
linux BASH shell
一. BASH shell的功能
- 命令编修能力 (history):
- 命令与文件补全功能: ([tab] 按键的好处)
- 命令别名配置功能: (alias)
- 工作控制、前景背景控制: (job control, foreground, background)
- 程序化脚本: (shell scripts)
- 通配符: (Wildcard)
- 当命令超长的时候使用"\"进行两行或者多行写入。
- Bash shell 的内建命令: type


[root@www ~]# type [-tpa] name 选项与参数: :不加任何选项与参数时,type 会显示出 name 是外部命令还是 bash 内建命令 -t :当加入 -t 参数时,type 会将 name 以底下这些字眼显示出他的意义: file :表示为外部命令; alias :表示该命令为命令别名所配置的名称; builtin :表示该命令为 bash 内建的命令功能; -p :如果后面接的 name 为外部命令时,才会显示完整文件名; -a :会由 PATH 变量定义的路径中,将所有含 name 的命令都列出来,包含 alias 范例一:查询一下 ls 这个命令是否为 bash 内建? [root@www ~]# type ls ls is aliased to `ls --color=tty' <==未加任何参数,列出 ls 的最主要使用情况 [root@www ~]# type -t ls alias <==仅列出 ls 运行时的依据 [root@www ~]# type -a ls ls is aliased to `ls --color=tty' <==最先使用 aliase ls is /bin/ls <==还有找到外部命令在 /bin/ls 范例二:那么 cd 呢? [root@www ~]# type cd cd is a shell builtin <==看到了吗? cd 是 shell 内建命令
二. 变量的取用与配置
1. 变量的取用
[root@www ~]# name=good [root@www ~]# echo $name good
2. 变量的配置
变量与变量内容以一个等号『=』来连结,如下所示: 『myname=good』 等号两边不能直接接空格符,如下所示为错误: 『myname = good』或『myname=good Tsai』 变量名称只能是英文字母与数字,但是开头字符不能是数字,如下为错误: 『2myname=good』 变量内容若有空格符可使用双引号『"』或单引号『'』将变量内容结合起来,但 双引号内的特殊字符如 $ 等,可以保有原本的特性,如下所示: 『var="lang is $LANG"』则『echo $var』可得『lang is en_US』 单引号内的特殊字符则仅为一般字符 (纯文本),如下所示: 『var='lang is $LANG'』则『echo $var』可得『lang is $LANG』 可用跳脱字符『 \ 』将特殊符号(如 [Enter], $, \, 空格符, '等)变成一般字符; 在一串命令中,还需要藉由其他的命令提供的信息,可以使用反单引号『`命令`』或 『$(命令)』。特别注意,那个 ` 是键盘上方的数字键 1 左边那个按键,而不是单引号! 例如想要取得核心版本的配置: 『version=`uname -r`』再『echo $version』可得『2.6.18-128.el5』 若该变量为扩增变量内容时,则可用 "$变量名称" 或 ${变量} 累加内容,如下所示: 『PATH="$PATH":/home/bin』 若该变量需要在其他子程序运行,则需要以 export 来使变量变成环境变量: 『export PATH』 通常大写字符为系统默认变量,自行配置变量可以使用小写字符,方便判断 (纯粹依照使用者兴趣与嗜好) ; 取消变量的方法为使用 unset :『unset 变量名称』例如取消 myname 的配置: 『unset myname』
3. 系统登录配额
[root@www ~]# ulimit [-SHacdfltu] [配额] 选项与参数: -H :hard limit ,严格的配置,必定不能超过这个配置的数值; -S :soft limit ,警告的配置,可以超过这个配置值,但是若超过则有警告信息。 在配置上,通常 soft 会比 hard 小,举例来说,soft 可配置为 80 而 hard 配置为 100,那么你可以使用到 90 (因为没有超过 100),但介于 80~100 之间时, 系统会有警告信息通知你! -a :后面不接任何选项与参数,可列出所有的限制额度; -c :当某些程序发生错误时,系统可能会将该程序在内存中的信息写成文件(除错用), 这种文件就被称为核心文件(core file)。此为限制每个核心文件的最大容量。 -f :此 shell 可以创建的最大文件容量(一般可能配置为 2GB)单位为 Kbytes -d :程序可使用的最大断裂内存(segment)容量; -l :可用于锁定 (lock) 的内存量 -t :可使用的最大 CPU 时间 (单位为秒) -u :单一用户可以使用的最大程序(process)数量。 范例一:列出你目前身份(假设为root)的所有限制数据数值 [root@www ~]# ulimit -a core file size (blocks, -c) 0 <==只要是 0 就代表没限制 data seg size (kbytes, -d) unlimited scheduling priority (-e) 0 file size (blocks, -f) unlimited <==可创建的单一文件的大小 pending signals (-i) 11774 max locked memory (kbytes, -l) 32 max memory size (kbytes, -m) unlimited open files (-n) 1024 <==同时可开启的文件数量 pipe size (512 bytes, -p) 8 POSIX message queues (bytes, -q) 819200 real-time priority (-r) 0 stack size (kbytes, -s) 10240 cpu time (seconds, -t) unlimited max user processes (-u) 11774 virtual memory (kbytes, -v) unlimited file locks (-x) unlimited 范例二:限制用户仅能创建 10MBytes 以下的容量的文件 [root@www ~]# ulimit -f 10240 [root@www ~]# ulimit -a file size (blocks, -f) 10240 <==最大量为10240Kbyes,相当10Mbytes [root@www ~]# dd if=/dev/zero of=123 bs=1M count=20 File size limit exceeded <==尝试创建 20MB 的文件,结果失败了!
4. env观察环境变量
- HOME
代表用户的家目录。还记得我们可以使用 cd ~ 去到自己的家目录吗?或者利用 cd 就可以直接回到用户家目录了。那就是取用这个变量啦~ 有很多程序都可能会取用到这个变量的值! - SHELL
告知我们,目前这个环境使用的 SHELL 是哪支程序? Linux 默认使用 /bin/bash 的啦! - HISTSIZE
这个与『历史命令』有关,亦即是, 我们曾经下达过的命令可以被系统记录下来,而记录的『笔数』则是由这个值来配置的。 - MAIL
当我们使用 mail 这个命令在收信时,系统会去读取的邮件信箱文件 (mailbox)。 - PATH
就是运行文件搜寻的路径啦~目录与目录中间以冒号(:)分隔, 由于文件的搜寻是依序由 PATH 的变量内的目录来查询,所以,目录的顺序也是重要的喔。 - LANG
这个重要!就是语系数据啰~很多信息都会用到他, 举例来说,当我们在启动某些 perl 的程序语言文件时,他会主动的去分析语系数据文件, 如果发现有他无法解析的编码语系,可能会产生错误喔!一般来说,我们中文编码通常是 zh_TW.Big5 或者是 zh_TW.UTF-8,这两个编码偏偏不容易被解译出来,所以,有的时候,可能需要修订一下语系数据。 这部分我们会在下个小节做介绍的! - RANDOM
这个玩意儿就是『随机随机数』的变量啦!目前大多数的 distributions 都会有随机数生成器,那就是 /dev/random 这个文件。 我们可以透过这个随机数文件相关的变量 ($RANDOM) 来随机取得随机数值喔。在 BASH 的环境下,这个 RANDOM 变量的内容,介于 0~32767 之间,所以,你只要 echo $RANDOM 时,系统就会主动的随机取出一个介于 0~32767 的数值。万一我想要使用 0~9 之间的数值呢?呵呵~利用 declare 宣告数值类型, 然后这样做就可以了:declare -i number=$RANDOM*10/32768 ; echo $number
范例一:列出目前的 shell 环境下的所有环境变量与其内容。 [root@www ~]# env HOSTNAME=www.vbird.tsai <== 这部主机的主机名 TERM=xterm <== 这个终端机使用的环境是什么类型 SHELL=/bin/bash <== 目前这个环境下,使用的 Shell 是哪一个程序? HISTSIZE=1000 <== 『记录命令的笔数』在 CentOS 默认可记录 1000 笔 USER=root <== 使用者的名称啊! LS_COLORS=no=00:fi=00:di=00;34:ln=00;36:pi=40;33:so=00;35:bd=40;33;01:cd=40;33;01: or=01;05;37;41:mi=01;05;37;41:ex=00;32:*.cmd=00;32:*.exe=00;32:*.com=00;32:*.btm=0 0;32:*.bat=00;32:*.sh=00;32:*.csh=00;32:*.tar=00;31:*.tgz=00;31:*.arj=00;31:*.taz= 00;31:*.lzh=00;31:*.zip=00;31:*.z=00;31:*.Z=00;31:*.gz=00;31:*.bz2=00;31:*.bz=00;3 1:*.tz=00;31:*.rpm=00;31:*.cpio=00;31:*.jpg=00;35:*.gif=00;35:*.bmp=00;35:*.xbm=00 ;35:*.xpm=00;35:*.png=00;35:*.tif=00;35: <== 一些颜色显示 MAIL=/var/spool/mail/root <== 这个用户所取用的 mailbox 位置 PATH=/sbin:/usr/sbin:/bin:/usr/bin:/usr/X11R6/bin:/usr/local/bin:/usr/local/sbin: /root/bin <== 不再多讲啊!是运行文件命令搜寻路径 INPUTRC=/etc/inputrc <== 与键盘按键功能有关。可以配置特殊按键! PWD=/root <== 目前用户所在的工作目录 (利用 pwd 取出!) LANG=en_US <== 这个与语系有关,底下会再介绍! HOME=/root <== 这个用户的家目录啊! _=/bin/env <== 上一次使用的命令的最后一个参数(或命令本身)
5. set观察所有变量
[root@www ~]# set BASH=/bin/bash <== bash 的主程序放置路径 BASH_VERSINFO=([0]="3" [1]="2" [2]="25" [3]="1" [4]="release" [5]="i686-redhat-linux-gnu") <== bash 的版本啊! BASH_VERSION='3.2.25(1)-release' <== 也是 bash 的版本啊! COLORS=/etc/DIR_COLORS.xterm <== 使用的颜色纪录文件 COLUMNS=115 <== 在目前的终端机环境下,使用的字段有几个字符长度 HISTFILE=/root/.bash_history <== 历史命令记录的放置文件,隐藏档 HISTFILESIZE=1000 <== 存起来(与上个变量有关)的文件之命令的最大纪录笔数。 HISTSIZE=1000 <== 目前环境下,可记录的历史命令最大笔数。 HOSTTYPE=i686 <== 主机安装的软件主要类型。我们用的是 i686 兼容机器软件 IFS=$' \t\n' <== 默认的分隔符 LINES=35 <== 目前的终端机下的最大行数 MACHTYPE=i686-redhat-linux-gnu <== 安装的机器类型 MAILCHECK=60 <== 与邮件有关。每 60 秒去扫瞄一次信箱有无新信! OLDPWD=/home <== 上个工作目录。我们可以用 cd - 来取用这个变量。 OSTYPE=linux-gnu <== 操作系统的类型! PPID=20025 <== 父程序的 PID (会在后续章节才介绍) PS1='[\u@\h \W]\$ ' <== PS1 就厉害了。这个是命令提示字符,也就是我们常见的 [root@www ~]# 或 [dmtsai ~]$ 的配置值啦!可以更动的! PS2='> ' <== 如果你使用跳脱符号 (\) 第二行以后的提示字符也 name=VBird <== 刚刚配置的自定义变量也可以被列出来喔! $ <== 目前这个 shell 所使用的 PID ? <== 刚刚运行完命令的回传值。
PS1:(提示字符的配置)
这是 PS1 (数字的 1 不是英文字母),这个东西就是我们的『命令提示字符』喔! 当我们每次按下 [Enter] 按键去运行某个命令后,最后要再次出现提示字符时, 就会主动去读取这个变量值了。上头 PS1 内显示的是一些特殊符号,这些特殊符号可以显示不同的信息, 每个 distributions 的 bash 默认的 PS1 变量内容可能有些许的差异,不要紧,『习惯你自己的习惯』就好了。 你可以用 man bash (注3)去查询一下 PS1 的相关说明,以理解底下的一些符号意义。
- \d :可显示出『星期 月 日』的日期格式,如:"Mon Feb 2"
- \H :完整的主机名。举例来说,鸟哥的练习机为『www.vbird.tsai』
- \h :仅取主机名在第一个小数点之前的名字,如鸟哥主机则为『www』后面省略
- \t :显示时间,为 24 小时格式的『HH:MM:SS』
- \T :显示时间,为 12 小时格式的『HH:MM:SS』
- \A :显示时间,为 24 小时格式的『HH:MM』
- \@ :显示时间,为 12 小时格式的『am/pm』样式
- \u :目前使用者的账号名称,如『root』;
- \v :BASH 的版本信息,如鸟哥的测试主板本为 3.2.25(1),仅取『3.2』显示
- \w :完整的工作目录名称,由根目录写起的目录名称。但家目录会以 ~ 取代;
- \W :利用 basename 函数取得工作目录名称,所以仅会列出最后一个目录名。
- \# :下达的第几个命令。
- \$ :提示字符,如果是 root 时,提示字符为 # ,否则就是 $ 啰~
6. 别名配置和取消
[root@study ~]# type -a vi vi 是 /usr/bin/vi [root@study ~]# alias vi='vim' [root@study ~]# type -a vi vi 是 `vim' 的别名 vi 是 /usr/bin/vi [root@study ~]# unalias vi [root@study ~]# type -a vi vi 是 /usr/bin/vi [root@study ~]#
7. history
默认的bash设置中,在使用history命令查看历史命令的时候,不显示命令执行的时间,通过增加HISTTIMEFORMAT变量可以时间记录历史命令的功能。 设置方法: 在/etc/profile 或者 /etc/bashrc 里面加入下面2行就可以了,这样可以记录每个用户执行的命令了。 HISTTIMEFORMAT="%Y-%m-%d %H:%M:%S " export HISTTIMEFORMAT 注:HISTTIMEFORMAT的格式你可以自己定义,定义成你想要的格式。具体格式可以参照date命令。例如用"%Y-%m-%d %H:%M:%S "格式,"%s " 按照unix时间戳的格式显示。 ———————————————— 版权声明:本文为CSDN博主「diy534」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/diy534/article/details/7243532
[root@www ~]# history [n] [root@www ~]# history [-c] [root@www ~]# history [-raw] histfiles 选项与参数: n :数字,意思是『要列出最近的 n 笔命令行表』的意思! -c :将目前的 shell 中的所有 history 内容全部消除 -a :将目前新增的 history 命令新增入 histfiles 中,若没有加 histfiles , 则默认写入 ~/.bash_history -r :将 histfiles 的内容读到目前这个 shell 的 history 记忆中; -w :将目前的 history 记忆内容写入 histfiles 中!
8. read
要读取来自键盘输入的变量,就是用 read 这个命令了。
[root@www ~]# read [-pt] variable 选项与参数: -p :后面可以接提示字符! -t :后面可以接等待的『秒数!』这个比较有趣~不会一直等待使用者!
[root@study study]# echo $name [root@study study]# read name wangzengyi [root@study study]# echo $name wangzengyi [root@study study]# read -t 30 -p ">>>>" name >>>>jet [root@study study]# echo $name jet [root@study study]#
9. declare / typeset
作用:宣告变量类型。
[root@www ~]# declare [-aixr] variable 选项与参数: -a :将后面名为 variable 的变量定义成为数组 (array) 类型 -i :将后面名为 variable 的变量定义成为整数数字 (integer) 类型 -x :用法与 export 一样,就是将后面的 variable 变成环境变量; -r :将变量配置成为 readonly 类型,该变量不可被更改内容,也不能 unset
范例一:让变量 sum 进行 100+300+50 的加总结果 [root@www ~]# sum=100+300+50 [root@www ~]# echo $sum 100+300+50 <==咦!怎么没有帮我计算加总?因为这是文字型态的变量属性啊! [root@www ~]# declare -i sum=100+300+50 [root@www ~]# echo $sum 450 #变量类型默认为『字符串』,所以若不指定变量类型,则 1+2 为一个『字符串』而不是『计算式』。 所以上述第一个运行的结果才会出现那个情况的; #bash 环境中的数值运算,默认最多仅能到达整数形态,所以 1/3 结果是 0; 范例二:将 sum 变成环境变量 [root@www ~]# declare -x sum [root@www ~]# export | grep sum declare -ix sum="450" <==果然出现了!包括有 i 与 x 的宣告! 范例三:让 sum 变成只读属性,不可更动! [root@www ~]# declare -r sum [root@www ~]# sum=tesgting -bash: sum: readonly variable <==不能改这个变量了! 范例四:让 sum 变成非环境变量的自定义变量吧! [root@www ~]# declare +x sum <== 将 - 变成 + 可以进行『取消』动作 [root@www ~]# declare -p sum <== -p 可以单独列出变量的类型 declare -ir sum="450" <== 看吧!只剩下 i, r 的类型,不具有 x 了!
10. 数组(arry)变量类型
数组的概念比较类似于Python中的列表,通过下标可以增加或者取值。
var[index]=content
[root@study study]# name[1]=zhangsan [root@study study]# name[2]=lisi [root@study study]# name[3]=wangwu [root@study study]# echo ${name[1]} zhangsan [root@study study]# name[0]=no [root@study study]# echo ${name[0]} no [root@study study]#
11. locale
查看语系变量
[root@study study]# locale -a | head -5 #加-a参数是查看系统支持的语系,这些语系文件都放置在: /usr/lib/locale/ 这个目录中。 aa_DJ aa_DJ.iso88591 aa_DJ.utf8 aa_ER aa_ER@saaho [root@study study]# locale #不加参数查看系统当前使用的语系 LANG=zh_CN.UTF-8 LC_CTYPE="zh_CN.UTF-8" LC_NUMERIC="zh_CN.UTF-8" LC_TIME="zh_CN.UTF-8" LC_COLLATE="zh_CN.UTF-8" LC_MONETARY="zh_CN.UTF-8" LC_MESSAGES="zh_CN.UTF-8" LC_PAPER="zh_CN.UTF-8" LC_NAME="zh_CN.UTF-8" LC_ADDRESS="zh_CN.UTF-8" LC_TELEPHONE="zh_CN.UTF-8" LC_MEASUREMENT="zh_CN.UTF-8" LC_IDENTIFICATION="zh_CN.UTF-8" LC_ALL= [root@study study]#
12. 变量的删除
| 变量配置方式 | 说明 |
| ${变量#关键词} ${变量##关键词} |
若变量内容从头开始的数据符合『关键词』,则将符合的最短数据删除 若变量内容从头开始的数据符合『关键词』,则将符合的最长数据删除 |
| ${变量%关键词} ${变量%%关键词} |
若变量内容从尾向前的数据符合『关键词』,则将符合的最短数据删除 若变量内容从尾向前的数据符合『关键词』,则将符合的最长数据删除 |
| ${变量/旧字符串/新字符串} ${变量//旧字符串/新字符串} |
若变量内容符合『旧字符串』则『第一个旧字符串会被新字符串取代』 若变量内容符合『旧字符串』则『全部的旧字符串会被新字符串取代』 |
13. 变量的检查与替换
| 变量配置方式 | str 没有配置 | str 为空字符串 | str 已配置非为空字符串 |
| var=${str-expr} | var=expr | var= | var=$str |
| var=${str:-expr} | var=expr | var=expr | var=$str |
| var=${str+expr} | var= | var=expr | var=expr |
| var=${str:+expr} | var= | var= | var=expr |
| var=${str=expr} | str=expr var=expr |
str 不变 var= |
str 不变 var=$str |
| var=${str:=expr} | str=expr var=expr |
str=expr var=expr |
str 不变 var=$str |
| var=${str?expr} | expr 输出至 stderr | var= | var=$str |
| var=${str:?expr} | expr 输出至 stderr | expr 输出至 stderr | var=$str |
四. BASH shell
1. 路径与命令搜寻顺序
- 以相对/绝对路径运行命令,例如『 /bin/ls 』或『 ./ls 』;
- 由 alias 找到该命令来运行;
- 由 bash 内建的 (builtin) 命令来运行;
- 透过 $PATH 这个变量的顺序搜寻到的第一个命令来运行。
tips:通过type -a [command] 可以查询命令的搜寻顺序。
2. 进站画面与引导信息
/etc/issue #终端进站前画面
/etc/issue.net #远程用户进展前画面
/etc/motd #用户进站后的引导信息
1 \d 本地端时间的日期; 2 \l 显示第几个终端机接口; 3 \m 显示硬件的等级 (i386/i486/i586/i686...); 4 \n 显示主机的网络名称; 5 \o 显示 domain name; 6 \r 操作系统的版本 (相当于 uname -r) 7 \t 显示本地端时间的时间; 8 \s 操作系统的名称; 9 \v 操作系统的版本。
3.BASH环境的配置文件
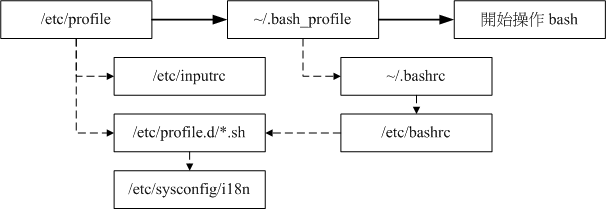
在开始介绍 bash 的配置文件前,我们一定要先知道的就是 login shell 与 non-login shell! 重点在于有没有输入账号和密码去登陆。
- login shell:取得 bash 时需要完整的登陆流程的,就称为 login shell。举例来说,你要由 tty1 ~ tty6 登陆,需要输入用户的账号与密码,此时取得的 bash 就称为『 login shell 』,login shell 读取这两个配置文件:
- /etc/profile:这是系统整体的配置,你最好不要修改这个文件,这个文件配置的主要变量有:
-
- PATH:会依据 UID 决定 PATH 变量要不要含有 sbin 的系统命令目录;
- MAIL:依据账号配置好使用者的 mailbox 到 /var/spool/mail/账号名;
- USER:根据用户的账号配置此一变量内容;
- HOSTNAME:依据主机的 hostname 命令决定此一变量内容;
- HISTSIZE:历史命令记录笔数 ;
- 呼叫/etc/inputrc:此文件定义 bash 的热键、[tab]要不要有声音等等。建议不要改动。
- 呼叫/etc/profile.d/*.sh:这个目录底下的文件规范了 bash 操作接口的颜色、 语系、ll 与 ls 命令的命令别名、vi 的命令别名、which 的命令别名等等。如果你需要帮所有使用者配置一些共享的命令别名时, 可以在这个目录底下自行创建扩展名为 .sh 的文件,并将所需要的数据写入即可。
- 呼叫/etc/sysconfig/i18n:这个文件是由 /etc/profile.d/lang.sh 呼叫进来的!这也是我们决定 bash 默认使用何种语系的重要配置文件!
- bash 在读完了整体环境配置的 /etc/profile 并藉此呼叫其他配置文件后,接下来则是会读取使用者的个人配置文件。~/.bash_profile 或 ~/.bash_login 或 ~/.profile:属于使用者个人配置:
- 其实 bash 的 login shell 配置只会读取上面三个文件的其中一个, 而读取的顺序则是依照上面的顺序。也就是说,如果 ~/.bash_profile 存在,那么其他两个文件不论有无存在,都不会被读取。 如果 ~/.bash_profile 不存在才会去读取 ~/.bash_login,而前两者都不存在才会读取 ~/.profile 。
-
.bash_profile内容
[root@www ~]# cat ~/.bash_profile # .bash_profile # Get the aliases and functions if [ -f ~/.bashrc ]; then <==底下这三行在判断并读取 ~/.bashrc . ~/.bashrc fi # User specific environment and startup programs PATH=$PATH:$HOME/bin <==底下这几行在处理个人化配置 export PATH unset USERNAME
- 下图为login shell 配置文件的加载顺序:
-
- 不注销使得环境变量生效的方法
-
[root@www ~]# source 配置文件档名 范例:将家目录的 ~/.bashrc 的配置读入目前的 bash 环境中 [root@www ~]# source ~/.bashrc <==底下这两个命令是一样的! [root@www ~]# . ~/.bashrc
-
- 不注销使得环境变量生效的方法
- non-login shell:取得 bash 接口的方法不需要重复登陆的举动,举例来说,(1)你以 X window 登陆 Linux 后, 再以 X 的图形化接口启动终端机,此时那个终端接口并没有需要再次的输入账号与密码,那个 bash 的环境就称为 non-login shell了。(2)你在原本的 bash 环境下再次下达 bash 这个命令,同样的也没有输入账号密码, 那第二个 bash (子程序) 也是 non-login shell 。
- ~/.bashrc (non-login shell 会读)
-
[root@www ~]# cat ~/.bashrc # .bashrc # User specific aliases and functions alias rm='rm -i' <==使用者的个人配置 alias cp='cp -i' alias mv='mv -i' # Source global definitions if [ -f /etc/bashrc ]; then <==整体的环境配置 . /etc/bashrc fi
-
/etc/bashrc 帮我们的 bash 定义出底下的数据:
- 依据不同的 UID 规范出 umask 的值;
- 依据不同的 UID 规范出提示字符 (就是 PS1 变量);
- 呼叫 /etc/profile.d/*.sh 的配置。
- 不小心删除了~/.bashrc,会出现什么现象,如何解决。
- 出现的现象是:命令提示符变成了 "-bash-3.2$"。
- 解决办法:复制 /etc/skel/.bashrc 到你的家目录,再修订一下你所想要的内容, 并使用 source 去呼叫 ~/.bashrc 。
- 其他配置文件介绍:
- ~/.bash_history:默认历史命令就记录在这里,而这个文件能够记录几笔数据,则与 HISTFILESIZE 这个变量有关啊。每次登陆 bash 后,bash 会先读取这个文件,将所有的历史命令读入内存, 因此,当我们登陆 bash 后就可以查知上次使用过哪些命令。
- ~/.bash_logout:这个文件则记录了『当我注销 bash 后,系统再帮我做完什么动作后才离开』。
4. 通配符与特殊符号
[root@www ~]# LANG=C <==由于与编码有关,先配置语系一下 范例一:找出 /etc/ 底下以 cron 为开头的档名 [root@www ~]# ll -d /etc/cron* <==加上 -d 是为了仅显示目录而已 范例二:找出 /etc/ 底下文件名『刚好是五个字母』的文件名 [root@www ~]# ll -d /etc/????? <==由于 ? 一定有一个,所以五个 ? 就对了 范例三:找出 /etc/ 底下文件名含有数字的文件名 [root@www ~]# ll -d /etc/*[0-9]* <==记得中括号左右两边均需 * 范例四:找出 /etc/ 底下,档名开头非为小写字母的文件名: [root@www ~]# ll -d /etc/[^a-z]* <==注意中括号左边没有 * 范例五:将范例四找到的文件复制到 /tmp 中 [root@www ~]# cp -a /etc/[^a-z]* /tmp
| 符号 | 意义 |
| * | 代表『 0 个到无穷多个』任意字符 |
| ? | 代表『一定有一个』任意字符 |
| [ ] | 同样代表『一定有一个在括号内』的字符(非任意字符)。例如 [abcd] 代表『一定有一个字符, 可能是 a, b, c, d 这四个任何一个』 |
| [ - ] | 若有减号在中括号内时,代表『在编码顺序内的所有字符』。例如 [0-9] 代表 0 到 9 之间的所有数字,因为数字的语系编码是连续的! |
| [^ ] | 若中括号内的第一个字符为指数符号 (^) ,那表示『反向选择』,例如 [^abc] 代表 一定有一个字符,只要是非 a, b, c 的其他字符就接受的意思。 |
| 符号 | 内容 |
| # | 批注符号:这个最常被使用在 script 当中,视为说明!在后的数据均不运行 |
| \ | 跳脱符号:将『特殊字符或通配符』还原成一般字符 |
| | | 管线 (pipe):分隔两个管线命令的界定(后两节介绍); |
| ; | 连续命令下达分隔符:连续性命令的界定 (注意!与管线命令并不相同) |
| ~ | 用户的家目录 |
| $ | 取用变量前导符:亦即是变量之前需要加的变量取代值 |
| & | 工作控制 (job control):将命令变成背景下工作 |
| ! | 逻辑运算意义上的『非』 not 的意思! |
| / | 目录符号:路径分隔的符号 |
| >, >> | 数据流重导向:输出导向,分别是『取代』与『累加』 |
| <, << | 数据流重导向:输入导向 (这两个留待下节介绍) |
| ' ' | 单引号,不具有变量置换的功能 |
| " " | 具有变量置换的功能! |
| ` ` | 两个『 ` 』中间为可以先运行的命令,亦可使用 $( ) |
| ( ) | 在中间为子 shell 的起始与结束 |
| { } | 在中间为命令区块的组合! |
5. 终端机的环境配置
目前linux的环境配置已经非常完美,咱们不要画蛇添足的去改它,但是咱们可以了解下原理。
| 组合按键 | 运行结果 |
| Ctrl + C | 终止目前的命令 |
| Ctrl + D | 输入结束 (EOF),例如邮件结束的时候; |
| Ctrl + M | 就是 Enter 啦! |
| Ctrl + S | 暂停屏幕的输出 |
| Ctrl + Q | 恢复屏幕的输出 |
| Ctrl + U | 在提示字符下,将整列命令删除 |
| Ctrl + Z | 『暂停』目前的命令 |
[root@www ~]# stty [-a] 选项与参数: -a :将目前所有的 stty 参数列出来; 范例一:列出所有的按键与按键内容 [root@www ~]# stty -a speed 38400 baud; rows 24; columns 80; line = 0; intr = ^C; quit = ^\; erase = ^?; kill = ^U; eof = ^D; eol = <undef>; eol2 = <undef>; swtch = <undef>; start = ^Q; stop = ^S; susp = ^Z; rprnt = ^R; werase = ^W; lnext = ^V; flush = ^O; min = 1; time = 0; ....(以下省略).... # eof : End of file 的意思,代表『结束输入』。 # erase : 向后删除字符, # intr : 送出一个 interrupt (中断) 的讯号给目前正在 run 的程序; # kill : 删除在目前命令列上的所有文字; # quit : 送出一个 quit 的讯号给目前正在 run 的程序; # start : 在某个程序停止后,重新启动他的 output # stop : 停止目前屏幕的输出; # susp : 送出一个 terminal stop 的讯号给正在 run 的程序。 # 修改方法介绍: [root@www ~]# stty erase ^h #用ctrl+h进行字符删除。
五. 数据流重导向
1. 标准输入、标准输出、标准错误输出
- 标准输入 (stdin) :代码为 0 ,使用 < 或 << ;
-
标准输入范例
#范例1 [root@www ~]# cat > catfile < ~/.bashrc [root@www ~]# ll catfile ~/.bashrc -rw-r--r-- 1 root root 194 Sep 26 13:36 /root/.bashrc -rw-r--r-- 1 root root 194 Feb 6 18:29 catfile # 注意看,这两个文件的大小会一模一样!几乎像是使用 cp 来复制一般! #范例2 [root@www ~]# cat > catfile << "eof" > This is a test. > OK now stop > eof <==输入这关键词,立刻就结束而不需要输入 [ctrl]+d [root@www ~]# cat catfile This is a test. OK now stop <==只有这两行,不会存在关键词那一行!
-
- 标准输出 (stdout):代码为 1 ,使用 > 或 >> ;
- 标准错误输出(stderr):代码为 2 ,使用 2> 或 2>> ;
-
标准输出范例
# 将错误的和正确的结果分别输出到不同文件 [dmtsai@www ~]$ find /home -name .bashrc > list_right 2> list_error # 将错误的数据丢弃,屏幕上显示正确的数据 [dmtsai@www ~]$ find /home -name .bashrc 2> /dev/null /home/dmtsai/.bashrc <==只有 stdout 会显示到屏幕上, stderr 被丢弃了 # 将命令的数据全部写入名为 list 的文件中 [dmtsai@www ~]$ find /home -name .bashrc > list 2> list <==错误 [dmtsai@www ~]$ find /home -name .bashrc > list 2>&1 <==正确 [dmtsai@www ~]$ find /home -name .bashrc &> list <==正确
-
2. 命令运行的判断依据
- 命令连续运行,在命令和命令之间使用";"。
- $?(命令回传值)与&&或||
-
范例
#例题: #以 ls 测试 /tmp/vbirding 是否存在,若存在则显示 "exist" ,若不存在,则显示 "not exist"! #答:这又牵涉到逻辑判断的问题,如果存在就显示某个数据,若不存在就显示其他数据,那我可以这样做: ls /tmp/vbirding && echo "exist" || echo "not exist"
-
命令下达情况 说明 cmd1 && cmd2 1. 若 cmd1 运行完毕且正确运行($?=0),则开始运行 cmd2。
2. 若 cmd1 运行完毕且为错误 ($?≠0),则 cmd2 不运行。cmd1 || cmd2 1. 若 cmd1 运行完毕且正确运行($?=0),则 cmd2 不运行。
2. 若 cmd1 运行完毕且为错误 ($?≠0),则开始运行 cmd2。
-
六.管线命令(pipe)
1. 管线命令的特点
- 管线命令仅会处理 standard output,对于 standard error output 会予以忽略
- 管线命令必须要能够接受来自前一个命令的数据成为 standard input 继续处理才行。
2.摘取命令
cut命令
[root@www ~]# cut -d'分隔字符' -f fields <==用于有特定分隔字符 [root@www ~]# cut -c 字符区间 <==用于排列整齐的信息 选项与参数: -d :后面接分隔字符。与 -f 一起使用; -f :依据 -d 的分隔字符将一段信息分割成为数段,用 -f 取出第几段的意思; -c :以字符 (characters) 的单位取出固定字符区间;
范例一:将 PATH 变量取出,我要找出第五个路径。 [root@www ~]# echo $PATH /bin:/usr/bin:/sbin:/usr/sbin:/usr/local/bin:/usr/X11R6/bin:/usr/games: # 1 | 2 | 3 | 4 | 5 | 6 | 7 [root@www ~]# echo $PATH | cut -d ':' -f 5 # 如同上面的数字显示,我们是以『 : 』作为分隔,因此会出现 /usr/local/bin # 那么如果想要列出第 3 与第 5 呢?,就是这样: [root@www ~]# echo $PATH | cut -d ':' -f 3,5 范例二:将 export 输出的信息,取得第 12 字符以后的所有字符串 [root@www ~]# export declare -x HISTSIZE="1000" declare -x INPUTRC="/etc/inputrc" declare -x KDEDIR="/usr" declare -x LANG="zh_TW.big5" .....(其他省略)..... # 注意看,每个数据都是排列整齐的输出!如果我们不想要『 declare -x 』时, # 就得这么做: [root@www ~]# export | cut -c 12- HISTSIZE="1000" INPUTRC="/etc/inputrc" KDEDIR="/usr" LANG="zh_TW.big5" .....(其他省略)..... # 知道怎么回事了吧?用 -c 可以处理比较具有格式的输出数据! # 我们还可以指定某个范围的值,例如第 12-20 的字符,就是 cut -c 12-20 等等! 范例三:用 last 将显示的登陆者的信息中,仅留下用户大名 [root@www ~]# last root pts/1 192.168.201.101 Sat Feb 7 12:35 still logged in root pts/1 192.168.201.101 Fri Feb 6 12:13 - 18:46 (06:33) root pts/1 192.168.201.254 Thu Feb 5 22:37 - 23:53 (01:16) # last 可以输出『账号/终端机/来源/日期时间』的数据,并且是排列整齐的 [root@www ~]# last | cut -d ' ' -f 1 # 由输出的结果我们可以发现第一个空白分隔的字段代表账号,所以使用如上命令: # 但是因为 root pts/1 之间空格有好几个,并非仅有一个,所以,如果要找出 # pts/1 其实不能以 cut -d ' ' -f 1,2 喔!输出的结果会不是我们想要的。
grep命令
[root@www ~]# grep [-acinv] [--color=auto] '搜寻字符串' filename 选项与参数: -a :将 binary 文件以 text 文件的方式搜寻数据 -c :计算找到 '搜寻字符串' 的次数 -i :忽略大小写的不同,所以大小写视为相同 -n :顺便输出行号 -v :反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行! --color=auto :可以将找到的关键词部分加上颜色的显示喔!
范例一:将 last 当中,有出现 root 的那一行就取出来; [root@www ~]# last | grep 'root' 范例二:与范例一相反,只要没有 root 的就取出! [root@www ~]# last | grep -v 'root' 范例三:在 last 的输出信息中,只要有 root 就取出,并且仅取第一栏 [root@www ~]# last | grep 'root' |cut -d ' ' -f1 # 在取出 root 之后,利用上个命令 cut 的处理,就能够仅取得第一栏啰! 范例四:取出 /etc/man.config 内含 MANPATH 的那几行 [root@www ~]# grep --color=auto 'MANPATH' /etc/man.config ....(前面省略).... MANPATH_MAP /usr/X11R6/bin /usr/X11R6/man MANPATH_MAP /usr/bin/X11 /usr/X11R6/man MANPATH_MAP /usr/bin/mh /usr/share/man # 神奇的是,如果加上 --color=auto 的选项,找到的关键词部分会用特殊颜色显示喔!
3.排序命令
sort
[root@www ~]# sort [-fbMnrtuk] [file or stdin] 选项与参数: -f :忽略大小写的差异,例如 A 与 a 视为编码相同; -b :忽略最前面的空格符部分; -M :以月份的名字来排序,例如 JAN, DEC 等等的排序方法; -n :使用『纯数字』进行排序(默认是以文字型态来排序的); -r :反向排序; -u :就是 uniq ,相同的数据中,仅出现一行代表; -t :分隔符,默认是用 [tab] 键来分隔; -k :以那个区间 (field) 来进行排序的意思
范例一:个人账号都记录在 /etc/passwd 下,请将账号进行排序。 [root@www ~]# cat /etc/passwd | sort adm:x:3:4:adm:/var/adm:/sbin/nologin apache:x:48:48:Apache:/var/www:/sbin/nologin bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin # 鸟哥省略很多的输出~由上面的数据看起来, sort 是默认『以第一个』数据来排序, # 而且默认是以『文字』型态来排序的喔!所以由 a 开始排到最后啰! 范例二:/etc/passwd 内容是以 : 来分隔的,我想以第三栏来排序,该如何? [root@www ~]# cat /etc/passwd | sort -t ':' -k 3 root:x:0:0:root:/root:/bin/bash uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin bin:x:1:1:bin:/bin:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin # 看到特殊字体的输出部分了吧?怎么会这样排列啊?呵呵!没错啦~ # 如果是以文字型态来排序的话,原本就会是这样,想要使用数字排序: # cat /etc/passwd | sort -t ':' -k 3 -n # 这样才行啊!用那个 -n 来告知 sort 以数字来排序啊! 范例三:利用 last ,将输出的数据仅取账号,并加以排序 [root@www ~]# last | cut -d ' ' -f1 | sort
wc
[root@www ~]# wc [-lwm] 选项与参数: -l :仅列出行; -w :仅列出多少字(英文单字); -m :多少字符; 范例一:那个 /etc/man.config 里面到底有多少相关字、行、字符数? [root@www ~]# cat /etc/man.config | wc 141 722 4617 # 输出的三个数字中,分别代表: 『行、字数、字符数』 范例二:我知道使用 last 可以输出登陆者,但是 last 最后两行并非账号内容, 那么请问,我该如何以一行命令串取得这个月份登陆系统的总人次? [root@www ~]# last | grep [a-zA-Z] | grep -v 'wtmp' | wc -l # 由于 last 会输出空白行与 wtmp 字样在最底下两行,因此,我利用 # grep 取出非空白行,以及去除 wtmp 那一行,在计算行数,就能够了解啰!
uniq
[root@www ~]# uniq [-ic] 选项与参数: -i :忽略大小写字符的不同; -c :进行计数 范例一:使用 last 将账号列出,仅取出账号栏,进行排序后仅取出一位; [root@www ~]# last | cut -d ' ' -f1 | sort | uniq 范例二:承上题,如果我还想要知道每个人的登陆总次数呢? [root@www ~]# last | cut -d ' ' -f1 | sort | uniq -c 1 12 reboot 41 root 1 wtmp # 从上面的结果可以发现 reboot 有 12 次, root 登陆则有 41 次! # wtmp 与第一行的空白都是 last 的默认字符,那两个可以忽略的!
4.双向重导向
tee
[root@www ~]# tee [-a] file 选项与参数: -a :以累加 (append) 的方式,将数据加入 file 当中! [root@www ~]# last | tee last.list | cut -d " " -f1 # 这个范例可以让我们将 last 的输出存一份到 last.list 文件中; [root@www ~]# ls -l /home | tee ~/homefile | more # 这个范例则是将 ls 的数据存一份到 ~/homefile ,同时屏幕也有输出信息! [root@www ~]# ls -l / | tee -a ~/homefile | more # 要注意! tee 后接的文件会被覆盖,若加上 -a 这个选项则能将信息累加。
5.字符转换命令
tr
[root@www ~]# tr [-ds] SET1 ... 选项与参数: -d :删除信息当中的 SET1 这个字符串; -s :取代掉重复的字符!
范例一:将 last 输出的信息中,所有的小写变成大写字符: [root@www ~]# last | tr '[a-z]' '[A-Z]' # 事实上,没有加上单引号也是可以运行的,如:『 last | tr [a-z] [A-Z] 』 范例二:将 /etc/passwd 输出的信息中,将冒号 (:) 删除 [root@www ~]# cat /etc/passwd | tr -d ':' 范例三:将 /etc/passwd 转存成 dos 断行到 /root/passwd 中,再将 ^M 符号删除 [root@www ~]# cp /etc/passwd /root/passwd && unix2dos /root/passwd [root@www ~]# file /etc/passwd /root/passwd /etc/passwd: ASCII text /root/passwd: ASCII text, with CRLF line terminators <==就是 DOS 断行 [root@www ~]# cat /root/passwd | tr -d '\r' > /root/passwd.linux # 那个 \r 指的是 DOS 的断行字符,关于更多的字符,请参考 man tr [root@www ~]# ll /etc/passwd /root/passwd* -rw-r--r-- 1 root root 1986 Feb 6 17:55 /etc/passwd -rw-r--r-- 1 root root 2030 Feb 7 15:55 /root/passwd -rw-r--r-- 1 root root 1986 Feb 7 15:57 /root/passwd.linux # 处理过后,发现文件大小与原本的 /etc/passwd 就一致了!
col
[root@www ~]# col [-xb] 选项与参数: -x :将 tab 键转换成对等的空格键 -b :在文字内有反斜杠 (/) 时,仅保留反斜杠最后接的那个字符 范例一:利用 cat -A 显示出所有特殊按键,最后以 col 将 [tab] 转成空白 [root@www ~]# cat -A /etc/man.config <==此时会看到很多 ^I 的符号,那就是 tab [root@www ~]# cat /etc/man.config | col -x | cat -A | more # 嘿嘿!如此一来, [tab] 按键会被取代成为空格键,输出就美观多了! 范例二:将 col 的 man page 转存成为 /root/col.man 的纯文本档 [root@www ~]# man col > /root/col.man [root@www ~]# vi /root/col.man COL(1) BSD General Commands Manual COL(1) N^HNA^HAM^HME^HE c^Hco^Hol^Hl - filter reverse line feeds from input S^HSY^HYN^HNO^HOP^HPS^HSI^HIS^HS c^Hco^Hol^Hl [-^H-b^Hbf^Hfp^Hpx^Hx] [-^H-l^Hl _^Hn_^Hu_^Hm] # 你没看错!由于 man page 内有些特殊按钮会用来作为类似特殊按键与颜色显示, # 所以这个文件内就会出现如上所示的一堆怪异字符(有 ^ 的) [root@www ~]# man col | col -b > /root/col.man
join
[root@www ~]# join [-ti12] file1 file2 选项与参数: -t :join 默认以空格符分隔数据,并且比对『第一个字段』的数据, 如果两个文件相同,则将两笔数据联成一行,且第一个字段放在第一个! -i :忽略大小写的差异; -1 :这个是数字的 1 ,代表『第一个文件要用那个字段来分析』的意思; -2 :代表『第二个文件要用那个字段来分析』的意思。 范例一:用 root 的身份,将 /etc/passwd 与 /etc/shadow 相关数据整合成一栏 [root@www ~]# head -n 3 /etc/passwd /etc/shadow ==> /etc/passwd <== root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin ==> /etc/shadow <== root:$1$/3AQpE5e$y9A/D0bh6rElAs:14120:0:99999:7::: bin:*:14126:0:99999:7::: daemon:*:14126:0:99999:7::: # 由输出的数据可以发现这两个文件的最左边字段都是账号!且以 : 分隔 [root@www ~]# join -t ':' /etc/passwd /etc/shadow root:x:0:0:root:/root:/bin/bash:$1$/3AQpE5e$y9A/D0bh6rElAs:14120:0:99999:7::: bin:x:1:1:bin:/bin:/sbin/nologin:*:14126:0:99999:7::: daemon:x:2:2:daemon:/sbin:/sbin/nologin:*:14126:0:99999:7::: # 透过上面这个动作,我们可以将两个文件第一字段相同者整合成一行! # 第二个文件的相同字段并不会显示(因为已经在第一行了嘛!) 范例二:我们知道 /etc/passwd 第四个字段是 GID ,那个 GID 记录在 /etc/group 当中的第三个字段,请问如何将两个文件整合? [root@www ~]# head -n 3 /etc/passwd /etc/group ==> /etc/passwd <== root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin ==> /etc/group <== root:x:0:root bin:x:1:root,bin,daemon daemon:x:2:root,bin,daemon # 从上面可以看到,确实有相同的部分喔!赶紧来整合一下! [root@www ~]# join -t ':' -1 4 /etc/passwd -2 3 /etc/group 0:root:x:0:root:/root:/bin/bash:root:x:root 1:bin:x:1:bin:/bin:/sbin/nologin:bin:x:root,bin,daemon 2:daemon:x:2:daemon:/sbin:/sbin/nologin:daemon:x:root,bin,daemon # 同样的,相同的字段部分被移动到最前面了!所以第二个文件的内容就没再显示。 # 请读者们配合上述显示两个文件的实际内容来比对!
paste
[root@www ~]# paste [-d] file1 file2 选项与参数: -d :后面可以接分隔字符。默认是以 [tab] 来分隔的! - :如果 file 部分写成 - ,表示来自 standard input 的数据的意思。 范例一:将 /etc/passwd 与 /etc/shadow 同一行贴在一起 [root@www ~]# paste /etc/passwd /etc/shadow bin:x:1:1:bin:/bin:/sbin/nologin bin:*:14126:0:99999:7::: daemon:x:2:2:daemon:/sbin:/sbin/nologin daemon:*:14126:0:99999:7::: adm:x:3:4:adm:/var/adm:/sbin/nologin adm:*:14126:0:99999:7::: # 注意喔!同一行中间是以 [tab] 按键隔开的! 范例二:先将 /etc/group 读出(用 cat),然后与范例一贴上一起!且仅取出前三行 [root@www ~]# cat /etc/group|paste /etc/passwd /etc/shadow -|head -n 3 # 这个例子的重点在那个 - 的使用!那玩意儿常常代表 stdin 喔!
expand
[root@www ~]# expand [-t] file 选项与参数: -t :后面可以接数字。一般来说,一个 tab 按键可以用 8 个空格键取代。 我们也可以自行定义一个 [tab] 按键代表多少个字符呢! 范例一:将 /etc/man.config 内行首为 MANPATH 的字样就取出;仅取前三行; [root@www ~]# grep '^MANPATH' /etc/man.config | head -n 3 MANPATH /usr/man MANPATH /usr/share/man MANPATH /usr/local/man # 行首的代表标志为 ^ ,这个我们留待下节介绍!先有概念即可! 范例二:承上,如果我想要将所有的符号都列出来?(用 cat) [root@www ~]# grep '^MANPATH' /etc/man.config | head -n 3 |cat -A MANPATH^I/usr/man$ MANPATH^I/usr/share/man$ MANPATH^I/usr/local/man$ # 发现差别了吗?没错~ [tab] 按键可以被 cat -A 显示成为 ^I 范例三:承上,我将 [tab] 按键配置成 6 个字符的话? [root@www ~]# grep '^MANPATH' /etc/man.config | head -n 3 | \ > expand -t 6 - | cat -A MANPATH /usr/man$ MANPATH /usr/share/man$ MANPATH /usr/local/man$ 123456123456123456..... # 仔细看一下上面的数字说明,因为我是以 6 个字符来代表一个 [tab] 的长度,所以, # MAN... 到 /usr 之间会隔 12 (两个 [tab]) 个字符喔!如果 tab 改成 9 的话, # 情况就又不同了!这里也不好理解~您可以多配置几个数字来查阅就晓得!
6.分割命令
split
[root@www ~]# split [-bl] file PREFIX 选项与参数: -b :后面可接欲分割成的文件大小,可加单位,例如 b, k, m 等; -l :以行数来进行分割。 PREFIX :代表前导符的意思,可作为分割文件的前导文字。
范例一:我的 /etc/termcap 有七百多K,若想要分成 300K 一个文件时? [root@www ~]# cd /tmp; split -b 300k /etc/termcap termcap [root@www tmp]# ll -k termcap* -rw-r--r-- 1 root root 300 Feb 7 16:39 termcapaa -rw-r--r-- 1 root root 300 Feb 7 16:39 termcapab -rw-r--r-- 1 root root 189 Feb 7 16:39 termcapac # 那个档名可以随意取的啦!我们只要写上前导文字,小文件就会以 # xxxaa, xxxab, xxxac 等方式来创建小文件的! 范例二:如何将上面的三个小文件合成一个文件,档名为 termcapback [root@www tmp]# cat termcap* >> termcapback # 很简单吧?就用数据流重导向就好啦!简单! 范例三:使用 ls -al / 输出的信息中,每十行记录成一个文件 [root@www tmp]# ls -al / | split -l 10 - lsroot [root@www tmp]# wc -l lsroot* 10 lsrootaa 10 lsrootab 6 lsrootac 26 total # 重点在那个 - 啦!一般来说,如果需要 stdout/stdin 时,但偏偏又没有文件, # 有的只是 - 时,那么那个 - 就会被当成 stdin 或 stdout ~
7.参数代换命令
xargs
[root@www ~]# xargs [-0epn] command 选项与参数: -0 :如果输入的 stdin 含有特殊字符,例如 `, \, 空格键等等字符时,这个 -0 参数 可以将他还原成一般字符。这个参数可以用于特殊状态喔! -e :这个是 EOF (end of file) 的意思。后面可以接一个字符串,当 xargs 分析到 这个字符串时,就会停止继续工作! -p :在运行每个命令的 argument 时,都会询问使用者的意思; -n :后面接次数,每次 command 命令运行时,要使用几个参数的意思。看范例三。 当 xargs 后面没有接任何的命令时,默认是以 echo 来进行输出喔!
范例一:将 /etc/passwd 内的第一栏取出,仅取三行,使用 finger 这个命令将每个 账号内容秀出来 [root@www ~]# cut -d':' -f1 /etc/passwd |head -n 3| xargs finger Login: root Name: root Directory: /root Shell: /bin/bash Never logged in. No mail. No Plan. ......底下省略..... # 由 finger account 可以取得该账号的相关说明内容,例如上面的输出就是 finger root # 后的结果。在这个例子当中,我们利用 cut 取出账号名称,用 head 取出三个账号, # 最后则是由 xargs 将三个账号的名称变成 finger 后面需要的参数! 范例二:同上,但是每次运行 finger 时,都要询问使用者是否动作? [root@www ~]# cut -d':' -f1 /etc/passwd |head -n 3| xargs -p finger finger root bin daemon ?...y .....(底下省略).... # 呵呵!这个 -p 的选项可以让用户的使用过程中,被询问到每个命令是否运行! 范例三:将所有的 /etc/passwd 内的账号都以 finger 查阅,但一次仅查阅五个账号 [root@www ~]# cut -d':' -f1 /etc/passwd | xargs -p -n 5 finger finger root bin daemon adm lp ?...y .....(中间省略).... finger uucp operator games gopher ftp ?...y .....(底下省略).... # 在这里鸟哥使用了 -p 这个参数来让您对于 -n 更有概念。一般来说,某些命令后面 # 可以接的 arguments 是有限制的,不能无限制的累加,此时,我们可以利用 -n # 来帮助我们将参数分成数个部分,每个部分分别再以命令来运行!这样就 OK 啦!^_^ 范例四:同上,但是当分析到 lp 就结束这串命令? [root@www ~]# cut -d':' -f1 /etc/passwd | xargs -p -e'lp' finger finger root bin daemon adm ?... # 仔细与上面的案例做比较。也同时注意,那个 -e'lp' 是连在一起的,中间没有空格键。 # 上个例子当中,第五个参数是 lp 啊,那么我们下达 -e'lp' 后,则分析到 lp # 这个字符串时,后面的其他 stdin 的内容就会被 xargs 舍弃掉了! 范例五:找出 /sbin 底下具有特殊权限的档名,并使用 ls -l 列出详细属性 [root@www ~]# find /sbin -perm +7000 | ls -l # 结果竟然仅有列出 root 所在目录下的文件!这不是我们要的! # 因为 ll (ls) 并不是管线命令的原因啊! [root@www ~]# find /sbin -perm +7000 | xargs ls -l -rwsr-xr-x 1 root root 70420 May 25 2008 /sbin/mount.nfs -rwsr-xr-x 1 root root 70424 May 25 2008 /sbin/mount.nfs4 -rwxr-sr-x 1 root root 5920 Jun 15 2008 /sbin/netreport ....(底下省略)....
8.‘-’号的作用
[root@www ~]# tar -cvf - /home | tar -xvf -

