Model Interaction. In Proceedings of the 61st ACL (Volume 1: Long Papers), pages 9977–10000, Toronto, Canada. Association for Computational Linguistics.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号