20180925-3 效能分析
此作业的要求参见:https://edu.cnblogs.com/campus/nenu/2018fall/homework/2145
修改后的代码git地址为:https://git.coding.net/wangyupan/fourth-program.git
用ptime测试消耗的时间
前两次测试
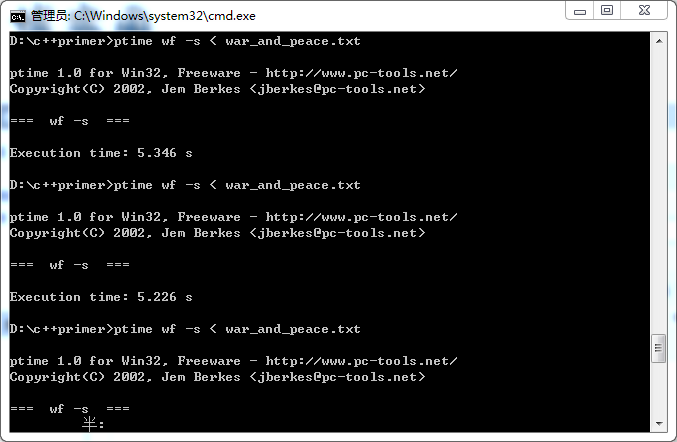
第三次测试的时间
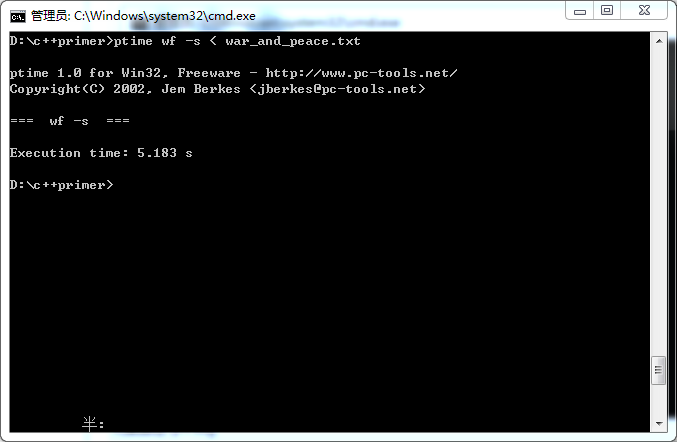
平均时间为:5.251s
我认为下面的代码是导致运行时间过长的罪魁祸首:
for(int i=0; i<len; i++) { if(str[i]>='A'&&str[i]<='Z') { str[i]+=32; } if(str[i]>='a'&&str[i]<='z') { str1[j++]=str[i]; } else { str1[j]='\0'; if(str1[0]=='\0') continue; else total++; bool flag=true; for(int i=0; i<num; i++) { if(strcmp(Word[i].W,str1)==0) { Word[i].cnt++; flag=false; break; } } if(flag) { strcpy(Word[num].W,str1); Word[num].cnt=1; num++; } j=0; } }
这段代码是实现读取单词的功能,里面有一个双层循环,所以我猜测它会导致时间复杂度过大。
用very sleepy进行profile:
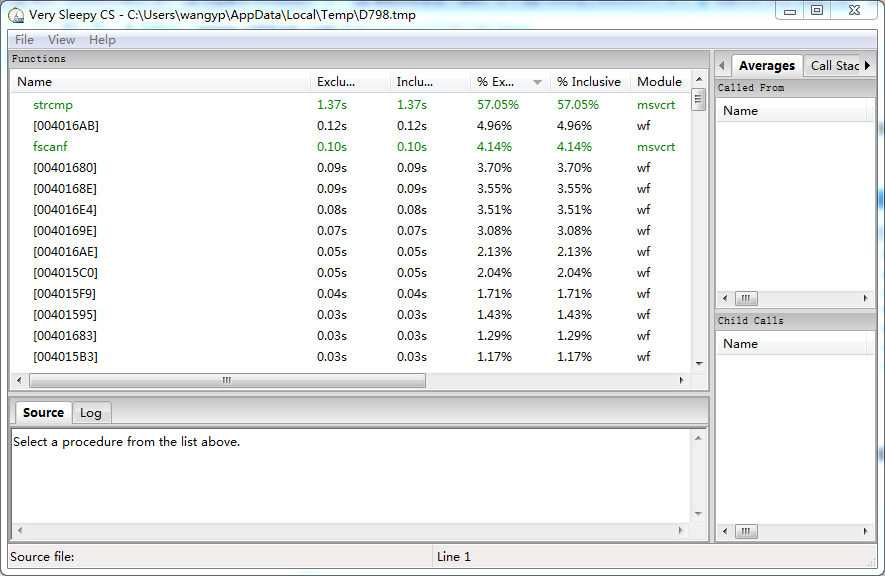
strcmp函数占用时间太多,得到的单词跟前面存储起来的单词进行比较时用到strcmp,利用strcmp函数的代码段如下:
for(int i=0; i<num; i++) { if(strcmp(Word[i].W,str1)==0) { Word[i].cnt++; flag=false; break; } }
我的猜测也没有方法改进。根据profile可知,单词比较时比较花费时间,我使用了map这个数据结构,他的插入和查找速度总体上很快,我向我的程序做了如下改进:
void fcounter() { long long total = 0; long long num = 0; string fileName = "out.txt"; char str[50]; char str1[50]; string temp; while (~scanf("%s",str)) { int len = strlen(str); int j = 0; for (int i = 0; i < len; ++i) { if (str[i] >= 'A' && str[i] <= 'Z') str[i] += 32; if (str[i] >= 'a' && str[i] <= 'z') str1[j++] = str[i]; else { //str1[j] == '0'; str1[j] = 0; j = 0; if (str1[0] == 0) continue; else ++total; // 这里用map temp = str1; if (Word1.count(temp) > 0) Word1[temp]++; else Word1[temp] = 1; // else if (Word.count(temp) == 0) // Word[temp] = 1; // else // ; } } str1[j] = 0; if (str1[0] == 0) continue; temp = str1; if (Word1.count(temp) > 0) Word1[temp]++; else Word1[temp] = 1; } map<string, int>::iterator p; vector<pair<string, int> > word_vector; pair<string, int> element; for (p = Word1.begin(); p != Word1.end(); ++p) { element.first = p->first; element.second = p->second; word_vector.push_back(element); } sort(word_vector.begin(), word_vector.end(), word_cmp); total = word_vector.size(); if (word_vector.size() > 20) num = 20; ofstream fout; fout.open(fileName.c_str()); fout << "total " << word_vector.size() << endl; for (int i = 0; i < num; ++i) fout << word_vector[i].first << ' ' << word_vector[i].second << endl; fout.close(); }
修改之后我程序跑的明显变快了:
第一次测试:
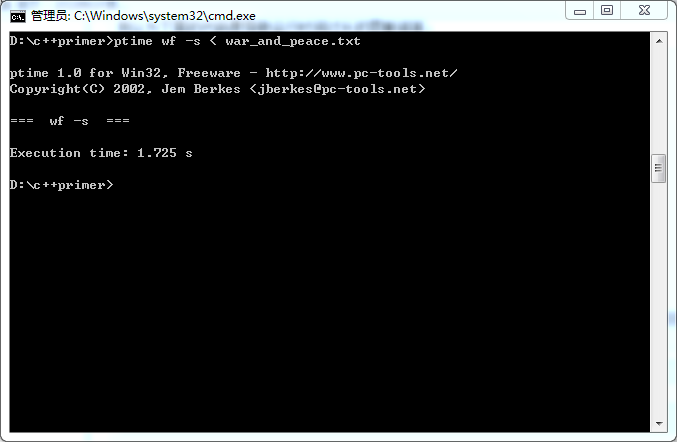
第二次测试:
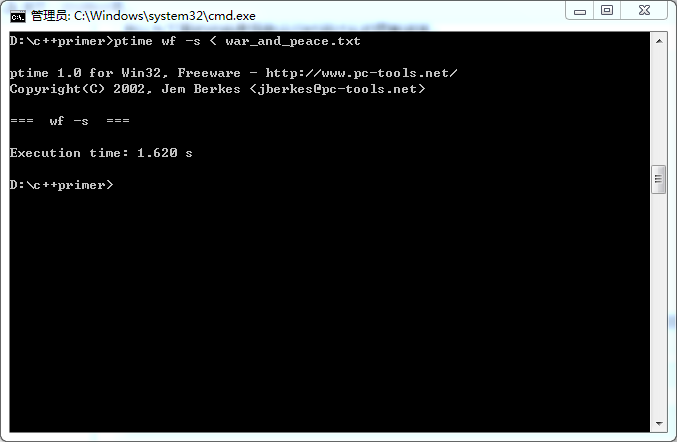
第三次测试:
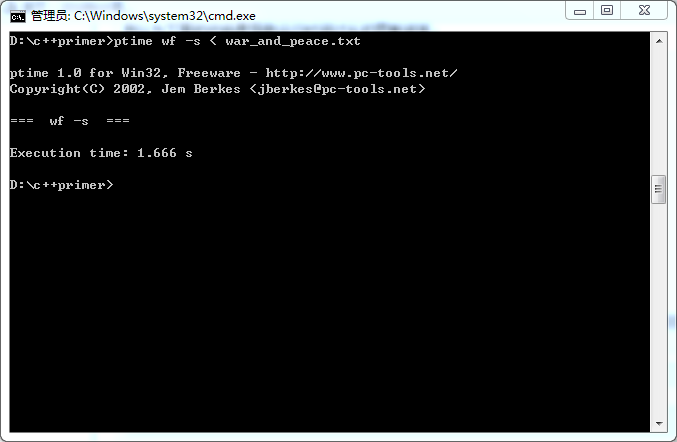
平均时间为:1.670s
较上次5.251s有较大提升。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号