

python爬取大众点评并写入mongodb数据库和redis数据库
抓取大众点评首页左侧信息,如图:
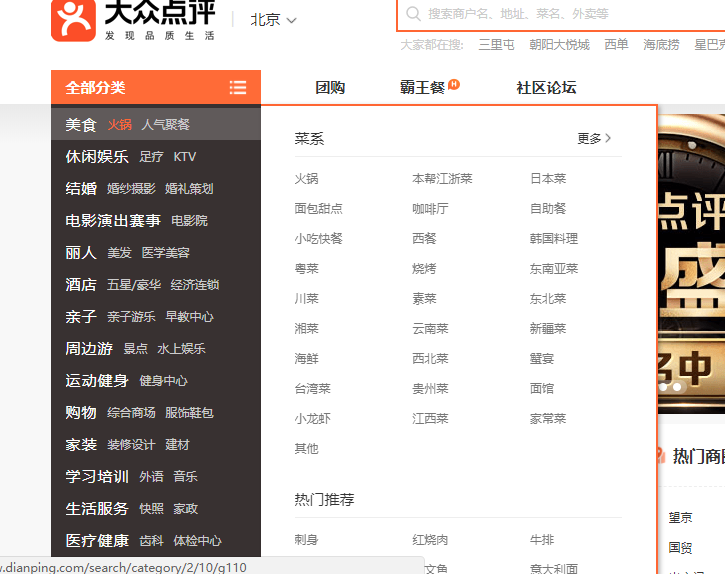
我们要实现把中文名字都存到mongodb,而每个链接存入redis数据库。
因为将数据存到mongodb时每一个信息都会有一个对应的id,那样就方便我们存入redis可以不出错。
# -*- coding: utf-8 -*-
import re
from urllib.request import urlopen
from urllib.request import Request
from bs4 import BeautifulSoup
from lxml import etree
import pymongo
client = pymongo.MongoClient(host="127.0.0.1")
db = client.dianping #库名dianping
collection = db.classification #表名classification
import redis #导入redis数据库
r = redis.Redis(host='127.0.0.1', port=6379, db=0)
# client = pymongo.MongoClient(host="192.168.60.112")
# myip = client['myip'] # 给数据库命名
def secClassFind(selector, classid):
secItems = selector.xpath('//div[@class="sec-items"]/a')
for secItem in secItems:
url = secItem.get('href') #得到url
title = secItem.text
classid = collection.insert({'classname': title, 'pid': classid})
classurl = '%s,%s' % (classid, url) #拼串
r.lpush('classurl', classurl) #入库
def Public(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'} #协议头
req_timeout = 5
req = Request(url=url, headers=headers)
f = urlopen(req, None, req_timeout)
s = f.read()
s = s.decode("utf-8")
# beautifulsoup提取
soup = BeautifulSoup(s, 'html.parser')
links = soup.find_all(name='li', class_="first-item")
for link in links:
selector = etree.HTML(str(link))
# indexTitleUrls = selector.xpath('//a[@class="index-title"]/@href')
# # 获取一级类别url和title
# for titleurl in indexTitleUrls:
# print(titleurl)
indexTitles = selector.xpath('//a[@class="index-title"]/text()')
for title in indexTitles:
# 第二级url
print(title)
classid = collection.insert({'classname': title, 'pid': None})
secClassFind(selector, classid)
print('---------')
# secItems = selector.xpath('//div[@class="sec-items"]/a')
# for secItem in secItems:
# print(secItem.get('href'))
# print(secItem.text)
print('-----------------------------')
#
# myip.collection.insert({'name':secItem.text})
# r.lpush('mylist', secItem.get('href'))
# collection.find_one({'_id': ObjectId('5a14c8916d123842bcea5835')}) # connection = pymongo.MongoClient(host="192.168.60.112") # 连接MongDB数据库
# post_info = connection.myip # 指定数据库名称(yande_test),没有则创建
# post_sub = post_info.test # 获取集合名:test
Public('http://www.dianping.com/')

