java多线程系列五、并发容器
一、ConcurrentHashMap
1、为什么要使用ConcurrentHashMap
在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,HashMap在并发执行put操作时会引起死循环,是因为多线程会导致HashMap的Entry链表
形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获取Entry。
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞或轮询状态。如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低。
2、ConcurrentHashMap的一些有用的方法
很多时候我们希望在元素不存在时插入元素,我们一般会像下面那样写代码
synchronized(map){ if (map.get(key) == null){ return map.put(key, value); } else{ return map.get(key); } }
putIfAbsent(key,value)方法原子性的实现了同样的功能
V putIfAbsent(K key, V value)
如果key对应的value不存在,则put进去,返回null。否则不put,返回已存在的value。
boolean remove(Object key, Object value)
如果key对应的值是value,则移除K-V,返回true。否则不移除,返回false。
boolean replace(K key, V oldValue, V newValue)
如果key对应的当前值是oldValue,则替换为newValue,返回true。否则不替换,返回false。
3、Hash的解释
散列,任意长度的输入,通过一种算法,变换成固定长度的输出。属于压缩的映射。
hash算法示例图演示:
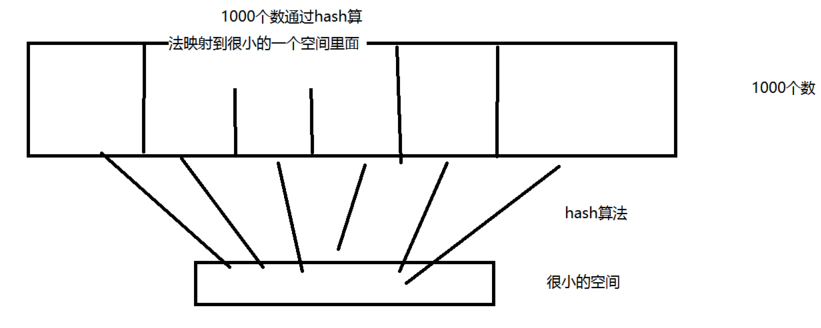
类似于HaspMap的实现就是使用散列,比如把1000个元素放到长度为10的hashmap里面去,放入之前会把这1000个数经过hash算法映射到10个数组里面去,这时候就会存在相同的映射值在一个数组的相同位置,就会产生hash碰撞,此时hashmap就会在产生碰撞的数组的后面使用Entry链表来存储相同映射的值,然后使用equals方法来判断同一个链表存储的值是否一样来获取值,链表就是hashmap用来解决碰撞的方法,所以我们一般在写一个类的时候要写自己的hashcode方法和equals方法,如果键的hashcode相同,再使用键的equals方法判断键内容是不是一样的,一样的就获取值
Md5,Sha,取余都是散列算法,ConcurrentHashMap中是wang/jenkins算法
4、ConcurrentHashMap在1.7下的实现
分段锁的设计思想。
分段锁的思想示例图:
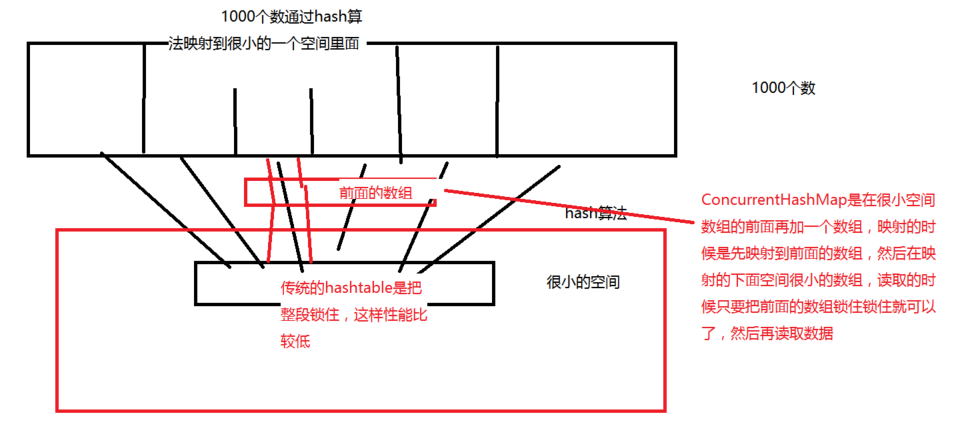
说明:
a)传统的hashtable是很小空间的数组整段锁住,这样性能比较低
b)ConcurrentHashMap是在很小空间数组的前面再加一个数组,映射的时候先映射到前面的数组,然后再映射到后面的很小空间的数组;读取的时候只需要把前面的数组锁住就可以了。这就是分段锁的思想
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment实际是一种可重入锁(ReentrantLock),也就是用于分段的锁。HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组。Segment的结构和HashMap类似,是一种数组和链表结构。一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得与它对应的Segment锁。
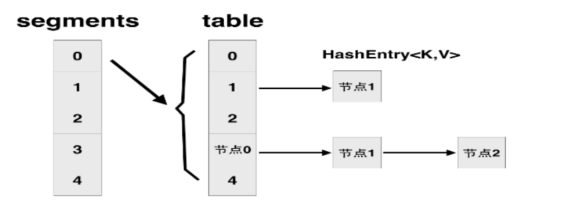
说明:上图存在两次散列的过程:比如插入一个1000的数,首先是把1000的位数(最多是高16位)做一次散列找到在segments数组中的位置,然后再把1000本身做一次散列找到在table中的位置
获取值时一样
ConcurrentHashMap初始化方法是通过initialCapacity、loadFactor和concurrencyLevel(参数concurrencyLevel是用户估计的并发级别,就是说你觉得最多有多少线程共同修改这个map,根据这个来确定Segment数组的大小concurrencyLevel默认是DEFAULT_CONCURRENCY_LEVEL = 16;)。
ConcurrentHashMap完全允许多个读操作并发进行,读操作并不需要加锁。ConcurrentHashMap实现技术是保证HashEntry几乎是不可变的。HashEntry代表每个hash链中的一个节点,可以看到其中的对象属性要么是final的,要么是volatile的。
总结:ConcurrentHashMap在1.7及以下的实现使用数组+链表的方式,采用了分段锁的思想
5、ConcurrentHashMap在1.8下的实现
改进一:取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
改进二:将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
总结:ConcurrentHashMap在1.8下的实现使用数组+链表+红黑树的方式,当链表个数超过8的时候就把原来的链表转成红黑树,使用红黑树来存取,采用了元素锁的思想
二、ConcurrentSkipListMap 和ConcurrentSkipListSet
ConcurrentSkipListMap TreeMap的并发实现
ConcurrentSkipListSet TreeSet的并发实现
1、了解什么是SkipList
二分查找和AVL树查找
二分查找要求元素可以随机访问,所以决定了需要把元素存储在连续内存。这样查找确实很快,但是插入和删除元素的时候,为了保证元素的有序性,就需要大量的移动元素了。
如果需要的是一个能够进行二分查找,又能快速添加和删除元素的数据结构,首先就是二叉查找树,二叉查找树在最坏情况下可能变成一个链表。
于是,就出现了平衡二叉树,根据平衡算法的不同有AVL树,B-Tree,B+Tree,红黑树等,但是AVL树实现起来比较复杂,平衡操作较难理解,这时候就可以用SkipList跳跃表结构。
传统意义的单链表是一个线性结构,向有序的链表中插入一个节点需要O(n)的时间,查找操作需要O(n)的时间。

如果我们使用上图所示的跳跃表,就可以减少查找所需时间为O(n/2),因为我们可以先通过每个节点的最上面的指针先进行查找,这样子就能跳过一半的节点。
比如我们想查找19,首先和6比较,大于6之后,在和9进行比较,然后在和12进行比较......最后比较到21的时候,发现21大于19,说明查找的点在17和21之间,从这个过程中,我们可以看出,查找的时候跳过了3、7、12等点,因此查找的复杂度为O(n/2)。
跳跃表其实也是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针,从而提升查找的效率。
跳跃表又被称为概率,或者说是随机化的数据结构,目前开源软件 Redis 和 lucence都有用到它。
三、 ConcurrentLinkedQueue 无界非阻塞队列
ConcurrentLinkedQueue LinkedList 并发版本
Add,offer:添加元素
Peek():get头元素并不把元素拿走
poll():get头元素把元素拿走
四、CopyOnWriteArrayList和CopyOnWriteArraySet
写的时候进行复制,可以进行并发的读。
适用读多写少的场景:比如白名单,黑名单,商品类目的访问和更新场景,假如我们有一个搜索网站,用户在这个网站的搜索框中,输入关键字搜索内容,但是某些关键字不允许被搜索。这些不能被搜索的关键字会被放在一个黑名单当中,黑名单每天晚上更新一次。当用户搜索时,会检查当前关键字在不在黑名单当中,如果在,则提示不能搜索。
弱点:内存占用高,数据一致性弱
总结:写的时候重新复制一份数据,然后在复制的数据里面写入数据,写完以后再把原来的数据的引用执行复制的数据,所以存在数据的弱一致性,适用于读多写少的场景
五、什么是阻塞队列
取数据和存数据不满足要求时,会对线程进行阻塞。例如取数据时发现队列里面没有数据就在那里阻塞等着有数据了再取;存数据时发现队列已经满了就在那里阻塞等着有数据被取走时再存
|
方法 |
抛出异常 |
返回值 |
一直阻塞 |
超时退出 |
|
插入 |
Add |
offer |
put |
offer |
|
移除 |
remove |
poll |
take |
poll |
|
检查 |
element |
peek |
没有 |
没有 |
1、常用阻塞队列
ArrayBlockingQueue: 数组结构组成有界阻塞队列。
先进先出原则,初始化必须传大小,take和put时候用的同一把锁
LinkedBlockingQueue:链表结构组成的有界阻塞队列
先进先出原则,初始化可以不传大小,put,take锁分离
PriorityBlockingQueue:支持优先级排序的无界阻塞队列,
排序,自然顺序升序排列,更改顺序:类自己实现compareTo()方法,初始化PriorityBlockingQueue指定一个比较器Comparator
DelayQueue: 使用了优先级队列的无界阻塞队列
支持延时获取,队列里的元素要实现Delay接口。DelayQueue非常有用,可以将DelayQueue运用在以下应用场景。
缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。
还有订单到期,限时支付等等。
SynchronousQueue:不存储元素的阻塞队列
每个put操作必须要等take操作
LinkedTransferQueue:链表结构组成的无界阻塞队列
Transfer,tryTransfer,生产者put时,当前有消费者take,生产者直接把元素传给消费者
LinkedBlockingDeque:链表结构组成的双向阻塞队列
可以在队列的两端插入和移除,xxxFirst头部操作,xxxLast尾部操作。工作窃取模式。
2、了解阻塞队列的实现原理
使用了Condition实现。
3、生产者消费者模式
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生
产线程和消费线程的工作能力来提高程序整体处理数据的速度。
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发
中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理
完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这种生产消费能力不均衡的问题,便有了生产者和消费者模式。
生产者和消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通信,而是通过阻塞队列来进行通信,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
六、什么是Fork/Join框架
并行执行任务的框架,把大任务拆分成很多的小任务,汇总每个小任务的结果得到大任务的结果。
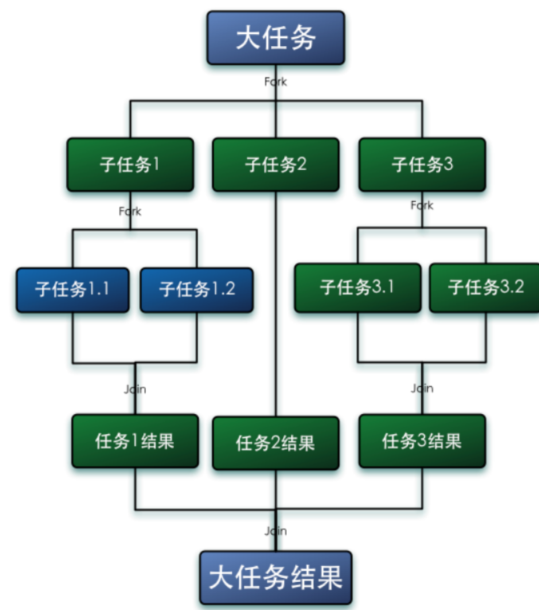
1、工作窃取算法
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行,执行完以后把结果放回去
那么,为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。
比如A线程负责处理A队列里的任务。但是,有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
2、Fork/Join框架的使用
Fork/Join使用两个类来完成以上两件事情。
①ForkJoinTask:我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务
中执行fork()和join()操作的机制。通常情况下,我们不需要直接继承ForkJoinTask类,只需要继承它的子类,Fork/Join框架提供了以下两个子类。
·RecursiveAction:用于没有返回结果的任务。
·RecursiveTask:用于有返回结果的任务。
②ForkJoinPool:ForkJoinTask需要通过ForkJoinPool来执行。
Fork/Join有同步和异步两种方式。
案例1:孙悟空摘桃子fork/join的案例

1 /**
2 * 孙悟空摘桃子fork/join的案例,孙悟空去摘桃子时发现桃子太多就让猴子猴孙去帮忙在桃子,
3 * 摘完以后再统一汇总求和
4 */
5 public class ForkJoinWuKong {
6
7 private static class XiaoWuKong extends RecursiveTask<Integer>{
8
9 private final static int THRESHOLD = 100;//阈值,数组多小的时候,不再进行任务拆分操作
10 private PanTao[] src;
11 private int fromIndex;
12 private int toIndex;
13 private IPickTaoZi pickTaoZi;
14
15 public XiaoWuKong(PanTao[] src, int fromIndex, int toIndex, IPickTaoZi pickTaoZi) {
16 this.src = src;
17 this.fromIndex = fromIndex;
18 this.toIndex = toIndex;
19 this.pickTaoZi = pickTaoZi;
20 }
21
22 @Override
23 protected Integer compute() {
24 //计算完以后结果汇总
25 if (toIndex-fromIndex<THRESHOLD){
26 int count =0 ;
27 for(int i=fromIndex;i<toIndex;i++){
28 if (pickTaoZi.pick(src,i)) count++;
29 }
30 return count;
31 }
32 //大任务拆分成小任务
33 else{
34 //fromIndex....mid......toIndex
35 int mid = (fromIndex+toIndex)/2;
36 XiaoWuKong left = new XiaoWuKong(src,fromIndex,mid,pickTaoZi);
37 XiaoWuKong right = new XiaoWuKong(src,mid,toIndex,pickTaoZi);
38 invokeAll(left,right);
39 return left.join()+right.join();
40
41 }
42 }
43 }
44
45 public static void main(String[] args) {
46
47 ForkJoinPool pool = new ForkJoinPool();
48 PanTao[] src = MakePanTaoArray.makeArray();
49 IProcessTaoZi processTaoZi = new WuKongProcessImpl();
50 IPickTaoZi pickTaoZi = new WuKongPickImpl(processTaoZi);
51
52 long start = System.currentTimeMillis();
53
54 //构造一个ForkJoinTask
55 XiaoWuKong xiaoWuKong = new XiaoWuKong(src,0,
56 src.length-1,pickTaoZi);
57
58 //ForkJoinTask交给ForkJoinPool来执行。
59 pool.invoke(xiaoWuKong);
60
61 System.out.println("The count is "+ xiaoWuKong.join()
62 +" spend time:"+(System.currentTimeMillis()-start)+"ms");
63
64 }
65
66 }
3、案例2:使用Fork/Join框架实现计算1+2+3+....+100的结果
package com.study.demo.forkjoin;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
/**
* Fork/Join框架设计思路:
* 第一步:分割任务。首先我们需要有一个fork类来把大任务分割成子任务,有可能子任务还是很大,所以还需要
* 不停的分割,直到分割出的子任务足够小。
* 第二步:执行任务并合并结果。分割的子任务分别放在双端队列里,然后启动几个线程分别从双端队列里获取任务执行。
* 子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
*
* Fork/Join框架的具体实现:
* Fork/Join使用两个类来完成以上两件事情:
* ForkJoinTask:我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join()
* 操作的机制,通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下两个子类:
* RecursiveAction:用于没有返回结果的任务。
* RecursiveTask :用于有返回结果的任务。
* ForkJoinPool :ForkJoinTask需要通过ForkJoinPool来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,
* 进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
*
* 实战:使用Fork/Join框架实现计算1+2+3+....+100的结果-100个数拆分成10个(阈值)子任务来执行最后汇总结果
*
*/
public class CountTask extends RecursiveTask<Integer> {
/**
* 序列化
*/
private static final long serialVersionUID = 1L;
private static final int THRESHOLD = 10;// 阈值
private int start;
private int end;
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
// 如果任务足够小就计算任务
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任务大于阀值,就分裂成两个子任务计算
int middle = (start + end) / 2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
// 执行子任务
leftTask.fork();
rightTask.fork();
// 等待子任务执行完,并得到其结果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
// 合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 生成一个计算任务,负责计算1+2+3+4
CountTask task = new CountTask(1, 100);
// 执行一个任务
Future result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException e) {
} catch (ExecutionException e) {
}
}
}
七、并发工具类
1. CountDownLatch
允许一个或多个线程等待其他线程完成操作。CountDownLatch的构造函数接收一个int类型的参数作为计数器,如果你想等待N个点完成,这里就传入N。当我们调用CountDownLatch的countDown方法时,N就会减1,CountDownLatch的await方法会阻塞当前线程,直到N变成零。
由于countDown方法可以用在任何地方,所以这里说的N个点,可以是N个线程,也可以是1个线程里的N个执行步骤。用在多个线程时,只需要把这个CountDownLatch的引用传递到线程里即可。
1 public class CountDownLatchCase {
2
3 static CountDownLatch c = new CountDownLatch(7);
4
5 private static class SubThread implements Runnable{
6
7 @Override
8 public void run() {
9 System.out.println(Thread.currentThread().getId());
10 c.countDown();
11 System.out.println(Thread.currentThread().getId()+" is done");
12 }
13 }
14
15 public static void main(String[] args) throws InterruptedException {
16
17 new Thread(new Runnable() {
18 @Override
19 public void run() {
20 System.out.println(Thread.currentThread().getId());
21 c.countDown();
22 System.out.println("sleeping...");
23 try {
24 Thread.sleep(1500);
25 } catch (InterruptedException e) {
26 e.printStackTrace();
27 }
28 System.out.println("sleep is completer");
29 c.countDown();
30 }
31 }).start();
32
33 for(int i=0;i<=4;i++){
34 Thread thread = new Thread(new SubThread());
35 thread.start();
36 }
37
38 c.await();
39 System.out.println("Main will gone.....");
40 }
41 }
八、 CyclicBarrier
CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。CyclicBarrier默认的构造方法是CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用await方法告诉CyclicBarrier我已经到达了屏障,然后当前线程被阻塞。
1 public class CyclicBarrriesBase {
2
3 static CyclicBarrier c = new CyclicBarrier(2);
4
5 public static void main(String[] args) throws InterruptedException, BrokenBarrierException {
6 new Thread(new Runnable() {
7 @Override
8 public void run() {
9 System.out.println(Thread.currentThread().getId());
10 try {
11 c.await();//等待主线程完成
12 System.out.println(Thread.currentThread().getId()+"is going");
13 } catch (InterruptedException e) {
14 e.printStackTrace();
15 } catch (BrokenBarrierException e) {
16 e.printStackTrace();
17 }
18 System.out.println("sleeping...");
19
20 }
21 }).start();
22
23 System.out.println("main will sleep.....");
24 Thread.sleep(2000);
25 c.await();////等待子线程完成
26
27 System.out.println("All are complete.");
28 }
29
30
31
32 }
CyclicBarrier还提供一个更高级的构造函数CyclicBarrier(int parties,Runnable barrierAction),用于在线程到达屏障时,优先执行barrierAction,方便处理更复杂的业务场景。
CyclicBarrier可以用于多线程计算数据,最后合并计算结果的场景。
1 public class CyclicBarrierSum {
2
3 static CyclicBarrier c = new CyclicBarrier(5,new SumThread());
4 //子线程结果存放的缓存
5 private static ConcurrentHashMap<String,Integer> resultMap =
6 new ConcurrentHashMap<>();
7
8 //所有子线程达到屏障后,会执行这个Runnable的任务
9 private static class SumThread implements Runnable{
10
11 @Override
12 public void run() {
13 int result =0;
14 for(Map.Entry<String,Integer> workResult:resultMap.entrySet()){
15 result = result+workResult.getValue();
16 }
17 System.out.println("result = "+result);
18 System.out.println("完全可以做与子线程,统计无关的事情.....");
19 }
20 }
21
22 //工作线程,也就是子线程
23 private static class WorkThread implements Runnable{
24
25 private Random t = new Random();
26
27 @Override
28 public void run() {
29 int r = t.nextInt(1000)+1000;
30 System.out.println(Thread.currentThread().getId()+":r="+r);
31 resultMap.put(Thread.currentThread().getId()+"",r);
32 try {
33 Thread.sleep(1000+r);
34 c.await();
35 } catch (InterruptedException e) {
36 e.printStackTrace();
37 } catch (BrokenBarrierException e) {
38 e.printStackTrace();
39 }
40
41 }
42 }
43
44 public static void main(String[] args) {
45 for(int i=0;i<=4;i++){
46 Thread thread = new Thread(new WorkThread());
47 thread.start();
48 }
49 }
50 }
CyclicBarrier和CountDownLatch的区别
CountDownLatch的计数器只能使用一次,而CyclicBarrier的计数器可以使用reset()方法重置,CountDownLatch.await一般阻塞主线程,所有的工作线程执行countDown,而CyclicBarrierton通过工作线程调用await从而阻塞工作线程,直到所有工作线程达到屏障。
九、控制并发线程数的Semaphore
Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。应用场景Semaphore可以用于做流量控制,特别是公用资源有限的应用场景,比如数据库连接。假如有一个需求,要读取几万个文件的数据,因为都是IO密集型任务,我们可以启动几十个线程并发地读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,这时我们必须控制只有10个线程同时获取数据库连接保存数据,否则会报错无法获取数据库连接。这个时候,就可以使用Semaphore来做流量控制。。Semaphore的构造方法Semaphore(int permits)接受一个整型的数字,表示可用的许可证数量。Semaphore的用法也很简单,首先线程使用Semaphore的acquire()方法获取一个许可证,使用完之后调用release()方法归还许可证。还可以用tryAcquire()方法尝试获取许可证。
1 public class SemaphporeCase<T> {
2
3 private final Semaphore items;//有多少元素可拿
4 private final Semaphore space;//有多少空位可放元素
5 private List queue = new LinkedList<>();
6
7 public SemaphporeCase(int itemCounts){
8 this.items = new Semaphore(0);
9 this.space = new Semaphore(itemCounts);
10 }
11
12 //放入数据
13 public void put(T x) throws InterruptedException {
14 space.acquire();//拿空位的许可,没有空位线程会在这个方法上阻塞
15 synchronized (queue){
16 queue.add(x);
17 }
18 items.release();//有元素了,可以释放一个拿元素的许可
19 }
20
21 //取数据
22 public T take() throws InterruptedException {
23 items.acquire();//拿元素的许可,没有元素线程会在这个方法上阻塞
24 T t;
25 synchronized (queue){
26 t = (T)queue.remove(0);
27 }
28 space.release();//有空位了,可以释放一个存在空位的许可
29 return t;
30 }
31 }
Semaphore还提供一些其他方法,具体如下。
·intavailablePermits():返回此信号量中当前可用的许可证数。
·intgetQueueLength():返回正在等待获取许可证的线程数。
·booleanhasQueuedThreads():是否有线程正在等待获取许可证。
·void reducePermits(int reduction):减少reduction个许可证,是个protected方法。
·Collection getQueuedThreads():返
十、Exchanger
Exchanger(交换者)是一个用于线程间协作的工具类。Exchanger用于进行线程间的数据交换。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。这两个线程通过exchange方法交换数据,如果第一个线程先执行exchange()方法,它会一直等待第二个线程也执行exchange方法,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。
1 public class ExchangeCase {
2
3 static final Exchanger<List<String>> exgr = new Exchanger<>();
4
5 public static void main(String[] args) {
6
7 new Thread(new Runnable() {
8
9 @Override
10 public void run() {
11 try {
12 List<String> list = new ArrayList<>();
13 list.add(Thread.currentThread().getId()+" insert A1");
14 list.add(Thread.currentThread().getId()+" insert A2");
15 list = exgr.exchange(list);//交换数据
16 for(String item:list){
17 System.out.println(Thread.currentThread().getId()+":"+item);
18 }
19 } catch (InterruptedException e) {
20 e.printStackTrace();
21 }
22 }
23 }).start();
24
25 new Thread(new Runnable() {
26
27 @Override
28 public void run() {
29 try {
30 List<String> list = new ArrayList<>();
31 list.add(Thread.currentThread().getId()+" insert B1");
32 list.add(Thread.currentThread().getId()+" insert B2");
33 list.add(Thread.currentThread().getId()+" insert B3");
34 System.out.println(Thread.currentThread().getId()+" will sleep");
35 Thread.sleep(1500);
36 list = exgr.exchange(list);//交换数据
37 for(String item:list){
38 System.out.println(Thread.currentThread().getId()+":"+item);
39 }
40 } catch (InterruptedException e) {
41 e.printStackTrace();
42 }
43 }
44 }).start();
45
46 }
47
48 }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号