MYSQL的innodb引擎中,聚簇索引和二级索引有什么不同
好了,我们先来接触第一个概念,就是二叉搜索树。一坨数字15、10、18、7、12、16、19,让你快速从中找到16,然后我们将它组织为一颗二叉搜索树,如下图所示: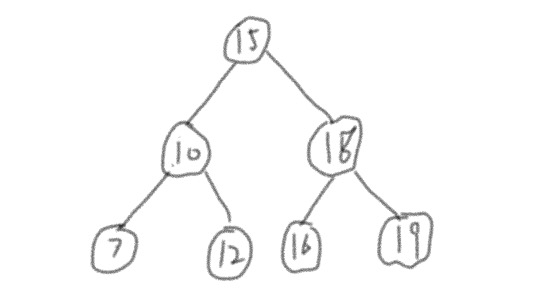
然后我们在寻找16的时候,第三次就锁定到16。
如果不用这种方法,而且我们从头15数字开始,怕是要循环到第六次才能锁定。当然,运气好从后往前,第二次就能找到。你运气不能总是这么好吧?所以搜索二叉树是稳定的均衡的方法。我们看到搜索二叉树有一个巨大的特点:一个节点永远比他的左子树大,永远比他的右子树小。
然后我们再来接触第二个概念,叫做平衡树。还是这一坨数字15、10、18、7、12、16、19,依然按照二叉搜索的定义去规划组织,但是结构却如下图: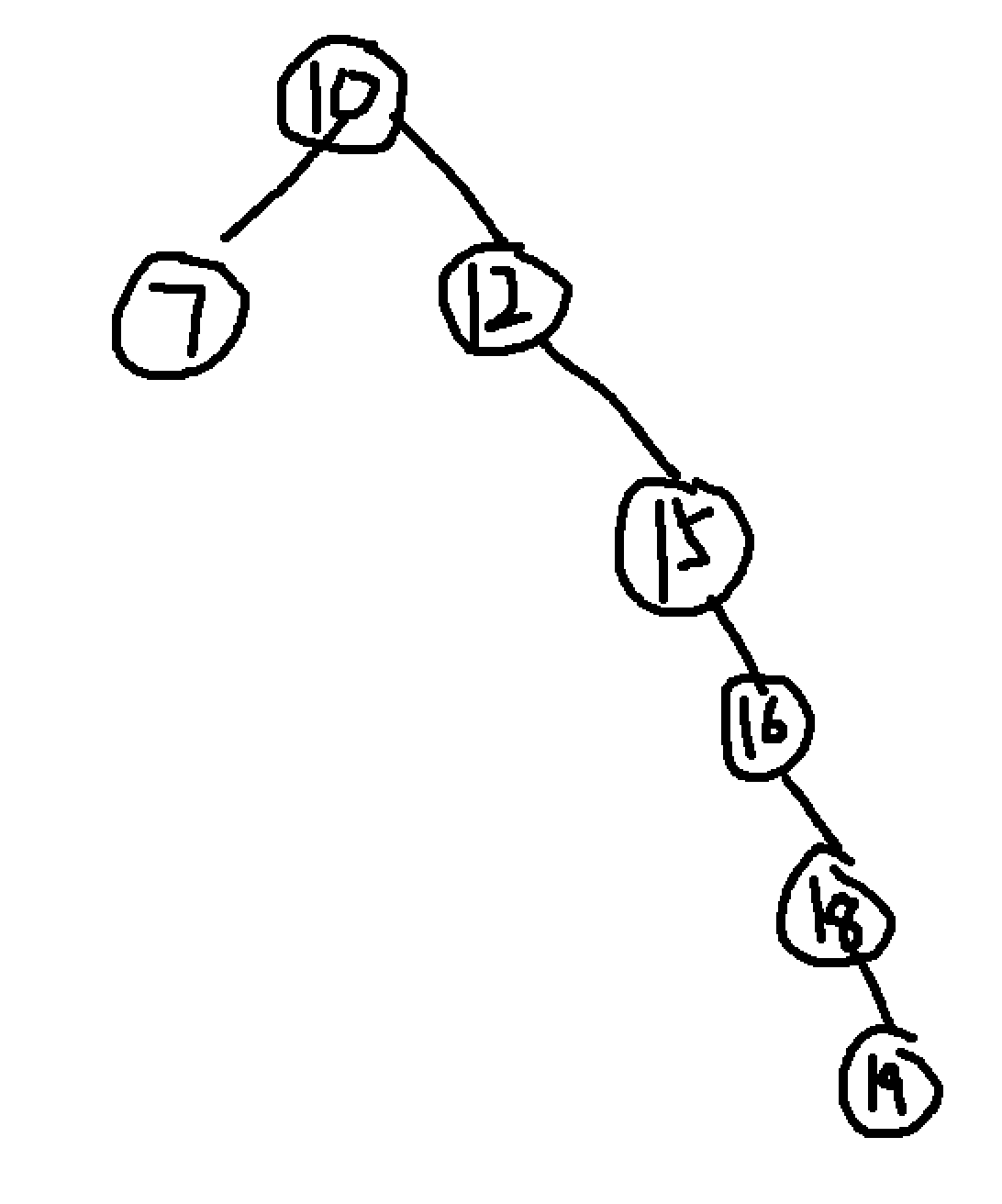
你现在找16的话,就需要4次才行,如果你要找19,似乎比从头循环查找也强不了多少。所以,这棵树需要平衡,什么算平衡呢?文章开头的树就标准的平衡树,平衡树有个巨大的特征,就是任何一个节点的左子树和他的右子树之间的高度差不能超过1,只要满足这个条件就是平衡的。
(.什么叫树的高度,就是整个树的层次,有几层就有多高,比如开头的那个树,高度就是3 )
所以,开头的那个图中二叉搜索树的全称应该叫做 平衡二叉搜索树 !二叉搜索树只有是平衡的,才能体现快速查找的意义,否则毫无意义!
下面我们来接触最后一种树,叫做多路平衡搜索树,细心的少年已经发现端倪了,少了两个字:二叉,多了两个字:多路。简单说,就是n叉了,而且还得依然保持平衡和搜索的特性,所以它应该向下面这样: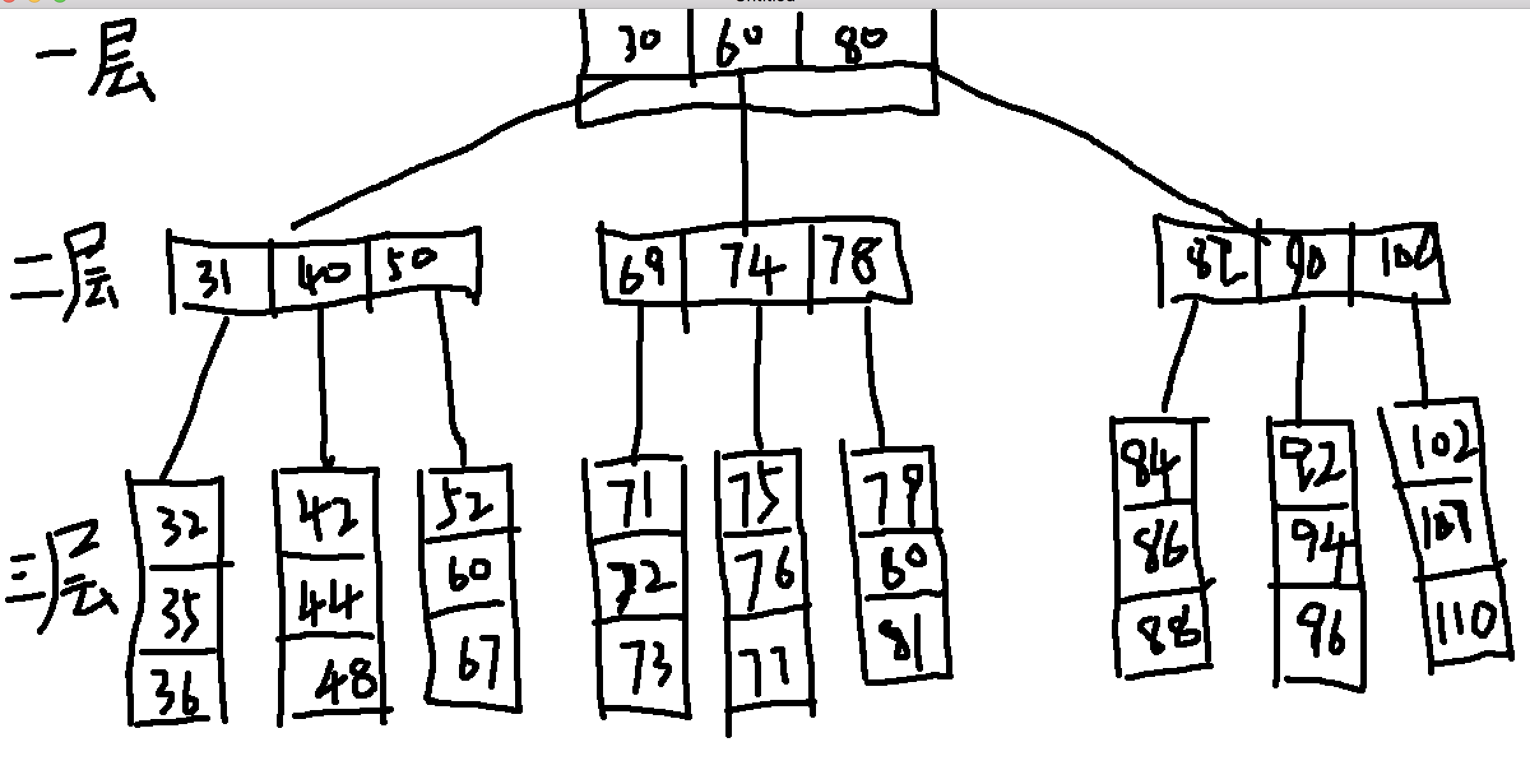
一层和二层节点叫做内部节点,第三层的节点叫做叶子节点。除此之外,很重要的一点,忘了在图中画出来,就是每相邻的两个叶子结点之间都通过指针互相指,这样可以在叶子结点之间迅速转移,快速定位范围!
好了下面要接触聚簇索引和二级索引了,在这里,先忘记掉主键索引、唯一索引、普通索引、哈希索引这些概念,你就当没有,不然你会很迷惑,这几个索引和聚簇以及二级索引之间没有什么必然联系,只是从不同维度分类不同而已。
聚簇索引中聚簇的意思就是顺序存储的意思,聚簇是按照主键的大小顺序来组织一行一行数据的,一个innodb表只能有一个聚簇索引。聚簇索引的叶子节点中除了保存主键key外,还直接保存了整条数据,这很重要!一定要记住!也就是说,当你通过主键索引查询到一次数据后,直接就可以获取到全部数据!然后由于聚簇索引是按照主键顺序来的,所以如果你利用聚簇索引进行范围查询,速度是非常快。比如上图中,叶子结点中的32,35,36等等,这都是主键id,与此同时,还保存了该主键id指向的整条数据。比如要查找主键id为32的记录,系统只需要执行三次查询就可以锁定到数据,而且可以顺带把整条数据也全部带走。
二级索引又叫辅助索引,就是除了聚簇索引外的,一个innodb表可以有多个二级索引。二级索引和聚簇索引的内部节点组织方式都是一样的,但是仅仅是在叶子节点上是不一样的。聚簇索引的叶子节点上直接保存了整条数据,但是二级索引在叶子节点上出了索引键值外,还保存该条记录的主键id,然后数据库再拿着这个主键id去数据库中进行查询,这个过程参考聚簇索引查找过程。还是id为32的数据,另外一列示username,值为huahua,你在username上创建了一个二级索引,那么当你使用select * from user where username=’huahua’查询的时候,查询到叶子结点的时候,会获取到该条记录的主键id为32,然后再拿这个32进行聚簇索引中的主键查询。所以,二级索引比主键索引慢,就是因为这个原因。
如果看了这些,你就应该明白为什么网上说mysql一定要给数据表创建一个主键id,这就是原因咯。但是实际上,即便是你不定义主键索引,mysql内部会优先从你的表里找一个唯一索引当主键索引,如果连唯一索引都没找到,mysql系统内部直接自定义一个主键索引,只不过你看不到也用不到。一定要记住聚簇索引的特征:按照顺序组织存储!这也就意味着如果你定义的主键不是自增的,而是自己系统生成,那么就不要用字符串,即便是数字,也得遵循一定的顺序生成,先到的一定要比后到的小,不然顺序乱了,突然插入一个小的主键,整个索引(也就是这棵多路平衡x叉树的部分地方必须要重新构建!这是十分耗费性能的)。
为什么说索引可以加速查询,但是会降低增加和删除的代价,因为它要维护这棵树,明白了吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号