15 | 流式计算的代表:Storm、Flink、Spark Streaming
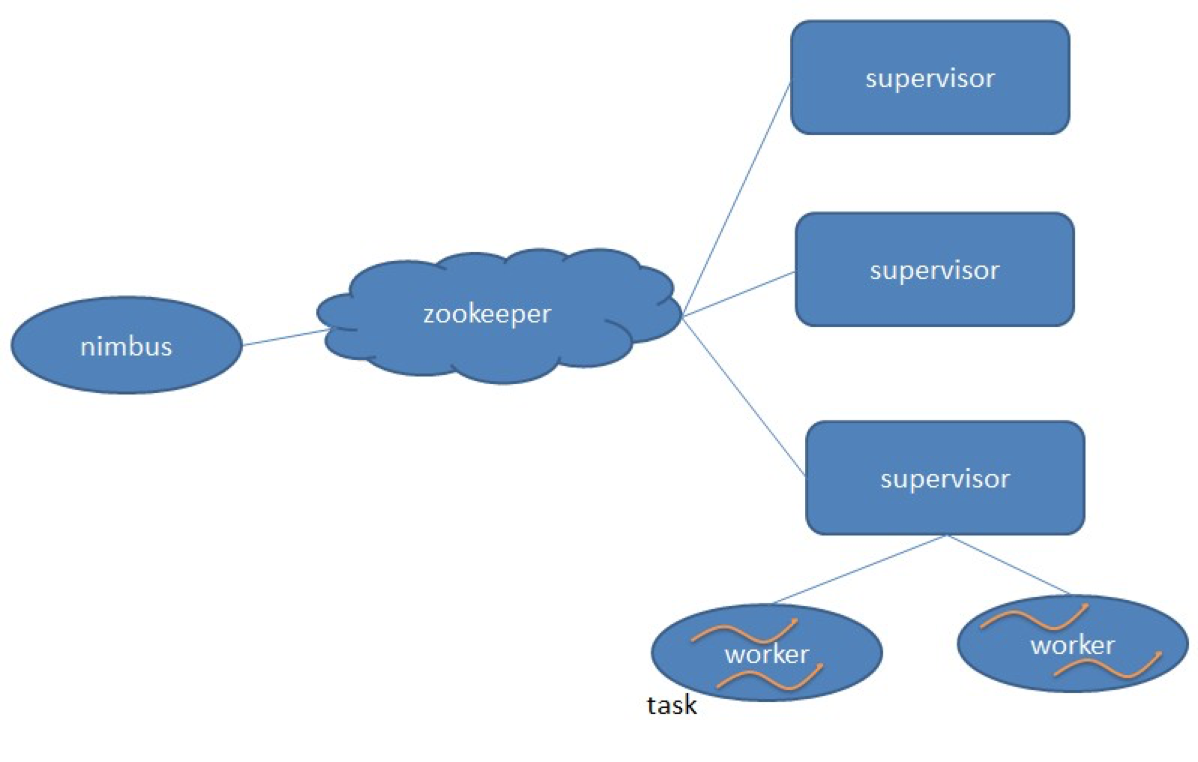
Storm

开发者无需关注数据的流转、消息的处理和消费,只要编程开发好数据处理的逻辑 bolt 和数据源的逻辑 spout,以及它们之间的拓扑逻辑关系 toplogy,提交到 Storm 上运行即可。



Spark Streaming
Spark 是一个快速计算的大数据引擎,它将原始数据分片后装载到集群中计算,对于数据量不是很大、过程不是很复杂的计算,可以在秒级甚至毫秒级完成处理。Spark Streaming巧妙地利用了 Spark 的分片和快速计算的特性,将实时传输进来的数据按照时间进行分段,把一段时间传输进来的数据合并在在一起,当作一批数据,再去交给 Spark 去处理。

如果时间段分得足够小,每一段的数据量就会比较小,再加上 Spark 引擎的处理速度又足够快,这样看起来好像数据是被实时处理的一样,这就是 Spark Streaming 实时流计算的奥妙。
Spark Streaming 主要负责将流数据转换成小的批数据,剩下的就可以交给 Spark 去做了。
Flink
Flink 一开始就是按照流处理计算去设计的。当把从文件系统(HDFS)中读入的数据也当做数据流看待,他就变成批处理系统了。
为什么 Flink 既可以流处理又可以批处理呢?
如果要进行流计算,Flink 会初始化一个流执行环境 StreamExecutionEnvironment,然后利用这个执行环境构建数据流 DataStream。
如果要进行批处理计算,Flink 会初始化一个批处理执行环境ExecutionEnvironment,然后利用这个环境构建数据集 DataSet。
Flink 处理实时数据流的方式跟 Spark Streaming 也很相似,也是将流数据分段后,一小批一小批地处理。流处理算是 Flink 里的“一等公民”,Flink 对流处理的支持也更加完善。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号