
基于对比学习的文本相似度模型
问题:BERT的表示本身存在塌缩的问题。通过对BERT词表示的观察,会发现整体呈锥形分布:高频词聚集在锥头部,低频词分散在锥尾。又由于高频词本身是高频的,因此会主要贡献整个的句子表示,让整体的相似度都很高。
解决思路:
对比学习,它是通过拉近相同样本的距离、拉远不同样本的距离,来刻画样本本身的表示,正好可以解决BERT表示的塌缩问题。
两种对比学习方法:
ConSERT 与 SimCSE都是基于对比学习的文本相似度模型:
1、ConSERT 是采用多种数据增强的方式来构造正例的。主要在Embedding层使用下面几种方法:
shuffle:更换position id的顺序
token cutoff:在某个token维度把embedding置为0
feature cutoff:在embedding矩阵中,有768个维度,把某个维度的feature置为0
dropout:embedding层的dropout
2、SimCSE 则是采用了 BERT 所有层中的 Dropout,将一个batch的数据两次经过BERT(实际上是复制batch的数据再经过BERT,可以加快效率),得到不同的两个输出,比如输入的样本x再两次经过BERT后,由于DropMask的不同,得到的输出就是不一样的,假设得到的输出为 hz 和 hz′ ,将 hz 和 hz′ 作为一组正例, hz 和其他的作为负例,然后用对比损失计算loss。
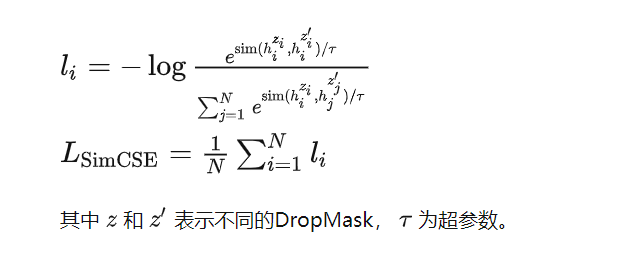
链接:https://zhuanlan.zhihu.com/p/378544839
链接:https://wmathor.com/index.php/archives/1580/

