k8s快速部署--kubeadm
一、部署前准备
1.1 主机规划
| 主机名 | ip地址 | 操作系统 | cpu*内存 | 硬盘 |
|---|---|---|---|---|
| master | 192.168.100.101 | Centos7 | 2*2 | 50G |
| node1 | 192.168.100.102 | Centos7 | 2*2 | 50G |
| node2 | 192.168.100.103 | Centos7 | 2*2 | 50G |
1.2 升级内核版本
可以参考https://www.cnblogs.com/wangyuanguang/p/18051798
1.3 分别设置主机名并添加hosts映射
~]# hostnamectl set-hostname master
~]# hostnamectl set-hostname node1
~]# hostnamectl set-hostname node2
~]# vim /etc/hosts
192.168.100.101 master
192.168.100.102 node1
192.168.100.103 node2
1.4 关闭selinux和firewalld
~]# systemctl stop firewalld
~]# systemctl disable firewalld
~]# sed -i 's/enforcing/disabled/' /etc/selinux/config
~]# setenforce 0
1.5 禁止swap分区
~]# swapoff -a
1.6 将桥接的IPv4流量传递到iptables的链
~]# cat > /etc/sysctl.d/k8s.conf << EOF
net.ipv4.ip_forward = 1
net.ipv4.tcp_tw_recycle = 0
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
二、部署docker
2.1 具体安装不做演示,配置参照如下
vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://hub-mirror.c.163.com","https://registry.aliyuncs.com","https://registry.docker-cn.com","https://docker.mirrors.ustc.edu.cn"],
"data-root": "/data/docker",
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": { "max-size": "300m","max-file": "3" },
"live-restore": true
}
三、部署k8s基础命令
3.1 添加k8s阿里云的yum源
cat > /etc/yum.repos.d/kubernetes.repo << EOF[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
3.2 查看最新可安装的软件
]# yum --disablerepo="*" --enablerepo="kubernetes" list available
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
kubernetes | 1.4 kB 00:00:00
kubernetes/primary | 137 kB 00:00:00
kubernetes 1022/1022
可安装的软件包
cri-tools.x86_64 1.26.0-0 kubernetes
kubeadm.x86_64 1.28.2-0 kubernetes
kubectl.x86_64 1.28.2-0 kubernetes
kubelet.x86_64 1.28.2-0 kubernetes
kubernetes-cni.x86_64 1.2.0-0 kubernetes
rkt.x86_64
3.3 安装kubeadm、kubectl、kubelet
]# yum install -y kubelet-1.28.2 kubeadm-1.28.2 kubectl-1.28.2
]# systemctl start kubelet
]# systemctl enable kubelet
四、部署集群
4.1 初始化master
kubeadm init --apiserver-advertise-address=192.168.100.101 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.28.0 --service-cidr=10.140.0.0/16 --pod-network-cidr=10.240.0.0/16
参数注释:
–apiserver-advertise-address
指明用Master的哪个interface与Cluster 的其他节点通信。 如果Master有多个interface, 建议明确指定, 如果 不指定, kubeadm会自动选择有默认网关的interface。
–pod-network-cidr
选择一个Pod网络插件,并检查它是否需要在初始化Master时指定一些参数,它的值取决于你在下一步选择的哪个网络网络插件,这里选择Flannel的网络插件参数为 10.244.0.0/16。Calico网络为192.168.0.0/16。参考:Installing a pod network add-on
-service-cidr
选择service网络
–image-repository
使用kubeadm config images pull来预先拉取初始化需要用到的镜像,用来检查是否能连接到Kubenetes的Registries。
Kubenetes默认Registries地址是k8s.gcr.io,很明显,在国内并不能访问gcr.io,因此在kubeadm v1.13之前的版本,安装起来非常麻烦,但是在1.13版本中终于解决了国内的痛点,其增加了一个--image-repository参数,默认值是k8s.gcr.io,我们将其指定为国内镜像地址:registry.aliyuncs.com/google_containers。
–kubernetes-version
默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本来跳过网络请求。
4.2 报错问题及处理
问题一
# 问题一
[init] Using Kubernetes version: v1.28.2
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: time="2024-03-05T11:40:45+08:00" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
# 解决方案
查看版本都没有问题,启动状态也都正常
[root@nacos ~]# containerd -v
containerd containerd.io 1.6.26 3dd1e886e55dd695541fdcd67420c2888645a495
[root@nacos ~]# docker -v
Docker version 24.0.7, build afdd53b
编辑以下文件,将下面一行内容注释掉
~]# vim /etc/containerd/config.toml
#disabled_plugins = ["cri"]
保存退出重启containerd 后重新初始化成功
原因参考:https://blog.csdn.net/mo_sss/article/details/134855578
报错内容中的内容分析
CRI Container Runtime Interface 容器运行时接口
container runtime is not running 容器运行时未启动
validate service connection 无效的服务连接
CRI v1 runtime API is not implemented for endpoint “unix:///var/run/containerd/containerd.sock” 容器运行时接口 v1 运行时 接口 没有实现节点文件sock,应该就是此文件未找到
containerd安装的默认禁用(重点)
使用安装包安装的containerd会默认禁用作为容器运行时的功能,即安装包安装containerd后默认禁用containerd作为容器运行时
这个时候使用k8s就会报错了,因为没有容器运行时可以用
开启方法就是将/etc/containerd/config.toml文件中的disabled_plugins的值的列表中不包含cri
修改后重启containerd才会生效
问题二
# 如果kubernets初始化时失败后,第二次再次执行会初始化命令会报错,这时需要进行重置
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
# 解决方法
kubeadm reset
问题三
# 服务器重启后初始化出现如下问题
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables does not exist
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
# 解决:驱动加载
modprobe br_netfilter
bridge
问题四
# 出现如下报错
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all running Kubernetes containers by using crictl:
- 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock ps -a | grep kube | grep -v pause'
you have found the failing container, you can inspect its logs with:
- 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock logs CONTAINERID'
error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster
To see the stack trace of this error execute with --v=5 or higher
查看
~ #] journalctl -xeu kubelet
3月 05 15:34:31 master kubelet[3753]: E0305 15:34:31.924406 3753 eviction_manager.go:258] "Eviction manager: failed to get summary stats" err="failed to get node info: node \"master\" not found"
3月 05 15:34:33 master kubelet[3753]: E0305 15:34:33.467480 3753 event.go:289] Unable to write event: '&v1.Event{TypeMeta:v1.TypeMeta{Kind:"", APIVersion:""}, ObjectMeta:v1.ObjectMeta{Name:"master.17b9cdcc77bcf4b9", GenerateName:"", Namespace:"default", SelfLink:"", UID:"", ResourceVersion:"", Generation:0, CreationTimestamp:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), DeletionTimestamp:<nil>, DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]v1.OwnerReference(nil), Finalizers:[]string(nil), ManagedFields:[]v1.ManagedFieldsEntry(nil)}, InvolvedObject:v1.ObjectReference{Kind:"Node", Namespace:"", Name:"master", UID:"master", APIVersion:"", ResourceVersion:"", FieldPath:""}, Reason:"NodeHasSufficientMemory", Message:"Node master status is now: NodeHasSufficientMemory", Source:v1.EventSource{Component:"kubelet", Host:"master"}, FirstTimestamp:time.Date(2024, time.March, 5, 15, 30, 11, 629708473, time.Local), LastTimestamp:time.Date(2024, time.March, 5, 15, 30, 11, 629708473, time.Local), Count:1, Type:"Normal", EventTime:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Series:(*v1.EventSeries)(nil), Action:"", Related:(*v1.ObjectReference)(nil), ReportingController:"kubelet", ReportingInstance:"master"}': 'Post "https://192.168.100.101:6443/api/v1/namespaces/default/events": dial tcp 192.168.100.101:6443: connect: connection refused'(may retry after sleeping)
3月 05 15:34:36 master kubelet[3753]: E0305 15:34:36.225841 3753 controller.go:146] "Failed to ensure lease exists, will retry" err="Get \"https://192.168.100.101:6443/apis/coordination.k8s.io/v1/namespaces/kube-node-lease/leases/master?timeout=10s\": dial tcp 192.168.100.101:6443: connect: connection refused" interval="7s"
3月 05 15:34:36 master kubelet[3753]: I0305 15:34:36.421728 3753 kubelet_node_status.go:70] "Attempting to register node" node="master"
3月 05 15:34:36 master kubelet[3753]: E0305 15:34:36.422349 3753 kubelet_node_status.go:92] "Unable to register node with API server" err="Post \"https://192.168.100.101:6443/api/v1/nodes\": dial tcp 192.168.100.101:6443: connect: connection refused" node="master"
# 出错原因分析:
拉取 registry.k8s.io/pause:3.6 镜像失败 导致sandbox 创建不了而报错
# 解决方法:
# 生成 containerd 的默认配置文件
containerd config default > /etc/containerd/config.toml
# 查看 sandbox 的默认镜像仓库在文件中的第几行
cat /etc/containerd/config.toml | grep -n "sandbox_image"
# 使用 vim 编辑器 定位到 sandbox_image,将 仓库地址修改成 k8simage/pause:3.6
vim /etc/containerd/config.toml
sandbox_image = " registry.aliyuncs.com/google_containers/pause:3.6"
# 重启 containerd 服务
systemctl daemon-reload
systemctl restart containerd.service
初始化完成后会生成一串命令用于node节点的加入,如下记录下来
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.100.101:6443 --token jcdduw.3wfskykjk7gwdf1u \
--discovery-token-ca-cert-hash sha256:dd3cb5208a4ca032e85a5a30b9b02f963aff2fece13045cf8c74d7b9ed7f6098
4.2 关于token
注意token一般24小时候就会过期
查看当前token
[root@master ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
jcdduw.3wfskykjk7gwdf1u 8h 2024-03-06T09:40:51Z authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token
查看本机sha256值
[root@master ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
dd3cb5208a4ca032e85a5a30b9b02f963aff2fece13045cf8c74d7b9ed7f6098
重新生成token
[root@master ~]# kubeadm token create
重新生成token并打印出join命令
[root@master ~]# kubeadm token create --print-join-command
kubeadm join 192.168.100.101:6443 --token fpjwdf.p9bnbqf7cpvf1amc --discovery-token-ca-cert-hash sha256:dd3cb5208a4ca032e85a5a30b9b02f963aff2fece13045cf8c74d7b9ed7f6098
如果要加入master节点,需要先生成certificate-key(1.16版本前参数为--experimental-upload-certs,1.16及1.16版本以后为--upload-certs)
[root@master ~]# kubeadm init phase upload-certs --upload-certs
I0306 09:04:33.508490 63805 version.go:256] remote version is much newer: v1.29.2; falling back to: stable-1.28
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
820908fa5d83b9a7314a58147b80d0dc81b4f7469c9c8f72fb49b4fba2652c29
结合上面join和certs的(同样,1.16版本前参数为--experimental-control-plane --certificate-key ,1.16及1.16版本以后为--control-plane --certificate-key)
[root@master2 ~]# kubeadm join 192.168.100.101:6443 --token fpjwdf.p9bnbqf7cpvf1amc --discovery-token-ca-cert-hash sha256:dd3cb5208a4ca032e85a5a30b9b02f963aff2fece13045cf8c74d7b9ed7f6098 --control-plane --certificate-key 820908fa5d83b9a7314a58147b80d0dc81b4f7469c9c8f72fb49b4fba2652c29
4.3 配置kubectl
接着执行以下命令,让本机可以执行bubectl命令
[root@master ~]# mkdir -p $HOME/.kube
[root@master ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master ~]# chown $(id -u):$(id -g) $HOME/.kube/config
如果是root用户也可以直接使用以下命令
[root@master ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" > /etc/profile.d/kubeconfig.sh
[root@master ~]# source /etc/profile.d/kubeconfig.sh
将admin.conf拷贝到其他需要使用kunectl命令的node节点
[root@master ~]# scp /etc/kubernetes/admin.conf root@192.168.100.102:/etc/kubernetes/
[root@master ~]# scp /etc/kubernetes/admin.conf root@192.168.100.103:/etc/kubernetes/
在node节点上执行下面命令使kubectl临时生效
]# export KUBECONFIG=/etc/kubernetes/admin.conf
永久生效
]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" > /etc/profile.d/kubeconfig.sh
]# source /etc/profile.d/kubeconfig.sh
]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady control-plane 20h v1.28.2
node1 NotReady <none> 5h12m v1.28.2
node2 NotReady <none> 4h37m v1.28.2
4.4 加入work节点
在除master外其他node节点执行上面的join命令,加入k8s集群
]# kubeadm join 192.168.100.101:6443 --token jcdduw.3wfskykjk7gwdf1u \
--discovery-token-ca-cert-hash sha256:dd3cb5208a4ca032e85a5a30b9b02f963aff2fece13045cf8c74d7b9ed7f6098
注意:移除node节点
[root@master ~]# kubectl drain node2 --delete-local-data --force --ignore-daemonsets
Flag --delete-local-data has been deprecated, This option is deprecated and will be deleted. Use --delete-emptydir-data.
node/node2 cordoned
Warning: ignoring DaemonSet-managed Pods: kube-system/kube-proxy-9pscb
node/node2 drained
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady control-plane 15h v1.28.2
node1 NotReady <none> 30m v1.28.2
node2 NotReady,SchedulingDisabled <none> 28m v1.28.2
[root@master ~]# kubectl delete node node2
node "node2" deleted
#在被删除的node节点中清空集群数据信息【被删除节点执行】:
#清空前:
[root@localhost overlay2]# cd /etc/kubernetes/
[root@localhost kubernetes]# ls
kubelet.conf manifests pki
#清空
[root@localhost kubernetes]# kubeadm reset -f
[preflight] Running pre-flight checks
W0306 09:21:12.767822 100185 removeetcdmember.go:106] [reset] No kubeadm config, using etcd pod spec to get data directory
[reset] Deleted contents of the etcd data directory: /var/lib/etcd
[reset] Stopping the kubelet service
[reset] Unmounting mounted directories in "/var/lib/kubelet"
[reset] Deleting contents of directories: [/etc/kubernetes/manifests /var/lib/kubelet /etc/kubernetes/pki]
[reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf]
The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d
The reset process does not reset or clean up iptables rules or IPVS tables.
If you wish to reset iptables, you must do so manually by using the "iptables" command.
If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar)
to reset your system's IPVS tables.
The reset process does not clean your kubeconfig files and you must remove them manually.
Please, check the contents of the $HOME/.kube/config file.
# 清空后
[root@localhost kubernetes]# ls
manifests pki
# 重新加入
[root@localhost kubernetes]# kubeadm join 192.168.100.101:6443 --token fpjwdf.p9bnbqf7cpvf1amc --discovery-token-ca-cert-hash sha256:dd3cb5208a4ca032e85a5a30b9b02f963aff2fece13045cf8c74d7b9ed7f6098
在master节点查看nodes状态
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady control-plane 15h v1.28.2
node1 NotReady <none> 35m v1.28.2
node2 NotReady <none> 10s v1.28.2
五、安装CNI网络插件
下面两种插件二选一,master上执行,如果是云服务器建议按照flannel,calico可能会和云网络环境有冲突
安装flannel网络插件
下载yaml文件,网咯会有波动,可以多wget几次
[root@master ~]# mkdir /data/k8s
[root@master ~]# cd /data/k8s/
[root@master ~]# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
修改kube-flannel.yml中net-conf.json下面的网段为上面init pod-network-cidr的网段地址(必须正确否则会导致集群网络问题)
[root@master ~]# sed -i 's/10.244.0.0/10.240.0.0/' kube-flannel.yml
安装插件
[root@master ~]# kubectl apply -f kube-flannel.yml
[root@master k8s]# kubectl get pods -n kube-flannel
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-2dlk6 1/1 Running 0 33s
kube-flannel-ds-nq549 1/1 Running 0 33s
kube-flannel-ds-tjg7r 1/1 Running 0 33s
查看nodes节点状态已经都变成ready了
[root@master k8s]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane 16h v1.28.2
node1 Ready
node2 Ready
六、集群测试
创建一个pod,并确实是否运行正常
[root@master k8s]# kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
[root@master k8s]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-7854ff8877-nl4t2 1/1 Running 0 34s
[root@master k8s]# kubectl expose deployment nginx --port=80 --type=NodePort
service/nginx exposed
[root@master k8s]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.140.0.1 <none> 443/TCP 17h
service/nginx NodePort 10.140.115.205 <none> 80:31726/TCP 30s
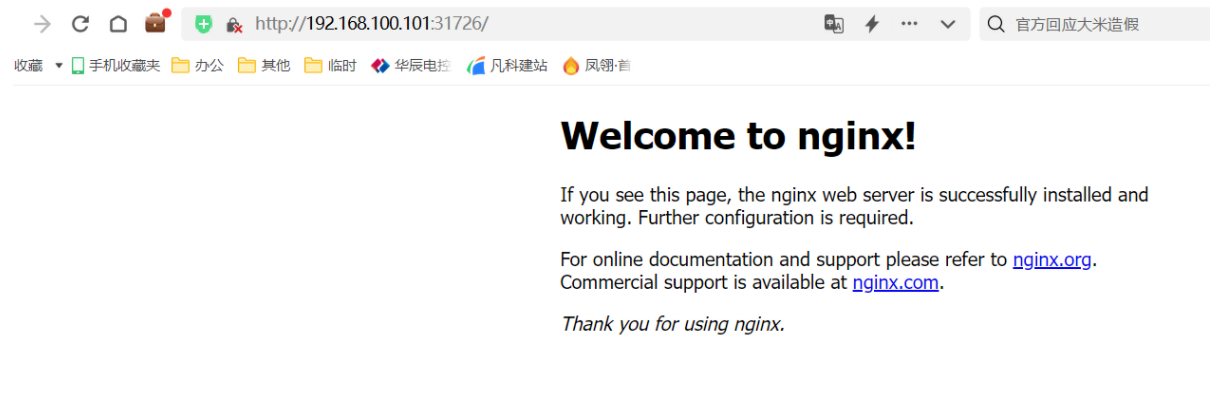
另外两个节点查看service
[root@node1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.140.0.1 <none> 443/TCP 20h
nginx NodePort 10.140.115.205 <none> 80:31726/TCP 173m
[root@node2 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.140.0.1 <none> 443/TCP 20h
nginx NodePort 10.140.115.205 <none> 80:31726/TCP 178m
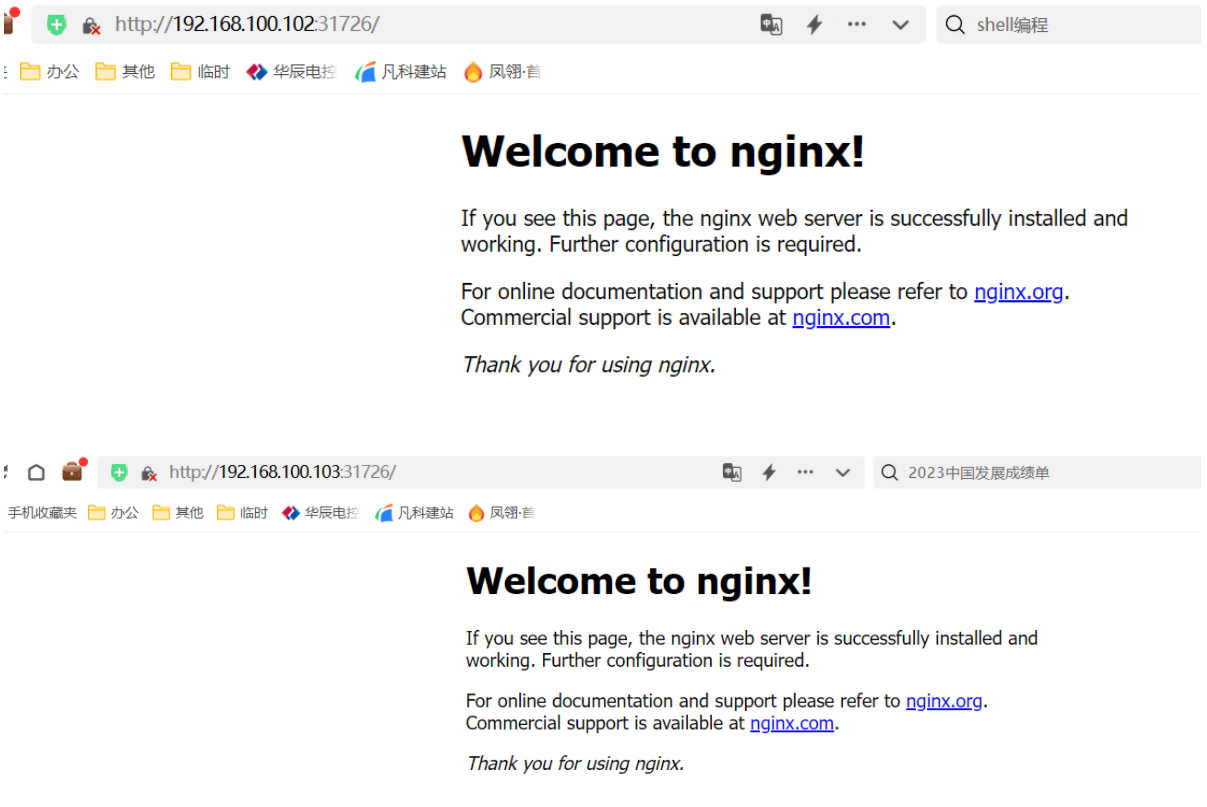
至此k8s快速部署完成
七、k8s常用命令
查看pod,service,endpoints,secret等等的状态
kubectl get 组件名 # 例如kubectl get pod 查看详细信息可以加上-o wide 其他namespace的指定 -n namespace名
创建,变更一个yaml文件内资源,也可以是目录,目录内包含一组yaml文件(实际使用中都是以yaml文件为主,直接使用命令创建pod的很少,推荐多使用yaml文件)
kubectl apply -f xxx.yaml # 例如kubectl apply -f nginx.yaml 这里是如果没有则创建,如果有则变更,比create好用
删除一个yaml文件内资源,也可以是目录,目录内包含一组yaml文件
kubectl delete -f xxx.yaml # 例如kubectl delete -f nginx.yaml
查看资源状态,比如有一组deployment内的pod没起来,一般用于pod调度过程出现的问题排查
kubectl describe pod pod名 # 先用kubectl get pod查看 有异常的复制pod名使用这个命令
查看pod日志,用于pod状态未就绪的故障排查
kubectl logs pod名 # 先用kubectl get pod查看 有异常的复制pod名使用这个命令
查看node节点或者是pod资源(cpu,内存资源)使用情况
kubectl top 组件名 # 例如kubectl top node kubectl top pod
进入pod内部
kubectl exec -ti pod名 /bin/bash # 先用kubectl get pod查看 有需要的复制pod名使用这个命令

 浙公网安备 33010602011771号
浙公网安备 33010602011771号