Redis
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
一、Redis安装和基本使用
windows安装
http://c.biancheng.net/redis/windows-installer.html
Linux安装
wget http://download.redis.io/releases/redis-3.0.6.tar.gz
tar xzf redis-3.0.6.tar.gz
cd redis-3.0.6
make
启动服务端
src/redis-server
启动客户端
src/redis-cli
redis> set foo bar
OK
redis> get foo
"bar"
二、Redis的特性
使用Redis有哪些好处?
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2) 支持丰富数据类型,支持string,list,set,sorted set,hash
(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
redis相比memcached有哪些优势?
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多
(3) redis可以持久化其数据
redis常见性能问题和解决方案
(1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
(3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
(4) 尽量避免在压力很大的主库上增加从库
(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3...
这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。
MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据
相关知识:redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。redis 提供 6种数据淘汰策略:
voltile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
Memcache与Redis的区别都有哪些?
1)、存储方式
Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。
Redis有部份存在硬盘上,这样能保证数据的持久性。
2)、数据支持类型
Memcache对数据类型支持相对简单。
Redis有复杂的数据类型。
3),value大小
redis最大可以达到1GB,而memcache只有1MB
Redis 常见的性能问题都有哪些?如何解决?
1).Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
2).Master AOF持久化,如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化,如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
3).Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
4). Redis主从复制的性能问题,为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内
redis 最适合的场景
Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎Redis更像一个加强版的Memcached,那么何时使用Memcached,何时使用Redis呢?
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
1 、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2 、Redis支持数据的备份,即master-slave模式的数据备份。
3 、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
(1)、会话缓存(Session Cache)
最常用的一种使用Redis的情景是会话缓存(session cache)。用Redis缓存会话比其他存储(如Memcached)的优势在于:Redis提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗?
幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用Redis来缓存会话的文档。甚至广为人知的商业平台Magento也提供Redis的插件。
(2)、全页缓存(FPC)
除基本的会话token之外,Redis还提供很简便的FPC平台。回到一致性问题,即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似PHP本地FPC。
再次以Magento为例,Magento提供一个插件来使用Redis作为全页缓存后端。
此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
(3)、队列
Reids在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用。Redis作为队列使用的操作,就类似于本地程序语言(如Python)对 list 的 push/pop 操作。
如果你快速的在Google中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的就是利用Redis创建非常好的后端工具,以满足各种队列需求。例如,Celery有一个后台就是使用Redis作为broker,你可以从这里去查看。
(4),排行榜/计数器
Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的10个用户–我们称之为“user_scores”,我们只需要像下面一样执行即可:
当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games就是一个很好的例子,用Ruby实现的,它的排行榜就是使用Redis来存储数据的,你可以在这里看到。
(5)、发布/订阅
最后(但肯定不是最不重要的)是Redis的发布/订阅功能。发布/订阅的使用场景确实非常多。我已看见人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用Redis的发布/订阅功能来建立聊天系统!(不,这是真的,你可以去核实)。
Redis提供的所有特性中,我感觉这个是喜欢的人最少的一个,虽然它为用户提供如果此多功能。
三、Python操作redis
sudo pip install redis
or
sudo easy_install redis
or
源码安装
API使用
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
import redis
r = redis.Redis(host='10.211.55.4', port=6379)
r.set('foo', 'Bar')
print(r.get('foo'))
连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
r.set('foo', 'Bar')
print r.get('foo')
操作
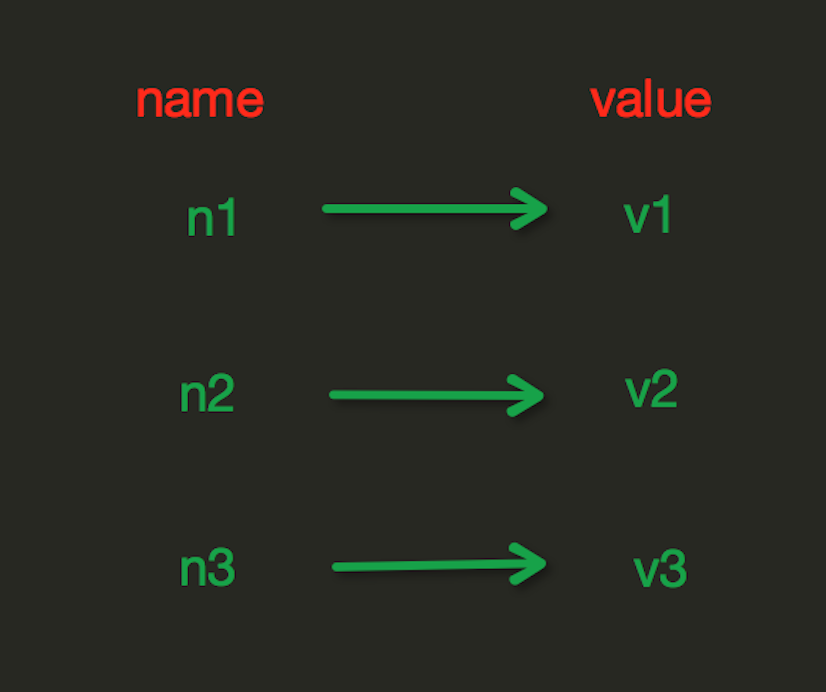
1、String操作
String操作,redis中的String在在内存中按照一个name对应一个value来存储。如图:
set(name, value, ex=None, px=None, nx=False, xx=False)
set(name, value, ex=None, px=None, nx=False, xx=False)
# 在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
setnx(name, value)
# 设置值,只有name不存在时,执行设置操作(添加)
setex(name, value, time)
# 设置值
# 参数:
# time,过期时间(数字秒 或 timedelta对象)
psetex(name, time_ms, value)
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args, **kwargs)
批量设置值
如:
mset(k1='v1', k2='v2')
或
mget({'k1': 'v1', 'k2': 'v2'})
get(name)
获取值
mget(keys, *args)
批量获取
如:
mget('ylr', 'wupeiqi')
或
r.mget(['ylr', 'wupeiqi'])
getset(name, value)
设置新值并获取原来的值
getrange(key, start, end)
# 获取子序列(根据字节获取,非字符)
# 参数:
# name,Redis 的 name
# start,起始位置(字节)
# end,结束位置(字节)
# 如: "大帅逼" ,0-3表示 "大"
setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
# 参数:
# offset,字符串的索引,字节(一个汉字三个字节)
# value,要设置的值
setbit(name, offset, value)
# 对name对应值的二进制表示的位进行操作
# 参数:
# name,redis的name
# offset,位的索引(将值变换成二进制后再进行索引)
# value,值只能是 1 或 0
# 注:如果在Redis中有一个对应: n1 = "foo",
那么字符串foo的二进制表示为:01100110 01101111 01101111
所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1,
那么最终二进制则变成 01100111 01101111 01101111,即:"goo"
# 扩展,转换二进制表示:
# source = "武沛齐"
source = "foo"
for i in source:
num = ord(i)
print bin(num).replace('b','')
特别的,如果source是汉字 "大帅比"怎么办?
答:对于utf-8,每一个汉字占 3 个字节,那么 "大帅比" 则有 9个字节
对于汉字,for循环时候会按照 字节 迭代,那么在迭代时,将每一个字节转换 十进制数,然后再将十进制数转换成二进制
11100110 10101101 10100110 11100110 10110010 10011011 11101001 10111101 10010000
-------------------------- ----------------------------- -----------------------------
大 帅 比
getbit(name, offset)
# 获取name对应的值的二进制表示中的某位的值 (0或1)
bitcount(key, start=None, end=None)
# 获取name对应的值的二进制表示中 1 的个数
# 参数:
# key,Redis的name
# start,位起始位置
# end,位结束位置
bitop(operation, dest, *keys)
# 获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值
# 参数:
# operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或)
# dest, 新的Redis的name
# *keys,要查找的Redis的name
# 如:
bitop("AND", 'new_name', 'n1', 'n2', 'n3')
# 获取Redis中n1,n2,n3对应的值,然后讲所有的值做位运算(求并集),然后将结果保存 new_name 对应的值中
strlen(name)
# 返回name对应值的字节长度(一个汉字3个字节)
incr(self, name, amount=1)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
# 参数:
# name,Redis的name
# amount,自增数(必须是整数)
# 注:同incrby
incrbyfloat(self, name, amount=1.0)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
# 参数:
# name,Redis的name
# amount,自增数(浮点型)
decr(self, name, amount=1)
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。
# 参数:
# name,Redis的name
# amount,自减数(整数)
append(key, value)
# 在redis name对应的值后面追加内容
# 参数:
key, redis的name
value, 要追加的字符串
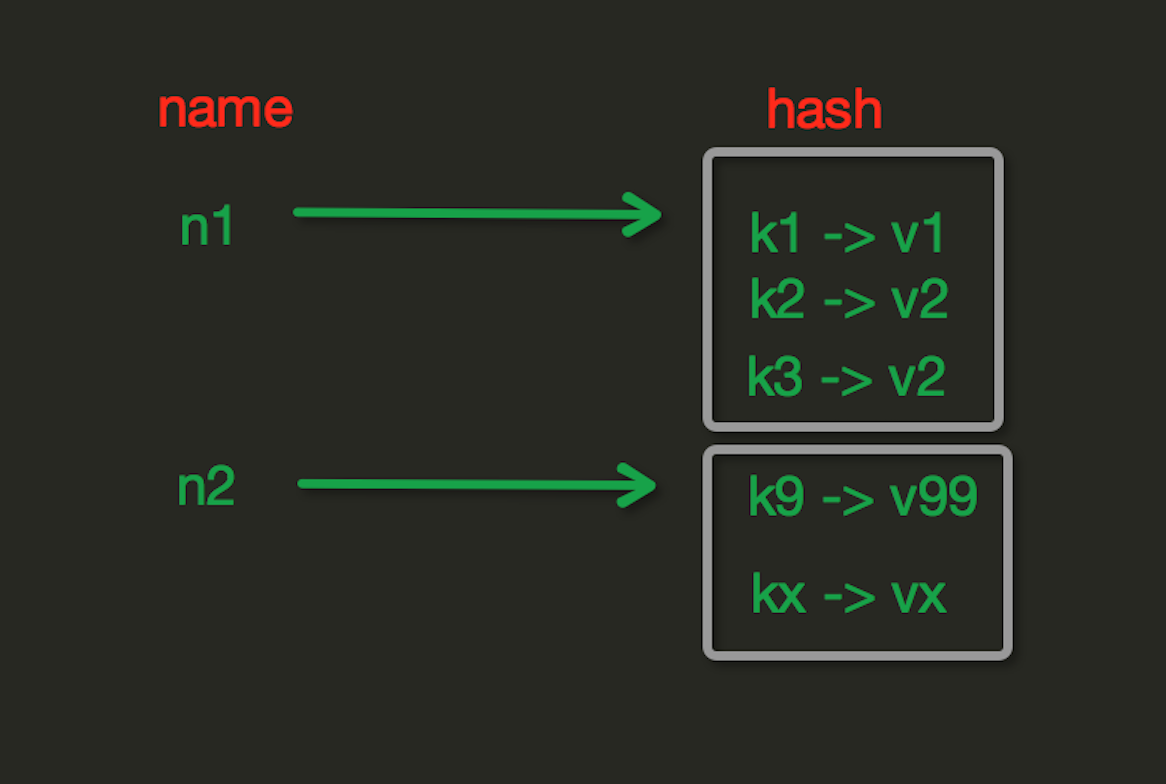
2、Hash操作
Hash操作,redis中Hash在内存中的存储格式如下图:
hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name, mapping)
# 在name对应的hash中批量设置键值对
# 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
# 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
hget(name,key)
# 在name对应的hash中获取根据key获取value
hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值
# 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3
# 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
hgetall(name)
# 获取name对应hash的所有键值
hlen(name)
# 获取name对应的hash中键值对的个数
hkeys(name)
# 获取name对应的hash中所有的key的值
hvals(name)
# 获取name对应的hash中所有的value的值
hexists(name, key)
# 检查name对应的hash是否存在当前传入的key
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
hscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
# 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
# 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# for item in r.hscan_iter('xx'):
# print item
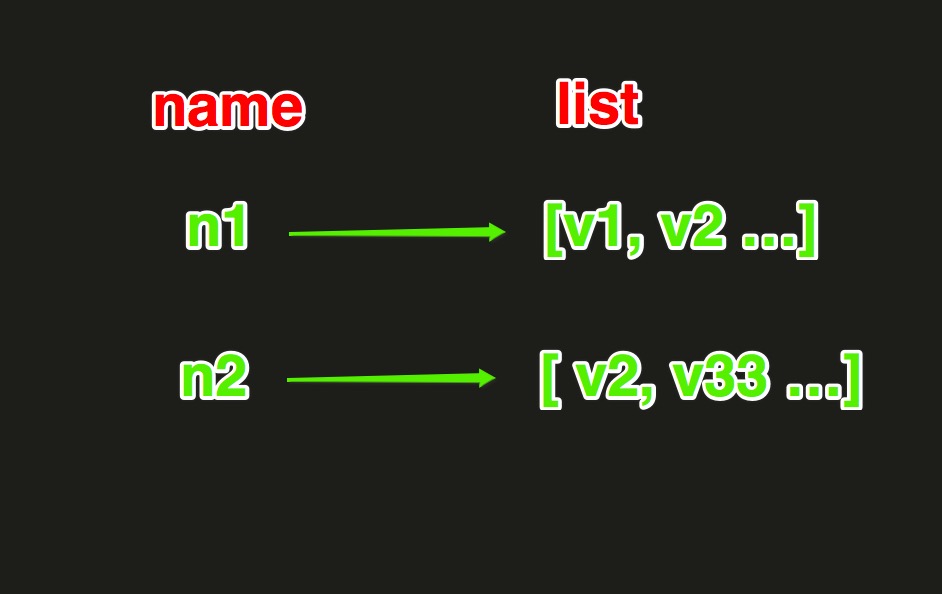
3、List操作
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:
lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边
# 如:
# r.lpush('oo', 11,22,33)
# 保存顺序为: 33,22,11
# 扩展:
# rpush(name, values) 表示从右向左操作
lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
# 更多:
# rpushx(name, value) 表示从右向左操作
llen(name)
# name对应的list元素的个数
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值
# 参数:
# name,redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据
r.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值
# 参数:
# name,redis的name
# index,list的索引位置
# value,要设置的值
r.lrem(name, value, num)
# 在name对应的list中删除指定的值
# 参数:
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
# 更多:
# rpop(name) 表示从右向左操作
lindex(name, index)
在name对应的列表中根据索引获取列表元素
lrange(name, start, end)
# 在name对应的列表分片获取数据
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
# 参数:
# src,要取数据的列表的name
# dst,要添加数据的列表的name
blpop(keys, timeout)
# 将多个列表排列,按照从左到右去pop对应列表的元素
# 参数:
# keys,redis的name的集合
# timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
# 更多:
# r.brpop(keys, timeout),从右向左获取数据
brpoplpush(src, dst, timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
# 参数:
# src,取出并要移除元素的列表对应的name
# dst,要插入元素的列表对应的name
# timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
4、Set操作
Set操作,Set集合就是不允许重复的列表
sadd(name,values)
# name对应的集合中添加元素
scard(name)
获取name对应的集合中元素个数
sdiff(keys, *args)
# 在第一个name对应的集合中且不在其他name对应的集合的元素集合
sdiffstore(dest, keys, *args)
# 获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
sinter(keys, *args)
# 获取多一个name对应集合的并集
sinterstore(dest, keys, *args)
# 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
sismember(name, value)
# 检查value是否是name对应的集合的成员
smembers(name)
# 获取name对应的集合的所有成员
smove(src, dst, value)
# 将某个成员从一个集合中移动到另外一个集合
spop(name)
# 从集合的右侧(尾部)移除一个成员,并将其返回
srandmember(name, numbers)
# 从name对应的集合中随机获取 numbers 个元素
srem(name, values)
# 在name对应的集合中删除某些值
sunion(keys, *args)
# 获取多一个name对应的集合的并集
sunionstore(dest,keys, *args)
# 获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
sscan(name, cursor=0, match=None, count=None)
sscan_iter(name, match=None, count=None)
# 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
5、有序集合
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素
# 如:
# zadd('zz', 'n1', 1, 'n2', 2)
# 或
# zadd('zz', n1=11, n2=22)
zcard(name)
# 获取name对应的有序集合元素的数量
zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数
zincrby(name, value, amount)
# 自增name对应的有序集合的 name 对应的分数
r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素
# 参数:
# name,redis的name
# start,有序集合索引起始位置(非分数)
# end,有序集合索引结束位置(非分数)
# desc,排序规则,默认按照分数从小到大排序
# withscores,是否获取元素的分数,默认只获取元素的值
# score_cast_func,对分数进行数据转换的函数
# 更多:
# 从大到小排序
# zrevrange(name, start, end, withscores=False, score_cast_func=float)
# 按照分数范围获取name对应的有序集合的元素
# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)
# 从大到小排序
# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始)
# 更多:
# zrevrank(name, value),从大到小排序
zrangebylex(name, min, max, start=None, num=None)
# 当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的 值 (lexicographical ordering)来进行排序,而这个命令则可以返回给定的有序集合键 key 中, 元素的值介于 min 和 max 之间的成员
# 对集合中的每个成员进行逐个字节的对比(byte-by-byte compare), 并按照从低到高的顺序, 返回排序后的集合成员。 如果两个字符串有一部分内容是相同的话, 那么命令会认为较长的字符串比较短的字符串要大
# 参数:
# name,redis的name
# min,左区间(值)。 + 表示正无限; - 表示负无限; ( 表示开区间; [ 则表示闭区间
# min,右区间(值)
# start,对结果进行分片处理,索引位置
# num,对结果进行分片处理,索引后面的num个元素
# 如:
# ZADD myzset 0 aa 0 ba 0 ca 0 da 0 ea 0 fa 0 ga
# r.zrangebylex('myzset', "-", "[ca") 结果为:['aa', 'ba', 'ca']
# 更多:
# 从大到小排序
# zrevrangebylex(name, max, min, start=None, num=None)
zrem(name, values)
# 删除name对应的有序集合中值是values的成员
# 如:zrem('zz', ['s1', 's2'])
zremrangebyrank(name, min, max)
# 根据排行范围删除
zremrangebyscore(name, min, max)
# 根据分数范围删除
zremrangebylex(name, min, max)
# 根据值返回删除
zscore(name, value)
# 获取name对应有序集合中 value 对应的分数
zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX
zunionstore(dest, keys, aggregate=None)
# 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX
zscan(name, cursor=0, match=None, count=None, score_cast_func=float)
zscan_iter(name, match=None, count=None,score_cast_func=float)
# 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
5、自定义增量迭代
# 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要:
# 1、获取name对应的所有列表
# 2、循环列表
# 但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能:
def list_iter(name):
"""
自定义redis列表增量迭代
:param name: redis中的name,即:迭代name对应的列表
:return: yield 返回 列表元素
"""
list_count = r.llen(name)
for index in xrange(list_count):
yield r.lindex(name, index)
# 使用
for item in list_iter('pp'):
print item
6、其他常用操作
delete(*names)
# 根据删除redis中的任意数据类型
exists(name)
# 检测redis的name是否存在
keys(pattern='*')
# 根据模型获取redis的name
# 更多:
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
expire(name ,time)
# 为某个redis的某个name设置超时时间
rename(src, dst)
# 对redis的name重命名为
move(name, db))
# 将redis的某个值移动到指定的db下
randomkey()
# 随机获取一个redis的name(不删除)
type(name)
# 获取name对应值的类型
scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None)
# 同字符串操作,用于增量迭代获取key
管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True)
pipe.multi()
pipe.set('name', 'alex')
pipe.set('role', 'sb')
pipe.execute()
# 实现计数器
import redis
conn = redis.Redis(host='192.168.1.41',port=6379)
conn.set('count',1000)
with conn.pipeline() as pipe:
# 先监视,自己的值没有被修改过
conn.watch('count')
# 事务开始
pipe.multi()
old_count = conn.get('count')
count = int(old_count)
if count > 0: # 有库存
pipe.set('count', count - 1)
# 执行,把所有命令一次性推送过去
pipe.execute()
发布订阅

发布者:服务器
订阅者:Dashboad和数据处理
Demo如下:
# RedisHelper
import redis
class RedisHelper:
def __init__(self):
self.__conn = redis.Redis(host='10.211.55.4')
self.chan_sub = 'fm104.5'
self.chan_pub = 'fm104.5'
def public(self, msg):
self.__conn.publish(self.chan_pub, msg)
return True
def subscribe(self):
pub = self.__conn.pubsub()
pub.subscribe(self.chan_sub)
pub.parse_response()
return pub
RedisHelper
订阅者:
from monitor.RedisHelper import RedisHelper
obj = RedisHelper()
redis_sub = obj.subscribe()
while True:
msg= redis_sub.parse_response()
print(msg)
发布者:
from monitor.RedisHelper import RedisHelper
obj = RedisHelper()
obj.public('hello')
sentinel
redis重的sentinel主要用于在redis主从复制中,如果master顾上,则自动将slave替换成master
from redis.sentinel import Sentinel
# 连接哨兵服务器(主机名也可以用域名)
sentinel = Sentinel([('10.211.55.20', 26379),
('10.211.55.20', 26380),
],
socket_timeout=0.5)
# # 获取主服务器地址
# master = sentinel.discover_master('mymaster')
# print(master)
#
# # # 获取从服务器地址
# slave = sentinel.discover_slaves('mymaster')
# print(slave)
#
#
# # # 获取主服务器进行写入
# master = sentinel.master_for('mymaster')
# master.set('foo', 'bar')
# # # # 获取从服务器进行读取(默认是round-roubin)
# slave = sentinel.slave_for('mymaster', password='redis_auth_pass')
# r_ret = slave.get('foo')
# print(r_ret)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号