Albert学习记录
albert相对BERT而言主要有三个改进方向:
1、对Embedding因式分解
在BERT中,词向量维度E和隐层维度H是相等的。而词嵌入学习的是单词与上下文无关的表示,而隐层则是学习与上下文相关的表示。显然后者更加复杂,需要更多的参数,也就是说模型应当增大隐层大小 ,或者说满足
。在实际中,词表V通常非常大,如果E=V,随着BERT模型的增大,E也会随着H不断增加,导致embedding matrix的维度
非常巨大。
在Albert中,想要打破 与
之间的绑定关系,从而减小模型的参数量,同时提升模型表现。词表V到隐层H的中间,使用一个小维度做一次尺度变换:先将单词投影到一个低维的embedding空间
,再将其投影到高维的隐藏空间
。这使得embedding matrix的维度从
减小到
。当
时,参数量减少非常明显。
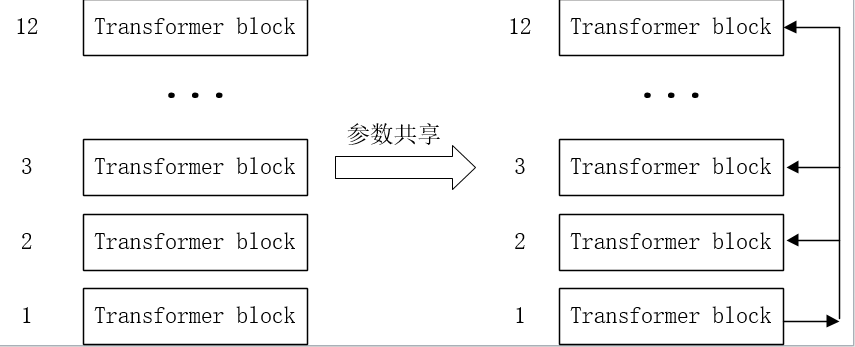
2、参数共享
通过层与层之间的参数共享也是albert减少参数量的一个方法。
bert的每一层参数独立,当层数增加时,参数量也会明显上升,albert将所有层的参数进行共享,即只学习一层的参数量,极大地减小模型的参数量,提升训练速度。
3、SOP任务
Albert对BERT的预训练任务Next-sentence prediction (NSP)进行了改进。
下一句预测(Next-sentence prediction,NSP):正样本为文章中上下相邻的两个句子,负样本为从两篇文档中各自选取一个句子。
句子顺序预测(Sentence-order prediction,SOP):正样本为文章中上下相邻的两个句子,负样本为一篇文档中的两个连续的句子,并将它们的顺序交换
NSP任务相对简单: 模型在判断两个句子的关系时不仅考虑了两个句子之间的连贯性(coherence),还会考虑到两个句子的话题(topic)。而两篇文档的话题通常不同,模型会更多的通过话题去分析两个句子的关系,而不是句子间的连贯性,这使得NSP任务变成了一个相对简单的任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号