mysql系列九、mysql语句执行过程及运行原理(分组查询和关联查询原理)
一、背景介绍
了解一个sql语句的执行过程,了解一部分都做了什么,更有利于对sql进行优化,因为你知道它的每一个连接、where、分组、子查询是怎么运行的,都干了什么,才会知道怎么写是不合理的。
大致执行顺序:
select[distinct]
from
join(如:left join)
on
where
group by
having
union
order by
limit
二、数据表准备
1、创建表
DROP TABLE IF EXISTS student; CREATE TABLE `student` ( `id` int(5) NOT NULL AUTO_INCREMENT, `name` varchar(10) DEFAULT NULL, `subject` varchar(10) DEFAULT NULL, `grade` double(4,1) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=40 DEFAULT CHARSET=utf8;
2、初始化数据
INSERT INTO student(`name`,`subject`,grade)VALUES('aom','语文',88); INSERT INTO student(`name`,`subject`,grade)VALUES('aom','数学',99); INSERT INTO student(`name`,`subject`,grade)VALUES('aom','外语',55); INSERT INTO student(`name`,`subject`,grade)VALUES('jack','语文',67); INSERT INTO student(`name`,`subject`,grade)VALUES('jack','数学',44); INSERT INTO student(`name`,`subject`,grade)VALUES('jack','外语',55); INSERT INTO student(`name`,`subject`,grade)VALUES('susan','语文',56); INSERT INTO student(`name`,`subject`,grade)VALUES('susan','数学',35); INSERT INTO student(`name`,`subject`,grade)VALUES('susan','外语',77); INSERT INTO student(`name`,`subject`,grade)VALUES('alice','语文',88); INSERT INTO student(`name`,`subject`,grade)VALUES('alice','数学',77); INSERT INTO student(`name`,`subject`,grade)VALUES('alice','外语',100); INSERT INTO student(`name`,`subject`,grade)VALUES('rajo','语文',33); INSERT INTO student(`name`,`subject`,grade)VALUES('rajo','数学',55); INSERT INTO student(`name`,`subject`,grade)VALUES('rajo','外语',55);
三、sql分组查询执行顺序分析
下面我们来看一下,数据在数据库中的存储形式。

(图1.0)
现在针对这张student表中的数据提出一个问题:要求查询出挂科数目多于两门(包含两门)的前两名学生的姓名,如果挂科数目相同按学生姓名升序排列。
下面是这条查询的sql语
SELECT `name`,COUNT(`name`) AS num FROM student WHERE grade < 60 GROUP BY `name` HAVING num >= 2 ORDER BY num DESC,`name` ASC
LIMIT 0,2;
执行结果:
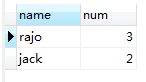
图(1.1)
以上这条sql语句基本上概括了单表查询中所有要注意的点,那么我们就以这条sql为例来分析一下一条语句的执行流程。
1、from:读取数据到内存
一条查询的sql语句先执行的是 FROM student 负责把数据库的表文件加载到内存中去,如图1.0中所示。(mysql数据库在计算机上也是一个进程,cpu会给该进程分配一块内存空间,在计算机‘服务’中可以看到,该进程的状态)

图(1.2)
2、WHERE:过滤、生成一张临时表
WHERE grade < 60,会把(图1.0)所示表中的数据进行过滤,取出符合条件的记录行,生成一张临时表,如下图所示。

图(1.3)
3、GROUP :分成若干临时表
GROUP BY `name`会把图(1.3)的临时表切分成若干临时表,我们用下图来表示内存中这个切分的过程。

图(1.4)
4、SELECT
SELECT 的执行读取规则分为sql语句中有无GROUP BY两种情况:
- 当没有GROUP BY时,SELECT 会根据后面的字段名称对内存中的一张临时表整列读取。
- 当查询sql中有GROUP BY时,会对内存中的若干临时表分别执行SELECT,而且只取各临时表中的第一条记录,然后再形成新的临时表。这就决定了查询sql使用GROUP BY的场景下,SELECT后面跟的一般是参与分组的字段和聚合函数,否则查询出的数据要是情况而定。另外聚合函数中的字段可以是表中的任意字段,需要注意的是聚合函数会自动忽略空值。
我们还是以本例中的查询sql来分析,现在内存中有四张被GROUP BY `name`切分成的临时表,我们分别取名为 tempTable1,tempTable2,tempTable3,tempTable4分别对应图(1.4)下面写四条"伪SQL"来说明这个查询过程。
SELECT `name`,COUNT(`name`) AS num FROM tempTable1; SELECT `name`,COUNT(`name`) AS num FROM tempTable2; SELECT `name`,COUNT(`name`) AS num FROM tempTable3; SELECT `name`,COUNT(`name`) AS num FROM tempTable4;
最后再次成新的临时表,如下图:

5、HAVING
HAVING num >= 2对上图所示临时表中的数据再次过滤,与WHERE语句不同的是HAVING 用在GROUP BY之后,WHERE是对FROM student从数据库表文件加载到内存中的原生数据过滤,而HAVING 是对SELECT 语句执行之后的临时表中的数据过滤,所以说column AS otherName ,otherName这样的字段在WHERE后不能使用,但在HAVING 后可以使用。但HAVING的后使用的字段只能是SELECT 后的字段,SELECT后没有的字段HAVING之后不能使用。HAVING num >= 2语句执行之后生成一张临时表,如下:
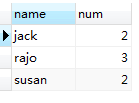
6、ORDER
ORDER BY num DESC,`name` ASC对以上的临时表按照num,name进行排序。
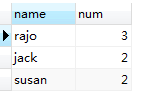
7、Limit
LIMIT 0,2取排序后的前两个。
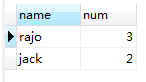
以上就是一条sql的执行过程,同时我们在书写查询sql的时候应当遵守以下顺序。
SELECT XXX FROM XXX WHERE XXX GROUP BY XXX HAVING XXX ORDER BY XXX LIMIT XXX;
四、sql关联查询执行顺序分析
1、sql执行顺序
(1)from (3) join (2) on (4) where (5)group by(开始使用select中的别名,后面的语句中都可以使用) (6) avg,sum.... (7)having (8) select (9) distinct (10) order by
从这个顺序中我们不难发现,所有的 查询语句都是从from开始执行的,在执行过程中,每个步骤都会为下一个步骤生成一个虚拟表,这个虚拟表将作为下一个执行步骤的输入。
第一步:首先对from子句中的前两个表执行一个笛卡尔乘积,此时生成虚拟表 vt1(选择相对小的表做基础表)
第二步:接下来便是应用on筛选器,on 中的逻辑表达式将应用到 vt1 中的各个行,筛选出满足on逻辑表达式的行,生成虚拟表 vt2
第三步:如果是outer join 那么这一步就将添加外部行,left outer jion 就把左表在第二步中过滤的添加进来,如果是right outer join 那么就将右表在第二步中过滤掉的行添加进来,这样生成虚拟表 vt3
第四步:如果 from 子句中的表数目多余两个表,那么就将vt3和第三个表连接从而计算笛卡尔乘积,生成虚拟表,该过程就是一个重复1-3的步骤,最终得到一个新的虚拟表 vt3。
第五步:应用where筛选器,对上一步生产的虚拟表引用where筛选器,生成虚拟表vt4,在这有个比较重要的细节不得不说一下,对于包含outer join子句的查询,就有一个让人感到困惑的问题,到底在on筛选器还是用where筛选器指定逻辑表达式呢?on和where的最大区别在于,如果在on应用逻辑表达式那么在第三步outer join中还可以把移除的行再次添加回来,而where的移除的最终的。举个简单的例子,有一个学生表(班级,姓名)和一个成绩表(姓名,成绩),我现在需要返回一个x班级的全体同学的成绩,但是这个班级有几个学生缺考,也就是说在成绩表中没有记录。为了得到我们预期的结果我们就需要在on子句指定学生和成绩表的关系(学生.姓名=成绩.姓名)那么我们是否发现在执行第二步的时候,对于没有参加考试的学生记录就不会出现在vt2中,因为他们被on的逻辑表达式过滤掉了,但是我们用left outer join就可以把左表(学生)中没有参加考试的学生找回来,因为我们想返回的是x班级的所有学生,如果在on中应用学生.班级='x'的话,left outer join会把x班级的所有学生记录找回(感谢网友康钦谋__康钦苗的指正),所以只能在where筛选器中应用学生.班级='x' 因为它的过滤是最终的。
第六步:group by 子句将中的唯一的值组合成为一组,得到虚拟表vt5。如果应用了group by,那么后面的所有步骤都只能得到的vt5的列或者是聚合函数(count、sum、avg等)。原因在于最终的结果集中只为每个组包含一行。这一点请牢记。
第七步:应用cube或者rollup选项,为vt5生成超组,生成vt6.
第八步:应用having筛选器,生成vt7。having筛选器是第一个也是为唯一一个应用到已分组数据的筛选器。
第九步:处理select子句。将vt7中的在select中出现的列筛选出来。生成vt8.
第十步:应用distinct子句,vt8中移除相同的行,生成vt9。事实上如果应用了group by子句那么distinct是多余的,原因同样在于,分组的时候是将列中唯一的值分成一组,同时只为每一组返回一行记录,那么所以的记录都将是不相同的。
第十一步:应用order by子句。按照order_by_condition排序vt9,此时返回的一个游标,而不是虚拟表。sql是基于集合的理论的,集合不会预先对他的行排序,它只是成员的逻辑集合,成员的顺序是无关紧要的。对表进行排序的查询可以返回一个对象,这个对象包含特定的物理顺序的逻辑组织。这个对象就叫游标。正因为返回值是游标,那么使用order by 子句查询不能应用于表表达式。排序是很需要成本的,除非你必须要排序,否则最好不要指定order by,最后,在这一步中是第一个也是唯一一个可以使用select列表中别名的步骤。
第十二步:应用top选项。此时才返回结果给请求者即用户。
2、mysql的执行顺序
SELECT语句定义
一个完成的SELECT语句包含可选的几个子句。SELECT语句的定义如下:
SQL代码
<SELECT clause> [<FROM clause>] [<WHERE clause>] [<GROUP BY clause>] [<HAVING clause>] [<ORDER BY clause>] [<LIMIT clause>]
SELECT子句是必选的,其它子句如WHERE子句、GROUP BY子句等是可选的。
一个SELECT语句中,子句的顺序是固定的。例如GROUP BY子句不会位于WHERE子句的前面。
SELECT语句执行顺序
SELECT语句中子句的执行顺序与SELECT语句中子句的输入顺序是不一样的,所以并不是从SELECT子句开始执行的,而是按照下面的顺序执行:
开始->FROM子句->WHERE子句->GROUP BY子句->HAVING子句->ORDER BY子句->SELECT子句->LIMIT子句->最终结果
每个子句执行后都会产生一个中间结果,供接下来的子句使用,如果不存在某个子句,就跳过 。
3、MySQL如何执行关联查询
MySQL认为任何一个查询都是一次“关联”,并不仅仅是一个查询需要到两个表匹配才叫关联,所以在MySQL中,每一个查询,每一个片段(包括子查询,甚至基于单表查询)都可以是一次关联。当前MySQL关联执行的策略很简单:MySQL对任何关联都执行嵌套循环关联操作,即MySQL先在一个表中循环取出单条数据,然后在嵌套循环到下一个表中寻找匹配的行,依次下去,直到找到所有表中匹配的行为止。然后根据各个表匹配的行,返回查询中需要的各个列。请看下面的例子中的简单的查询:
select tbl1.col1, tbl2.col2 from tbl1 inner join tbl2 using(col3) where tbl1.col1 in (5, 6);
假设MySQL按照查询中的表顺序进行关联操作,我们则可以用下面的伪代码表示MySQL将如何完成这个查询:
outer_iter = iterator over tbl1 where col1 in (5, 6) outer_row = outer_iter.next while outer_row inner_iter = iterator over tbl2 where col3 = outer_row.col3 inner_row = inner_iter.next while inner_row output [ outer_row.col1, inner_row.col2] inner_row = inner_iter.next end outer_row = outer_iter.next end
上面的执行计划对于单表查询和多表关联查询都适用,如果是一个单表查询,那么只需要上面外层的基本操作。对于外连接,上面的执行过程仍然适用。例如,我们将上面的查询语句修改如下:
select tbl1.col1, tbl2.col2 from tbl1 left outer join tbl2 using(col3) where tbl1.col1 in (5, 6);
那么,对应的伪代码如下:
outer_iter = iterator over tbl1 where col1 in (5, 6) outer_row = outer_iter.next while outer_row inner_iter = iterator over tbl2 where col3 = outer_row.col3 inner_row = inner_iter.next if inner_row while inner_row output [ outer_row.col1, inner_row.col2] inner_row = inner_iter.next end else output [ outer_row.col1, null] end outer_row = outer_iter.next end


 浙公网安备 33010602011771号
浙公网安备 33010602011771号