
三、Prometheus安装与部署
prometheus安装与部署
prometheus是一个开源系统监视和警报工具,自2012年成立以来,许多公司和组织都采用了Prometheus,该项目拥有非常活跃的开发人员和用户以及社区,它现在是一个独立的开源项目,独立于任何公司维护。为了强调这一点,并澄清项目的治理结构,普罗米修斯加入了cncf 。
笔记配套视频效果更佳哦,视频地址:https://edu.51cto.com/lecturer/14390454.html
1.Prometheus架构图
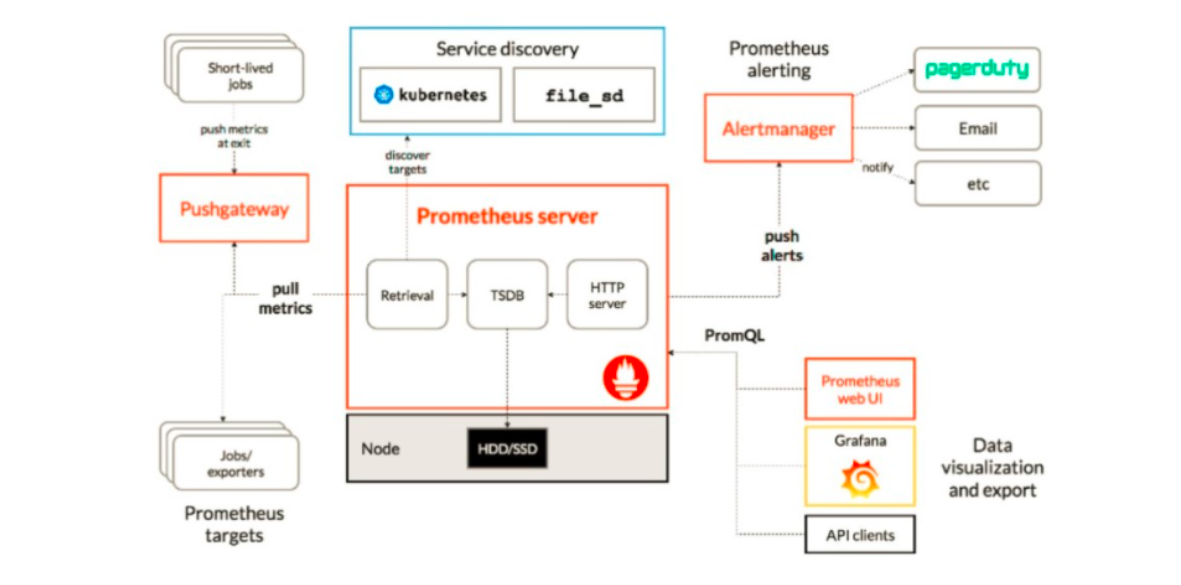
基础环境准备
#关闭防火墙firewalld
[root@prometheus ~]# systemctl disable firewalld
[root@prometheus ~]# systemctl stop firewalld
#关闭selinux
[root@prometheus ~]# sed -i '/^SELINUX=/c SELINUX=disabled' /etc/selinux/config
1.1安装prometueus
官网地址:https://prometheus.io/download/ 下载相应版本,安装到服务器上官网提供的是二进制版,解压就能用,不需要编译.
[root@prometheus ~]# wget https://github.com/prometheus/prometheus/releases/download/v2.32.1/prometheus-2.32.1.linux-amd64.tar.gz
[root@prometheus ~]# tar xf prometheus-2.32.1.linux-amd64.tar.gz -C /usr/local/
[root@prometheus ~]# mv /usr/local/prometheus-2.32.1.linux-amd64/ /usr/local/prometheus
[root@prometheus ~]# chmod +x /usr/local/prometheus/prom*
[root@prometheus ~]# cp -rp /usr/local/prometheus/promtool /usr/bin/
#配置开启启动,加入开机自启
[root@prometheus ~]# vim /usr/lib/systemd/system/prometheus.service
[root@prometheus ~]# cat /usr/lib/systemd/system/prometheus.service
[Unit]
Description=Prometheus server daemon
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --web.enable-lifecycle
Restart=on-failure
[Install]
WantedBy=multi-user.target
#启动prometheus并加入开机自启
[root@prometheus ~]# systemctl daemon-reload
[root@prometheus ~]# systemctl start prometheus.service
[root@prometheus ~]# systemctl enable prometheus.service
[root@prometheus ~]# systemctl status prometheus.service
#也可以利用自带的启动脚本启动
[root@prometheus ~]# /usr/local/prometheus/prometheus --config.file="/usr/local/prometheus/prometheus.yml" &
#确认端口
[root@prometheus ~]# lsof -i:9090
[root@prometheus ~]# ps aux |grep prometheus
#说明
[root@prometheus prometheus]# ./prometheus --help
usage: prometheus [<flags>]
The Prometheus monitoring server
Flags:
#帮助
-h, --help Show context-sensitive help (also try --help-long and --help-man).
#版本
--version Show application version.
#配置文件
--config.file="prometheus.yml"
Prometheus configuration file path.
#监听端口
--web.listen-address="0.0.0.0:9090"
Address to listen on for UI, API, and telemetry.
#空闲连接的超时时间
--web.read-timeout=5m Maximum duration before timing out read of the request, and closing idle connections.
#最大连接数
--web.max-connections=512 Maximum number of simultaneous connections.
#可从外部访问Prometheus的URL(例如,如果Prometheus是通过反向代理提供的)。 用于生成返回到Prometheus本身的相对和绝对链接。 如果URL包含路径部分,它将被用作Prometheus服务的所有HTTP端点的前缀。 如果省略,则会自动派生相关的URL组件。
--web.external-url=<URL> The URL under which Prometheus is externally reachable (for example, if Prometheus is served via a reverse proxy). Used for generating relative and absolute links back to
Prometheus itself. If the URL has a path portion, it will be used to prefix all HTTP endpoints served by Prometheus. If omitted, relevant URL components will be derived
automatically.
#内部路由的前缀。 默认为--web.external-url的路径。
--web.route-prefix=<path> Prefix for the internal routes of web endpoints. Defaults to path of --web.external-url.
#静态资源目录的路径,位于/ user
--web.user-assets=<path> Path to static asset directory, available at /user.
#启用是否通过HTTP请求重新加载
--web.enable-lifecycle Enable shutdown and reload via HTTP request.
#管理控制操作启用API端点
--web.enable-admin-api Enable API endpoints for admin control actions.
#模板目录的路径,位于/consoles
--web.console.templates="consoles"
Path to the console template directory, available at /consoles.
#控制台库目录的路径
--web.console.libraries="console_libraries"
Path to the console library directory.
#Prometheus实例页面的文档标题
--web.page-title="Prometheus Time Series Collection and Processing Server"
Document title of Prometheus instance.
#用于CORS来源的正则表达式。
--web.cors.origin=".*" Regex for CORS origin. It is fully anchored. Example: 'https?://(domain1|domain2)\.com'
#指标(数据)存储的基本路径
--storage.tsdb.path="data/"
Base path for metrics storage.
#将数据保留多长时间。 此标志已被弃用,请改用“ storage.tsdb.retention.time”。
--storage.tsdb.retention=STORAGE.TSDB.RETENTION
[DEPRECATED] How long to retain samples in storage. This flag has been deprecated, use "storage.tsdb.retention.time" instead.
#将数据保留多长时间。默认15天
--storage.tsdb.retention.time=STORAGE.TSDB.RETENTION.TIME
How long to retain samples in storage. When this flag is set it overrides "storage.tsdb.retention". If neither this flag nor "storage.tsdb.retention" nor
"storage.tsdb.retention.size" is set, the retention time defaults to 15d.
#可以为块存储的最大字节数。 支持的单位:KB,MB,GB,TB,PB。
--storage.tsdb.retention.size=STORAGE.TSDB.RETENTION.SIZE
[EXPERIMENTAL] Maximum number of bytes that can be stored for blocks. Units supported: KB, MB, GB, TB, PB. This flag is experimental and can be changed in future releases.
#不在数据目录中创建锁文件
--storage.tsdb.no-lockfile
Do not create lockfile in data directory.
#允许重叠的块,从而启用垂直压缩和垂直查询合并。
--storage.tsdb.allow-overlapping-blocks
[EXPERIMENTAL] Allow overlapping blocks, which in turn enables vertical compaction and vertical query merge.
#压缩tsdb WAL
--storage.tsdb.wal-compression
Compress the tsdb WAL.
#关闭或配置重新加载时等待刷写数据的时间
--storage.remote.flush-deadline=<duration>
How long to wait flushing sample on shutdown or config reload.
#在单个查询中通过远程读取接口返回的最大样本总数。 0表示没有限制。 对于流式响应类型,将忽略此限制。
--storage.remote.read-sample-limit=5e7
Maximum overall number of samples to return via the remote read interface, in a single query. 0 means no limit. This limit is ignored for streamed response types.
#并发远程读取调用的最大数目。 0表示没有限制。
--storage.remote.read-concurrent-limit=10
Maximum number of concurrent remote read calls. 0 means no limit.
#用于流式传输远程读取响应类型的单个帧中的最大字节数。 请注意,客户端也可能会限制帧大小。 1MB为默认情况下由protobuf推荐
--storage.remote.read-max-bytes-in-frame=1048576
Maximum number of bytes in a single frame for streaming remote read response types before marshalling. Note that client might have limit on frame size as well. 1MB as
recommended by protobuf by default.
#容忍中断以恢复警报“ for”状态的最长时间。
--rules.alert.for-outage-tolerance=1h
Max time to tolerate prometheus outage for restoring "for" state of alert.
#警报和恢复的“ for”状态之间的最短持续时间。 仅对于配置的“ for”时间大于宽限期的警报,才保持此状态。
--rules.alert.for-grace-period=10m
Minimum duration between alert and restored "for" state. This is maintained only for alerts with configured "for" time greater than grace period.
#将警报重新发送到Alertmanager之前等待的最短时间。
--rules.alert.resend-delay=1m
Minimum amount of time to wait before resending an alert to Alertmanager.
#等待的Alertmanager通知的队列容量。
--alertmanager.notification-queue-capacity=10000
The capacity of the queue for pending Alertmanager notifications.
#向Alertmanager发送警报的超时。
--alertmanager.timeout=10s
Timeout for sending alerts to Alertmanager.
#在表达式求值期间检索指标的最大回溯持续时间。
--query.lookback-delta=5m The maximum lookback duration for retrieving metrics during expression evaluations.
#最大查询时间。
--query.timeout=2m Maximum time a query may take before being aborted.
#最大查询并发数
--query.max-concurrency=20
Maximum number of queries executed concurrently.
#单个查询可以加载到内存中的最大样本数。 请注意,如果查询尝试将更多的样本加载到内存中,则查询将失败,因此这也限制了查询可以返回的样本数。
--query.max-samples=50000000
Maximum number of samples a single query can load into memory. Note that queries will fail if they try to load more samples than this into memory, so this also limits the
number of samples a query can return.
#日志级别
--log.level=info Only log messages with the given severity or above. One of: [debug, info, warn, error]
#日志格式
--log.format=logfmt Output format of log messages. One of: [logfmt, json]
Prometheus的配置文件是YAML格式,大致分为四大块,包括: global、 alerting、rule_ files、 scrape configs。在下面的prometheus.ym 配置文件中来描述其用途。
笔记配套视频效果更佳哦,视频地址:https://edu.51cto.com/lecturer/14390454.html
[root@prometheus ~]# cat /usr/local/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
#minute. Server端去endpoint端拉取数据的时间间隔(频率),这个值也表示是时间序列的颗粒度,可以被局部配置覆盖。
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
#minute.Server.该参数用于控制记录规则和报警规则的执行间隔(频率),Prometheus使用记录规则来创建新的时间序列并生成告警(Prometheus会拉取大 量的时间序列度量数据,如CPU、内存、磁盘等,但这些单个的度量数据不能直接拿来告警,需要先用PromQL来编写规则得到我们想要的指标值,然后给这个规则定义一个名字,这个编写好的规则我们称之为记录规则,同时,这也是一个新的时间序列数据,这个已定义的规则名可以在告警规则中引用)。
# scrape_timeout is set to the global default (10s).
#scrape_ timeout: 30s #scrape_ timeout is set to the global default (10s).Server 拉取数据的超时时间,该值不能大于scrape_ interval的值。
# Alertmanager configuration,用于设置Prometheus的告警,Prometheus本身不支持告警通知功能,需要借助Alertmanager组件,详细可参考Alertmanager使用篇。
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.用来指定包含记录规则或告警规则的文件列表。
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
#用来配置Prometheus要拉取的目标endpoint端点(即要监控的目标资源)。目前配置是基于静态列表方式,后续还可以配置成文件读取和自动发现等方式。
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
1.2浏览器访问
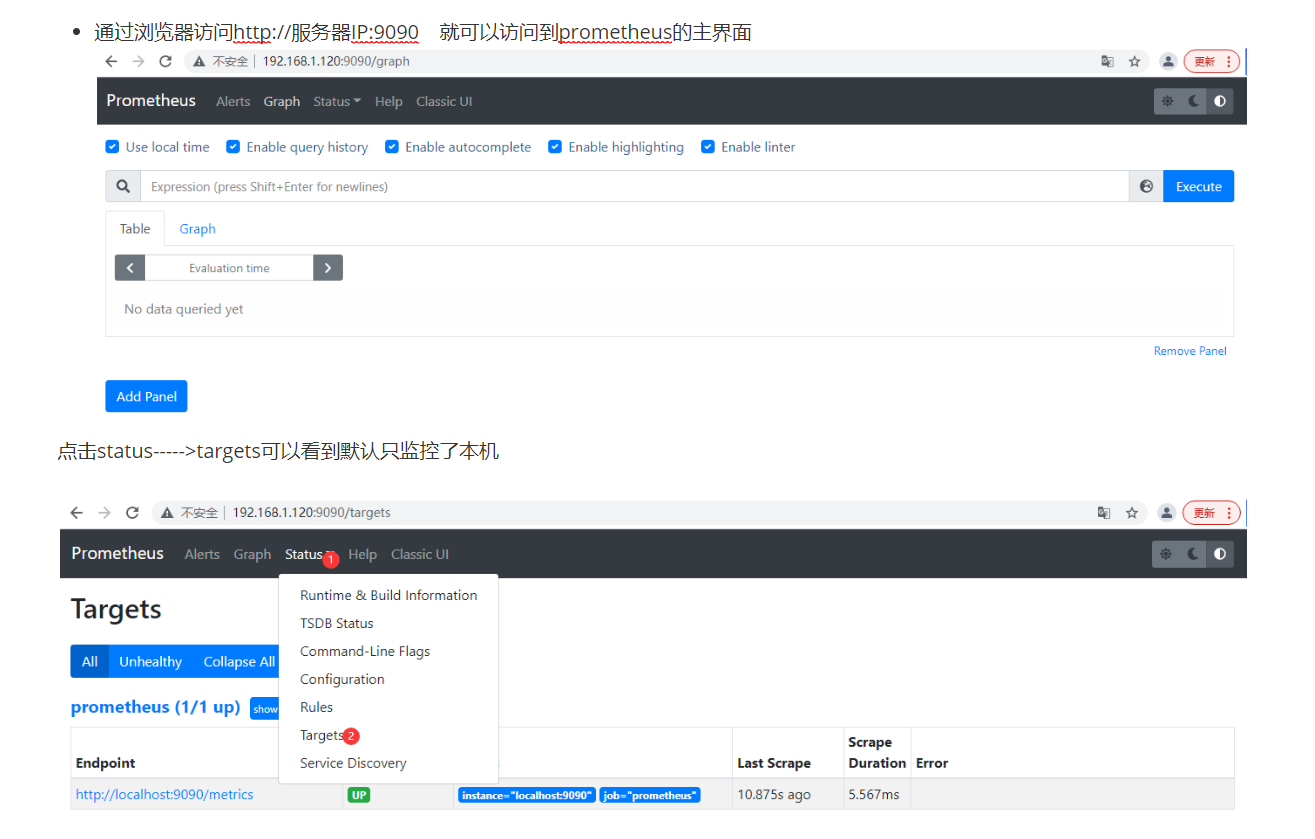
- 在web界面可以通过关键字查询项
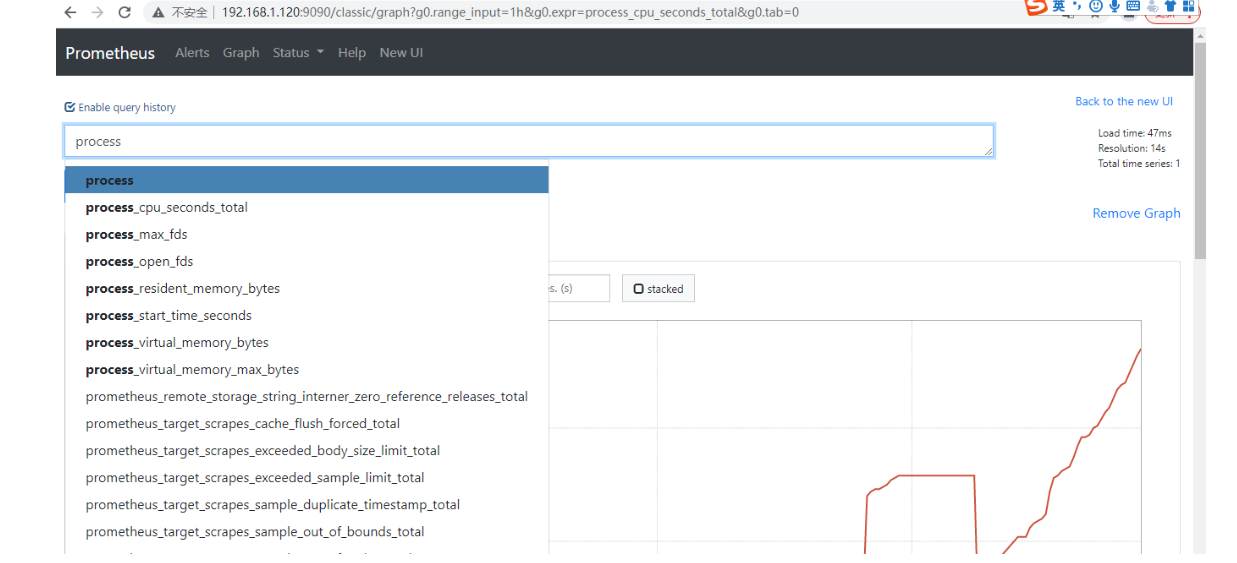
#监控项
1.Prometheus服务器已服务的/metrics请求的总数,在控制台输入进行查询
promhttp_metric_handler_requests_total
2.如果我们只对导致HTTP代码200的请求感兴趣,我们可以使用此查询来检索该信息:
promhttp_metric_handler_requests_total{code="200"}
3.计算返回的时间序列总数,可以写成
count(promhttp_metric_handler_requests_total)
4.例如,输入以下表达式来绘制在自我抓取的Prometheus中发生的返回状态代码200的每秒HTTP请求率:
rate(promhttp_metric_handler_requests_total{code="200"}[1m])

二、node_export的部署
监控远程Linux主机
① 在远程linux主机(被监控端)上安装node_exporter组件
# 下载址:https://prometheus.io/download/
[root@web01 ~]# wget https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz
[root@web01 ~]# ls
anaconda-ks.cfg node_exporter-1.3.1.linux-amd64.tar.gz
[root@web01 ~]# tar xf node_exporter-1.3.1.linux-amd64.tar.gz -C /usr/local
[root@web01 ~]# mv /usr/local/node_exporter-1.3.1.linux-amd64/ /usr/local/node_exporter
#启动agent
[root@web01 ~]# ls /usr/local/node_exporter/
LICENSE node_exporter NOTICE
[root@web01 ~]# nohup /usr/local/node_exporter/node_exporter &
#默认监听端口9100
[root@web01 ~]# lsof -i:9100
#加入开机启动,使用system管理
[root@web01 ~]# vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
[Service]
ExecStart=/usr/local/node_exporter/node_exporter --web.listen-address=:9100 --collector.systemd --collector.systemd.unit-whitelist="(ssh|docker|rsyslog|redis-server).service" --collector.textfile.directory=/usr/local/node_exporter/textfile.collected
Restart=on-failure
[Install]
WantedBy=multi-user.target
#启动
[root@web01 ~]# systemctl enable node_exporter
[root@web01 ~]# systemctl start node_exporter.service
浏览器访问:192.168.1.100:9100/metrics
访问:192.168.1.100:9100/metrics
笔记配套视频效果更佳哦,视频地址:https://edu.51cto.com/lecturer/14390454.html
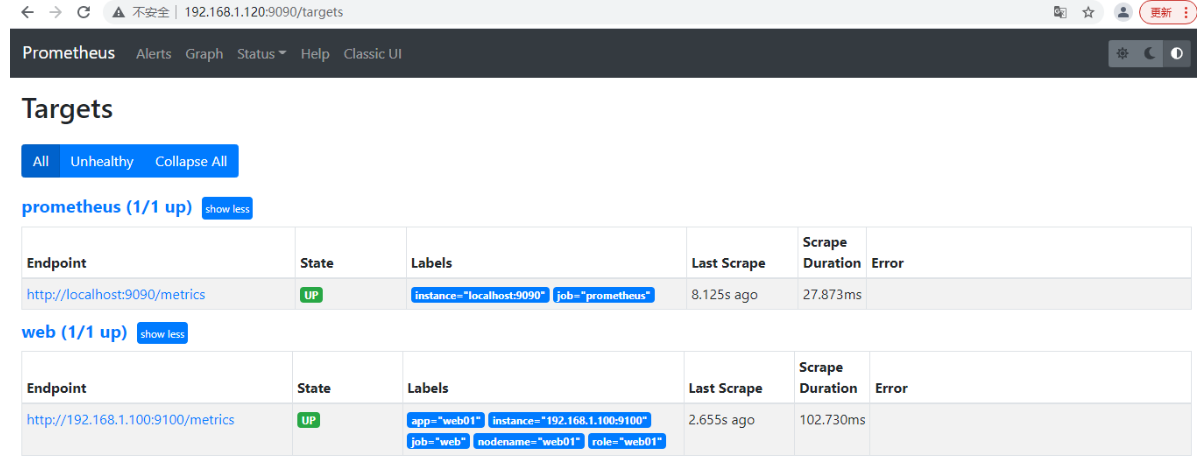
在prometheus服务器上配置node节点
[root@prometheus ~]# cat /usr/local/prometheus/prometheus.yml
..........
- job_name: 'web' #表示被监控的机器名称
static_configs:
- targets: ['192.168.1.100:9100'] #被监控机器的ip:9100端口
labels:
app: web01
nodename: web01
role: web01
[root@prometheus ~]# systemctl daemon-reload
[root@prometheus ~]# systemctl restart prometheus.service
二、启动参数说明
1、启用systemd收集器
systemd收集器记录systemd中的服务和系统状态。首先需要通过参数--collector.systemd启用该收集器,同时如果不希望收集所有的服务,只收集部分关键服务, node_ exporter在启动时可以使用--collector.systemd.unit-whitelist参数配置指定的服务。
2、指定textfile收集器目录
使用textfile收集器可以让用户添加自定义的度量指标,功能类似pushgateway,同zabbix中自定义的item-样,只要将度量指标和值按照prometheus规范的格式输出到指定位置且以.prom后缀文件保存,textfile收集 器会自动读取collector .textfile.directory目录下所有以prom结尾的文件,并提取所有格式为Prometheus的指标暴 露给Prometheus来抓取。textfile收集器默认是开启的,我们只需要指定- -collector.textfile.directory的路径即可。
--collector.textfile.directory= /usr/local/node_ exporter/textfile.collected
通过浏览器访问http://被监控端IP:9100/metrics就可以查看到node_exporter在被监控端收集的监控信息
笔记配套视频效果更佳哦,视频地址:https://edu.51cto.com/lecturer/14390454.html
技术是没有终点的,也是学不完的,最重要的是活着、不秃。 学习看书还是看视频,都不重要,重要的是学会,欢迎关注,我们的目标---不秃。
---更多运维开发交流及软件包免费获取请加V: Linuxlaowang


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义