
ElasticSearch 架构及应用简介
ES介绍
ElasticSearch作为一个广泛使用的搜索引擎,能够支撑数百个节点的集群,高可用,而且检索速度非常快。由于它受到的重视,刚开始接触它的人可能对其抱有很高的期望,认为它开箱即用,但其实还是需要对其原理有一定的了解和调优技巧的。
ElasticSearch存在开源版本和收费版本,开源版本在github上可以看到,收费版本没有源码,可以在一些云服务厂商购买。一般都需要至少一个ElasticSearch集群才能支持业务的需求。
而存在的场景问题是,ES集群在业务数据量很大的情况下,需要为平衡和满足数据存储,业务高峰的写入压力瓶颈,数据删除和同步等方面的需求做出调整。
ES最简单的目的就是用于检索,当然它经常跟Kibana结合,用于数据分析,因为集成了很多功能,包括机器学习,数据分析插件,所以它在商业智能领域也有很深入的应用。
ElasticSearch的数据结构
全文查询的存储、查询用到了倒排索引;原始文本以索引分隔;
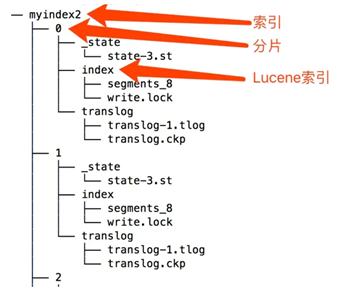
存储的文件本身是一个个sharding的分片。由于跟日期关联紧密,默认的索引名中会带有日期。
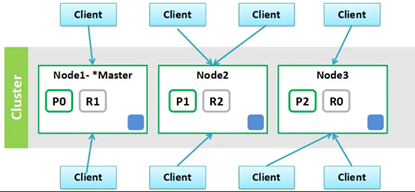
集群有节点的备份;节点内有分片;
目录结构:
ES架构图
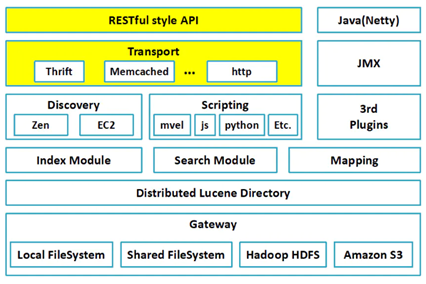
其中 Discovery是节点发现的共识机制模块,Zen已经在7.X升级成了Zen2协议。当然可以看到索引、搜索、Mapping模块构成了数据处理的核心;
ES的运行环境和语言主要是Java,所以占用资源也会较大;在腾讯云上一个ES集群基础配置是三台2核4G,500G硬盘的主机,一主二从;
大数据量下的索引设计实现
在ES中,大的数据单个Lucene索引无法保存在一个文件,超出2^31字节(2G)的会生成新文件,读取时会造成性能下降。而且大块数据丢失会造成较大的问题。
基于此,对大索引的设计建议:
- 使用模板+Rollover+Curator动态创建索引。
使用效果:
index_2019-01-01-000001
index_2019-01-02-000002
- 滚动索引
解决大块数据丢失的情况
2.1 使用 Rollover 增量管理索引
目的:按照日期、文档数、文档存储大小三个维度进行更新索引。使用举例:
curl --user elastic:xxxxxx -XPOST http://172.24.18.250:9200/logs_write/_rollover ‘{ "conditions": { "max_age": "7d", "max_docs": 1000, "max_size": "5gb" }}’
使用案例:
(1)维基百科和百度百科。
(2)The Guardian(国外新闻网站),用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析;
(3)Stack Overflow(国外的程序异常讨论论坛);
(4)GitHub(开源代码管理),搜索上千亿行代码。
(5)电商网站,检索商品。
应用场景:
(6)日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
(7)BI系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近3年的用户消费金额的趋势以及用户群体的组成构成, ES执行数据分析和挖掘,Kibana进行数据可视化国内。
(9)国内:站内搜索(电商,招聘,门户,等等),IT 的 OA系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)
分布式协议理论与现实的鸿沟
在7.X之前,ES使用的是自己写的Zen协议,为了验证它的正确性,还使用了TLA+形式化语言进行验证。
其形式化语言是tla后缀的文件,长这样:
EXTENDS Naturals, FiniteSets, Sequences, TLC CONSTANTS Lucene_addDocuments, Lucene_updateDocuments, Lucene_deleteDocuments CONSTANTS ADD, RETRY_ADD, UPDATE, DELETE CONSTANTS DocContent CONSTANTS DocAutoIdTimestamp CONSTANTS DuplicationLimit Request(request_count) == [type: {ADD}, seqno: {1}, content: DocContent, autoTimestamp: {DocAutoIdTimestamp}] \cup [type: {RETRY_ADD}, seqno: 1..request_count, content: DocContent, autoTimestamp: {DocAutoIdTimestamp}] \cup [type: {UPDATE}, seqno: 1..request_count, content: DocContent] \cup [type: {DELETE}, seqno : 1..request_count]
在7.X的版本中,它又更新了自己的一致性协议,虽然吸取了很多学术论文的知识和经验,但是本身又超越了论文本身,在定制化协议上更进一步,甚至可以说是重新发明了一套协议。
在官方文档中,对不使用Raft的原因解释道:
为什么不选择 Raft? [2]
我们经常被问到的一个问题是,为什么不简单地“插入”像 Raft 一样的标准分布式共识算法。有很多公认的算法,每种算法都有不同的利弊权衡。我们仔细评估了所有可以找到的文献,并从中汲取灵感。在我们早期的概念验证中,有一个概念便使用了非常接近 Raft 的协议。我们从这一经验中了解到,将其与 Elasticsearch 完全集成,需要做出非常巨大的改变。此外,许多标准算法还规定了一些对于 Elasticsearch 来说不是最佳选择的设计决策。例如:
标准算法通常是围绕操作日志构建的,而 Elasticsearch 的集群协调更多的是直接基于集群状态本身。相比基于操作可能达到的优化来说,集群协调可以更简单地对批处理(将相关操作合并到单个广播中)之类的操作进行重大优化。
标准算法在集群伸缩能力方面都相当受限,需要一系列步骤来完成许多维护任务,而 Elasticsearch 的集群协调可以在一个步骤中安全地执行任意的重配置。这通过避免不确定的中间状态简化了周围的系统。
标准算法通常过于关注安全性,而忽略了如何保证活动性的细节,也没有描述如果发现某个节点不健康时,集群该如何反应。Elasticsearch 的健康检测机制非常复杂,已经在该领域经过了多年的使用和优化,对于我们来说,维持其现在的运行状况十分重要。事实上,与保证系统的活动性相比,实现系统的安全性所需付出的成本要少得多。大多数的实现工作都集中在系统的活动性上。
项目的目标之一是,支持从运行 Zen Discovery 的 6.7 集群零中断滚动升级到运行新协调子系统的版本 7 集群。将任何标准算法调整为允许这种滚动升级的算法似乎都不可行。
基于ElasticSearch的管理平台
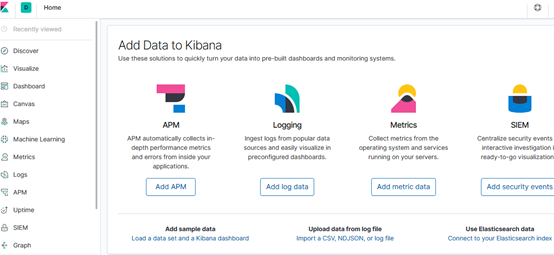
Kibana的网页界面如下,可以在这里进行数据的索引管理,数据分析,可视化
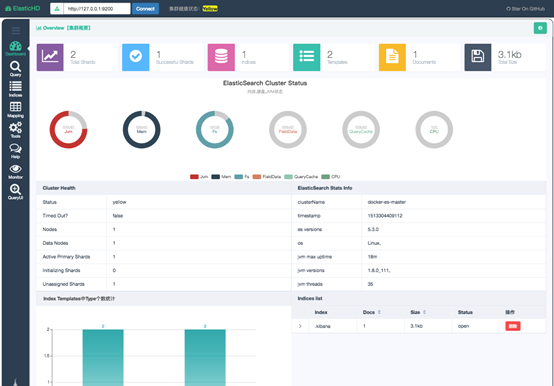
也有其他开源项目:https://github.com/360EntSecGroup-Skylar/ElasticHD
支持自动根据SQL语句生成查询索引模板
References
[1] https://cloud.tencent.com/developer/article/1122524 如何优雅的全量读取Elasticsearch索引里面的数据
[2] https://www.jianshu.com/p/b1724c49d7c9 Elasticsearch(ES)集群架构
[3] https://juejin.im/post/5e675070e51d4526d43f44ae Elasticsearch 索引设计实战指南
[4] https://www.elastic.co/blog/a-new-era-for-cluster-coordination-in-elasticsearch Elasticsearch 集群协调迎来新时代
[5] https://github.com/360EntSecGroup-Skylar/ElasticHD ElasticHD

 浙公网安备 33010602011771号
浙公网安备 33010602011771号