如何正确的关闭Elasticsearch集群
如何正确的关闭Elasticsearch集群
背景
接触Elasticsearch(5.x)也快半年时间了,一直也没弄明白如何的关闭ES集群。经常在测试和生产环境遇到这样的问题“重启ES后数据怎么没了?”,“启动ES后,怎么一直有大量的数据在迁移?”
问题原因
其本质原因有两点:
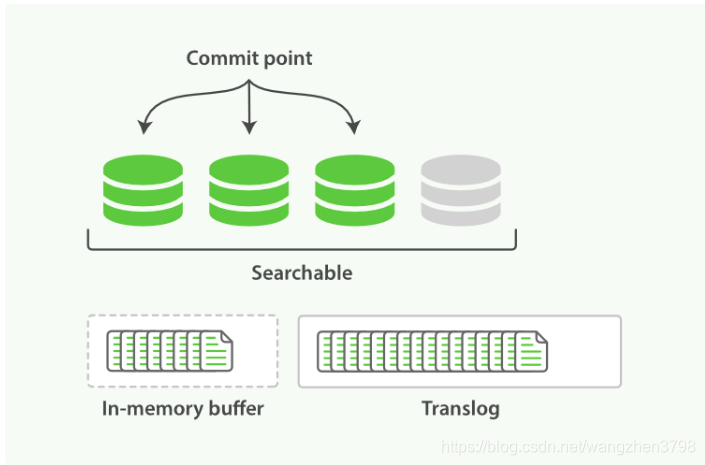
- ES中的数据不是实时写入磁盘的。数据进入ES后先进入data buffer和log buffer,然后进入操作系统文件系统缓存的数据段,最后再特定时机下才刷入磁盘。即在内存中有很多数据是没写入磁盘的。
- ES的分片自动分配迁移机制。当集群发现经过一分钟后(index.unassigned.node_left.delayed_timeout参数设置)还连接不上某个节点,就会把集群内的数据重新进行分布,即使后来节点重新连接上,原来的数据因为重新分布也无效了。
如何正确的关闭ES集群
- 第一步,禁止分片自动分布
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "none"
}
}
- 第二步,执行同步刷新
POST _flush/synced
- 第三步,各节点逐个关闭
# 通过服务关闭
# sudo systemctl stop elasticsearch.service
# 发送TERM信号关闭进程
kill $(cat pid.txt)
如何启动ES集群
- 第一步,执行完操作后逐个启动节点,先master节点再其他节点
cd $ES_HOME/bin
./elasticsearch -d -p $ES_HOME/pid.txt
- 第二步,等待所有节点加入集群
查看集群状态是否为"yellow"或者"green"
GET _cat/health
GET _cat/nodes
- 第三步,启用分片自动分布("yellow"或者"green"后)
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": null
}
}
- 第四步,等待集群可用
通过集群的状态和恢复进程监控集群是否可用
GET _cat/health
GET _cat/recovery

 浙公网安备 33010602011771号
浙公网安备 33010602011771号