ES系列十六、集群配置和维护管理
一、修改配置文件
1.节点配置
1.vim elasticsearch.yml
# ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticsearch comes with reasonable defaults for most settings. # Before you set out to tweak and tune the configuration, make sure you # understand what are you trying to accomplish and the consequences. # # The primary way of configuring a node is via this file. This template lists # the most important settings you may want to configure for a production cluster. # # Please consult the documentation for further information on configuration options: # https://www.elastic.co/guide/en/elasticsearch/reference/index.html # # ---------------------------------- Cluster ----------------------------------- # # Use a descriptive name for your cluster: # 集群名称 cluster.name: es-test # # ------------------------------------ Node ------------------------------------ # # Use a descriptive name for the node: # 节点名称 node.name: node-1 # # Add custom attributes to the node: # node.attr.rack: r1 # # ----------------------------------- Paths ------------------------------------ # # Path to directory where to store the data (separate multiple locations by comma): # path.data: /home/esdata/data # # Path to log files: # path.logs: /home/esdata/log # # ----------------------------------- Memory ----------------------------------- # # Lock the memory on startup: # bootstrap.memory_lock: false bootstrap.system_call_filter: false # # Make sure that the heap size is set to about half the memory available # on the system and that the owner of the process is allowed to use this # limit. # # Elasticsearch performs poorly when the system is swapping the memory. # # ---------------------------------- Network ----------------------------------- # # Set the bind address to a specific IP (IPv4 or IPv6): # network.host: 0.0.0.0 # # Set a custom port for HTTP: # http.port: 9200 # # For more information, consult the network module documentation. # # --------------------------------- Discovery ---------------------------------- # # Pass an initial list of hosts to perform discovery when new node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] # 节点主机 discovery.zen.ping.unicast.hosts: ["192.168.1.102","192.168.1.103","192.168.1.104"] # # Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1): # 主节点数量 discovery.zen.minimum_master_nodes: 1 # # For more information, consult the zen discovery module documentation. # # ---------------------------------- Gateway ----------------------------------- # # Block initial recovery after a full cluster restart until N nodes are started: # 节点发现多少开始恢复 gateway.recover_after_nodes: 3 # # For more information, consult the gateway module documentation. # # ---------------------------------- Various ----------------------------------- # # Require explicit names when deleting indices: # action.destructive_requires_name: true http.cors.enabled: true http.cors.allow-origin: "*"
其他节点文件除了节点名称不一样,其他都一样。
2.验证
1.启动三台机器ES和head
2.访问head地址查看
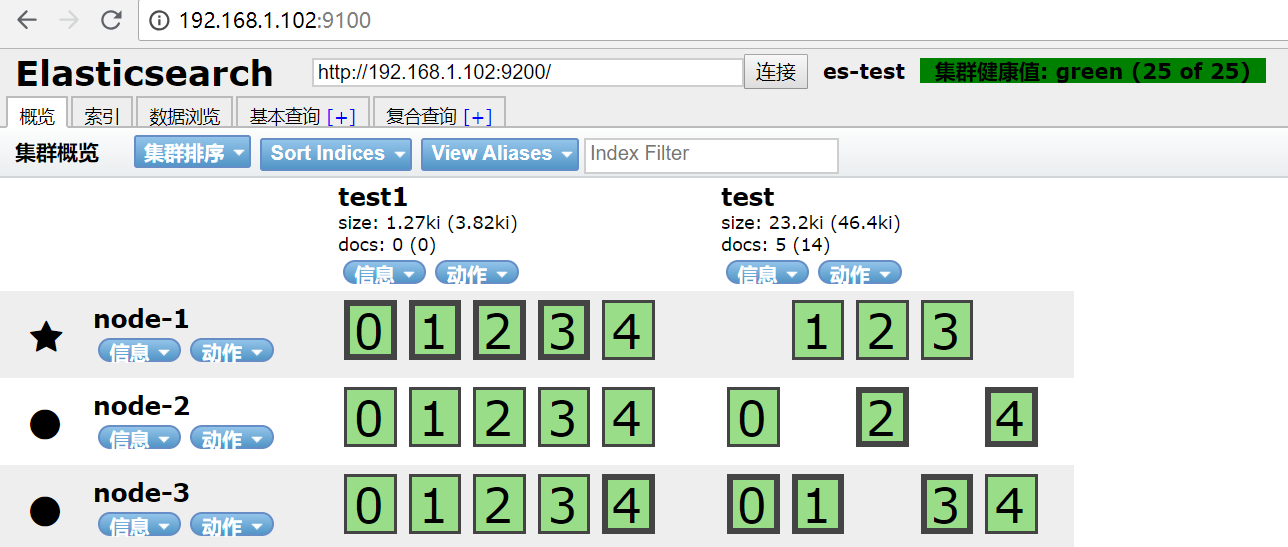
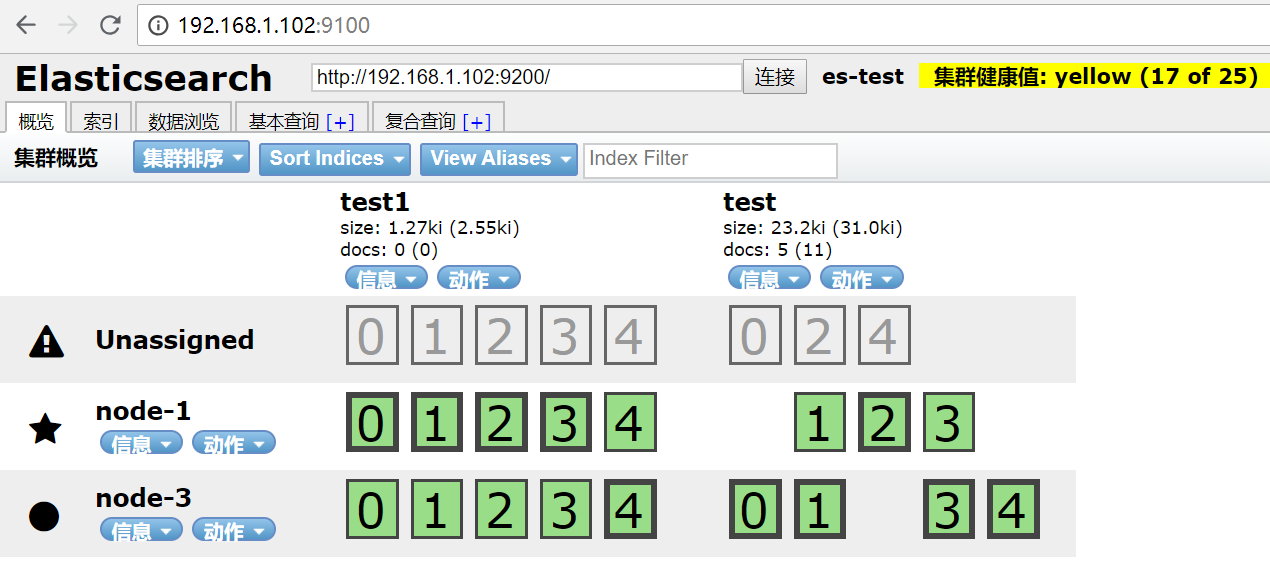
集群一共两个三个节点,test有5分片,每个分片两个副本,停掉节点二,集群副本0,2,4不见了
二、集群规划
搭建一个集群我们需要考虑如下几个问题:
1. 我们需要多大规模的集群?
2. 集群中的节点角色如何分配?
3. 如何避免脑裂问题?
4. 索引应该设置多少个分片?
5. 分片应该设置几个副本?
下面我们就来分析和回答这几个问题
1、我们需要多大规模的集群?
需要从以下两个方面考虑:
1.1 当前的数据量有多大?数据增长情况如何?
1.2 你的机器配置如何?cpu、多大内存、多大硬盘容量?
推算的依据:
ES JVM heap 最大可以设置32G 。
30G heap 大概能处理的数据量 10 T。如果内存很大如128G,可在一台机器上运行多个ES节点实例。
备注:集群规划满足当前数据规模+适量增长规模即可,后续可按需扩展。
两类应用场景:
A. 用于构建业务搜索功能模块,且多是垂直领域的搜索。数据量级几千万到数十亿级别。一般2-4台机器的规模。
B. 用于大规模数据的实时OLAP(联机处理分析),经典的如ELK Stack,数据规模可能达到千亿或更多。几十到上百节点的规模。
2、集群中的节点角色如何分配?
2.1 节点角色:
Master
node.master: true 节点可以作为主节点
DataNode
node.data: true 默认是数据节点。
Coordinate node 协调节点
如果仅担任协调节点,将上两个配置设为false。
说明:
一个节点可以充当一个或多个角色,默认三个角色都有
协调节点:一个节点只作为接收请求、转发请求到其他节点、汇总各个节点返回数据等功能的节点。就叫协调节点
2.2 如何分配:
A. 小规模集群,不需严格区分。
B. 中大规模集群(十个以上节点),应考虑单独的角色充当。特别并发查询量大,查询的合并量大,可以增加独立的协调节点。角色分开的好处是分工分开,不互影响。如不会因协调角色负载过高而影响数据节点的能力。
3、如何避免脑裂问题?
3.1 脑裂问题:
一个集群中只有一个A主节点,A主节点因为需要处理的东西太多或者网络过于繁忙,从而导致其他从节点ping不通A主节点,这样其他从节点就会认为A主节点不可用了,就会重新选出一个新的主节点B。过了一会A主节点恢复正常了,这样就出现了两个主节点,导致一部分数据来源于A主节点,另外一部分数据来源于B主节点,出现数据不一致问题,这就是脑裂。
3.2 尽量避免脑裂,需要添加最小数量的主节点配置:
discovery.zen.minimum_master_nodes: (有master资格节点数/2) + 1
这个参数控制的是,选举主节点时需要看到最少多少个具有master资格的活节点,才能进行选举。官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。
3.3 常用做法(中大规模集群):
1. Master 和 dataNode 角色分开,配置奇数个master,如3
2. 单播发现机制,配置master资格节点:
discovery.zen.ping.multicast.enabled: false —— 关闭多播发现机制,默认是关闭的
discovery.zen.ping.unicast.hosts: ["master1", "master2", "master3"] —— 配置单播发现的主节点ip地址,其他从节点要加入进来,就得去询问单播发现机制里面配置的主节点我要加入到集群里面了,主节点同意以后才能加入,然后主节点再通知集群中的其他节点有新节点加入
3. 配置选举发现数,及延长ping master的等待时长
discovery.zen.ping_timeout: 30(默认值是3秒)——其他节点ping主节点多久时间没有响应就认为主节点不可用了
discovery.zen.minimum_master_nodes: 2 —— 选举主节点时需要看到最少多少个具有master资格的活节点,才能进行选举
4、索引应该设置多少个分片?
说明:分片数指定后不可变,除非重索引。
思考:
分片对应的存储实体是什么?
存储的实体是索引
分片是不是越多越好?
不是
分片多有什么影响?
分片多浪费存储空间、占用资源、影响性能
4.1 分片过多的影响:
每个分片本质上就是一个Lucene索引, 因此会消耗相应的文件句柄, 内存和CPU资源。
每个搜索请求会调度到索引的每个分片中. 如果分片分散在不同的节点倒是问题不太. 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降。
ES使用词频统计来计算相关性. 当然这些统计也会分配到各个分片上. 如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差。
4.2 分片设置的可参考原则:
ElasticSearch推荐的最大JVM堆空间是30~32G, 所以把你的分片最大容量限制为30GB, 然后再对分片数量做合理估算. 例如, 你认为你的数据能达到200GB, 推荐你最多分配7到8个分片。
在开始阶段, 一个好的方案是根据你的节点数量按照1.5~3倍的原则来创建分片. 例如,如果你有3个节点, 则推荐你创建的分片数最多不超过9(3x3)个。当性能下降时,增加节点,ES会平衡分片的放置。
对于基于日期的索引需求, 并且对索引数据的搜索场景非常少. 也许这些索引量将达到成百上千, 但每个索引的数据量只有1GB甚至更小. 对于这种类似场景, 建议只需要为索引分配1个分片。如日志管理就是一个日期的索引需求,日期索引会很多,但每个索引存放的日志数据量就很少。
5、分片应该设置几个副本?
说明:副本数是可以随时调整的!
思考:
副本的用途是什么?
备份数据保证高可用数据不丢失,高并发的时候参与数据查询
针对它的用途,我们该如何设置它的副本数?
一般一个分片有1-2个副本即可保证高可用
集群规模没变的情况下副本过多会有什么影响?
副本多浪费存储空间、占用资源、影响性能
5.1 副本设置基本原则:
为保证高可用,副本数设置为2即可。要求集群至少要有3个节点,来分开存放主分片、副本。
如发现并发量大时,查询性能会下降,可增加副本数,来提升并发查询能力。
注意:新增副本时主节点会自动协调,然后拷贝数据到新增的副本节点
三、集群管理
1. 监控API
http://localhost:9200/_cat
2. x-pack
为集群提供安全防护、监控、告警、报告等功能的收费组件;
部分免费:https://www.elastic.co/subscriptions
6.3开始已开源,并并入了elasticsearch核心中。
官网安装介绍:
https://www.elastic.co/guide/en/elasticsearch/reference/6.2/installing-xpack-es.html
ES安装参考:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号