社会科学问题研究的计算实践——4、博弈论基础概念(计算实践:多人重复囚徒困境(IPD)博弈循环赛)
 计算实践:多人重复囚徒困境(IPD)博弈循环赛
计算实践:多人重复囚徒困境(IPD)博弈循环赛
学习资源来自,一个哲学学生的计算机作业 (karenlyu21.github.io)
1、背景问题
1.1、博弈问题作为理论抽象
博弈论是社会科学经典理论,同图论一样,博弈论可以用于对现实世界的一类现象进行抽象。
李老师先从最经典的“囚徒困境”讲起。两疑犯被警察抓住,分开关押。警察怀疑他们和一抢劫案有关,但没充足的证据。然而,他们都拒捕的事实也是可判刑的。开始审问,两疑犯被分别告知以下后果:
- 如果你坦白,而他抵赖,则马上把你释放,他将承担全部罪行,将被判刑10年。
- 如果你们都坦白,你们的罪行也就证实了。但由于你们有认罪表现,将都判刑4年。
- 如果你们都不坦白,那么没有证据证明你们的抢劫罪,但我们也会以拒捕罪起诉你们,将被判刑1年。
同时也告知:另一方也正在被告知这样的后果及你也知道这些。
两个囚徒之间的博弈可以由以下的收益矩阵表示:
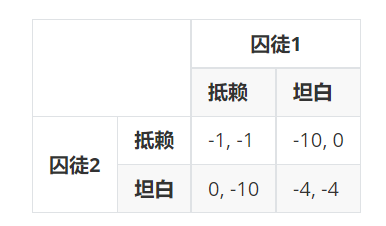
这里的要点是,每个人的收益不仅受自己的选择影响,而且受对方的选择影响。收益矩阵的不同赋值(关键是不同选择的收益的序数),决定了博弈的结果。
除了囚徒困境以外,博弈有多种类型。按照收益矩阵的不同赋值,博弈还有协调博弈和零和博弈(定义在此处略过),等等。除了两个参与者之间的博弈,博弈还可能在多个人之间发生。例如,在拍卖活动中,我的收益也取决于别人的出价。
总而言之,博弈有以下三个要素:
- 参与人(玩家/局中人):至少两个,独立
- 策略(战略,选项):每人可能的选择
- 回报(收益):不仅取决于自己,还取决于别人
对于任意一个博弈,我们关心:
- 作为参与人,我怎么能得到较大回报?
- 作为观察者(社会),总体来看,结果会如何?
1.2、博弈问题求解
求解博弈问题有多种方法。一种普遍的关注是找出博弈的均衡:对每个参与人而言,单方面更换策略已不能更好。根据纳什的研究,任何有穷博弈都至少有一个均衡,它有可能是纯策略均衡,也有可能是混合策略均衡(以给定的概率分别采取多种策略)。
要进行简单博弈推理,我们首先有以下几个理论假设:
- 个人收益是参与人关注的唯一对象。
- 参与人都是利己理性的(rational):追求自己的收益最大化(尽量大)——给定其他人的策略,若自己能通过改变当前策略获得更大收益,则不会采用当前策略。
- 每个参与人都对博弈结构(收益矩阵)有充分了解,即信息完整。
- 每个参与人都知道其他参与人也了解上述要点——共有知识(common knowledge)。
在前面囚徒困境的例子中,
尽管两者都抵赖总福利最大(−1,−1),但是,每个人都有动机在别人抵赖时坦白,从而获得更大的收益0,也担心对方这样做。给定对方的选择(不管是“抵赖”还是“坦白”),自己都是选“坦白”更好,也就是说,“坦白”是双方各自的“严格占优策略”。因此,这个博弈会在−4,−4达到均衡。
除了双方都有严格占优策略的情况之外,达成均衡有多种方式。李老师在课上给我们举了几个例子,我们还做了几个求解练习。由于这些内容与本节课的计算作业关系不大,故仅列举在此。
- 一方有严格占优策略,另一方能推测出对方的严格占优策略,从而采取“最佳应对策略”。
- 双方没有严格占优策略,但都有“占优策略”。可以通过排除“严格劣策略”来找出这种均衡。
- 双方都没有占优策略和严格劣策略,但“互为最佳应对策略”的情况仍然存在,如果某种外界因素促使这一情况实现,那么双方都没有动机改变自己的策略,达到稳定状况。
2、计算实践:多人重复囚徒困境(IPD)博弈循环赛
2.1、作业描述与算法思路
为了研究重复囚徒困境问题,假设招募了全班共m个人参加重复博弈,采用循环赛制,即一共有m/(m−1)2场博弈;每场n(无穷,很大,事先不确定)轮。
我们被告知博弈矩阵(如下图)以及参加的总人数,还被告知,比赛采用串行方式,即两个人把n轮做完,再换两人。
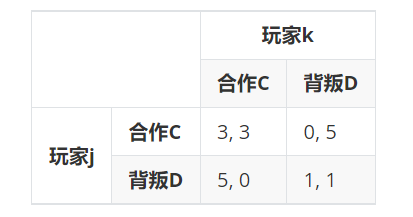
我们要以一个函数的方式提供自己的策略。该函数的输入是自己和对手到当前为止已给出的行为(策略的一部分),返回自己下一次的行为。总得分是我参与的所有博弈(n(m−1)次)的得分之和。
每个人给出自己的策略函数后,我们还需要写程序模拟一个循环赛程序(调用那些函数),试用不同的n,分别算出每个人的总分,并进行讨论。
为了设计出得分高的策略,我的函数要分析自己和对手到当前为止已给出的行为,预测对方的下一次行为。给出自己的反应时,我们还要考虑到,自己如此行动会成为此后博弈的已知信息,这会不会影响未来的合作?总之,我们需要预测对方的行动,做出最有利于多次博弈总收益的回应。最好是能猜出对方的策略函数。比如说,“一报还一报”策略可能被很多人采纳,那么我可以在我的策略函数中设置一些判断条件。如果对方真的采用“一报还一报”策略,最有利于我的策略就是永远选择合作。模拟循环赛的程序并不难,只有判断最佳应答策略时程序稍微有些复杂,具体的算法见后。
2.2、编程实现与要点说明
2.2.1、策略函数
每个人的策略函数,输入自己到当前为止已给出的行为me和对手到当前为止已给出的行为him,返回下一次的行为合作C或背叛D。
一个最典型的策略函数是“一报还一报”。如果对方上一次选择合作,亦即if him[i-1]=='C',我这一次就选择合作'C';否则就选择背叛'D'。
copy# 一报还一报的策略函数
def p7(i, me, him):
if i == 0:
return 'C'
else:
if him[i-1] == 'C':
return 'C'
else:
return 'D'
老师提供了一个devil策略。如果对方上一次选择合作,devil就选择背叛;对方上一次背叛,devil就合作。
copy# devil的策略函数
def devil(i, me, him):
if i == 0:
return 'D'
else:
if him[i-1] == 'C':
return 'D'
else:
return 'C'
我的策略函数则稍微复杂一些。我在函数里加入了一些判断条件,试图预测对方的策略,从而给出自己的反应。
前四次我都选择合作,从而获取对方的四次反应数据。
copy# 预测对方策略进而给出自己的策略函数
def p10(i, me, him):
if i in [0, 1, 2, 3]:
return 'C'
接着,我开始预测对方的策略函数。
如果对方第三次以后总是选择合作,我就认为ta采取的是“天真策略”('innocent')。当然,我前四次都选择合作,对方也选择合作很正常,这个判断条件会让我第五次选择背叛。但这只会损害我在一轮里的收益,这是获取对方反应数据的必要成本。如果我第五次选择了背叛,对方仍然不选择背叛,认为对方采取的是“天真策略”('innocent')就比较合理了。
copy else:
if 'D' not in him[2:]:
flag = 'innocent'
if flag == 'innocent':
return 'D'
接着,我开始验证对方是否采取了“一报还一报”策略。关键在于分析对方采取合作时的情景:对方为什么愿意信任我,选择合作?
- 一个可能的原因是,我上一轮也选了合作。我选择合作的次数存储在
cnt1_1,当我上一轮选择合作时对方下一轮选择合作的次数存储在cnt1_2,当cnt1_2 / (cnt1_1 - 1) > 0.9时,我认为我上一轮选择合作能够触发对方下一轮选择合作。这个策略被我称为's-retri'(短时报复策略)。 - 另一个原因是,我过去经常选择合作,对方就会选择合作。对方选择合作的次数存储在
cnt2_1,ta选择合作时,有cnt2_2次,我过去行为的众数也是合作。当cnt2_2 / cnt2_1 > 0.9时,我认为,我过去经常选择合作能够触发对方下一轮选择合作。这个策略被我称为'l-retri'(长时报复策略)。
copy flag = None
cnt1_1 = 0
cnt1_2 = 0
cnt2_1 = 0
cnt2_2 = 0
for j in range(i-1):
if me[j-1] == 'C':
cnt1_1 += 1
if me[j-1] == him[j]:
cnt1_2 += 1
elif him[j] == 'C':
cnt2_1 += 1
if j > 2 and max(set(me), key=me.count) == him[j]:
cnt2_2 += 1
elif cnt1_2 / (cnt1_1 - 1) > 0.9 and cnt1_2 >= 2:
flag = 's-retri'
elif cnt2_1 > 0:
if cnt2_2 / cnt2_1 > 0.9:
flag = 'l-retri'
如果我无法判断对方的策略,保险起见,我选择背叛。
如果我判断对方的策略是报复策略(不论是长时还是短时),我都选择合作,以期ta下回也会和我合作。
copy if flag == None:
return 'D'
elif flag in ['s-retri', 'l-retri']:
return 'C'
2.2.2、博弈循环赛
11位同学(每一个同学def一个策略)和devil的策略函数集合在strategy.py里,先跨文件调用:
copyimport strategy
# 作者并未给出全部策略,笔者认为可以自己书写(but 我还没想出这么多...)
strategies = [strategy.p1, strategy.p2, strategy.p3, strategy.p4, strategy.p5, strategy.p6, strategy.p7, strategy.p8, strategy.p9, strategy.p10, strategy.p11, strategy.devil]
outputF = open('./output.csv', 'w') # for scores
outputF2 = open('./output.txt', 'w') # for analysis
首先定义一个函数game_dual。给定两个玩家,模拟二者之间的多轮重复博弈,按照收益矩阵计算两个人各自的分数。
copy# 模拟多轮重复博弈
def game_dual(n, i, j):
me = []
me_score = 0
me_str = strategies[j-1]
him = []
him_score = 0
him_str = strategies[j-1]
for k in range(n):
# actions
me_react = me_str(k, me, him)
him_react= him_str(k, him, me)
me.append(me_react)
him.append(him_react)
# scores
if me_react == 'D' and him_react == 'D':
me_score += 1
him_score += 1
elif me_react == 'C' and him_react == 'D':
me_score += 0
him_score += 5
elif me_react == 'D' and him_react == 'C':
me_score += 5
him_score += 0
else:
me_score += 3
him_score += 3
return me_score, him_score
定义函数game,以便改变循环赛设定(轮数n和有无devil)时多次调用。让所有玩家两两进行博弈,把每一组的结果存储在score_dict里。例如,i和j博弈的结果就是score_dict[i][j]。
首先,统一计算所有玩家相互博弈后的总分数(存储在scores里),输出结果。
copy# 循环赛设定
def game(n, devil=False):
score_dict = {}
print('Game on... (%i rounds in all)' % n)
if devil == False:
end = 12
else:
end = 13
scores = [0 for i in range(end)]
for i in range(1, end):
for j in range(i+1, end):
me_score, him_score = game_dual(n, i, j)
score_dict[i, j] = [me_score, him_score]
print('%i v.s. %i: %i – %i' % (i, j, me_score, him_score))
scores[i] += me_score
scores[j] += him_score
outputF.write('devil = %s and n = %i\n' % (str(devil), n))
outputF2.write('*** devil = %s and n = %i ***\n' % (str(devil), n))
for i in range(1, end): # total scores of each one
outputF.write('%i,%i\n' % (i, scores[i]))
print('%i: %i' % (i, scores[i]))
接着,为了分析最佳应答策略,我分析比赛结果score_dict,把每个人从i处赚得的分数存储在score_individual[i]里。
copy for key, value in score_dict.items():
for i in range(1, end):
if i in key:
i_index = key.index(i)
j = key[1 - i_index]
j_score = value[1 - i_index]
scores_individuals[i][j] = j_score
从i处赚得最多分数的人,具有最佳应答策略。
copy best_react_dict = {}
for key, value in scores_individuals.items():
best_reacted = [0, 0] # [j, j_score] (j reacted best against key, with a score of j_score)
for j, j_score in value:
if j_score > best_reacted[1]:
best_reacted = [j, j_score]
考虑有多个最佳应答策略的情况,他们从i赚得的分数一样。
copy elif j_score == best_reacted[1]:
best_reacted.append(j)
best_reacted.append(j_score)
考虑不存在最佳应答策略的情况,删除用来占空的[0,0]。
copy if best_reacted[0:2] == [0, 0]:
del best_reacted[0:2]
输出分析结果
copy best_react_dict[key] = best_reacted
print('* 对%i,p%s是最佳应答策略。' % (key, best_reacted[0:-1:2]))
outputF2.write('* 对%i,p%s是最佳应答策略。\n' % (key, best_reacted[0:-1:2]))
print()
非严格占优策略dominant对于所有玩家都是最佳占优策略。
copy # 非严格占优策略
dominant = [1] + best_react_dict[1][0:-1:2]
for i in range(2, end):
next_range = best_react_dict[i][0:-1:2] + [i]
dominant = [x for x in dominant if x in next_range]
两个人互相是对方的最佳占优策略,也值得分析。
copy # 互为对方的最佳占优策略
reciprocal = []
for key, value in best_react_dict.items():
for j in range(0, len(value), 2):
if value[j] > key:
for k in range(0, len(best_react_dict[value[j]]), 2):
if key == best_react_dict[value[j]][k]:
reciprocal.append([key, value[j]])
为了方便重复调用,以上分析都被包含在game函数中。game函数最后返回score_dict。
copy return score_dict
以下是主程序。循环次数不同时、有无devil时,计算比赛的不同结果。
copy# 主程序
score_dict_whole = {0: {}, 1: {}}
for n in [1, 10, 100, 1000]:
print('无devil, n = %i' % n)
score_dict_whole[0][n] = game(n)
print('有devil, n = %i' % n)
score_dict_whole[1][n] = game(n, True)
2.2.3、结果与分析
由于缺少数据或部分代码,这里结果和分析无法做出,但已经联系作者,希望可在GitHub开源。上述编程的实现及思路值得学习,下面的分析也值得了解!

n=1000, devil=True时,输出结果如下:
copy>>> *** devil = True and n = 1000 ***
>>> * 对1,p[10]是最佳应答策略。
>>> * 对2,p[1, 3, 4, 5, 6, 7, 8, 9, 11]是最佳应答策略。
>>> * 对3,p[1, 2, 4, 5, 6, 7, 8, 9, 11]是最佳应答策略。
>>> * 对4,p[1, 2, 3, 5, 6, 7, 8, 9, 11]是最佳应答策略。
>>> * 对5,p[1, 2, 3, 4, 6, 7, 8, 9, 10, 11]是最佳应答策略。
>>> * 对6,p[1, 2, 3, 4, 5, 7, 8, 9, 11]是最佳应答策略。
>>> * 对7,p[1, 2, 3, 4, 5, 6, 8, 9, 11]是最佳应答策略。
>>> * 对8,p[1, 2, 3, 4, 5, 6, 7, 9, 11]是最佳应答策略。
>>> * 对9,p[1, 2, 3, 4, 5, 6, 7, 8, 11]是最佳应答策略。
>>> * 对10,p[12]是最佳应答策略。
>>> * 对11,p[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]是最佳应答策略。
>>> * 对12,p[5]是最佳应答策略。
>>> (非严格)占优策略:无。
>>> 互为最佳应答策略:2 – 3 | 2 – 4 | 2 – 5 | 2 – 6 | 2 – 7 | 2 – 8 | 2 – 9 | 2 – 11 | 3 – 4 | 3 – 5 | 3 – 6 | 3 – 7 | 3 – 8 | 3 – 9 | 3 – 11 | 4 – 5 | 4 – 6 | 4 – 7 | 4 – 8 | 4 – 9 | 4 – 11 | 5 – 6 | 5 – 7 | 5 – 8 | 5 – 9 | 5 – 11 | 6 – 7 | 6 – 8 | 6 – 9 | 6 – 11 | 7 – 8 | 7 – 9 | 7 – 11 | 8 – 9 | 8 – 11 | 9 – 11 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | devil |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 69100 | 68918 | 69136 | 75545 | 71928 | 68622 | 69136 | 69129 | 69136 | 61366 | 68695 | 27003 |
我的策略函数(编号10)的分数并不好,在p4与devil面前失分最多。
- 在p4面前失分是由于对方的严格设置,即每次都遵循“一报还一报”的策略,p4才会选择与我合作。我虽然倾向于与一报还一报者合作,却没有设置得那么严格,有的时候甚至会试探性地采取背叛,因此对方不愿意和我合作。
- 在devil面前失分,是由于devil策略被我判断成了“长时报复策略”。尽管恶魔选择与我合作仅仅是为了调戏我,但这被我判断成了,由于我过去多是合作,他才与我合作。我的判断的重点在于,合作的选择是难的,不像背叛那么安全,我要理解一个人为什么下定决心合作。但devil选择合作的理由恰恰相反——他不care丢分,只要能激怒对方就行。我的预测算法没有考虑到这种奇葩的存在。
对于p4和devil以外的策略,我丢分的原因在于,我设置的“一报还一报”的比例门槛是0.9,这就意味着,当别人并没有完全按照一报还一报的策略进行时,我仍然在选择合作,这损伤了我的分数。
3、完整代码
策略函数
copyimport random
# 策略集合 C合作 D背叛
def p1(i, me, him):
cooperate = True
if i > 0 and him[0] == 'D':
cooperate = False # If the partner betrays at first, cooperation will not exist.
elif i > 3: # I will cooperate in the first 4 games as long as the partner does not betray at first.
check, count_twenty, count_fifty, count_hundred = True, 0, 0, 0
for j in range(i - 2):
count = 0
for k in range(j, j + 2):
if him[k] == 'D': count += 1
if count > 1:
cooperate, check = False, False
break # If the partner betrays two or more times in any three consecutive games, cooperation will no longer continue.
if i > 20 and check:
for k in range(i - 20, i):
if him[k] == 'D': count_twenty += 1
if count_twenty > 1: cooperate, check = False, False # If the partner betrays two or more times in the last 20 games, cooperation will not continue until 20 games later.
if i > 50 and check:
for k in range(i - 50, i):
if him[k] == 'D': count_fifty += 1
if count_fifty > 2: cooperate, check = False, False # If the partner betrays three or more times in the last 50 games, cooperation will not continue until 50 games later.
if i > 100 and check:
for k in range(i - 100, i):
if him[k] == 'D': count_hundred += 1
if count_hundred > 4: cooperate = False # If the partner betrays five or more times in the last 100 games, cooperation will not continue until 100 games later.
if cooperate:
return 'C' # If cooperation, I will cooperate.
else:
return him[i - 1] # If no cooperation, I will do TFT.
def p2(i, me, him):
if i == 0:
return 'C'
elif him[i - 1] == 'C':
return 'C'
elif random.random() < 0.15:
return 'C'
else:
return 'D'
def p3(i, me, him):
if i == 0:
return 'C'
else:
if him[i - 1] == 'C':
return 'C'
else:
return 'D'
def p4(i, me, him):
if i == 0:
return 'C'
else:
test = 0
for tt in range(2, i):
if him[tt - 1] != me[tt - 2]:
test = 1 # 不是正向复读机
if test == 0:
return 'C'
if test == 1:
for t in range(2, i):
if him[t - 1] == me[t - 2]:
test = 2 # 不是负向复读机
if test == 1:
return 'D'
if test == 2:
for ttt in range(1, i - 1):
if him[ttt] == 'D': # 不是一直合作者
test = 3
if test == 2:
return 'D'
if test == 3:
for tttt in range(1, i - 1):
if him[tttt] == 'C': # 不是一直欺骗者
test = 4
if test == 3:
return 'D'
if test == 4:
p = 0
p = random.randint(0, 4)
if p == 1:
return 'C'
else:
return 'D'
def p5(i, me, him):
def threshold(me, him):
if len(me) == 0:
return 0.5
else:
ccnt = 0
dcnt = 0
if 'C' in me:
for i in range(len(me)):
if me[i] == 'C':
if him[i] == 'C':
ccnt += 1
else:
dcnt += 1
if ccnt + dcnt > 30:
return ccnt / (ccnt + dcnt)
return 0.5
if i == 0:
return 'C'
else:
if him[i - 1] == 'C' and me[i - 1] == 'C':
return 'C'
elif him[i - 1] == 'C' and me[i - 1] == 'D':
return 'D'
elif him[i - 1] == 'D' and me[i - 1] == 'D':
a = random.random()
if a < threshold(me, him):
return 'C'
else:
return 'D'
else:
return 'D'
def p6(i, me, him):
if i == 0 or i == 1:
return 'C'
else:
if him[i - 1] == him[i - 2] == 'D':
return 'D'
else:
return 'C'
def p7(i, me, him):
if i == 0:
return 'C'
else:
if him[i - 1] == 'C':
return 'C'
else:
return 'D'
def p8(i, me, him):
if i == 0 or i == 1:
return 'C'
else:
return him[i - 1]
def p9(i, me, him):
if i == 0:
return 'C'
else:
if him[i - 1] == 'C':
return 'C'
else:
return 'D'
def p10(i, me, him):
# guess his ploy
if i > 3:
flag = None
cnt1_1 = 0
cnt1_2 = 0
cnt2_1 = 0
cnt2_2 = 0
for j in range(i - 1):
if me[j - 1] == 'C':
cnt1_1 += 1
if me[j - 1] == him[j]:
cnt1_2 += 1
elif him[j] == 'C':
cnt2_1 += 1
if j > 2 and max(set(me), key=me.count) == him[j]:
cnt2_2 += 1
if 'D' not in him[2:]:
flag = 'innocent'
elif cnt1_2 / (cnt1_1 - 1) > 0.9 and cnt1_2 >= 2:
flag = 's-retri'
elif cnt2_1 > 0:
if cnt2_2 / cnt2_1 > 0.9:
flag = 'l-retri'
# my reaction
if i in [0, 1, 2, 3]:
return 'C' # elicit his ploy
else:
if flag == None:
return 'D'
elif flag == 'innocent':
return 'D'
elif flag in ['s-retri', 'l-retri']:
return 'C'
def p11(i, me, him):
if i <= 2:
return 'C'
# 初始三次均合作
else:
kindness = him.count('C') / len(him) # 计算对方历史友善度
if kindness > 0.5:
# 友善度较高,以牙还牙,倾向于合作
if him[-1] == 'D':
# 前一次背叛,根据前三次友善度随机背叛
betray_him = him[-3::].count('D') / 3
choice = random.random() + 0.1
if choice > betray_him:
return 'C'
else:
return 'D'
else:
# 前一次合作,选择合作
return 'C'
elif kindness > 0.1:
# 友善度较低,尝试合作,不行就永不合作
if him[-1] == 'D':
# 以牙还牙,比我更过分的就丧失信任
betray_him = him[-3::].count('D') / 3
betray_me = me[-3::].count('D') / 3
if betray_me < betray_him:
# 我前三次友善度更高,我不再信任
return 'D'
else:
# 我前三次友善度更低,我根据前三次友善度随机背叛
choice = random.random() + 0.1
if choice > betray_him:
return 'C'
else:
return 'D'
if him[-1] == 'C':
# 如果示好得到回应,根据前两次友善度合作
if me[-2] == 'C':
betray_him = him[-2::].count('D') / 3
choice = random.random() + 0.1
if choice > betray_him:
return 'C'
else:
return 'D'
if me[-2] == 'D':
# 如果对方主动合作,前一次合作就继续合作
return 'C'
else:
# 友善度过低,对方可能按照占优策略无脑背叛,选择背叛,小概率合作试探
if me[-3] == 'C' and 'D' not in him[-2::]:
# 试探合作得到极友善回应,继续合作
return 'C'
else:
luck = random.random()
if luck > 0.1:
if 'C' in him[-3::]:
# 存在友善表现,1/3概率合作去试探
if luck > 0.7:
return 'C'
else:
return 'D'
else:
# 十分不友善,选择背叛
return 'D'
else:
# 0.1的概率随机合作试探
return 'C'
def devil(i, me, him):
if i == 0:
return 'D'
else:
if him[i - 1] == 'C':
return 'D'
else:
return 'C'
博弈论问题
copyimport Peking_University.Game_theory.strategy as strategy
strategies = [strategy.p1, strategy.p2, strategy.p3,
strategy.p4, strategy.p5, strategy.p6,
strategy.p7, strategy.p8, strategy.p9,
strategy.p10, strategy.p11, strategy.devil]
outputF = open('./output.csv', 'w') # for scores
outputF2 = open('./output.txt', 'w') # for analysis
# 模拟多轮重复博弈
def game_dual(n, i, j):
me = []
me_score = 0
me_str = strategies[i-1]
him = []
him_score = 0
him_str = strategies[j-1]
for k in range(n):
# actions
me_react = me_str(k, me, him)
him_react = him_str(k, him, me)
me.append(me_react)
him.append(him_react)
# scores
if me_react == 'D' and him_react == 'D':
me_score += 1
him_score += 1
elif me_react == 'C' and him_react == 'D':
me_score += 0
him_score += 5
elif me_react == 'D' and him_react == 'C':
me_score += 5
him_score += 0
else:
me_score += 3
him_score += 3
return me_score, him_score
# 循环赛设定
def game(n, devil=False):
score_dict = {}
print('Game on... (%i rounds in all)' % n)
if devil == False:
end = 12
else:
end = 13
scores = [0 for i in range(end)]
for i in range(1, end):
for j in range(i+1, end):
me_score, him_score = game_dual(n, i, j)
score_dict[i, j] = [me_score, him_score]
print('%i v.s. %i: %i – %i' % (i, j, me_score, him_score))
scores[i] += me_score
scores[j] += him_score
outputF.write('devil = %s and n = %i\n' % (str(devil), n))
outputF2.write('*** devil = %s and n = %i ***\n' % (str(devil), n))
for i in range(1, end): # total scores of each one
outputF.write('%i,%i\n' % (i, scores[i]))
print('%i: %i' % (i, scores[i]))
scores_individuals = {}
for i in range(1, end):
scores_individuals[i] = {} # store how many points each one get from i
for key, value in score_dict.items():
for i in range(1, end):
if i in key:
i_index = key.index(i)
j = key[1 - i_index]
j_score = value[1 - i_index]
scores_individuals[i][j] = j_score
best_react_dict = {}
for key, value in scores_individuals.items():
best_reacted = [0, 0] # [j, j_score] (j reacted best against key, with a score of j_score)
for j, j_score in value:
if j_score > best_reacted[1]:
best_reacted = [j, j_score]
elif j_score == best_reacted[1]:
best_reacted.append(j)
best_reacted.append(j_score)
if best_reacted[0:2] == [0, 0]:
del best_reacted[0:2]
best_react_dict[key] = best_reacted
print('* 对%i,p%s是最佳应答策略。' % (key, best_reacted[0:-1:2]))
outputF2.write('* 对%i,p%s是最佳应答策略。\n' % (key, best_reacted[0:-1:2]))
print()
# 非严格占优策略
dominant = [1] + best_react_dict[1][0:-1:2]
for i in range(2, end):
next_range = best_react_dict[i][0:-1:2] + [i]
dominant = [x for x in dominant if x in next_range]
print('(非严格)占优策略:', end='')
print(dominant)
outputF2.write('(非严格)占优策略:')
if dominant == []:
outputF2.write('无。\n')
else:
for item in dominant:
outputF2.write('%i, ' % item)
outputF2.write('\n')
# 互为对方的最佳占优策略
reciprocal = []
for key, value in best_react_dict.items():
for j in range(0, len(value), 2):
if value[j] > key:
for k in range(0, len(best_react_dict[value[j]]), 2):
if key == best_react_dict[value[j]][k]:
reciprocal.append([key, value[j]])
print('互为最佳应答策略:', end = ' ')
print(reciprocal)
outputF2.write('互为最佳应答策略:')
for item in reciprocal:
a = item[0]
b = item[1]
outputF2.write('%i – %i | ' % (a,b))
outputF2.write('\n')
print('- ' * 20)
outputF2.write('- ' * 20)
outputF2.write('\n')
return score_dict
# 主程序
score_dict_whole = {0: {}, 1: {}}
for n in [1, 10, 100, 1000]:
print('无devil, n = %i' % n)
score_dict_whole[0][n] = game(n)
print('有devil, n = %i' % n)
score_dict_whole[1][n] = game(n, True)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具