
18、正则表达式
re模块
1、findall:返回所有满足匹配条件的结果,放到列表里,也就是说生成的是一个列表。
import re ret=re.findall('www.(?:oldboy|baidu).com','www.oldboy.com') print(ret)

findall的优先级:findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可:-------->(?:取消优先级)
2、search:在整个字符串内匹配,返回第一个满足匹配条件的结果,用group显示,没匹配到调用group会报错。
import re ret=re.search('a','baabc').group() print(ret)

3、match :从头开始匹配,必须第一个字符就要满足匹配结果才能匹配的上,用group显示,没有结果返回None调用group会报错。
import re ret=re.match('a','aabc').group() print(ret)

import re ret=re.match('a','baabc').group() print(ret)

4、sub 类似字符串中的replace替换功能:(要替换的类型,替换后内容,替换的字符串,匹配的数量(要替换的数量))。
import re ret=re.sub('\d','G','djfh24su5dfdffd',2) print(ret)
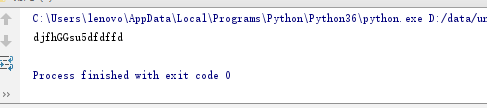
3、subn:也是替换,将要替换的内容替换了,返回元祖,元祖为:(替换的结果,替换了多少次)。
import re ret=re.subn('\d','G','djfh24su5dfdffd') print(ret)

3、compile :将正则表达式编译成一个正则表达式对象,正则表达式对象调用search,参数为待匹配的对象
import re obj=re.compile('\d{3}') ret=obj.search('jih345njkiud234') print(ret.group())

4、split:分割
split的优先级:在匹配部分加上()之后所切出的结果是不同的,没有()的没有保留所匹配的项,有()的能够保留匹配的项。这个在某些需要保留匹配部分的使用过程是非常重要的。(也就是说对于要匹配的条件来说,加不加括号是有区别的,没有括号不保留匹配的项,加上括号保留匹配的项。)
import re ret=re.split('(\d+)','eva34heh4hi5gg') print(ret)

import re ret=re.split('(\d)','eva34heh4hi5gg') print(ret)

这就是差距啊,差距!给你一个保护罩你就牛逼了,是不是?是不是?这个样子有点像现实的某……

 浙公网安备 33010602011771号
浙公网安备 33010602011771号