python正则表达式
正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
作用
1.检测某个字符串是否符合规则.比如:判断手机号,身份证号是否合法
2.提取网页字符串中想要的数据.比如:爬虫中,提取网站天气,信息,股票代码,星座运势等具体关键字
在线测试工具
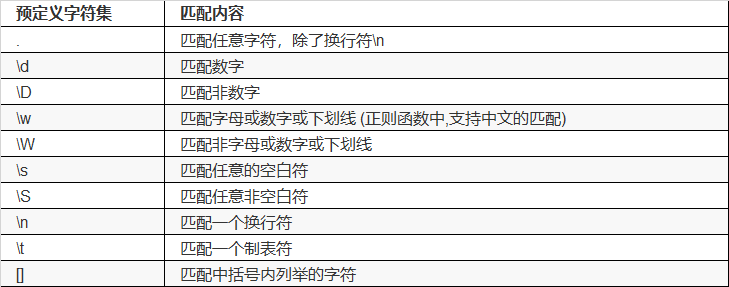
正则表达式包含的元素种类
正则表达式由一些 [普通字符] 和一些 [元字符] 组成:
(1)普通字符包括大小写字母和数字
(2)元字符具有特殊含义,大体种类分为如下:
1.预定义字符集,字符组
2.量词
3.边界符
4.分组

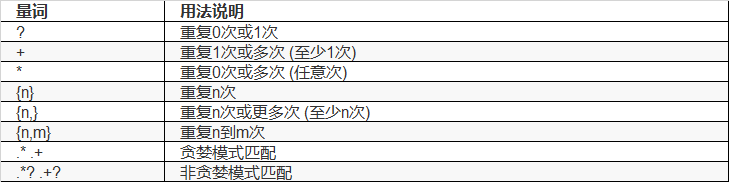
贪婪匹配: 默认向更多次数匹配 (底层用的是回溯算法)
非贪婪匹配: 默认向更少次数匹配 (量词的后面加?号)
(1)量词( * ? + {} )加上问号?表示非贪婪 惰性匹配
(2)例:.*?w 表示匹配任意长度任意字符遇到一个w就立即停止

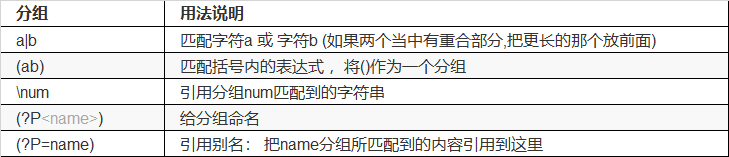
分组
1.正常分组 ()
1) 正常情况下用()圆括号进行分组 可以用\1 反向引用第一个圆括号匹配的内容。
2) (?:正则表达式) 表示取消优先显示的功能
2.命名分组
3) (?P<组名>正则表达式) 给这个组起一个名字
4) (?P=组名) 引用之前组的名字,把该组名匹配到的内容放到当前位置

findall 匹配字符串中相应内容,返回列表 [用法: findall("正则表达式","要匹配的字符串")]
search 通过正则匹配出第一个对象返回,通过group取出对象中的值
match 验证用户输入内容
split 切割
sub 替换
subn 替换
finditer 匹配字符串中相应内容,返回迭代器
compile 指定一个统一的匹配规则
练习
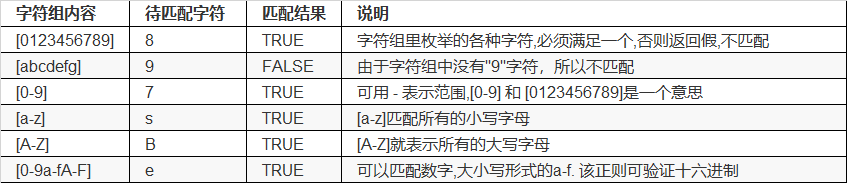
字符组练习
>>> import re >>> print(re.findall('a[abc]b','aab abb acb adb')) ['aab', 'abb', 'acb'] >>> print(re.findall('a[0123456789]b','a1b a2b a3b acb ayb')) ['a1b', 'a2b', 'a3b'] >>> print(re.findall('a[abcdefg]b','a1b a2b a3b acb ayb adb')) ['acb', 'adb'] >>> print(re.findall('a[ABCDEFG]b','a1b a2b a3b aAb aDb aYb')) ['aAb', 'aDb'] >>> print(re.findall('a[0-9a-zA-Z]b','a-b aab aAb aWb aqba1b')) ['aab', 'aAb', 'aWb', 'aqb', 'a1b'] >>> print(re.findall('a[0-9][#/]b','a1/b a2b a29b a56b a456b')) ['a1/b'] >>> print(re.findall('a[^-+/]b','a%b ccaabda&bd')) ['a%b', 'aab', 'a&b']
量词练习
1) ? 匹配0个或者一个
>>> print(re.findall('a?b','abbzab abb aab')) ['ab', 'b', 'ab', 'ab', 'b', 'ab']
2) + 匹配一个或者多个
>>> print(re.findall('a+b','b ab aaaaaab abb')) ['ab', 'aaaaaab', 'ab']
3) * 匹配0个或者多个
>>> print(re.findall('a*b','b ab aaaaaab abbbbbbb')) ['b', 'ab', 'aaaaaab', 'ab', 'b', 'b', 'b', 'b', 'b', 'b']
4) {m,n} 匹配m个至n个
>>> print(re.findall('a{1,3}b','aaab ab aab abbb aaz aabb')) ['aaab', 'ab', 'aab', 'ab', 'aab']
贪婪匹配
>>> print(re.findall('a.*b','aab ab aaaaab a!!!@#$bz')) ['aab ab aaaaab a!!!@#$b']
非贪婪匹配
>>> print(re.findall('a.*?b','aab ab aaaaab a!!!@#$bz')) ['aab', 'ab', 'aaaaab', 'a!!!@#$b']
边界符练习
>>> strvar = "abacad" >>> print(re.findall('a.',strvar)) ['ab', 'ac', 'ad'] >>> print(re.findall('^a.',strvar)) ['ab'] >>> print(re.findall('a.$',strvar)) ['ad'] >>> print(re.findall('^a.$',strvar)) [] >>> print(re.findall('^a.*?$',strvar)) ['abacad'] >>> print(re.findall('^a.*?a$',strvar)) [] >>> print(re.findall('^a.*?d$',strvar)) ['abacad']
>>> print(re.findall('^g.*? ','giveme 1gfive gay')) ['giveme '] >>> print(re.findall('five$','aassfive')) ['five'] >>> print(re.findall('^giveme$','giveme')) ['giveme'] >>> print(re.findall('^giveme$','giveme giveme')) [] >>> print(re.findall('giveme','giveme giveme')) ['giveme', 'giveme'] >>> print(re.findall('^g.*e','gimeme 1gfive gay')) ['gimeme 1gfive']
分组练习(括号)
>>> print(re.findall('.*?_z','a_z b_z c_z')) ['a_z', ' b_z', ' c_z'] >>> print(re.findall('(.*?)_z','a_z b_z c_z')) ['a', ' b', ' c'] >>> print(re.findall('(?:.*?)_z','a_z b_z c_z')) ['a_z', ' b_z', ' c_z']
| 代表或 , a|b 匹配字符a 或者 匹配字符b . 把字符串长的写在前面,字符串短的写在后面
1. 整数或者小数:^[0-9]+([.][0-9]+){0,1}$
search函数
search函数只匹配到一个就返回,返回的是对象,可以让分组的内容和正常匹配的结果同时显示
group获取对象获取到的值
>>> obj = re.search('171[0-9]{8}|135\d{8}','17188886666 13566668888') >>> obj <_sre.SRE_Match object; span=(0, 11), match='17188886666'> >>> res = obj.group() >>> res '17188886666'
groups显示分组里所有内容
>>> obj = re.search('(www)\.(baidu|google)\.(com)','www.baidu.com wwww.google.com') >>> obj <_sre.SRE_Match object; span=(0, 13), match='www.baidu.com'> >>> print(obj.group()) www.baidu.com >>> print(obj.groups()) ('www', 'baidu', 'com')

