第十四章 二进制部署k8s集群的平滑升级
1、软件包下载
去github上下载较新的Kubernetes软件包https://github.com/

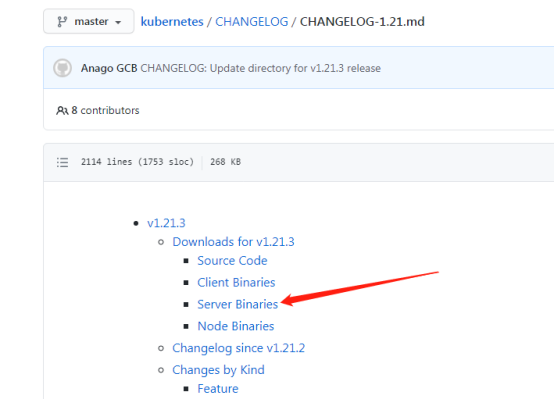
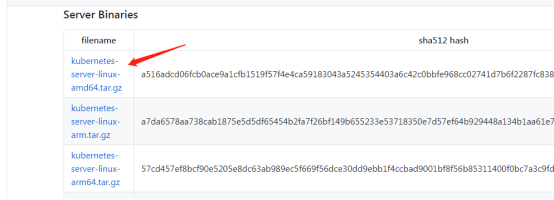
2、升级说明
- 升级包括master节点升级和node节点的升级,本章升级至v1.15.12;
- Master节点的服务包括:apiserver、controller-manager、kube-scheduler;
- Node节点的服务包括:kubelet和kube-proxy;
- 由于apiserver被nginx代理,所以在升级的时候需要操作操作nginx注释升级节点,避免带来无法访问的情况;
- 我们的master节点和node都是在同一个集群服务器上,所以一起进行操作;
3、确定节点升级顺序
查看节点信息
[root@hdss7-21 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
hdss7-21.host.com Ready <none> 14d v1.14.10
hdss7-22.host.com Ready <none> 14d v1.14.10
查看pod分布状态,尽量选择较少pod的节点先进行迁移
[root@hdss7-21 ~]# kubectl get pod -o wide -n kube-system
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-64f49f5655-smzzz 1/1 Running 6 8d 172.7.21.4 hdss7-21.host.com <none> <none>
kubernetes-dashboard-99ff79fcd-khl8z 1/1 Running 2 4d 172.7.22.4 hdss7-22.host.com <none> <none>
traefik-ingress-2svq6 1/1 Running 3 5d 172.7.21.5 hdss7-21.host.com <none> <none>
traefik-ingress-rcd28 1/1 Running 3 5d 172.7.22.3 hdss7-22.host.com <none> <none>
由于分布差不多,我们选择先升级10.4.7.21服务器上的节点
4、修改代理nginx配置
在10.4.7.21和22上都操作,以21为例
注释apiserver升级节点的服务器
[root@hdss7-11 ~]# vim /etc/nginx/nginx.conf
upstream kube-apiserver {
# server 10.4.7.21:6443 max_fails=3 fail_timeout=30s;
server 10.4.7.22:6443 max_fails=3 fail_timeout=30s;
}
[root@hdss7-11 ~]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
[root@hdss7-11 ~]# nginx -s reload
5、删除第一个节点
将节点调成不可调度状态
[root@hdss7-21 ~]# kubectl cordon hdss7-21.host.com
node/hdss7-21.host.com cordoned
当节点设置成不可调度状态之后,新启动的 pod 不会调度到此节点上,但是该节点上正在运行的 Pod 将不会被影响。
驱逐节点上的pod
[root@hdss7-21 ~]# kubectl drain hdss7-21.host.com --delete-local-data --ignore-daemonsets --force
node/hdss7-21.host.com already cordoned
WARNING: ignoring DaemonSet-managed Pods: default/nginx-ds-2rj9d, kube-system/traefik-ingress-2svq6
evicting pod "coredns-64f49f5655-smzzz"
evicting pod "nginx-dp-86678bb55c-tklvc"
pod/nginx-dp-86678bb55c-tklvc evicted
pod/coredns-64f49f5655-smzzz evicted
node/hdss7-21.host.com evicted
注释:
--delete-local-data 即使pod使用了emptyDir也删除 --ignore-daemonsets 忽略deamonset控制器的pod,如果不忽略,daemonset控制器控制的pod被删除后可能马上又在此节点上启动起来,会成为死循环; --force 不加force参数只会删除该NODE上由ReplicationController, ReplicaSet, DaemonSet,StatefulSet or Job创建的Pod,加了后还会删除'裸奔的pod'(没有绑定到任何replication controller)
再次查看pod分布
[root@hdss7-21 ~]# kubectl get pod -o wide -n kube-system
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-64f49f5655-n2pl7 1/1 Running 0 39s 172.7.22.7 hdss7-22.host.com <none> <none>
kubernetes-dashboard-99ff79fcd-khl8z 1/1 Running 2 4d 172.7.22.4 hdss7-22.host.com <none> <none>
traefik-ingress-2svq6 1/1 Running 3 5d 172.7.21.5 hdss7-21.host.com <none> <none>
traefik-ingress-rcd28 1/1 Running 3 5d 172.7.22.3 hdss7-22.host.com <none> <none>
除了daemonset的pod已被移动到10.4.7.22接节点上
测试重新启动的coredns是否生效
[root@hdss7-21 ~]# dig -t A nginx-dp.default.svc.cluster.local @192.168.0.2 +short
192.168.191.8
删除节点
[root@hdss7-21 ~]# kubectl delete node hdss7-21.host.com
node "hdss7-21.host.com" deleted
6、升级第一个节点
配置新版本
[root@hdss7-21 ~]# cd /opt/src/
[root@hdss7-21 src]# tar -zxvf kubernetes-server-linux-amd64-v1.15.12.tar.gz
[root@hdss7-21 src]# mv kubernetes /opt/kubernetes-v1.15.12
[root@hdss7-21 src]# cd /opt/kubernetes-v1.15.12/
[root@hdss7-21 kubernetes-v1.15.12]# rm -f kubernetes-src.tar.gz
[root@hdss7-21 kubernetes-v1.15.12]# cd server/bin/
[root@hdss7-21 bin]# rm -f *.tar *_tag
[root@hdss7-21 bin]# ll
总用量 677292
-rwxr-xr-x 1 root root 50581504 6月 16 21:10 apiextensions-apiserver
-rwxr-xr-x 1 root root 44638208 6月 16 21:10 kubeadm
-rwxr-xr-x 1 root root 48525312 6月 16 21:10 kube-aggregator
-rwxr-xr-x 1 root root 122097664 6月 16 21:10 kube-apiserver
-rwxr-xr-x 1 root root 116301824 6月 16 21:10 kube-controller-manager
-rwxr-xr-x 1 root root 46419968 6月 16 21:10 kubectl
-rwxr-xr-x 1 root root 54980712 6月 16 21:10 kubectl-convert
-rwxr-xr-x 1 root root 118151728 6月 16 21:10 kubelet
-rwxr-xr-x 1 root root 43139072 6月 16 21:10 kube-proxy
-rwxr-xr-x 1 root root 47112192 6月 16 21:10 kube-scheduler
-rwxr-xr-x 1 root root 1593344 6月 16 21:10 mounter
[root@hdss7-21 bin]# mkdir certs
[root@hdss7-21 bin]# mkdir /opt/kubernetes-v1.15.12/conf
拷贝证书
[root@hdss7-21 bin]# cp /opt/kubernetes/server/bin/certs/* certs/
[root@hdss7-21 bin]# ls certs/
apiserver-key.pem ca-key.pem client-key.pem kubelet-key.pem kube-proxy-client-key.pem
apiserver.pem ca.pem client.pem kubelet.pem kube-proxy-client.pem
拷贝服务启动脚本
[root@hdss7-21 bin]# cp /opt/kubernetes/server/bin/*.sh .
[root@hdss7-21 bin]# ls
apiextensions-apiserver kube-apiserver kubectl kube-proxy mounter
certs kube-apiserver-startup.sh kubectl-convert kube-proxy-startup.sh
kubeadm kube-controller-manager kubelet kube-scheduler
kube-aggregator kube-controller-manager-startup.sh kubelet-startup.sh kube-scheduler-startup.sh
拷贝配置文件
[root@hdss7-21 bin]# cp /opt/kubernetes/conf/* /opt/kubernetes-v1.15.12/conf/
[root@hdss7-21 bin]# ls /opt/kubernetes-v1.15.12/conf/
audit.yaml k8s-node.yaml kubelet.kubeconfig kube-proxy.kubeconfig nginx-ds.yaml
重新创建软连接
[root@hdss7-21 bin]# cd /opt/
[root@hdss7-21 opt]# ll
总用量 24
drwx--x--x 4 root root 4096 7月 2 21:50 containerd
lrwxrwxrwx 1 root root 16 6月 8 20:36 etcd -> /opt/etcd-v3.3.1
drwxr-xr-x 5 etcd etcd 4096 7月 9 21:25 etcd-v3.3.1
lrwxrwxrwx 1 root root 20 7月 17 19:40 flannel -> /opt/flannel-v0.11.0
drwxr-xr-x 3 root root 4096 7月 28 20:05 flannel-v0.11.0
lrwxrwxrwx 1 root root 23 7月 10 20:17 kubernetes -> /opt/kubernetes-v1.14.10
drwxr-xr-x 5 root root 4096 7月 10 20:36 kubernetes-v1.14.10
drwxr-xr-x 6 root root 4096 7月 28 22:18 kubernetes-v1.15.12
drwxr-xr-x 2 root root 4096 7月 28 22:10 src
[root@hdss7-21 opt]# rm -rf kubernetes
[root@hdss7-21 opt]# ln -s /opt/kubernetes-v1.15.12 /opt/kubernetes
[root@hdss7-21 opt]# ll
总用量 24
drwx--x--x 4 root root 4096 7月 2 21:50 containerd
lrwxrwxrwx 1 root root 16 6月 8 20:36 etcd -> /opt/etcd-v3.3.1
drwxr-xr-x 5 etcd etcd 4096 7月 9 21:25 etcd-v3.3.1
lrwxrwxrwx 1 root root 20 7月 17 19:40 flannel -> /opt/flannel-v0.11.0
drwxr-xr-x 3 root root 4096 7月 28 20:05 flannel-v0.11.0
lrwxrwxrwx 1 root root 23 7月 28 22:20 kubernetes -> /opt/kubernetes-v1.15.12
drwxr-xr-x 5 root root 4096 7月 10 20:36 kubernetes-v1.14.10
drwxr-xr-x 6 root root 4096 7月 28 22:18 kubernetes-v1.15.12
drwxr-xr-x 2 root root 4096 7月 28 22:10 src
7、重启节点服务
[root@hdss7-21 opt]# supervisorctl status
etcd-server-7-21 RUNNING pid 6296, uptime 0:16:14
flanneld-7-21 RUNNING pid 7042, uptime 0:13:14
kube-apiserver-7-21 RUNNING pid 7165, uptime 0:12:24
kube-controller-manager-7-21 RUNNING pid 4675, uptime 0:19:03
kube-kubelet-7-21 RUNNING pid 7184, uptime 0:12:16
kube-proxy-7-21 RUNNING pid 4678, uptime 0:19:03
kube-scheduler-7-21 RUNNING pid 4673, uptime 0:19:03
重启node节点服务
[root@hdss7-21 opt]# supervisorctl restart kube-kubelet-7-21
[root@hdss7-21 opt]# supervisorctl restart kube-proxy-7-21
查看版本
[root@hdss7-21 opt]# kubectl get node
NAME STATUS ROLES AGE VERSION
hdss7-21.host.com Ready <none> 4d22h v1.15.12
hdss7-22.host.com Ready <none> 19d v1.14.10
重启master节点服务
[root@hdss7-21 opt]# supervisorctl restart kube-apiserver-7-21
[root@hdss7-21 opt]# supervisorctl restart kube-controller-manager-7-21
[root@hdss7-21 opt]# supervisorctl restart kube-scheduler-7-21
注意重启过程中可以查看日志,确保启动无问题。
8、修改代理nginx配置
修改11和12配置
[root@hdss7-11 ~]# vim /etc/nginx/nginx.conf
upstream kube-apiserver {
server 10.4.7.21:6443 max_fails=3 fail_timeout=30s;
# server 10.4.7.22:6443 max_fails=3 fail_timeout=30s;
}
[root@hdss7-11 ~]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
[root@hdss7-11 ~]# nginx -s reload
9、升级第二个节点
按照同样的方法对其余节点进行升级
在10.4.7.22上操作
最后检查服务启动状态和node节点版本
[root@hdss7-22 ~]# supervisorctl status
etcd-server-7-22 RUNNING pid 1235, uptime 1:10:58
flanneld-7-22 RUNNING pid 1203, uptime 1:10:59
kube-apiserver-7-22 RUNNING pid 25776, uptime 0:01:39
kube-controller-manager-7-22 RUNNING pid 26009, uptime 0:01:09
kube-kubelet-7-22 RUNNING pid 23925, uptime 0:06:08
kube-proxy-7-22 RUNNING pid 24142, uptime 0:05:38
kube-scheduler-7-22 RUNNING pid 26190, uptime 0:00:38
[root@hdss7-22 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
hdss7-21.host.com Ready <none> 4d22h v1.15.12
hdss7-22.host.com Ready <none> 6m12s v1.15.12
10、修改nginx代理
将配置文件改为原来状态
[root@hdss7-11 ~]# vim /etc/nginx/nginx.conf
upstream kube-apiserver {
server 10.4.7.21:6443 max_fails=3 fail_timeout=30s;
server 10.4.7.22:6443 max_fails=3 fail_timeout=30s;
}
[root@hdss7-11 ~]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
[root@hdss7-11 ~]# nginx -s reload
11、测试操作平台

12、重新分配pod节点
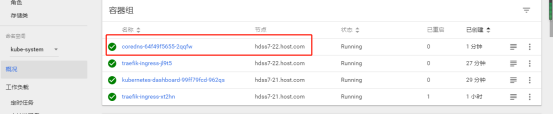
查看pod信息得知目前大部分的pod在10.4.7.21上,这不符合性能最优状态,我们可以在dashbard面板上删除一个pod,通过scheduler的计算,会在另外一个(22上)负载较少的node节点上重新启动这个pod
如下,删除coredns的pod
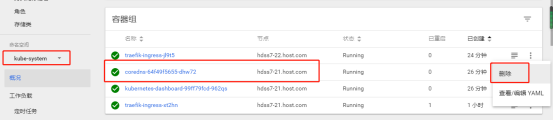
正在重启状态

启动后的状态