并行多核体系结构基础——第一章知识点和课后习题
 多核体系结构的概述
多核体系结构的概述
第一章介绍了什么是并行多核体系,对并行计算机做了简单的介绍,但提出并行并不是越多越好,我们需要考虑种种因素。本章习题较为简单,简单理解和套公式即可。
知识点:
1.1多核体系的概念
多核体系结构是指在单一管芯上集成多个处理器核(core)的一种体系结构。处理器核也就是俗称的中央处理器(CPU)。处理器核或CPU通常是指能够独立地从至少一个指令流获取和执行指令的处理单元。
因此,核通常包括诸如取指单元、程序计数器、指令调度器、功能单元、寄存器等逻辑单元。
对许多人来说,与核紧密集成的小型存储器 一级高速缓存(LI Cache)被视为核的一部分。
对某些人来说,二级高速缓存(L2 Cache)被认为是核的一部分,因为它是核私有的。
术语“处理器”的使用也同样是不一致的,有时它用来指代集成核的管芯,有时是指CPU。
为了避免混淆,在本书中术语“核”仅包括CPU,而不包括L1和L2高速缓存;术语“处理器”指CPU,而不考虑特定的核;指代管芯或芯片(chip)时使用术语“处理器管芯”或“处理器芯片”。
下图给出了最近多核管芯的一个示例。图中显示了集成在一个管芯上的16个核,它 们共享8个L3高速缓存bank,这些bank通过交叉开关(crossbar)互连到核。请注意,该图隐含地将L1和L2高速缓存看作核的一部分。

并行体系结构是指这样一种体系结构,其将多个CPU紧密耦合,以便它们一起工作以解决单个问题。并行计算机通过将大量处理单元(CPU)组合成单个系统,获得以数量级提升的速度来更快地执行大量的计算。
向多核体系结构过渡的一个有利发展是晶体管的日益小型化。通过这种小型化,越来越多的晶体管可以封装在单个管芯中,这种晶体管集成的速度是惊人的。
能够在一个周期中处理多条指令的处理器被称为超标量处理器。在超标量处理器中增加流水线宽度还会遇到复杂性问题,其中处理指令所需逻辑电路的复杂性随着流水线宽度的增加而以平方量级增加(在某些情况下甚至更糟)。在21世纪头十年,功耗问题浮出水面。

是付出额外的编程代价以获得更好的性能,还是付出更少的编程代价保持不高的性能?
1.2并行计算机概述
人们使用并行计算机一个原因是与单个处理器系统提供的性能相比,并行计算机能够提供的绝对性能。另一个原因是它在成本调控的性能或功耗调控的性能方面更具吸引力。
并行计算机定义为:“并行计算机是一系列处理单元的集合,它们通过通信和协作以快速解决一个大的问题。”
几个术语:
①“通信”是指处理单元彼此发送数据。
通信机制的选择确定了两类重要的并行体系结构:共享存储系统,在处理单元上运行的并行任务通过读取和写入公共存储空间来通信; 或者消息传递系统,所有数据都是本地的,并行任务必须向彼此发送显式消息以传递数据。 通信介质(如使用什么互连网络来连接处理单元)也是确定通信延迟、吞吐量、可扩展性和 容错的重要问题。
②“协作”是指并行任务在执行过程中相对于其他任务的同步。
同步允许对操作进行排序,如要求一个任务在另一个任务开始计算之前完成某个计算,同步才能确保正确性。同步中的重要问题包括同步粒度(任务同步的时间和频度)以及同步机制(实现同步功能的操作序列)。这些问题会影响可扩展性和负载均衡属性。
③“快速解决一个大的问题”表示处理单元共同处理一个问题,其目标是性能。
有趣的是,可以选择使用通用或专用体系结构。可以针对特定的计算进行设计和调优,使得机器对于该类型计算能够快速和可扩展,但是对于其他类型的计算则可能较慢。
④“多处理器”来指代处理器的集合。
而不管这些处理器是在不同的芯片中实现还是在单个芯片中实现的,而多核特别地指代在单个芯片上实现的多个处理器。
1.3并行计算机分类
Flynn根据指令流和数据流的数量定义了并行计算机的分类,如下所示:
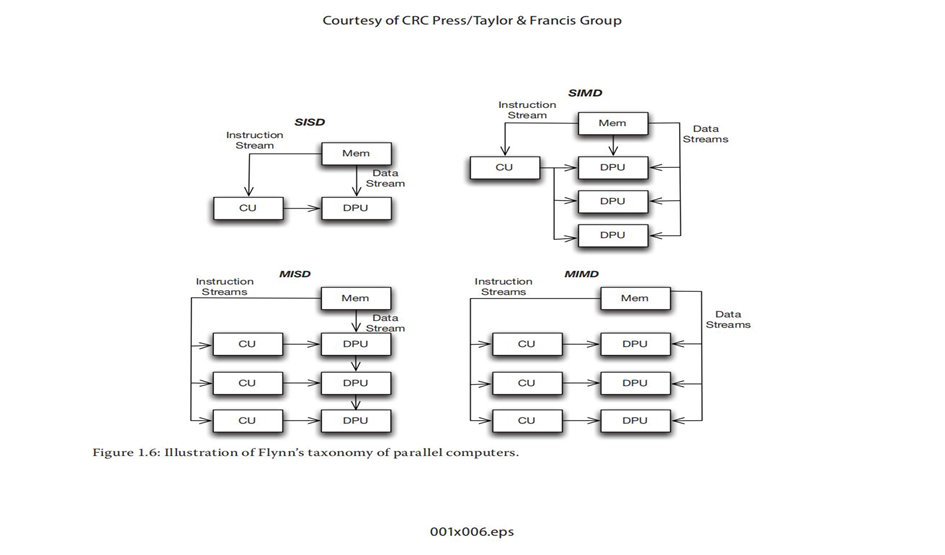
指令流是由单个程序计数器产生的指令序列,数据流是指令操作的存储空间地址。
SISD不被认为是并行体系结构,因为它只有一个指令流和一个数据流。然而,SISD可以利用指令并行性。
SIMD是一种并行体系结构,其中单个指令对多个数据进行操作。
MISD体系结构是多个处理单元从不同的指令流执行,并且数据从一个处理单元传递到下一个处理单元。
MIMD是当今大多数并行计算机使用的体系结构。它是最灵活的体系结构,因为其对指令流或数据流的数量没有限制(尽管与SIMD体系结构相比,它在用于执行单个计算任务的指令数量方面效率较低)。
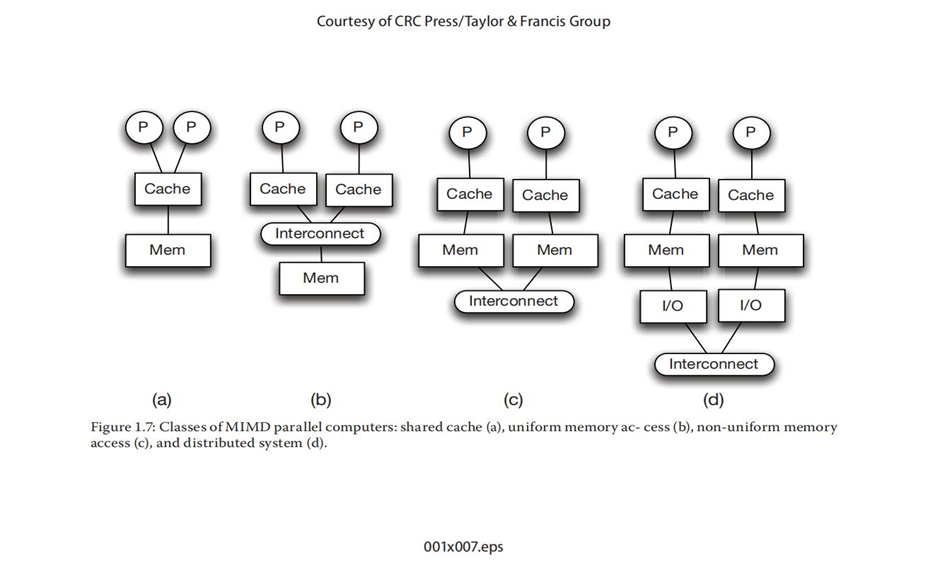
由于MIMD是最流行的并行计算机类型,我们将研究MIMD体系结构中处理器是如何物理互连的:
①图l.7a显示了一种体系结构,其中处理器共享某一级的高速缓存(通常是L2或L3高速缓存,但共享L1高速缓存也是可能的)
②专用高速缓存之间提供互连(见图l.7b)。这种体系结构通常称为对称多处理器(SMP)。在SMP体系结构中,不同的处理器共享存储器,并且对存储器具有大致相等的访问时间。
③图l.7c展示了每个处理器都有私有高速缓存和本地存储器的体系结构,但是硬件提供跨越所有本地存储器的互连以给岀单个存储器的抽象。然而,由于远端存储的访问时间比本地存储长,因此存储器访问延迟会有所不同。这种体系结构被称为非一致存储访问(NUMA)或分布式共享存储(DSM)。
④在图l.7d展示的体系结构中,每个处理器都是一个完整的节点,具有自己的高速缓存、 本地存储器和磁盘;并且通过I/O连接提供互连。因为I/O连接的延迟很大,所以硬件可能不会提供单个存储器的抽象(尽管软件层可以以相对较高的开销实现相同的抽象)。因此,它们通常被称为分布式计算机系统,或者更普遍地被称为集群。
1.4未来的多核体系结构
它将取决于不断评估的下一个可以摘到的“低挂果”。
即使能够非常成功地利用多核中的并行性,执行中的非并行部分也将日益成为瓶颈。为了说明这一点,了解Amdahl定律是有帮助的。

必记公式:
考试需硬记
Dynp=ACV2f中V在题目中表示阈值电压

课堂习题:
记住λ(特征尺寸)缩放给A(占比)、C(总电容)、V(阈值电压)、f(时钟频率)带来的影响

课后习题:
习题1

习题2

习题3

习题4

习题5


