
MYSQL--提高篇(面试必会)
mysql核心技术
1、索引
2、存储引擎
3、日志
4、备份
5、主从复制
1、索引及执行计划
1.1介绍
相当于一本书的目录,加速查询,或者优化查询。
1.2mysql索引的类型(是按照不同的算法进行归纳的)
BTREE
HASH
FULLTEXT
RTREE
GIS
1.3索引算法的演变
BTREE讲究的是查找数据的平衡(快速的查询)--->下一页的最大值是上一页的最小值。
1、遍历 2、二分法(对半查询)
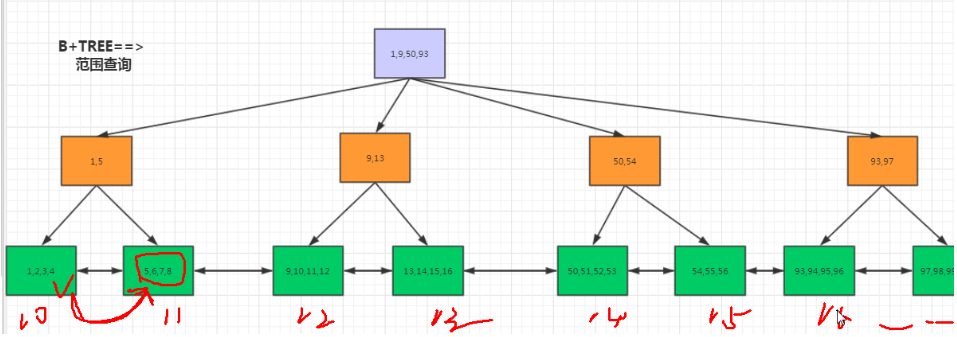
但是在mysql里面大多数查询是范围查询。
加强版 B+TREE
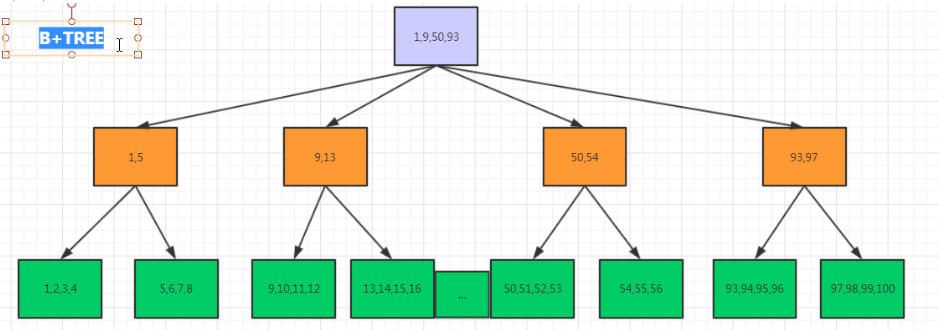
B+TREE(范围内查询==>) <-->查找 ①减少了io的次数;②减少了随机io的数量。③减少了io的量级。
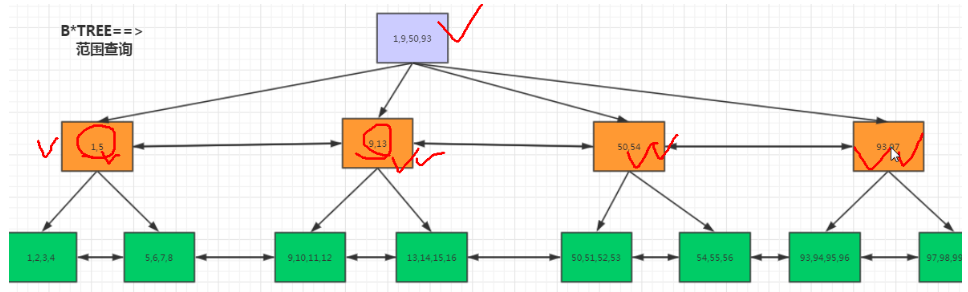
B*TREE 范围查询---->增强的B+TREE
1.3.1BTREE的在增强之路
B-TREE-------->叶子节点双向指针--------> 非叶子结点双向指针----------> B+TREE
1.3.3 BTREE 数据结构构建过程
(1) 数据排序(默认是从小到大)
(2) 将数据有序的存储到16KB数据页,生成叶子(leaf node)节点.
(3) 通过叶子节点范围(最小值到下个叶子节点最小值)+每个叶子节点指针生成non-leaf。
(4) 通过non-leaf节点的范围(最小值到下个non-leaf节点最小值)+每个 non-leaf指针生成root。
(5) B*TREE中,为了进一步优化范围查询,加入了leaf双向指针,non-leaf双向指针。
-
减少索引IO次数,有效的较少IOPS
-
减少了随机IO的数量
-
减少IO量级
1.3.4 MySQL的 索引组织表(InnoDB)
(1) Clusterd Index:聚簇(聚集,集群)索引
前提:
1.MySQL默认选择主键(PK)列构建聚簇索引BTREE。
2.如果没有主键,自动选择第--个唯一键的列构建聚簇索引BTREE。
3.如果以上都没有,会自动按照rowid生成聚簇索引。
说明:
1.聚簇索引,叶子节点,就是原始的数据页,保存的是表整行数据.
2.为了保证我们的索引是"矮胖"结构,枝节点和根节点都是只保存ID列值范围+下层指针.
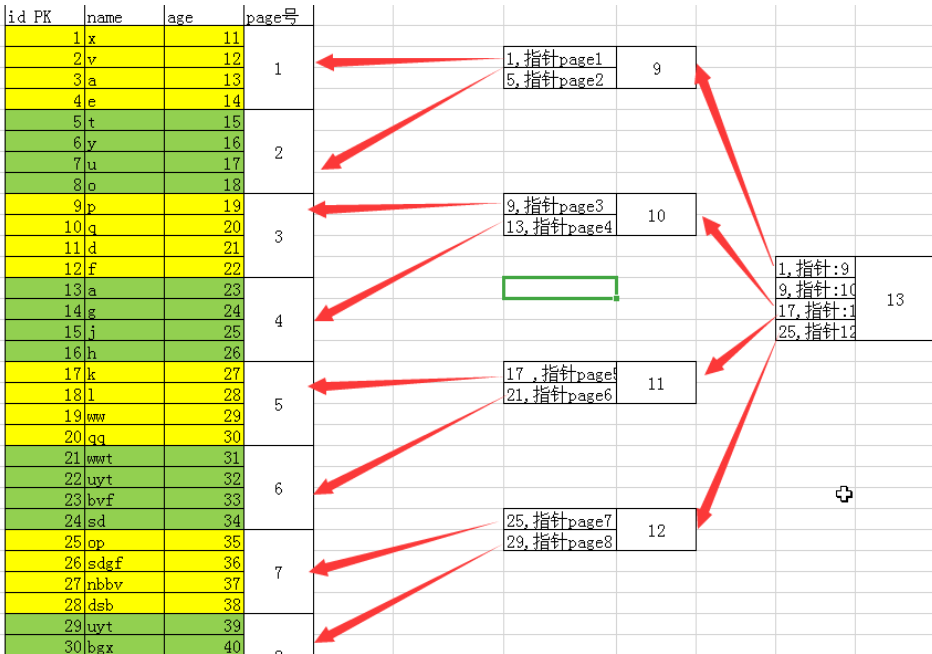
示例展示(优化)
优化查询之辅助查询
聚簇索引和辅助索引区别和联系
####--->区别<---###
1、一般选择主键生成聚簇索引,一-张表只能一个,没有主键选择唯一 键, 都没有选择隐藏rowid,自动生成隐藏聚簇索引。
2、聚簇索引叶子节点,存储的是整行的表数据.枝节点和根节点,叶子节点ID值的范围。
3.辅助索引,可以有多个.
4.辅助索引,叶子节点,存储的是索引列值+主键.
####--->联系<---###
执行查询时,
select from t1 where name= 'bgx' ;
1..首 先根据name的索引,快速锁定bgx的主键ID
2.根据ID列值回表查询聚簇索引,获取整行.
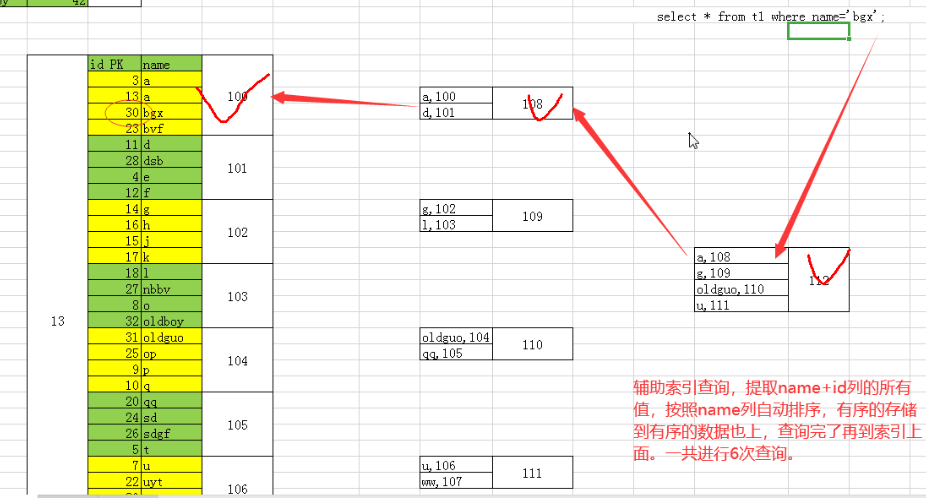
(2) Secondary Index: 辅助(二级)索引
构建过程:
alter table t1 add index idx (name)
1.提取name+id列的所有值。
2.按照name自动排序,从小到大排序,有序的存储到连续的数据页中,生成叶子节点
3.只提取叶子节点name范围+指针,生成枝节点和根节点。
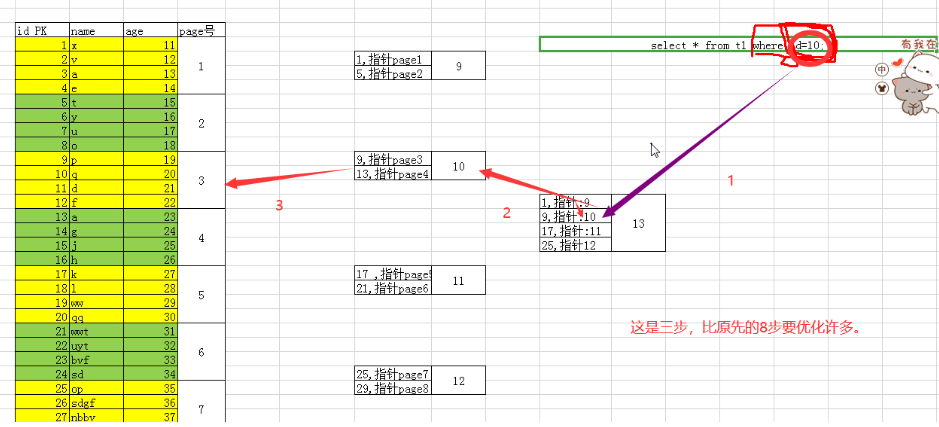
(3) 针对name列的查询,是如何优化?
select * from t1 where name='bgx';
1.按照查询条件bgx,带来基于name列构建辅助索引进行遍历(先辅助索引再根据主键值回到聚簇索引数进行遍历,理论上读取page为3次。)
2.根据ID值,回到聚簇索引树,继续遍历,进而找到所需数据行,理论读取的数据页为3次.
注意:一共是6次(一般情况)
特别注意:数据量在十万以下不建议建索引。
1.5辅助索引细分
1.5.1 单列
1.5.2联合索引
例如:
idx(a,b,c)
理论上可以有效的避免回表的次数_
1.5.3 唯一索引
手机号,身份证号类似的列.
理论上通过唯一索引作为遍历条件的话,读取6个page即可获取数据行.
1.6索引树高度问题,影响的原因?
(1) 数据行数多。
分区表(现在用的少)。
归档表。
分库分表。
(2)
选取的索引列值过长
前缀索引.
test (10)
(3)
varchar (64)
char (64)
enum()等数据类型的影响
索引的管理操作(创建、管理、修改、查询)
mysql> use world;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> desc city;
+-------------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+----------+------+-----+---------+----------------+
| ID | int(11) | NO | PRI | NULL | auto_increment |
| Name | char(35) | NO | | | |
| CountryCode | char(3) | NO | MUL | | |
| District | char(20) | NO | | | |
| Population | int(11) | NO | | 0 | |
+-------------+----------+------+-----+---------+----------------+
5 rows in set (0.00 sec)
mysql>
key: PRI : PK
UNI : 唯一键
MUL : 普通
mysql> show index from city\G; ###行转列,可以看到索引的具体情况。
*************************** 1. row ***************************
Table: city
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: ID
Collation: A
Cardinality: 4188
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
*************************** 2. row ***************************
Table: city
Non_unique: 1
Key_name: CountryCode
Seq_in_index: 1
Column_name: CountryCode
Collation: A
Cardinality: 232
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
2 rows in set (0.00 sec)
ERROR:
No query specified
mysql>
1.7.2创建索引
例子:
-- 1、单列索引 -- #####
SELECT * FROM city where population>100000;
mysql> alter table city add index idx_popu(population); ##创建索引
Query OK, 0 rows affected (0.17 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql>
### 说明:###
①作为where查询条件的列
②经常作为group by ,order by, distint, union的列创建索引.
mysql> select distinct countrycode from city; ##先排序,再去重
union all :不会去重
union :会自动去重(先排序,再去重)
-- 2、联合索引 -- #####
mysql> SELECT * FROM city where district='shandong' and name='jinan';
----------------------------------------------------------------
mysql> alter table city add index idx_dis_name(district,name);
Query OK, 0 rows affected (2.10 sec)
Records: 0 Duplicates: 0 Warnings: 0
----------------------------------------------------------------
说明:
联合索引排列顺序,从左到右.重复值少的列,优先放在最左边.
-- 2、前缀索引的应用 -- #####
mysql> alter table city add index idx_name(name(5)); ###name比较长,截取前五个字符构建。
Query OK, 0 rows affected (0.32 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql>
-- 3. 前缀索引应用(字符串)
mysql> alter table city add index idx_name(name(5));
-- 4. 唯一索引
mysql> alter table student add unique index idx_tel(xtel); ###unique
mysql> desc student;
1.7.3 删除索引
mysql> alter table city drop index idx_dis_name;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
2、执行计划(explain)分析
2.0 命令
explain select
desc select
mysql> desc select * from city where countrycode='CHN';
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
--- ## 重点关注指标说明: ###---
table:发生在哪张表的执行计划
type: 查询表的类型
全表扫描 :all
索引扫描 : index < range < ref < eq_ref < connst(system) < null ******
possible_keys:此次查询可能用到的索引
key: 此次查询走的索引名。
key_len:索引的覆盖长度.评估联合索引应用长度的。 *****
rows :扫描了表中的多少行
Extra :额外的信息 ***

2.4 type
(1)ALL : 全表扫描
mysql> desc select * from city;
mysql> desc select * from city where 1=1;
mysql> desc select * from city where population=42;
mysql> desc select * from city where countrycode !='CHN';
mysql> desc select * from city where countrycode not in ('CHN','USA');
mysql> desc select * from city where countrycode like '%CH%';
(2)index : 全索引扫描
mysql> desc select countrycode from city;
(3) range : 索引范围扫描(最常见)
> < >= <= like
in or
mysql> desc select * from city where id<10;
mysql> desc select * from city where countrycode like 'CH%';
mysql> desc select * from city where countrycode in ('CHN','USA');
改写:
desc
select * from city where countrycode='CHN'
union all
select * from city where countrycode='USA'
(4) ref 辅助索引等值查询
desc select * from city where countrycode='CHN';
(5) eq_ref 多表关联查询中,非驱动表的连接条件是主键或唯一键
desc
select
city.name,
country.name ,
city.population
from city
join country
on city.countrycode=country.code
where city.population<100;
(6) const(system) :主键或者唯一键等值查询
mysql> desc select * from city where id=10;
(7) NULL 索引中获取不到数据
mysql> desc select * from city where id=100000;
2.1使用场景
(1) 语句执行之前 :防患于未然
(2)出现慢语句时 : 亡羊补牢
2.2 执行计划结果查看(优化器选择后的执行计划)
mysql> desc select * from city where countrycode='CHN';
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | city | NULL | ref | CountryCode | CountryCode | 3 | const | 363 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql>
2.3 重点关注指标说明
table: 发生在哪张表的执行计划.
type : 查询的类型
全表扫描 : ALL
索引扫描 : index < range < ref < eq_ref < connst(system)< NULL *****
possible_keys : 可能用到的索引
key : 此次查询走的索引名.
key_len : 索引覆盖长度.评估联合索引应用长度的. *****
rows : 扫描了表中的多少行
Extra : 额外的信息 ****
2.4 type
(1) ALL : 全表扫描
mysql> desc select * from city;
mysql> desc select * from city where 1=1 ;
mysql> desc select * from city where population=42;
mysql> desc select * from city where countrycode !='CHN';
mysql> desc select * from city where countrycode not in ('CHN','USA');
mysql> desc select * from city where countrycode like '%CH%';
(2) index : 全索引扫描
mysql> desc select countrycode from city;
(3) range : 索引范围扫描(最常见)
< >= <= like
in or
mysql> desc select * from city where id<10;
mysql> desc select * from city where countrycode like 'CH%';
mysql> desc select * from city where countrycode in ('CHN','USA');
改写:
desc
select * from city where countrycode='CHN'
union all
select * from city where countrycode='USA'
(4) ref 辅助索引等值查询
desc
select * from city where countrycode='CHN';
(5) eq_ref 多表关联查询中,非驱动表的连接条件是主键或唯一键
desc
select
city.name,
country.name ,
city.population
from city
join country
on city.countrycode=country.code
where city.population<100;
(6) connst(system) :主键或者唯一键等值查询
mysql> desc select * from city where id=10;
(7) NULL 索引中获取不到数据
mysql> desc select * from city where id=100000;
2.5 key_len详细说明 ####值得计算 ---->优化联合索引的手段
2.5.1 作用
判断联合索引覆盖长度
2.5.2 最大覆盖长度的计算方法
idx(a,b,c) ====> a(10)+b(20)+c(30)
(1) 影响计算的条件
字符集 : utf8mb4
数字类型
tinyint 1 Bytes
int 4 Bytes
bigint 8 Bytes
字符串类型
char(5) 5*4 Bytes
varchar(5) 5*4 Bytes + 2 Bytes
没有 not null : 多一个字节存储是否为空
测试表:
create table keyt (
id int not null primary key auto_increment,
num int not null,
num1 int ,
k1 char(10) not null ,
k2 char(10) ,
k3 varchar(10) not null ,
k4 varchar(10)
)charset=utf8mb4;
num : 4
num1: 5
k1 : 40
k2 : 41
k3 : 42
k4 : 43
2.5.3 联合索引应用"道道" ---->重要
-- 建立联合索引时,最左侧列,选择重复值最少的列.
alter table keyt add index idx(a,b,c);
-- 例子:
-- 哪些情况可以完美应用以上索引.
desc select * from student where xname='张三' and xage=11 and xgender='m';
desc select * from student where xage=11 and xgender='m' and xname='张三' ;
desc select * from student where xgender='m' and xname='张三' and xage=11 ;
-- 影响到联合索引应用长度的.
-- 缺失 联合索引最左列,不走任何索引
mysql> desc select *from student where xage=11 and xgender='m' ;
-- 缺失中间部分,只能走丢失部分之前的索引部分
mysql> desc select *from student where xname ='张三' and xgender='m' ;
-- 查询条件中,出现不等值查询(> ,< ...like )
mysql> desc select *from student where xname ='张三' xage<18 and xgender='m' ;
联合索引应用长度到不等值列截断了.
-- 多子句
按照 select 子句顺序创建联合索引.
压力测试(索引的实际应用场景)
### 联合索引应用实例展示---(优化)
[root@db01 ~]# mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='test' --query="select * from test.t100w where k2='780P'" engine=innodb --number-of-queries=2000 -uroot -p123456 -verbose
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 8841.155 seconds
Minimum number of seconds to run all queries: 8841.155 seconds
Maximum number of seconds to run all queries: 8841.155 seconds
Number of clients running queries: 100
Average number of queries per client: 200
### 创建索引 #####----(优化后查询)
mysql> alter table test.t100w add index idx_k2(k2);
Query OK, 0 rows affected (7.13 sec)
Records: 0 Duplicates: 0 Warnings: 0
[root@db01 ~]# mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='test' --query="select * from test.t100w where k2='780P'" engine=innodb --number-of-queries=2000 -uroot -p123456 -verbose
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 0.651 seconds
Minimum number of seconds to run all queries: 0.651 seconds
Maximum number of seconds to run all queries: 0.651 seconds
Number of clients running queries: 100
Average number of queries per client: 20
###创建索引后的数据与创建索引前所用的时间两个相差太远。
索引续集:
1.索引应用规范
(1) 必须要有主键, 建议是自增长的ID列
(2) 经常做为where条件列 order by group by join on, distinct 的条件(业务:产品功能+用户行为)
(3) 唯一 值多的列作为联合素引最左列.
(4)列值长度较长的索引列,我们建议使用前缀索引.
(5) 降低索引条目,一方面不要创建没用索引,不常使用的索引清理, percona toolkit (x8xx)
(6) 索引维护要避开业务繁忙期
(7) 经常更新的列不要建索引
1.2 开发规范
没有查询条件,或者查询条件没有建立索引
查询结果集是原表中的大部分数据,应该是25%以上。
索引本身失效,统计数据不真实
查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,大,/,!等)
隐式转换导致索引失效.这一一点应当引起重视.也是开发中经常会犯的错误.
<>,not in不走索引(辅助索引)
like"%_"百分号在最前面不走
第五章 存储引擎
-
上节回顾
-
索引类型
BTREE : b-tree , b+tree , b*tree
RTREE
FULLTExT
HASH -
聚簇索引和辅助索引区别和联系
区别: -
一般选择主键生成聚簇索引,一张表只能一个 ,没有主键选择唯一键,都没有选择隐藏rowid,自动生成隐藏聚簇索引.
-
聚簇索引叶子节点,存储的是整行的表数据.枝节点和根节点,叶子节点ID值的范围.
-
辅助索引,可以有多个.
-
辅助索引,叶子节点,存储的是索引列值+主键.
关系:
执行查询时,select * from t1 where name='bgx';
1. 首先根据name的索引,快速锁定bgx的主键ID
2. 根据ID列值回表查询聚簇索引,获取整行.
-
管理
show index from city;
alter table city add index idx_name(name);
alter table city add index idx_a_b_c(a,b,c);
alter table city add index idx_a(a(10));
alter table city add unique index idx_a(a(10));
alter table city drop index idx_name; -
explain / desc
type : ALL index range ref eq_ref const(system) NULL
key_len
联合索引应用"道道" *****
建立联合索引时,最左侧列,选择重复值最少的列.
alter table keyt add index idx(a,b,c);
-- 例子:
-- 哪些情况可以完美应用以上索引.
desc select *from student where xname='张三' and xage=11 and xgender='m';
desc select *from student where xage=11 and xgender='m' and xname='张三' ;
desc select *from student where xgender='m' and xname='张三' and xage=11 ;
-- 影响到联合索引应用长度的.
-- 缺失 联合索引最左列,不走任何索引
mysql> desc select *from student where xage=11 and xgender='m' ;
-- 缺失中间部分,只能走丢失部分之前的索引部分
mysql> desc select *from student where xname ='张三' and xgender='m' ;
-- 查询条件中,出现不等值查询(> ,< ...like )
mysql> desc select *from student where xname ='张三' xage<18 and xgender='m' ;
联合索引应用长度到不等值列截断了.
-- 多子句
按照 select 子句顺序创建联合索引.
### 联合索引应用实例展示---(优化)
[root@db01 ~]# mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='test' --query="select * from test.t100w where k2='780P'" engine=innodb --number-of-queries=2000 -uroot -p123456 -verbose
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 8841.155 seconds
Minimum number of seconds to run all queries: 8841.155 seconds
Maximum number of seconds to run all queries: 8841.155 seconds
Number of clients running queries: 100
Average number of queries per client: 200
### 创建索引 #####----(优化后查询)
mysql> alter table test.t100w add index idx_k2(k2);
Query OK, 0 rows affected (7.13 sec)
Records: 0 Duplicates: 0 Warnings: 0
[root@db01 ~]# mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='test' --query="select * from test.t100w where k2='780P'" engine=innodb --number-of-queries=2000 -uroot -p123456 -verbose
mysqlslap: [Warning] Using a password on the command line interface can be insecure.
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 0.651 seconds
Minimum number of seconds to run all queries: 0.651 seconds
Maximum number of seconds to run all queries: 0.651 seconds
Number of clients running queries: 100
Average number of queries per client: 20
###创建索引后的数据与创建索引前所用的时间两个相差太远。
===========================================================
索引续集
1.索引应用规范
1.1 创建索引的条件
(1) 必须要有主键,建议是自增长的ID列
(2) 经常做为where条件列 order by group by join on, distinct 的条件(业务:产品功能+用户行为)
(3) 唯一值多的列作为联合索引最左列.
(4) 列值长度较长的索引列,我们建议使用前缀索引.
(5) 降低索引条目,一方面不要创建没用索引,不常使用的索引清理,percona toolkit(xxxxx)
(6) 索引维护要避开业务繁忙期
(7) 经常更新的列不要建索引
1.2 开发规范
(1) 没有查询条件,或者查询条件没有建立索引。
mysql> use world;
mysql> desc select * from city;
mysql> desc select * from city where true;
mysql> desc select * from city where 1=1;
mysql> desc select * from city where name='jinan';
mysql> desc select * from student where xage=11 and xgender='m' ;
(2) 查询结果集是原表中的大部分数据,应该是20-30%以上。
如果有1000w或者200w-300w的数据 ----> 则有可能导致索引失效.
解决方案: 给范围查询增加上限和下限
(3) 索引本身失效,统计数据不真实,更新不及时.
前几天运行的很快,突然有一天慢了.
mysql> use world;
mysql> desc select * from city where name='jinan';
###----->解决方案:<-----###
1. 手工触发更新统计信息
mysql> analyze table city;
+------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+------------+---------+----------+----------+
| world.city | analyze | status | OK |
+------------+---------+----------+----------+
1 row in set (0.17 sec)
mysql> optimize table city;
2. 重建索引 ###删了重建
(4) 查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等)
mysql> desc select * from city where id-1=9;
(5) 隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误.
mysql> use world;
mysql> create table tab(id int,telnum char(11));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into tab values(1,'110'),(2,119),(3,120),(4,190),(5,111),(6,123);
Query OK, 6 rows affected (0.37 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> select * from tab;
+------+--------+
| id | telnum |
+------+--------+
| 1 | 110 |
| 2 | 119 |
| 3 | 120 |
| 4 | 190 |
| 5 | 111 |
| 6 | 123 |
+------+--------+
6 rows in set (0.00 sec)
mysql> desc select * from tab where telnum=110; ### 不走索引,找的是110这个数字;
mysql> desc select * from tab where telnum='110'; ###走索引
(6) <> ,not in 不走索引(辅助索引)
mysql > desc select * from city where id <> 10;
(7) like "%_" 百分号在最前面不走
(8) 联合索引规范
联合索引(a,b,c) ----> bc ---> c 不走任何索引
联合索引(a,b,c) ----> ac 只能走部分
联合索引(a,b,c) 中间出现不等值(> < like)
2、扩展(Adaptive Hash indeces)
2.1 AHI 自适应hash索引
mysql> select @@innodb_adaptive_hash_index;
Adaptive Hash Indexes 原理
InnoDB存储引擎会监控对二级索引的查找,如果发现某一个二级索引被频繁访问,二级索引成为一个热数据。那么此时建立hash索引可以带来速度的提升 经常访问的二级索引数据会自动被生成到hash索引里面去(最近连续被访问三次的数据),自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。而且不需要将整个表都建哈希索引,InnoDB存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引。
查看使用状况:
mysql> show engine innodb status ;
可以通过观察show engine innodb status结果中的SEMAPHORES部分来决定是否使用自适应哈希索引。如果你看到很多线程都在btr0sea.c文件上创建rw-latch上waiting,那么建议关闭掉自适应哈希索引。高并发模式下AHI引起的竞争,需要关闭AHI.
设置参数
innodb_adaptive_hash_index=on/off
2.2 MySQL Insert Buffer技术 : 插入缓冲技术
插入缓冲技术,对于非聚集类索引的插入和更新操作,不是每一次都直接插入到索引页中,而是先插入到内存中。具体做法是:如果该索引页在缓冲池中,直接插入;否则,先将其放入插入缓冲区中,再以一定的频率和索引页合并,这时,就可以将同一个索引页中的多个插入合并到一个IO操作中,大大提高写性能。
这个设计思路和HBase中的LSM树有相似之处,都是通过先在内存中修改,到达一定量后,再和磁盘中的数据合并,目的都是为了提高写性能。
那么插入缓冲如何减少随机IO的呢?每个一段时间,insert buffer会去合并在insert buffer中的二级非唯一索引。通常情况下,它会合并N个修改到同一个btree索引的索引页中,从而节约了很多IO操作。经测试,insert buffer可以提高15倍的插入速度。
在事务提交后,insert buffer可能还在合并写入。所以,假如当DB异常重启,reovery阶段,当有非常多的二级索引需要更新或插入时,insert buffer将可能花费很长时间,甚至几个小时。在这个阶段,磁盘IO将会增加,那么就会导致IO-Bound类型的查询有显著的性能下滑。
inet数据,不会立即更新到索引树中,存储在Inet buffex中:
index merge 功能在内存中合并查询索引树.减少的大批量insert操作时索引的更新,减少I0和锁表的时间.
2.3 Index Condition Pushdown (ICP) :索引下推技术
mysql使用索引从表中检索行数据的一种优化方式,MySQL5.6开始支持
MySQL 5.6之前,存储引擎会通过遍历索引定位基表中的行,然后返回给Server层,再去为这些数据行进行WHERE后的条件的过滤。
mysql 5.6之后支持ICP后,如果WHERE条件可以使用索引
MySQL 会把这部分过滤操作放到存储引擎层,存储引擎通过索引过滤,把满足的行从表中读取出。
ICP能减少引擎层访问基表的次数和 Server层访问存储引擎的次数。
联合索引(a,b,c) ----> ac 只能走部分
没有ICP
a ---> 从磁盘拿满足a条件的数据 加载到内存 ,再C过滤想要的结果 =====> SQL层 --->
有ICP
a ----> a + c =====> SQL 层
mysql> SET @@optimizer_switch='index_condition_pushdown=on;
mysql> show variables like 'optimizer_switch%' \G;
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,subquery_materialization_cost_based=on,use_index_extensions=on
2.4 MRR 的全称是 Multi-Range Read : 辅助索引
Optimization,是优化器将随机 IO 转化为顺序 IO 以降低查询过程中IO开销的一种手段,这对IO-bound类型的SQL语句性能带来极大的提升,适用于range ref eq_ref类型的查询
MRR优化的几个好处
使数据访问有随机变为顺序,查询辅助索引是,首先把查询结果按照主键进行排序,按照主键的顺序进行书签查找。
减少缓冲池中页被替换的次数
批量处理对键值的操作。
辅助索引---回表->聚簇索引,在回表之前自动将主键值先排序,一次性回表查询
减少回表次数,随机I0尽可能转换为顺序Id
SNL, BNL,BKA : Join 的三种经典算法
SNL :关联表中没有索引.我们不建议出现
BNL :在驱动表,得到所有数据,一次性到内循环中进行匹配
mysql> SET @@optimizer_switch='mrr=on,mrr_cost_based=off';
mysql> show variables like 'optimizer_switch%' \G;
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=off,block_nested_loop=on,batched_key_access=on,materialization=on,semijoin=on,loosescan=on,firstmatch=on,subquery_materialization_cost_based=on,use_index_extensions=on
1 row in set (0.00 sec)
2.5 针对多表连接查询
Simple Nested Loops Join(SNL),简单嵌套循环算法
Index Nested Loops Join(INL),索引嵌套循环连接
Block Nested Loops Join(BNL),块嵌套循环连接
Batched Key Access join(BKA) , BNL+MRR
说明:
- batched_key_access=on
- mrr必须开启 ,mrr=on,mrr_cost_based=off
- 被驱动表,关联列必须有索引.
作用:
- 减少了 Nested Loops 次数
- 将扫描非驱动表时,可以将大量的随机IO转变为顺序IO
A
id name age
1 zs 12
2 l4 13
3 w5 14
B
id addr telnum
1 bj 110
2 sh 120
3 tj 119
select name,age,telnum
from a join b
on A.id=b.id
where name like '张%'
提高表join性能的算法。当被join的表能够使用索引时,就先排好顺序,然后再去检索被join的表,听起来和MRR类似,实际上MRR也可以想象成二级索引和 primary key的join
如果被Join的表上没有索引,则使用老版本的BNL策略(BLOCK Nested-loop)
SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
mysql> show variables like 'optimizer_switch%' \G
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on, ,block_nested_loop=on,batched_key_access=on,materialization=on,semijoin=on,loosescan=on,firstmatch=on,subquery_materialization_cost_based=on,use_index_extensions=on
1 row in set (0.00 sec)
===============================================
第五章节 存储引擎
- 存储引擎介绍
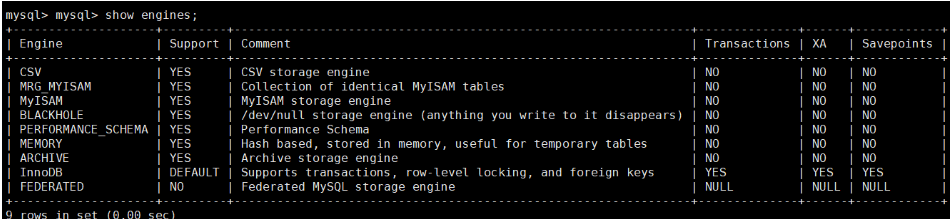
相当于Linux 文件系统.组织存储表数据. - 存储引擎的种类
show engines;
InnoDB
MyISAM
CSV
Memory
1、存储引擎的介绍
相当于Linux文件系统,组织存储表数据的。
mysql> mysql> show engines;
###存储引擎的种类
InnoDB
MyISAM
CSV
Memory
其它的存储引擎:
Mariadb : InnoDB,TokuDB<Myrocks
其他的存储引擎:
MariaDB : InnoDB,TokuDB ,Myrocks
percona : xtradb ,TokuDB ,Myrocks
TokuDB ,Myrocks : 比较适合于在写入操作较多的场景,数据量级大的场景.
原因是: 插入性能很高, 压缩比较高.
监控类的业务.
学员案例:
环境: zabbix 3.x mariaDB 5.5 centos 7.3
现象 : zabbix卡的要死 , 每隔3-4个月,都要重新搭建一遍zabbix,存储空间经常爆满.
问题 :
- zabbix 版本
- 数据库版本 ---> 5.5 ----> ibdata1 ----> 5.7 ,8.0
- zabbix数据库500G,存在一个文件里
优化建议:
1.数据库版本升级到Mairia 10.x版本,zabbix升级更高版本
2.存储引擎改为tokudb
3.监控数据按月份进行切割(二次开发:zabbix 数据保留机制功能重写,数据库分表)
4.关闭binlog和双1 等安全参数需要关闭
5.参数调整....
优化结果:
监控状态良好
select concat("alter table zabbix.",table_name," engine=tokudb") from information_schema.tables
where table_schema='zabbix';
为什么?
- 原生态支持TokuDB,另外经过测试环境,10.x要比5.5 版本性能 高 2-3倍
- TokuDB:insert数据比Innodb快的多,数据压缩比要Innodb高
3.监控数据按月份进行切割,为了能够truncate每个归档表,立即释放空间
4.关闭binlog ----->减少无关日志的记录.
5.参数调整...----->安全性参数关闭,提高性能.
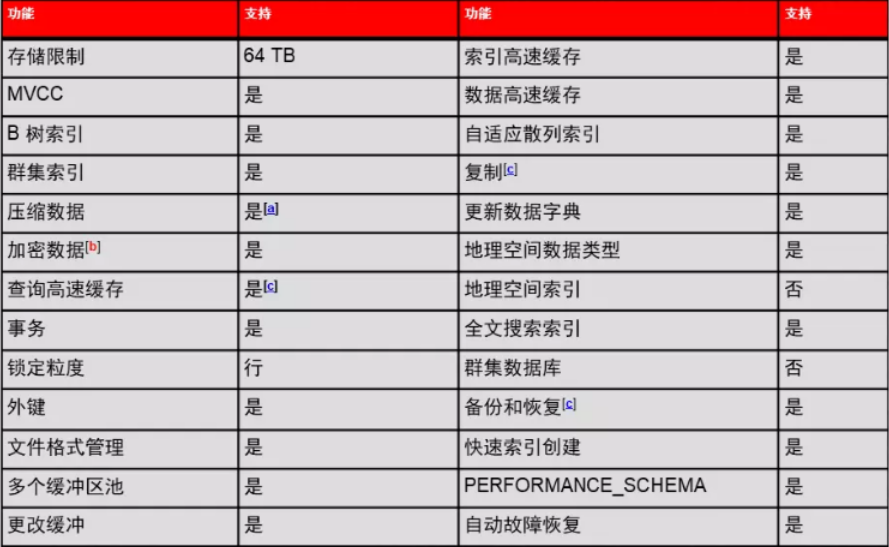
3、InnoDB存储引擎的核心特性
面试题:
(1) InnoDB存储引擎的特性
(2) InnoDB和MyISAM的区别 (在8.0之后没了MyISAM)
MVCC 多版本并发控制
聚簇索引 PK
事务
行级锁 MyISAM支持表锁
外键 FK (FOREIGN KEY)
复制支持高级特性: GTID等高级复制
自适应hash索引
支持热备(HOT Backup),MyISAM支持温备份
ACSR(自动故障恢复)----
Adaptive HASH INdex ----AHI
Replication
-
存储引擎的操作
-
查看存储引擎
mysql> show engines;
mysql> select @@default_storage_engine;
mysql> create table mt (id int) engine=myisam;
mysql> create table et (id int) engine=innodb;
5.2 查询所有非INNODB的表 , 并且提出修改建议
mysql> SELECT
-> table_schema,
-> table_name ,
-> ENGINE ,
-> CONCAT("alter table ",table_schema,".",table_name," engine=innodb;") AS "修改建议"
-> FROM information_schema.tables
-> WHERE table_schema NOT IN ('sys','information_schema','performance_schema','mysql')
-> AND ENGINE <> 'innodb';
+--------------+------------+--------+--------------------------------------+
| table_schema | table_name | ENGINE | 修改建议 |
+--------------+------------+--------+--------------------------------------+
| test | mt | MyISAM | alter table test.mt engine=innodb; |
| test | test | MyISAM | alter table test.test engine=innodb; |
+--------------+------------+--------+--------------------------------------+
2 rows in set (0.01 sec)
mysql>
4.2 修改表的存储引擎
mysql > alter table test.test engine=innodb;
扩展: 碎片问题解决.
由于业务中有大量的delete操作,产生了大量的碎片.
(1) 表数据逻辑导出,删除原表,重新导入.
(2)
mysql> alter table test.test engine=innodb;
小项目演示:
环境:centos7.4,MySQL 5.7.20,InnoDB存储引擎
业务特点:数据量级较大,经常需要按月删除历史数据.
问题:磁盘空间占用很大,不释放
处理方法:
以前:将数据逻辑导出,手工truncate表,然后导入进去
现在:
对表进行按月进行归档表
业务替换为truncate方式
学员案例:
环境: zabbix 3.x mariaDB 5.5 centos 7.3
现象 : zabbix卡的要死 , 每隔3-4个月,都要重新搭建一遍zabbix,存储空间经常爆满.
问题 :
- zabbix 版本
- 数据库版本 ---> 5.5 ----> ibdata1 ----> 5.7 ,8.0
- zabbix数据库500G,存在一个文件里
优化建议:
1.数据库版本升级到Mairia 10.x版本,zabbix升级更高版本
2.存储引擎改为tokudb
3.监控数据按月份进行切割(二次开发:zabbix 数据保留机制功能重写,数据库分表)
4.关闭binlog和双1 等安全参数需要关闭
5.参数调整....
优化结果:
监控状态良好
select concat("alter table zabbix.",table_name," engine=tokudb") from information_schema.tables
where table_schema='zabbix';
为什么?
- 原生态支持TokuDB,另外经过测试环境,10.x要比5.5 版本性能 高 2-3倍
- TokuDB:insert数据比Innodb快的多,数据压缩比要Innodb高
3.监控数据按月份进行切割,为了能够truncate每个归档表,立即释放空间
4.关闭binlog ----->减少无关日志的记录.
5.参数调整...----->安全性参数关闭,提高性能.
==================================================
实施过程:
1.部署 Mariadb 环境 10.1
(1) 上传解压
[root@zabbix-server local]# tar xf mariadb-10.2.30-linux-glibc_214-x86_64.tar.gz
[root@zabbix-server mariadb]# ln -s mariadb-10.2.30-linux-glibc_214-x86_64 mariadb
[root@zabbix-server mariadb]# chown -R mysql.mysql /usr/local/mariadb
[root@zabbix-server mariadb]# mkdir -p /data/mysql/data
[root@zabbix-server mariadb]# chown -R mysql.mysql data
[root@zabbix-server mariadb]# mv /etc/my.cnf /etc/my.cnf.bak
(2) 备份原数据库zabbix数据
mysqldump -B zabbix > /tmp/zabbix.sql
(3) 停源库 ,启新库
[root@zabbix-server local]# systemctl stop mariadb
/usr/local/mariadb/scripts/mysql_install_db --user=mysql --basedir=/usr/local/mariadb --datadir=/data/mysql/data
[root@zabbix-server data]# cd /usr/local/mariadb/support-files/
[root@zabbix-server support-files]# cp mysql.server /etc/init.d/mysqld
[root@zabbix-server support-files]# chkconfig --add mysqld
# ====未完待续(翻车现场.....)
#### 翻车拯救
#### 实施过程:zabbix库替换存储引擎innodb换成tokudb
1.部署 Mariadb 环境 10.0.38
[root@db01 mysql]# vim /etc/yum.repos.d/mariadb.repo
[mariadb]
name = MariaDB
baseurl = http://yum.mariadb.org/10.1/centos7-amd64
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
gpgcheck=0
enabled=1
tar xf mariadb-10.0.38-rhel-7-x86_64-rpms.tar
2. 改配置文件
[root@db01 my.cnf.d]# vim /etc/my.cnf.d/tokudb.cnf
[mariadb]
plugin-load-add=ha_tokudb.so
plugin-dir=/data/tokudb/plugin/
tokudb_commit_sync=ON
tokudb_cache_size=128M
tokudb_directio=ON
tokudb_row_format=tokudb_fast
tokudb_tmp_dir=/data/tokudb/tmp
tokudb_write_status_frequency =1
tokudb_read_status_frequency=1
tokudb_data_dir=/data/tokudb/data
tokudb_log_dir=/data/tokudb/log
mkdir -p /data/tokudb/{plugin,tmp,data,log}
chown -R mysql.mysql /data/*
cd /usr/lib64/mysql/plugin/
cp -a * /data/tokudb/plugin/
chown -R mysql.mysql /data/*
3. 启动数据库
[root@db01 data]# mysqld_safe &
4. 生成批量替换语句
select concat('alter table ',table_schema,'.',table_name,' drop FOREIGN KEY ', CONSTRAINT_NAME,";") from information_schema.TABLE_CONSTRAINTS where table_schema='zabbix' and CONSTRAINT_TYPE='FOREIGN KEY';
select concat('alter table ',table_schema,'.'table_name,' engine=tokudb') from information_schema.tables where table_schema='zabbix' into outfile '/tmp/alter.sql';
percona-server+tokudb+zabbix
##项目地址
https://www.jianshu.com/p/898d2e4bd3a7
5、InnoDB存储引擎物理存储结构
5.1 表空间(tablespace)
(1) MySQL5.5版本出现了共享表空间模式(移植了Oracle)
实现了较为方便的扩容功能,但是所有的表数据都集中在几个文件中,管理十分不方便.
(2) MySQL 5.6中 ,默认使用独立表空间模式实现数据的存储.
保留了共享表空间,只用来存储系统相关数据(数据字典+undo+tmp表空间)
把用户表数据和索引单独存储(独立表空间)
(3) MySQL 5.7
保留了共享表空间ibdata1,只用来存储系统相关数据(数据字典+undo),undo在5.7 手工配置将他独立出来=
(4) MySQL 8.0
保留了共享表空间ibdata1,只用来存储系统相关数据(dw,cb)
undo自动独立出来,移除了数据字典的存储.
5.2 表空间管理
查看表空间模式:
mysql> select @@innodb_file_per_table;
+-------------------------+
| @@innodb_file_per_table |
+-------------------------+
| 1 |
+-------------------------+
1 row in set (0.00 sec)
共享表空间的设置: (可以定制大小)------->在my.cnf设置
mysql> select @@innodb_data_file_path;
+-------------------------+
| @@innodb_data_file_path |
+-------------------------+
| ibdata1:12M:autoextend |
+-------------------------+
1 row in set (0.00 sec)
ibdata1:332M;ibdata2:128M:autoextend
### 注意:
一般情况下: 安装MySQL ,提前设置好
mysqld --initialize-insecure ....
my.cnf
ibdata1:512M:ibdata2:512M:autoextend
5.3 表的物理存储介绍
t1表:
ibd : 数据行
frm : 数据字典部分信息(列,列属性)
ibdata1 : 整个数据库的数据字典(所有表的列信息,列属性....),undo
ib_logfileN : redo事务日志
5.4 表空间迁移(快速迁移部分表数据)
(1) 准备一个新环境
(2) 创建和原表结构一样的表
show create table t1 ;
create ....
(3) 删除空表的ibd表空间文件
alter table t1 discard tablespace;
(4) cp 原表的ibd表空间到新环境
[root@db01 test]# cp -a t1.ibd /data/mysql/data_3307/db1
(5) 导入表空间文件.
alter table t1 import tablespace;
案例演示
5.5 学员的项目
案例背景:
硬件及软件环境:
联想服务器(IBM)
磁盘500G 没有raid
centos 6.8
mysql 5.6.33 innodb引擎 独立表空间
备份没有,日志也没开
开发用户专用库:
jira(bug追踪) 、 confluence(内部知识库) ------>LNMT
故障描述:
断电了,启动完成后“/” 只读
fsck 重启,系统成功启动,mysql启动不了。
结果:confulence库在 , jira库不见了
求助内容:
求助:
这种情况怎么恢复?
我问:
有备份没
求助:
连二进制日志都没有,没有备份,没有主从
我说:
没招了,jira需要硬盘恢复了。
求助:
1、jira问题拉倒中关村了
2、能不能暂时把confulence库先打开用着
将生产库confulence,拷贝到1:1虚拟机上/var/lib/mysql,直接访问时访问不了的
问:有没有工具能直接读取ibd
我说:我查查,最后发现没有
问题解决
我想出一个办法来:
表空间迁移:
create table xxx
alter table confulence.t1 discard tablespace;
alter table confulence.t1 import tablespace;
虚拟机测试可行。
处理问题思路:
confulence库中一共有107张表。
1、创建107和和原来一模一样的表。
他有2016年的历史库,我让他去他同时电脑上 mysqldump备份confulence库
mysqldump -uroot -ppassw0rd -B confulence --no-data >test.sql
拿到你的测试库,进行恢复
到这步为止,表结构有了。
2、表空间删除。
select concat('alter table ',table_schema,'.'table_name,' discard tablespace;') from information_schema.tables where table_schema='confluence' into outfile '/tmp/discad.sql';
source /tmp/discard.sql
执行过程中发现,有20-30个表无法成功。主外键关系
很绝望,一个表一个表分析表结构,很痛苦。
set foreign_key_checks=0 跳过外键检查。
把有问题的表表空间也删掉了。
3、拷贝生产中confulence库下的所有表的ibd文件拷贝到准备好的环境中
select concat('alter table ',table_schema,'.'table_name,' import tablespace;') from information_schema.tables where table_schema='confluence' into outfile '/tmp/discad.sql';
4、验证数据
表都可以访问了,数据挽回到了出现问题时刻的状态(2-8)
1、物理存储结构
1.1表空间
支持两类表空间:共享,独立
支持两类表空间: 共享,独立
5.5 版本 : 默认共享表空间. 包含: 数据字典\undo\tmp\用户表数据和索引
5.6 版本 : 默认独立表空间. 包含: 数据字典\undo\tmp,将用户数据和索引独立,每个表单独存储
5.7 版本 : 默认独立表空间. 包含: 数据字典\undo,tmp独立,将用户数据和索引独立,每个表单独存储
8.0 版本 : 默认独立表空间. 数据字典取消掉, undo,tmp独立 将用户数据和索引独立,每个表单独存储
1.2 功能名词介绍
transaction 事物
undo : ibdatal 回滚日志
tmp : ibtmp1 临时表空间
redo : ib_ logfile0~N 重做日志
ibd : t1. ibd 表空间数据文件
Innodb Buffer Pool 数据缓冲区池(70%-80%)
log buffer 重做日志缓冲区
LSN 日志序列号
Trx_ id 失去-事物ID
checkpoint 检查点
1.3 事务 ?
1.3.1 什么是事务?
将多条DML(标准的事务语句),放在一个"组"中运行,要么全成功要么全失败.
- 交易?
以物换物
货币换物
虚拟币换物
虚拟币虚拟物
1.3.2 事务ACID特性 atomicity,consistency,isolation,and durability.
A : 原子性 :每一个事物都是一个完整个体,不可再分性,要么全成功,要么全失败。
C : 一致性 :在事物发生前中后保证事物操作的前后一致性
I : 隔离性 :多个事物之间,所做事物互不干扰,,不能同时更新同一行数据。
D : 持久性 :事物完成之后所涉及的数据永久有效。必须永久有效(落地到磁盘中)
1.3.3 事物的生命周期管理
## 标准的事物的工作流程(生命周期)
(1)开启一个事物 ###二者均可开启一个新事物。
begin /start transaction;
mysql> begin;
mysql> start transaction;
(2)标准的事物语句
insert 插入
update update t1 set name='bgx' where id=1;
delete 删除
(3)结束事物
commit; ### 提交事物
rollback; ### 回滚事物,只能在没有提交commit之前做。
非标准的事物生命周期
(1)自动提交机制
MySQL5.6之后:
mysql> delete from city where id=100;
Query OK, 1 row affected (0.22 sec)
2. 每一条执行完成之后都会自动提交
mysql> select @@autocommit;
+--------------+
| @@autocommit |
+--------------+
| 1 |
+--------------+
1、begin子句会自动添加;----->### 意思是5.6之后自动在前面添加begin、commit;
改变:----加配置选项
vim /etc/my.cnf
......
autocommit=0
......
/etc/init.d/mysqld restart ###重新启动
说明:默认情况下,开启事务时不加begin,逐条自动提交. 手工开启begin命令,按照正常事务工作过程.
(2)隐式提交
用于隐式提交的SQL语句:
begin
a
b
begin
SETAUTOCOMMIT = 1
导致提交的非事务语句:
DDL语句:( ALTER、CREATE 和DROP )
DCL语句:( GRANT、REVOKE;和SETPASSWORD )
锁定语句:( LOCK TABLES和UNLOCK TABLES )
导致隐式提交的语句示例:
TRUNCATE TABLE
LOAD DATA INEILE
SELECT FOR UPDATE
(3) 隐式回滚
会话断开
数据库重启
死锁
1.3.4事物的底层工作过程
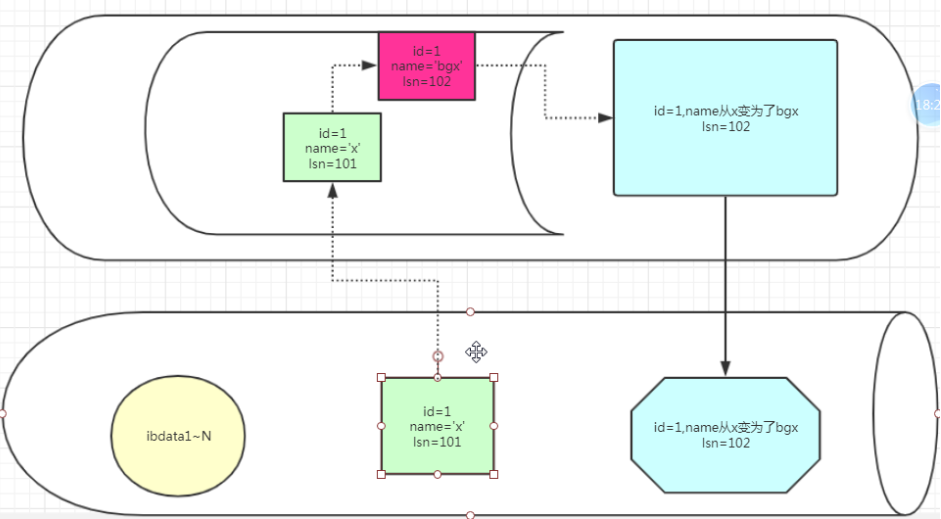
(1) redo
分布:
内存: log buffer
磁盘: ib_logfile0~N
功能:
1.保存内存数据页的变化
2.实现事务的快速持久化的特性:量少,顺序IO ---D特性:只要提交就肯定持久化。
3、宕机后,通过redo实现重做事物,将数据库恢复到宕机之前的状态。---->我们称之为ACSR中的“前滚”操作。
(2)undo 回滚日志
分布: 默认在ibdatal, 5.7开始可以独立undo,8.0之后自动独立。
功能:
1、保存当前事务操作的反操作
2、在执行rollback命令时,undo提供回滚操作。
3、宕机时,ACSR过程中提供回滚操作(将没有commit标记的回滚掉)
(3)锁 及 隔离级别------>(主要保证隔离性)
(1) 锁 :
S : 共享锁,读锁
X : 排它锁,写锁
IS : 意向S
IX : 意向X
(2)X锁的细分
TX -----表锁>DDL语句 table X
全局锁表:
备份时,备份系统表时(非INOODB表),FTWRL
mysql> flush table with read lock;
mysql> unlock tables;
单表: DDL
mysql> lock table t1 read ;
mysql> unlock tables;
RX -----行锁>DML语句 record X
GAPX ---->间隙锁 特殊DML GAP LOCK X
Next LOCK X ---->下一键锁定
(3)隔离级别(transaction_isolation)
mysql> select @@transaction_isolation;
RU :读未提交 READ-UNCOMMITTED
RC :读已提交 ***** READ-COMMITTED
RR :可重复读 ***** REPEATABLE-READ
SR :串行化
现象模拟:RU
session A
session B
###打开两个窗口测试
vim /etc/my.cnf ###添加参数
---------------------------------------
session A
mysql> begin;
mysql> use world id=1000;
myq1> delete from city where id=1000;
session B
mysql> begin;
mysql> use world id=1000;
mysql> select * from city where id=1000;
--------------------------------------
mysql> select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| REPEATABLE-READ |
+-------------------------+
1 row in set (0.00 sec)
mysql>
会产生的问题:
1.脏读
2.不可重复读现象
3.幻读
RC :读已提交 ***** READ-COMMITTED
1.不可重复读现象
2.幻读
RR:可重复读 ****** REPEATABLE-READ
1.幻读
说明:
1. RR级别+ GAP+ Next lock (GAP+RX)有效防止幻读现象
2.通过MVCC,多版本并发控制中,一致性快照读技术,防止出现不可重复读现象,解决了不可重复读问题。
总结:
AID都是为了数据库最终一致性C
SQL_MODE
约束
MDL 原数据锁
page lock 页锁
latch 内存页锁
2、INNODB存储引擎核心参数(重要)
mysql> select @@innodb_data_file_path; ##共享表空间的设置参数
mysql> select @@innodb_file_per_table; ##共享表空间的设置参数-->每一个表都是独立的一个空间。
mysql> select @@innodb_buffer_pool_size; #不要超过80%物理内存,一般70%, ----> Out of memory
mysql> select @@innodb_log_buffer_size; ##日志缓存区大小
mysql> select @@innodb_log_file_size; ##日志文件的大小
mysql> select @@innodb_log_file_in_group; ##日志文件设置多少个比如=3;
mysql> select @@innodb_flush_log_at_trx_commit; # 双1标准之一.控制redo刷写的策略.(面试必问);
0 每秒钟刷写redo到磁盘. (不怕丢数据的时候可以设置,提高性能的一种手段。)
1 每次事务提交,立即刷写redo到磁盘。(每次数据必须保证到磁盘)
2 每次事务提交,立即写日志到OS cache(缓存)中,然后每秒钟刷写到磁盘.
mysql> select @@innodb_flush_method; 控制(buffer脏页,redo buffer日志)刷写方式
建议设置:
O_DIRECT : 数据页刷写磁盘直接穿过文件系统缓存,redo 刷写时,先写os cache,再写到磁盘。
innodb_flush_method=O direct
###生成3个256M的日志文件
vim /etc/my.cnf
.......
innodb_log_file_size=256M
innodb_log_files_in_group=3
.......
/etc/init.d/mysqld restart
需求:我看看我的内存多大呀?
mysql> show engine innodb status\G; ###Free buffer 超过70%一般会去调


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义