文本相似度部分方法介绍及实现
文本相似度任务:
最近接到文本结构化的任务,经过一番实验发现,可将该任务转化为计算标题检索排序任务,可用文本相似度的方法来做。文本相似度计算可直接根据文本本身计算距离来得到或使用模型将语义向量化后再计算距离得到。
一、根据文本本身计算相似度:
1)余弦相似度
import numpy as np from collections import Counter def cos_sim(str1, str2): # str1,str2是分词后的标签列表 co_str1 = (Counter(str1)) co_str2 = (Counter(str2)) p_str1 = [] p_str2 = [] for temp in set(str1 + str2): p_str1.append(co_str1[temp]) p_str2.append(co_str2[temp]) p_str1 = np.array(p_str1) p_str2 = np.array(p_str2) return p_str1.dot(p_str2) / (np.sqrt(p_str1.dot(p_str1)) * np.sqrt(p_str2.dot(p_str2))) print(cos_sim('快乐在城市上空飘扬','快乐在乡镇上空飘扬')) 0.7777777777777778
2)difflib与fuzz均是python自带标准库的计算方法
import difflib from fuzzywuzzy import fuzz def diff_result(str1, str2): return difflib.SequenceMatcher(None, str1, str2).ratio() print(diff_result('快乐在城市上空飘扬','快乐在乡镇上空飘扬')) 0.7777777777777778 def fuzz_result(str1,str2): return fuzz.ratio(str1,str2) print(fuzz.ratio('快乐在城市上空飘扬','快乐在乡镇上空飘扬')) 78
二、使用深度学习模型计算文本相似度
使用模型进行语义抽取,然后根据各文本的特征向量算出余弦距离。
用于语义抽取的模型有很多,Bert及其变种在NLP领域一枝独秀。SBert是基于Bert改进计算相似度的模型,其结构如下:
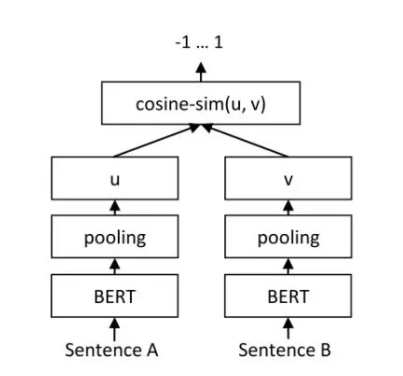
SBERT模型使用孪生网络结构,他的子网络都是用Bert模型,且两个BERT模型共享参数。计算句子A与句子B的相似度时,将A、B输入bert模型,分别得到句子表征,再计算两者之间的余弦相似度。
SBERT相较于BERT而言速度要快很多,经过查找相关资料原因如下:
SBERT一类的方法都可以统称为基于表示的BERT方法,然后直接两两拼接取CLS向量(或者其他什么pooling方法)的可以称为基于交互的BERT方法。相对于基于交互的BERT方法,基于表示的BERT方法有这么几个特点:
1、假设两个文本的长度分别为m和n,那么因为Self-Attention近似为平方复杂度,交互方法计算拼接之后的计算代价可以近似看做O((m+n)^2),然后基于表示的方法因为两个文档彼此独立计算,忽略最后的cosine similarity的话计算代价近似为O(m^2+n^2),比前者少一些
2、基于交互的BERT方法需要所有文档都进行两两拼接计算,1W个句子就要计算1W X 1W次,就算去重也最多只能砍掉一半的数量,而且这样对于IR这样的任务,计算过程必须全程在线上完成,上线成本极高。而基于表示的方法因为文档之间彼此并不耦合,所以只要把1W个句子都计算好,然后两两之间计算cosine similarity就可以了,而cosine similarity的计算代价极低,几乎可以忽略。而且还可以事先在线下算好保存起来,这样线上只要计算query就可以了(通常比doc短很多),可以大幅降低线上负载
3、这还没算完——对于召回任务,你可以不用遍历所有文档一个一个手动计算,直接使用基于ANN的向量召回引擎(比如faiss)还可以进一步地加快召回计算速度。
实现代码:
数据训练
from sentence_transformers import SentenceTransformer, SentencesDataset from sentence_transformers import InputExample, evaluation, losses from torch.utils.data import DataLoader import pandas as pd from tqdm import tqdm model = SentenceTransformer('distiluse-base-multilingual-cased') train_data = pd.read_csv(r"./input/train.csv", sep=",") train_data.sample(frac=1) val_data = pd.read_csv(r"./input/dev.csv", sep=",") val_data.sample(frac=1) test_data = pd.read_csv(r"./input/test.csv", sep=",") def get_input(): train_datas = [] _y = train_data["label"] _s1 = train_data["sentence1"] _s2 = train_data["sentence2"] for s1, s2, l in tqdm(zip(_s1, _s2, _y)): train_datas.append(InputExample(texts=[s1, s2], label=float(l))) return train_datas train_datas = get_input() def eval_examples(): sentences1, sentences2, scores = [], [], [] for s1, s2, l in tqdm(zip(val_data["sentence1"], val_data["sentence2"], val_data["label"])): sentences1.append(s1) sentences2.append(s2) scores.append(float(l)) return sentences1, sentences2, scores sentences1, sentences2, scores = eval_examples() # Define your train dataset, the dataloader and the train loss train_dataset = SentencesDataset(train_datas, model) train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=64) train_loss = losses.CosineSimilarityLoss(model) evaluator = evaluation.BinaryClassificationEvaluator(sentences1, sentences2, scores) # Tune the model model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=5, warmup_steps=100, evaluator=evaluator, evaluation_steps=300, output_path='./two_albert_similarity_model') model.evaluate(evaluator) # Define your evaluation examples def test_examples(): sentences1, sentences2, scores = [], [], [] for s1, s2, l in tqdm(zip(test_data["sentence1"], test_data["sentence2"], test_data["label"])): sentences1.append(s1) sentences2.append(s2) scores.append(float(l)) return sentences1, sentences2, scores sentences1, sentences2, scores = test_examples() evaluator = evaluation.EmbeddingSimilarityEvaluator(sentences1, sentences2, scores) print(model.evaluate(evaluator)) evaluator = evaluation.BinaryClassificationEvaluator(sentences1, sentences2, scores) print(model.evaluate(evaluator))
模型预测
from sentence_transformers import SentenceTransformer, util #微调后的模型 model = SentenceTransformer('./two_albert_similarity_model') # model = SentenceTransformer('cyclone/simcse-chinese-roberta-wwm-ext') emb1 = model.encode("预备党员") emb2 = model.encode("五、\t应用系统及数据资源设计方案,(一)\t架构设计,省级架构设计") emb3 = model.encode("交纳党费") cos_sim = util.pytorch_cos_sim(emb1, emb2) cos_sim1 = util.pytorch_cos_sim(emb3, emb2) print("Cosine-Similarity:", cos_sim,cos_sim1)
参考:
https://www.zhihu.com/question/468746817
https://zhuanlan.zhihu.com/p/351678987

 浙公网安备 33010602011771号
浙公网安备 33010602011771号