高级查询
判断
ISFULL(exp1,exp2) //exp1不为null,则返回exp1,否则返回exp2
where name IS null
where name IS NOT null
where binary name = ‘aaa’ //区别大小写
=,!=,<>,>,>=
查询处理
逻辑查询执行顺序

每一步生成一个虚拟表VT1,VT2,VT3,...如果没有指定某一子句,则跳过相应步骤,只有最后一步生成的虚拟表才会返回给用户;
example:
CREATE TABLE customes (
customer_id VARCHAR(10) NOT NULL,
city VARCHAR(10) NOT NULL,
PRIMARY KEY (customer_id)
);
INSERT INTO customes VALUES ('163', 'HangZhou'),
('9you', 'ShangHai'), ('TX', 'HangZhou'), ('baidu', 'HangZhou');
CREATE TABLE orders (
order_id INT NOT NULL AUTO_INCREMENT,
customer_id VARCHAR(10),
PRIMARY KEY (order_id)
);
INSERT INTO orders (customer_id) VALUES ('163'), ('163'), ('9you'), ('9you'),
('9you'), ('TX'), (NULL);
#查询来自杭州订单数少于2的客户
SELECT
c.customer_id,
count(o.order_id) total_order
FROM
customes c LEFT JOIN orders o
ON c.customer_id = o.customer_id
WHERE c.city = 'HangZhou'
GROUP BY c.customer_id
HAVING count(o.order_id) < 2
ORDER BY total_order DESC;
执行笛卡儿积(from)
也称为交叉连接;
from 前的表中包含a字段,from后的表中包含b字段,交叉连接虚拟表VT1中将包含a*b行数据;
example
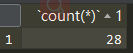
SELECT count(*) from customes JOIN orders;
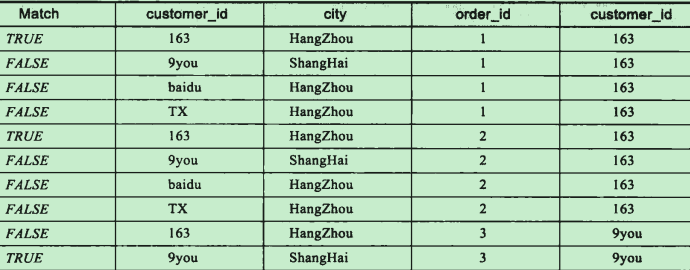
应用ON过滤器
- select共有3个过滤过程:ON、 WHERE、 HAVING
- ON最先执行;
- ON过滤条件下NULL值比较,比较结果为UNKNOWN,视为FALSE来进行处理,即两NULL不相等;
- 注:
GROUP BY子句把所有NULL值分到同一级;
ORDER BY子句把所有NULL值排列在一起;
执行 ON c.customer_id = o.customer_id
产生虚拟表VT2,会增加一个额外的列表示ON过滤返回值;
带有逻辑判断值的VT1
... ...
取出比较值为TRUE的记录,产生虚拟表VT2
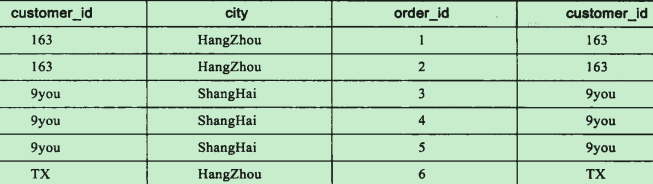
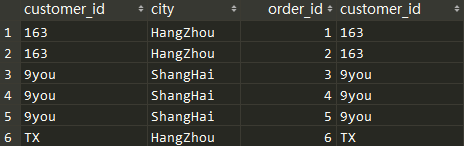
添加外部行(JOIN)
- [LEFT | RIGHT | FULL] [OUTER] JOIN:使用这些语句表示外部行
- 添加外部行是在VT2表的基础上添加保留表中被过滤掉的数据,非保留表数据被赋予NULL值,生成VT3;
customes c LEFT JOIN orders o
保留表:customes
非保留表:orders
- 连接表数大于2,则对虚拟表VT3重做和1~3步;
SELECT c.*,o.* FROM
customes c LEFT JOIN orders o
ON c.customer_id = o.customer_id;
- baidu在VT2表中没有订单而被过滤,baidu作为外部行被添加,生成VT3
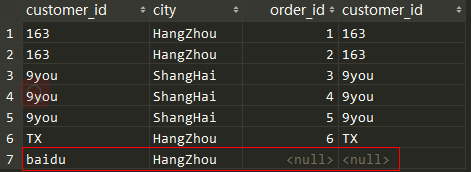
- INNER JOIN 不会添加被过滤掉的数据
SELECT c.*,o.* FROM
customes c INNER JOIN orders o
ON c.customer_id = o.customer_id;
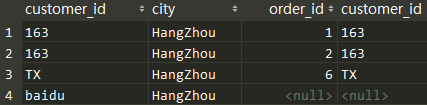
WHERE过滤器
- 在VT3进行WHERE过滤,生成VT4;
- WHERE过滤时,有两种过滤是不允许的:
- 由于数据未分组,不能使用统计函数
- 没有列的选取,不能使用列的别名
- ON与WHERE有所不同
- OUTER JOIN..ON,会将过滤掉的记录添加到保留表中
- WHERE过滤掉的记录则永久过滤掉
SELECT c.*,o.* FROM
customes c LEFT JOIN orders o
ON c.customer_id = o.customer_id
WHERE c.city = 'Hangzhou';
group by分组
- 根据VT4进行分组,生成VT5
- GROUP BY会认为NULL值是相等的,会将NULL分到同一分组中
WITH ROLLUP | CUBE
创建额外的记录添加到VT5,生成VT6
HAVING过滤器
生成VT7
- HAVING是对分组条件进行过滤的筛选器
- HAVING必须有在GROUP BY之后,ORDER BY之前;
- HAVING count(o.order_id)<2
注:子查询不能做分组的聚合函数,如,HAVING COUNT(SELECT ...)<2 是不合法的
聚合函数过滤使用having
SELECT列表
VT8
- 列的别名不能在SELECT中的其他别名表达式中使用

应用DISTINCT
VT9
- 会创建一张内存临时表(内存中存放不下就放到磁盘)操作的列增加了一个唯一索引,来去除重复数据
ORDER BY
VT10
SELECT order_id,customer_id FROM orders ORDER BY 1 ;
limit
VT11
子查询
where查询条件中的限制条件不是一个确定的值,而是一个来自于另一个查询的结果;
子查询分类
单行单列
子查询一列一个数据,位置在外层查询where后面,外层查询返回一行数据
运算符:=,>,<,>=,<=,<>
单行多列
子查询返回单行多个列数据,位置在外层查询where后面,外层查询返回一行数据
select * fromstudent where (age,height) = (select max(age),max(height) from stuinfo);
多行单列
子查询返回多行单列数据,位置在外层查询where后面,外层查询返回多行数据
关键字:any,in,some,all,exists,not in,not exists
多行多列
子查询返回多行多列数据,形成了一张表,位置在外层查询from后面
使用ANY、IN和SOME进行子查询
ANY
- ANY必须与一个操作符一起使用
- 对于子查询返回的列中的任一数值(or),如果有一个比较结果为TRUE,则返回TRUE
Example:
select s1 from t1 where s1>ANY (select s1 from t2);
如果t1.s1的某一行值大于t2.s1的某一行值,则为TRUE,否则为FALSE
比较结果条件:
- t1.s1有一行为10,t2.s1包含21,14,7,则为TRUE
t1.s1(10) > t2.s1(21,14,7)
- t1.s1(10)>t2.s1(21,14). 结果为false
- t1.s1(10)>t2.s1(null,null,null). 结果为UNKNOWN
IN
- IN是=ANY的别名
- IN前面要有字段;
- mysql优化器对于IN语句的优化是“LAZY”的,IN(1,2,3)显式的列表则不会 转换为EXISTS相关的子查询
exampl:
SELECT
customerid,
companyane
FROM customers A
WHERE country = 'Spain'
AND customerid IN (SELECT * FROM orders);
优化器会转换为:
SELECT
customerid,
companyane
FROM customers A
WHERE country = 'Spain'
AND exists(SELECT *
FROM orders B
WHERE A.customerid = B.customerid);
SOME
- SOME是ANY的别名
ALL
- ALL必须与比较操作符一起使用
- 对于子查询返回的列中的所有值(and),如果所有比较结果为TURE,则返回TURE
- t1.s1(10)>t2.s1(1,5,9),结果为TURE,否则为FALSE
- NOT IN是<>ALL的别名
独立子查询
- 不依赖外部查询而运行的子查询;
- mysql优化器对于IN语句的优化是“LAZY”的,IN(1,2,3)显式的列表则不会 转换为EXISTS相关的子查询
- select ... from t1 where t1.a IN(select b from t2);则会转换为:
select ... from t1 where exists(select 1 from t2 where t2.b=t1.a);成为相关子查询
相关子查询
引用了外部查询列的子查询,即子查询会对外部查询的每行进行一次计算;
EXISTS
exists 关键字前面不会有字段
example:
查询返回来自西班牙且发生过订单的消费者;
SELECT
customerid,
companyane
FROM customers A
WHERE country = 'Spain'
AND exists(SELECT *
FROM orders B
WHERE A.customerid = B.customerid);
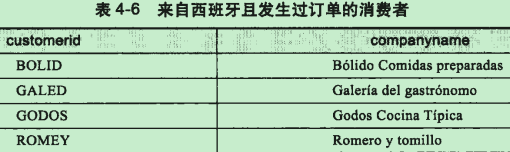
注:EXISTS子查询中的*可以放心使用,EXISTS只关心行是否存在,而不会去取各列的值;
IN与EXISTS值比较
EXISTS总是返回TRUE或FALSE,NULL值返回FALSE;
IN返回TRUE或FALSE或NULL;有NULL值比较返回UNKNOWN(NULL),在过滤器中处理方式与FALSE相同;
SELECT NULL IN ('A','B',NULL);
+------------------------+
| null in ('a','b',null) |
+------------------------+
| NULL |
+------------------------+
1 row in set (0.00 sec)
mysql> select null in ('a','b','c');
+-----------------------+
| null in ('a','b','c') |
+-----------------------+
| NULL |
+-----------------------+
1 row in set (0.00 sec)
NOT IN与NOT EXISTS值比较
NOT IN:在包含null值的子查询时,总是返回NOT TRUE或NOT UNKNOWN,即FALSE(0)和UNKNOWN(NULL)
mysql> select null not in ('a','b',null);
+----------------------------+
| null not in ('a','b',null) |
+----------------------------+
| NULL |
+----------------------------+
1 row in set (0.01 sec)
mysql> select 'a' not in ('a','b',null);
+---------------------------+
| 'a' not in ('a','b',null) |
+---------------------------+
| 0 |
+---------------------------+
1 row in set (0.00 sec)
mysql> select 'c' not in ('a','b',null);
+---------------------------+
| 'c' not in ('a','b',null) |
+---------------------------+
| NULL |
+---------------------------+
1 row in set (0.00 sec)
NOT IN 带有null值的子查询总是返回0或null
集合操作union
将多个结果集纵向连接
- 两个输入必须拥有相同的列数,数据类型不同,会自动隐式转化,结果列由第一输入决定;
- 只有最后一个SELECT可以应用INTO OUTILE,但整个集合操作会被输出到文件中;
- 不能使用HIGH_PRIORITY
- select包含limit和order by,将各select语句添加括号;
union [distinct]
过滤集合重复项,默认可省略distinct
union all
包含重复项
except
mysql不支持EXCEPT原生语法,通过union实现
except distinct
找出第一个输入中但不位于第二个输入中的行数据:
CREATE TABLE x(a CHAR(1),b CHAR(1));
CREATE TABLE y(a CHAR(1),b CHAR(1));
INSERT INTO x VALUES ('a','b'),('b',null),('c','d'),('c','d'),('c','d'),('c','c'),('e','f');
INSERT INTO y VALUES ('a','b'),('b',null),('c','d'),('c','c');
x表的(‘e’,’f’)不位于y表中,使用LEFT JOIN和NOT EXISTS查询:
SELECT DISTINCT x.a,x.b
FROM x LEFT JOIN y
ON x.a = y.a AND x.b = y.b
WHERE y.a IS NULL AND y.b IS NULL;
SELECT DISTINCT x.a,x.b FROM x
WHERE NOT exists(SELECT * FROM y WHERE x.a=y.a AND x.b=y.b);
+------+------+
| a | b |
+------+------+
| b | NULL | //查询出这条是不对的
| e | f |
+------+------+
2 rows in set (0.05 sec)
使用union:
SELECT *
FROM (SELECT DISTINCT a,b FROM x
UNION ALL
SELECT DISTINCT a,b FROM y) as A
GROUP BY a,b
HAVING count(*) = 1;
+------+------+
| a | b |
+------+------+
| e | f |
+------+------+
1 row in set (0.08 sec)
except all
数据在输入A中出现了x次,在输入B中出现了y次,如果x>y,则该数据将出现x-y次,否则结果中将不包含这数据;
INTERSECT
返回在两个输入中都出现的行,与except一样,如果输入中有null值,left join和not exists来解决就会有问题;
SELECT a,b FROM (
SELECT DISTINCT a,b FROM x
UNION ALL
SELECT DISTINCT a,b FROM y
) A
GROUP BY a,b
HAVING count(*) = 2;
+------+------+
| a | b |
+------+------+
| a | b |
| b | NULL |
| c | c |
| c | d |
+------+------+
4 rows in set (0.00 sec)
联接操作
将多张表横向连接
CROSS JOIN(交叉联接)
- 对两个表执行笛卡儿积,返回两个表中所有列的组合。若左表有m行数据,右表有n行数据,则CROSS JOIN将返回m*n行的表;
mysql> SELECT count(*) FROM dept_manager;
+----------+
| count(*) |
+----------+
| 24 |
+----------+
1 row in set (0.00 sec)
mysql> SELECT count(*) FROM dept_manager a JOIN dept_manager b;
+----------+
| count(*) |
+----------+
| 576 |
+----------+
1 row in set (0.01 sec)
- 自己与自己交叉联接,需要指定别名,否则报错;
SELECT count(*) FROM dept_manager JOIN dept_manager ;
[2018-05-09 15:26:53] [42000][1066] Not unique table/alias: 'dept_manager'
- ANSI SQL 92:
mysql> SELECT count(*) FROM dept_manager a JOIN dept_manager b;
+----------+
| count(*) |
+----------+
| 576 |
+----------+
1 row in set (0.01 sec)
- ANSI SQL 89:
mysql> SELECT COUNT(*) FROM dept_manager a,dept_manager b;
+----------+
| COUNT(*) |
+----------+
| 576 |
+----------+
1 row in set (0.00 sec)
- 快速生成重复测试数据
生成行号
SELECT emp_no,dept_no,(SELECT count(1) FROM dept_emp t2 WHERE t1.emp_no<=t2.emp_no) as row_num FROM dept_emp t1;
t1表大约有30万行,先取出t1表,然后每一行与t2表联接,30*30=900亿,太慢了,所以:
mysql> select @a:=@a+1 row_nums,emp_no,dept_no from dept_emp,(select @a:=0) t limit 10;
+----------+--------+---------+
| row_nums | emp_no | dept_no |
+----------+--------+---------+
| 1 | 10017 | d001 |
| 2 | 10055 | d001 |
| 3 | 10058 | d001 |
| 4 | 10108 | d001 |
| 5 | 10140 | d001 |
| 6 | 10175 | d001 |
| 7 | 10208 | d001 |
| 8 | 10228 | d001 |
| 9 | 10239 | d001 |
| 10 | 10259 | d001 |
+----------+--------+---------+
10 rows in set (0.02 sec)
select @a:=0是一行,30*1=30万,变量@a每行+1,所以性能提高了。SQL扫描成本为O(N)
数字辅助表
[INNER] JOIN(内联接)
隐式与显示,查询结果完全相同,语法有区别,区别在于隐式看不到join,显示看得到join;
隐式内连接:
select <select_list>
from 表名A,表名B
[where][and 消除笛卡尔积的连接条件]
[order by]
显示内连接:
- inner join 不添加外部行;与OUTER JOIN最大的区别;
- inner cross 在没有ON的情况下,没什么区别,属于同义词
- ON子句中的列具有相同的名称,可使用USING子句来进行简化
mysql> SELECT a.emp_no
FROM dept_manager a
JOIN dept_manager b
ON a.emp_no = b.emp_no AND a.dept_no = 'd001';
+--------+
| emp_no |
+--------+
| 110022 |
| 110039 |
+--------+
2 rows in set (0.00 sec)
使用USING
mysql> SELECT a.emp_no
FROM dept_manager a
JOIN dept_manager b
USING (emp_no)
WHERE a.dept_no = 'd001';
+--------+
| emp_no |
+--------+
| 110022 |
| 110039 |
+--------+
2 ROWS IN SET (0.00 sec)
OUTER JOIN(外联接)
- [LEFT | RIGHT [OUTER] JOIN ON
- 添加的外部行中没有匹配的数据会以NULL填充,IS NULL过滤掉为NULL的数据;
mysql> SELECT c.customer_id
FROM customers c LEFT JOIN orders o ON c.customer_id = o.customer_id //可用USING简化ON子句
WHERE o.order_id IS NULL
- OUTER JOIN必须有ON子句;
- 查询最小缺失值
create table t(a int,b VARCHAR(5),PRIMARY KEY (a));
INSERT INTO t VALUES (1,'z'),(2,'P'),(3,'G'),(5,'E'),(6,'F'),(7,'B'),(9,'V');
SELECT min(x.a + 1)
FROM t x LEFT JOIN t y ON x.a + 1 = y.a
WHERE y.a IS NULL;
+--------------+
| min(x.a + 1) |
+--------------+
| 4 |
+--------------+
1 row in set (0.00 sec)
SELF JOIN
CREATE TABLE emp(emp_no int PRIMARY KEY ,mgr_no int,emp_name VARCHAR(30));
INSERT INTO emp VALUES (1,NULL ,'David'),(4,1,'Jim'),(3,1,'Tommy'),(2,3,'Mariah'),
(5,3,'Selina'),(6,4,'John'),(8,3,'Monty');
SELECT a.emp_name emploees,b.emp_name manager FROM emp a LEFT JOIN emp b ON a.mgr_no = b.emp_no;
+----------+---------+
| emploees | manager |
+----------+---------+
| David | NULL |
| Mariah | Tommy |
| Tommy | David |
| Jim | David |
| Selina | Tommy |
| John | Jim |
| Monty | Tommy |
+----------+---------+
7 rows in set (0.02 sec)
七种JOIN理论
内连接
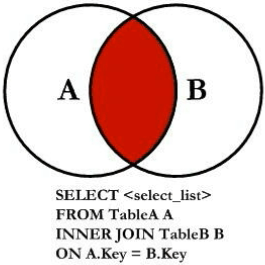
外连接左表为主
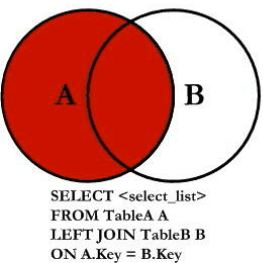
外连接右为主为
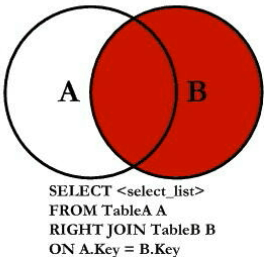
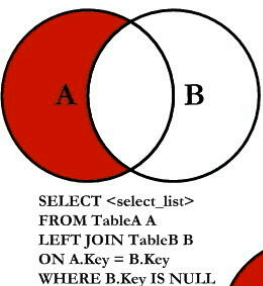
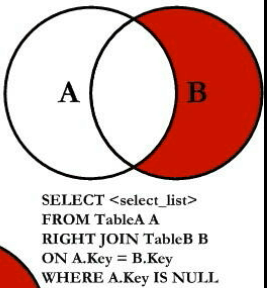
全外连接
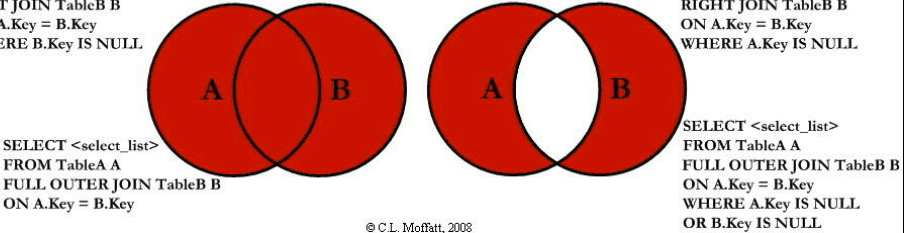
mysql不支持全外连接(full outer join),使用union 加左右连接
select * from tbl_emp emp left join tbl_dept dept on emp.deptld=dept.id
union
select * from tbl_emp emp right join tbl_dept dept on emp.deptld=dept.id;
select * from tbl_emp emp left join tbl_dept dept on emp.deptld=dept.id where dept.id is null
union
select * from tbl_emp emp right join tbl_dept dept on emp.deptld=dept.id where emp.deptld is null;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号