MySQL数据库基础
一、数据库相关概念
1.1 什么是数据库
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
通俗来说:所谓数据库,其实就是有点类似于excel表格,主要就是用来管理数据,对数据进行增删改查的。所以某种程度上来说,excel也可以看成一个简单的数库,只不过是在文件中对数据的读写速度相对较慢,所以现在我们使用数据库管理系统来管理和存储大量的数据
1.2 数据库分类
- 关系型数据库,如 MySQL,Oracle,SqlServer等
- 非关系型数据库,如 Redis,Mongodb,Memcache等
1.3 关系型数据库的特点
- 数据以表格的形式出现
- 每行为各种记录的数据
- 每列为记录名称所对应的数据域
- 许多的行和列组成一张表单
- 若干的表单组成database
1.4 关系型数据库的常用术语
- 数据库: 数据库是一些关联表的集合。
- 数据表: 在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同的数据, 例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余可以使系统速度更快。(在查询时可能经常需要在多个表之间进行连接查询;而进行连接操作会降低查询速度。例如,学生的信息存储在student表中,院系信息存储在department表中。通过student表中的dept_id字段与department表建立关联关系。如果要查询一个学生所在系的名称,必须从student表中查找学生所在院系的编号(dept_id),然后根据这个编号去department查找系的名称。如果经常需要进行这个操作时,连接查询会浪费很多的时间。因此可以在student表中增加一个冗余字段dept_name,该字段用来存储学生所在院系的名称。这样就不用每次都进行连接操作了。)
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
二、认识MYSQL
MySQL是最流行的关系型数据库管理系统,在WEB应用方面MySQL是最好的RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。由瑞典MySQL AB公司开发,目前属于Oracle公司
2.1 MySQL的特点
- MySQL是开源的,所以你不需要支付额外的费用。
- MySQL使用标准的SQL数据语言形式。
- MySQL可以允许于多个系统上,并且支持多种语言。这些编程语言包括C、C++、Python、Java、Perl、PHP、Eiffel、Ruby和Tcl等。
- MySQL对PHP有很好的支持,PHP是目前最流行的Web开发语言。
- MySQL支持大型数据库,支持5000万条记录的数据,32位系统表文件最大可支持4GB,64位系统支持最大的表文件为8TB。
- MySQL是可以定制的,采用了GPL协议,你可以修改源码来开发自己的Mysql系统
2.2 MySQL逻辑分层
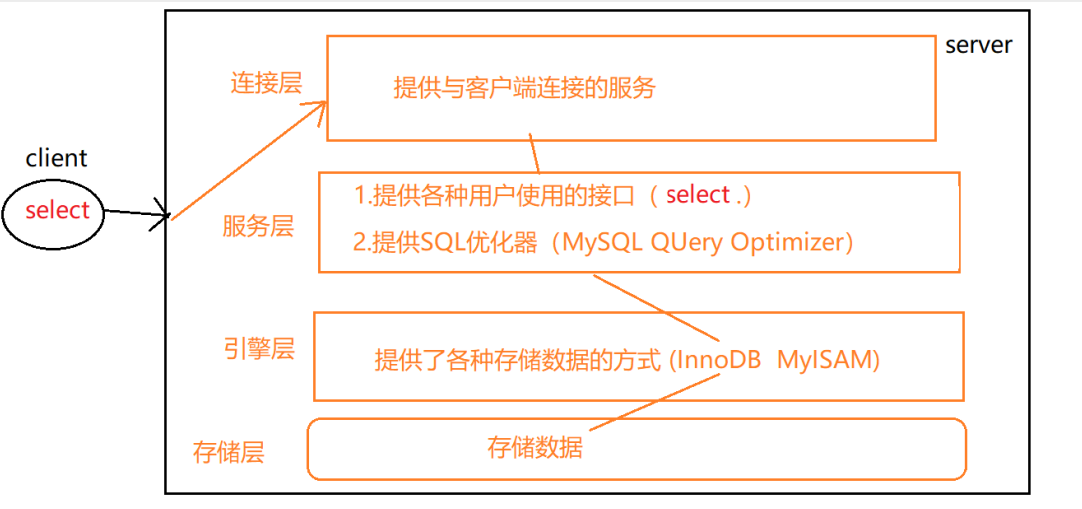
三、数据库的安装

3.1 Windows版本
3.1.1 下载
3.1.2 解压
如果想要让让MySQL安装在指定目录,那么就将解压后的文件夹移动到指定目录,如:C:\mysql-5.7.16-winx64
3.1.3 服务端初始化
MySQL解压后的 bin 目录下有一大堆的可执行文件,执行如下命令初始化数据
cd c:\mysql-5.7.16-winx64\bin mysqld --initialize-insecure
3.1.4 启动MySQL服务器
# 进入可执行文件目录 cd c:\mysql-5.7.16-winx64\bin # 启动MySQL服务 mysqld
3.1.5 启动MySQL客户端并连接MySQL服务
由于初始化时使用的【mysqld –initialize-insecure】命令,其默认未给root账户设置密码
# 进入可执行文件目录 cd c:\mysql-5.7.16-winx64\bin # 连接MySQL服务器 mysql -u root -p # 提示请输入密码,直接回车
登录成功后
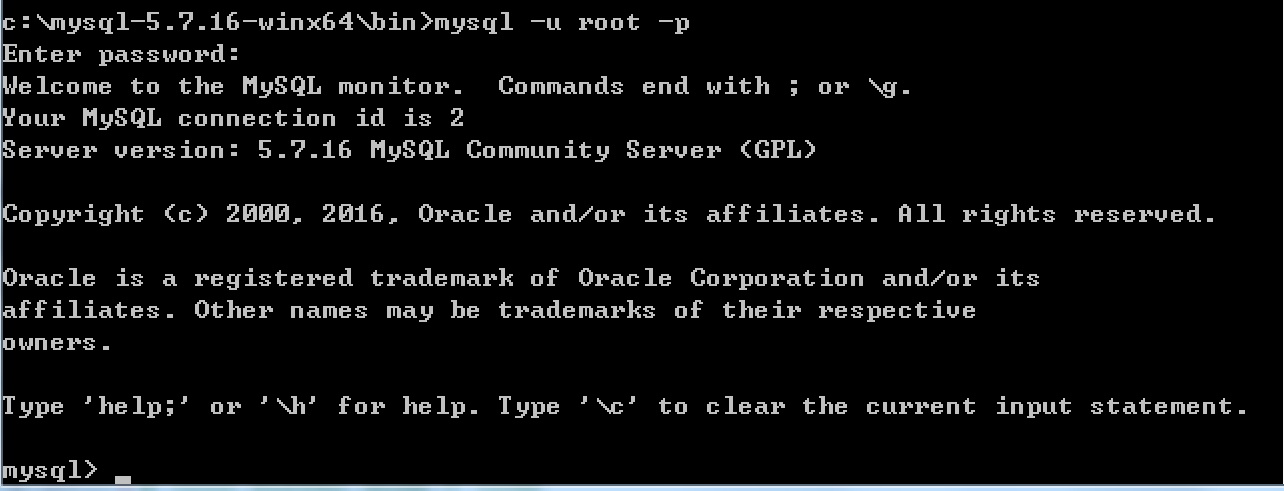
MySQL服务端已经安装成功并且客户端已经可以连接上,以后再操作MySQL时,只需要重复上述4、5步骤即可。但是,在4、5步骤中重复的进入可执行文件目录比较繁琐,如想日后操作简便,可以做如下操作:
1. 添加环境变量
将MySQL可执行文件添加到环境变量中,从而执行执行命令即可
右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【将MySQL的bin目录路径追加到变值值中,用 ; 分割】 如: C:\Program Files (x86)\Parallels\Parallels Tools\Applications;%SystemRoot%\system32;%SystemRoot%;%SystemRoot%\System32\Wbem;%SYSTEMROOT%\System32\WindowsPowerShell\v1.0\;C:\Python27;C:\Python35;C:\mysql-5.7.16-winx64\bin2. 将MySQL服务制作成windows服务
上一步解决了一些问题,但不够彻底,因为在执行【mysqd】启动MySQL服务器时,当前终端会被hang住,那么做一下设置即可解决此问题:
# 制作MySQL的Windows服务,在终端执行此命令: "c:\mysql-5.7.16-winx64\bin\mysqld" --install # 移除MySQL的Windows服务,在终端执行此命令: "c:\mysql-5.7.16-winx64\bin\mysqld" --remove注册成服务之后,以后再启动和关闭MySQL服务时,仅需执行如下命令:
# 启动MySQL服务 net start mysql # 关闭MySQL服务 net stop mysql
3.2 Linux版本
https://www.cnblogs.com/wangyong123/articles/11605254.html
四、数据库操作
4.1 显示数据库
SHOW DATABASE默认数据库:
mysql - 用户权限相关数据
test - 用户用户测试数据
informatin_schema - MySQL本身架构相关数据
4.2 创建数据库
CREATE DATABASE 数据库名称 DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
4.3 使用数据库
USE db_name
4.4 用户管理
4.4.1 创建用户
create user '用户名'@'IP地址' identified by '密码';create user 'wangyong'@'192.168.1.123' identified by '123qwe'; create user 'wangyong'@'192.168.1.%' identified by '123qwe'; create user 'wangyong'@'%' identified by '123qwe';
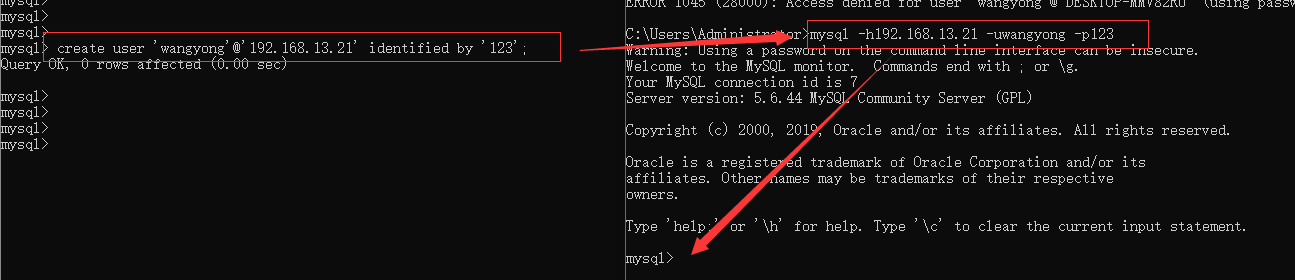
4.4.2 删除用户
drop user '用户名'@'IP地址';
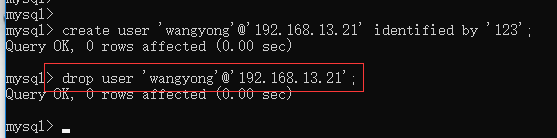
4.4.3 修改用户
rename user '用户名'@'IP地址'; to '新用户名'@'IP地址';
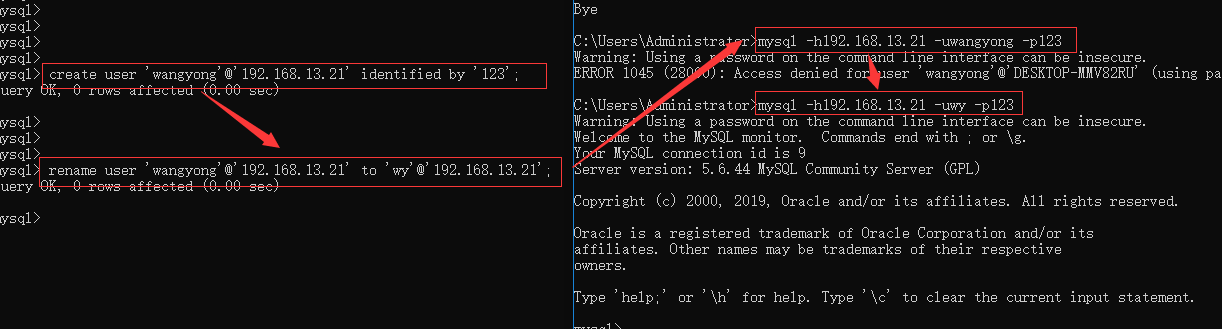
4.4.4 修改密码
set password for '用户名'@'IP地址' = Password('新密码')

4.5 授权管理
show grants for '用户'@'IP地址' -- 查看权限 grant 权限 on 数据库.表 to '用户'@'IP地址' -- 授权 revoke 权限 on 数据库.表 from '用户'@'IP地址' -- 取消权限
4.5.1 授权目标数据库的各种方式
数据库名.* 数据库中的所有 数据库名.表 指定数据库中的某张表 数据库名.存储过程 指定数据库中的存储过程 *.* 所有数据库
4.5.2 授权用户的各类方式
用户名@IP地址 用户只能在改IP下才能访问 用户名@192.168.1.% 用户只能在改IP段下才能访问(通配符%表示任意) 用户名@% 用户可以再任意IP下访问(默认IP地址为%)常见案例
grant all privileges on db1.tb1 TO '用户名'@'IP' grant select on db1.* TO '用户名'@'IP' grant select,insert on *.* TO '用户名'@'IP' revoke select on db1.tb1 from '用户名'@'IP'
1. 给db1下的所有文件查看权限: grant select on db1.* to 'wangyong'@'%'; 2. 给所有数据库的查看权限: grant select on *.* to 'wangyong'@'%'; 3. 给db1下的所有文件查看,插入,删除权限: grant select, insert, delete on db1.* to 'wangyong'@'%';
操作完成之后,不会立即生效,要想立即生效,可以如下操作:
flush privileges,将数据读取到内存中,从而立即生效
五、MySQL数据类型
数据库建表语句
create table 表名 ( 列1 [列属性 是否为null 默认值], 列2 [列属性 是否为null 默认值], ..... 列n [列属性 是否为null 默认值] )engine = 存储引擎 charset = 字符集
5.1 数值型
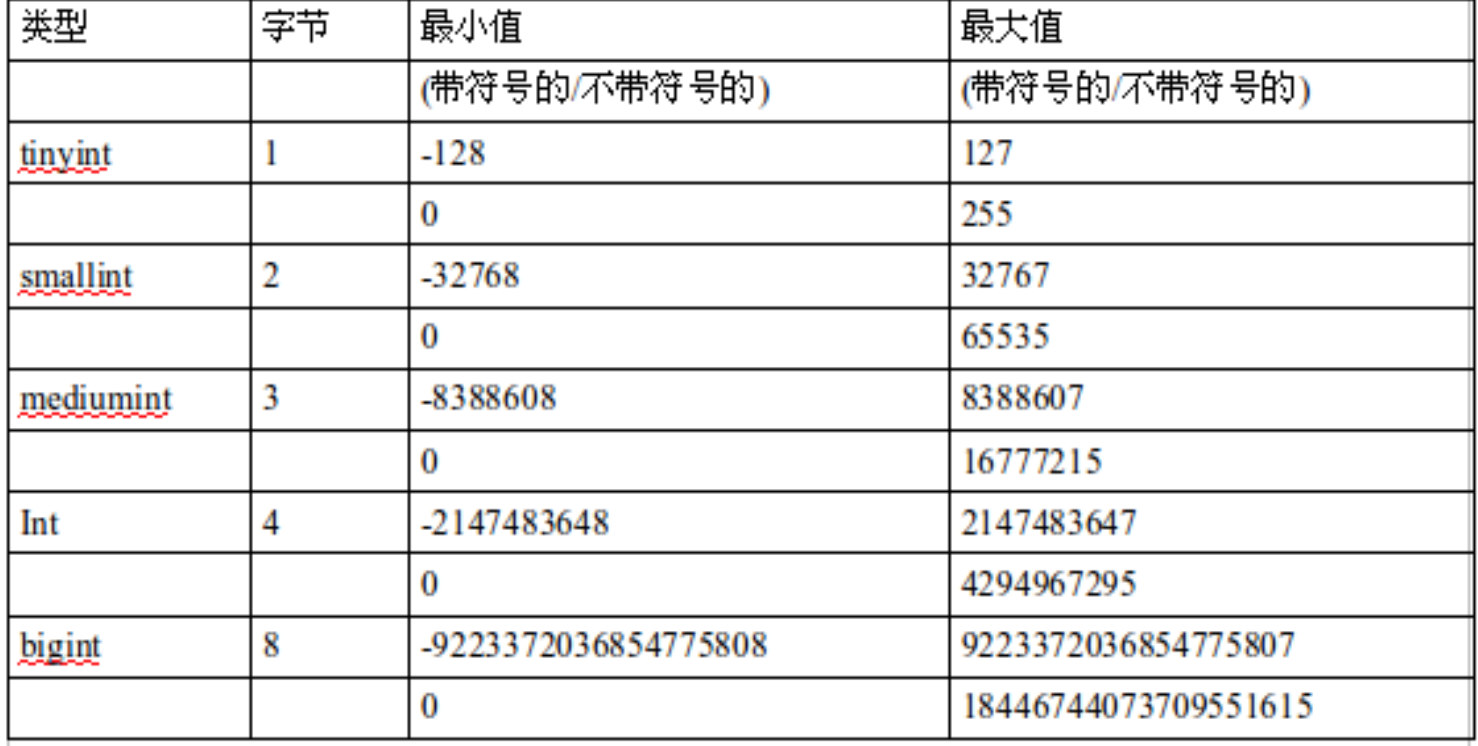
补充:
unsigned表示为无符号 float(M,D) 浮点型 decimal(M,D) 定点型 比float更加的精准 M: 精度(总位数)D: 标度(小数位)
5.2 字符创类型

5.3 时间日期类型

5.4 特殊的NULL类型
- NULL 不是假,也不是真,而是”空”
- NULL 的判断只能用is null,is not null
- NULL 影响查询速度,一般避免使值为NULL
六、 数据表操作
6.1 创建表
create table 表名 ( 列1 [列属性 是否为null 默认值], 列2 [列属性 是否为null 默认值], ..... 列n [列属性 是否为null 默认值] )engine = 存储引擎 charset = 字符集
6.1.1 解释说明
是否为null
not null - 不可空 null - 可空
默认值
创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值
create table tb1( id int not null default 2, num int not null )
自增
如果为某列设置自增列,插入数据时无需设置此列,默认将自增(表中只能有一个自增列)
create table tb1( nid int not null auto_increment primary key, num int null ) 或 create table tb1( nid int not null auto_increment, num int null, index(nid) )
6.1.2 注意
对于自增列,必须是索引(含主键)
对于自增可以设置步长和起始值
show session variables like 'auto_inc%'; set session auto_increment_increment = 2; set session auto_increment_offset = 10; shwo global variables like 'auto_inc%'; set global auto_increment_increment = 2; set global auto_increment_offset = 10;
主键
一种特殊的唯一索引,不允许有空值,如果主键使用单个列,则它的值必须唯一,如果是多列,则其组合必须唯一
create table tb1( nid int not null auto_increment primary key, num int null ) 或 create table tb1( nid int not null, num int not null, primary key(nid,num) )
外键
creat table color( nid int not null primary key, name char(16) not null ) create table fruit( nid int not null primary key, smt char(32) null , color_id int not null, constraint fk_cc foreign key (color_id) references color(nid) )
create table department ( id int auto_increment primary key, depart_name char(32) not null default '' )engine=innodb charset=utf8;create table userinfo ( id int auto_increment primary key, name varchar(32) not null default '', depart_id int not null default 1, constraint fk_userinfo_depart foreign key (depart_id) references department(id) )engine=innodb charset=utf8;
6.2 删除表
drop table 表名
6.3 清空表
delete from 表名 truncate table 表名
6.4 修改表
添加列:alter table 表名 add 列名 类型 删除列:alter table 表名 drop column 列名 修改列: alter table 表名 modify column 列名 类型; -- 类型 alter table 表名 change 原列名 新列名 类型; -- 列名,类型 添加主键: alter table 表名 add primary key(列名); 删除主键: alter table 表名 drop primary key; alter table 表名 modify 列名 int, drop primary key; 添加外键:alter table 从表(需要添加外键的表) add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段); 删除外键:alter table 表名 drop foreign key 外键名称
七、表的增删改查
7.1 增加
insert into 表 (列名,列名...) values (值,值,值...) insert into 表 (列名,列名...) values (值,值,值...),(值,值,值...) insert into 表 (列名,列名...) select (列名,列名...) from 表注释:列名可以不写,如果不写,则默认插入所有列的数据
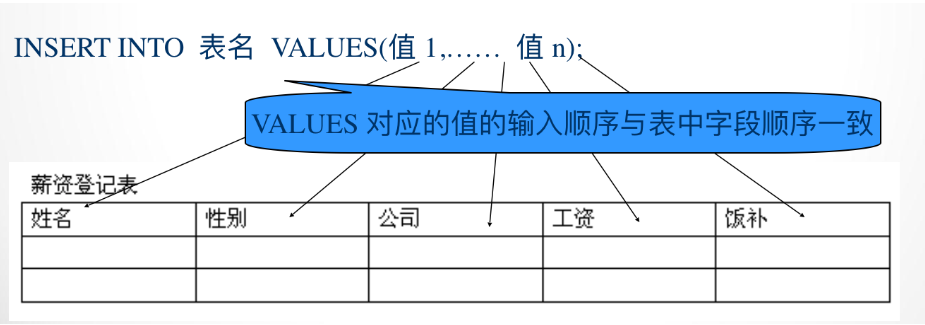
7.2 删除
delete from 表 delete from 表 where id=1 and name='wangyong'
7.3 修改
update 表 set name = 'wangyong' update 表 set name = 'wangyong' where id>1
7.4 基本查询
select * from 表// 查询表的字段 desc 表
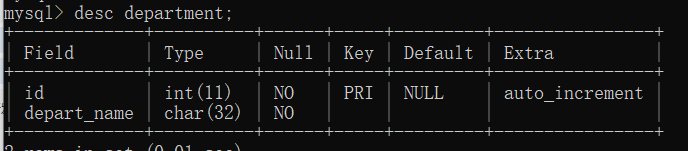
7.5 高级查询
https://www.cnblogs.com/wangyong123/articles/11615602.html
八、存储引擎
8.1 存储引擎的特点和分类
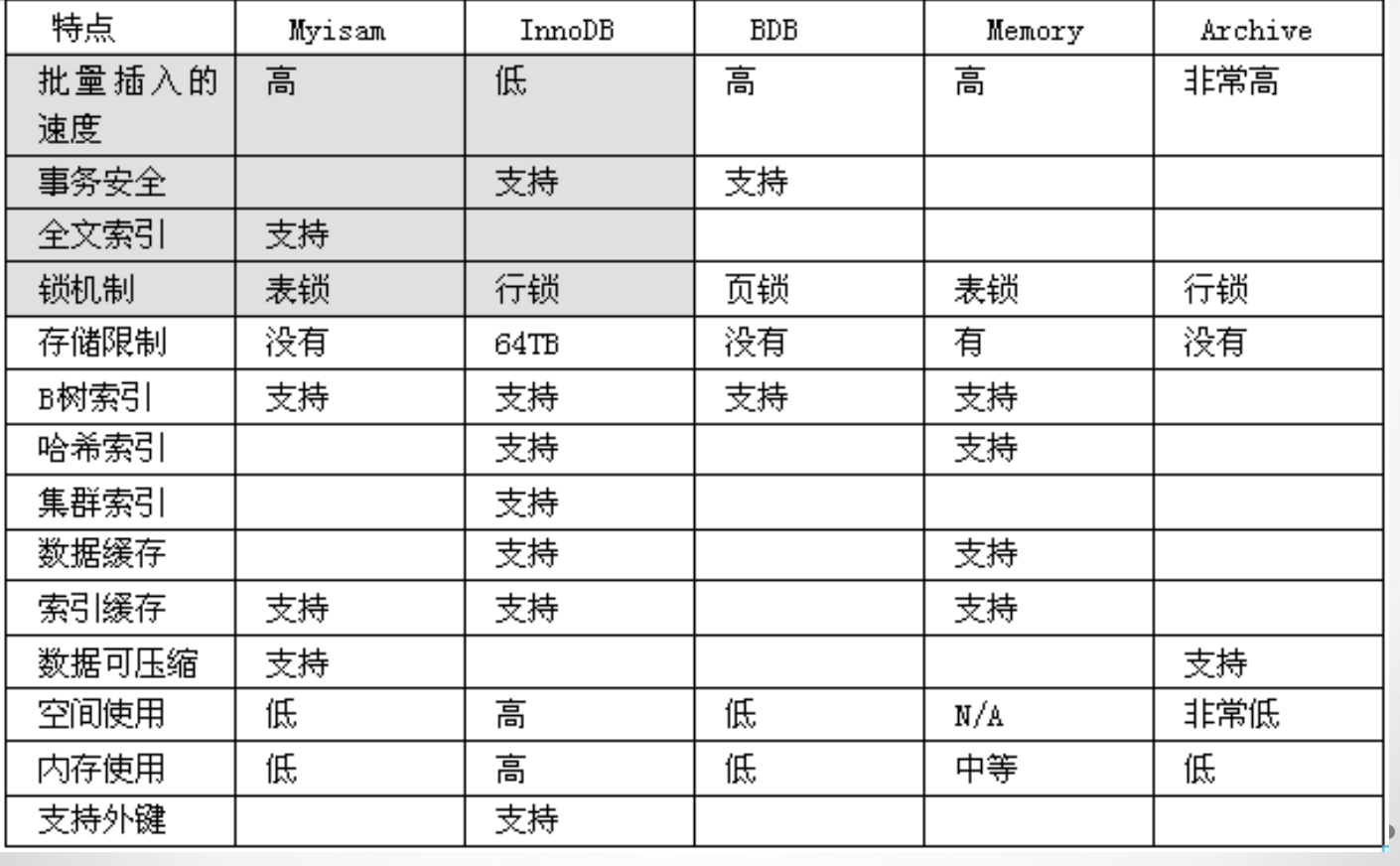
8.2 存储引擎的选择
对不同的数据有不同的管理方式和存储方式,在mysql中称之为存储引擎
1). 文章,新闻等安全性要求不高的,选myisam
2). 订单,资金,账单,火车票等对安全性要求高的,选用innodb
3). 对于临时中转表,可以用memory型 ,速度最快4). 中文全文索引:sphinx
# Innodb 1.(默认版本包含5.5) 2.支持事务 3.不支持全文索引 4.索引和数据都是在同一个文件中, .ibd 表的结构实在.frm文件中 # MyIsam 1.(默认版本5.5以下 5.3) 2.不支持事务 3.支持全文索引 4..frm: 表结构 .MYD: 表数据 .MYI: 表索引 # 常用的全文索引: sphinx ES
九、SQLAchemy
将代码转换成SQL语句执行:类 ------> 表
实例化 -> 数据
9.1 创建表
from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column,Integer, String,ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine # 链接MySQL engine = create_engine("mysql+pymysql://root@127.0.0.1:3306/day45?charset=utf8", max_overflow = 5) # max_overflow = 5代表最大连接池为5 # 声明Base类,后续的类都要继承Base类 Base = declarative_base() # 创建单表 """ create table user( id int auto_increment primary key, name varchar(32) not null default '', extra varchar(32) not null default '' )engine=Innodb charset=utf8 """ # 创建usertype, 并设置id,title class UserType(Base): __tablename__ = "usertype" # 表名 id = Column(Integer, autoincrement=True, primary_key=True) title = Column(String(32), nullable=False,server_default="") # 创建user表,并设置表的id, name, extra class Users(Base): __tablename__ = 'user' # 表名 id = Column(Integer, autoincrement=True, primary_key=True) # Column:字段,列 name = Column(String(32), nullable=False, server_default="") # name = Column(String(32), nullable=False, server_default="", unique=True) # 给name这一列添加唯一索引 extra = Column(String(32), nullable=False, server_default="") # extra:特点 # 外键(让User中的id与UserType中的id发生了外键的关系) type_id = Column(Integer, ForeignKey(UserType.id)) # type_id = Column(Integer, ForeignKey("usertype".id)) # # 添加索引 # __table_args__ = ( # UniqueConstraint("id", "name", name="uix_id_name"), # 给id,name添加联合唯一索引 # Index("ix_id_name","name", "extra") # 给name,extra添加普通索引 # ) # 删除表 def drop_db(): Base.metadata.drop_all(engine) # 会将当前文件中所有继承自Base类的类,生成表 def create_db(): Base.metadata.create_all(engine)
9.2 操作表
# 操作表中的数据 Session = sessionmaker(bind=engine) session = Session() # session:窗口, 实例化Session,相当于从连接池中拿一个连接过来进行操作
9.2.1 添加数据
# 往UserType中添加数据, 因为UserType与User存在外键联系,所以给UserType添加数据,则再往User中添加数据时,type_id就会有数据产生 # 添加一条数据 obj = UserType(title = "普通用户") session.add(obj) # 把对象数据添加到数据库中 # 添加多条数据 session.add_all([ UserType(title = "VIP用户"), UserType(title = "VIP中P用户"), UserType(title = "SVIP用户"), UserType(title = "黑金用户") ]) session.commit() session.close()
9.2.2 查询数据
(.all(), .first())
res = session.query(UserType) # 这一步就是将代码转换成SQL语句 print(res) # SELECT usertype.id AS usertype_id, usertype.title AS usertype_title FROM usertype # 查询全部,返回的是列表,列表中是对象 res = session.query(UserType).all() # .all()就是讲SQL语句发送给服务端执行SQL指令,得到一个列表对象 print(res) # [<__main__.UserType object at 0x00000164C846BEF0>, <__main__.UserType object at 0x00000164C846BF60>, <__main__.UserType object at 0x00000164C846BDA0>, <__main__.UserType object at 0x00000164C846BDD8>, <__main__.UserType object at 0x00000164C846BC88>] for k in res: print(k.id, k.title) # 1 普通用户 # 2 VIP用户 # 3 VIP中P用户 # 4 SVIP用户 # 5 黑金用户 # 查询一条,获得一条对象 res = session.query(UserType).first() print(res) # <__main__.UserType object at 0x000001640E9EBDD8> print(res.id, res.title) # 1 普通用户
类似sql中的where查询(filter(), filter_by())
# filter res = session.query(UserType).filter(UserType.title=="VIP用户") # filter 将查找(过滤)的条件转换成SQL语句 print(res) # SELECT usertype.id AS usertype_id, usertype.title AS usertype_title FROM usertype WHERE usertype.title = %(title_1)s res = session.query(UserType).filter(UserType.title=="VIP用户", UserType.id==2).all() # .first()与上一样 print(res) # [<__main__.UserType object at 0x000002C1ADFD73C8>] for row in res: print(row.id, row.title) # 2 VIP用户 print(res[0].id, res[0].title) # 2 VIP用户 # filter_by 传入的是一个类似key=value的数据, filter中传入的是一个表达式 res = session.query(UserType).filter_by(title="VIP用户").all() print(res) # [<__main__.UserType object at 0x000001FCDB07FDA0>]
9.2.3 删除数据(delete)
# 删除数据之前先查找数据 session.query(UserType).filter(UserType.id>3).delete() session.query(UserType).delete() # 相当于删除整个表
9.2.4 修改数据(update)
session.query(UserType).filter(UserType.id == 3).update({"title":"SVIP用户"}) # 将id=3数据的title的值改为SVIP用户
9.2.5 高级查询
""" 高级查询: 通配符、分组、排序、between and、in、not in、or """ """ 此时数据恢复成如下所示 +----+------------+ | id | title | +----+------------+ | 1 | 普通用户 | | 2 | VIP用户 | | 3 | VIP中P用户 | | 4 | SVIP用户 | | 5 | 黑金用户 | +----+------------+ """ # 逗号默认为 and res = session.query(UserType).filter(UserType.id==2, UserType.title=="VIP用户").all() for row in res: print(row.id, row.title) # row # between(1,3) 在1到3的范围内,包括1和3 res = session.query(UserType).filter(UserType.id.between(1,3 )).all() for row in res: print(row.id, row.title) # 1 普通用户 # 2 VIP用户 # 3 VIP中P用户 # in not in res = session.query(UserType).filter(UserType.id.in_([1,3,4])).all() ret = session.query(UserType).filter(~UserType.id.in_([1,3,4])).all() print(res) # [<__main__.UserType object at 0x000002839AD46048>, <__main__.UserType object at 0x000002839AD46198>, <__main__.UserType object at 0x000002839AD46278>] print(ret) # [<__main__.UserType object at 0x000002839AD467B8>, <__main__.UserType object at 0x000002839AD46828>] rer = session.query(UserType).filter(UserType.id.in_(session.query(UserType.id).filter_by(title='VIP用户'))).all() print(rer) # [<__main__.UserType object at 0x0000023CBD0D57B8>] from sqlalchemy import and_,or_ ret = session.query(UserType).filter(and_(UserType.id > 3, UserType.title == 'VIP用户')).all() res = session.query(UserType).filter(or_(UserType.id < 2, UserType.title == 'VIP用户')).all() print(ret) print(res) # 通配符 ret = session.query(UserType).filter(UserType.title.like('S%')).all() res = session.query(UserType).filter(~UserType.title.like('S%')).all() print(ret) print(res) # 排序 ret = session.query(UserType).order_by(UserType.title.desc()).all() res = session.query(UserType).order_by(UserType.title.desc(), UserType.id.asc()).all() # 分组 group_by """ +----+----------+-------+---------+ | id | name | extra | type_id | +----+----------+-------+---------+ | 1 | wangyong | nb | 5 | | 2 | liguo | cb | 3 | | 3 | jiyuzhi | sb | 1 | | 4 | kelinwei | zb | 3 | | 5 | gouyang | bb | 2 | +----+----------+-------+---------+ """ from sqlalchemy.sql import func res = session.query( Users.type_id, func.max(Users.id), func.min(Users.id)).group_by(Users.type_id).all() print(res) # [(1, 3, 3), (2, 5, 5), (3, 4, 2), (5, 1, 1)] res = session.query( Users.type_id, func.max(Users.id), func.min(Users.id)).group_by(Users.type_id).having(func.min(Users.id)>2).all() print(res) # [(1, 3, 3), (2, 5, 5)] """ 连表 """ res = session.query(Users).join(UserType) print(res) # SELECT user.id AS user_id, user.name AS user_name, user.extra AS user_extra, user.type_id AS user_type_id # FROM user INNER JOIN usertype ON usertype.id = user.type_id res = session.query(Users).join(UserType,isouter=True) # 会自动检测是否含有外键,如果存在,会自动进行关联 print(res) # SELECT user.id AS user_id, user.name AS user_name, user.extra AS user_extra, user.type_id AS user_type_id # FROM user LEFT OUTER JOIN usertype ON usertype.id = user.type_id res = session.query(Users).join(UserType,isouter=True).all() # 存在问题:只能查询到Users表的值,UserType表中的值无法查询 print(res) # [<__main__.Users object at 0x0000026AD9D74898>, <__main__.Users object at 0x0000026AD9D74908>, <__main__.Users object at 0x0000026AD9D74978>, <__main__.Users object at 0x0000026AD9D749E8>, <__main__.Users object at 0x0000026AD9D74A58>] for row in res: print(row.id, row.name) # 1. 想要既能查询到Users表中数据,又能查询到UserType中的数据 # 方法一: res = session.query(Users, UserType).join(UserType,isouter=True).all() print(row[0].id, row[0].name, row[1].title) # 方法二:使用relationship 在Users类中加入 usertype = relationship('UserType') # 关联到UserType,在创建User表时,会将UserType的数据添加到Users中,但是不会显示出来,就相当于一个隐藏属性 res = session.query(Users).all() for row in res: print(row.id, row.name, row.extra, row.usertype.title) # 2.想要知道某一个类型下面的用户 # 第一种 res = session.query(UserType).all() for row in res: print(row.id, row.title, session.query(Users.id).filter(Users.type_id==row.id).all()) # 第二种 在定义Users类时,继续添加 usertype = relationship('UserType', backref = "xxoo") backref:反向查询 res = session.query(UserType).all() for row in res: print(row.id, row.title, row.xxoo) # row.xxoo 多条记录查询 # relationship 哪张表中有外键,就把relationship 放在哪张表中
十、使用mysql.connector操作MySQL数据库以及解决SQL注入问题
pip install connectorimport mysql.connector class MysqlConnector: host = None user = None password = None database = None conn = None cursor = None def __init__(self, host="localhost", user="root", password="", database=database): """ init """ self.host = host self.user = user self.password = password self.database = database def connect_database(self): """ 连接数据库 :return: """ self.conn = mysql.connector.connect( host=self.host, user=self.user, password=self.password, database=self.database, # 使用已经存在的数据库,可以打开这一行 autocommit=True # 这个参数配置完成后 增删改操作都不需要在手动加conn.commit()了 ) # 获取游标实例 self.cursor = self.conn.cursor() def create_database(self, database): """ 创建新的数据库 :param database: :return: """ # 创建数据库 sql = f"create database {database}" self.cursor.execute(sql) # 展示执行数据库 sql = f"show databases" self.cursor.execute(sql) # 展示执行结果 # print(self.cursor) # MySQLCursor: show databases for database in self.cursor: print(database) # ('connector',), ('day02',) def create_table(self): """ 创建数据表 :return: """ # 创建表 sql = """ create table user ( id int auto_increment primary key, name varchar(20), class varchar(255) ) """ self.cursor.execute(sql) def insert_data_to_table(self): """ 插入数据到数据表中 :return: """ # 插入一条数据 sql = "insert into user(name, class) values (%s, %s)" values = ("WangYong", "211") # 元组格式 # execute也可以传入多个值,第一个是 sql语句,第二个是 sql语句的占位符数据 self.cursor.execute(sql, values) # 提交 autocommit=True # self.conn.commit() # 查看影响的行数 rowcount = self.cursor.rowcount print(f"{rowcount}记录创建成功") # 插入多条数据 sql = "insert into user(name, class) values (%s, %s)" values = [("WeiWei", "212"), ("WY", "213"), ("WW", "214")] self.cursor.executemany(sql, values) # autocommit=True # self.conn.commit() rowcount = self.cursor.rowcount print(f"{rowcount}记录创建成功") def select_database(self): """ 查看数据表的数据 fetchall()获取所有的记录 fetchone()获取第一行记录 fetchmany(size)获取前几行记录 :return: """ sql = "select * from user where name=%s" value = ("WeiWei",) self.cursor.execute(sql, value) res = self.cursor.fetchall() print(type(res), res) # <class 'list'> [(1, 'WangYong', '211'), (2, 'WangYong', '211')] def sql_inject(self): """ sql注入问题 因为太过于相信用户的输入, 导致我们在接受用户输入的参数的时候, 并没有对他进行转义 避免sql注入的方法: 1. 自己手工对用户输入的值进行转义 2. 使用execute()自动进行过滤 :return: """ # sql注入,下面的问题是会查询所有的数据 sql = "select * from user where name='WangYong' or 1=1" # 避免sql注入的问题, 一般sql语句中用占位符传值 # sql = "select * from user where name=%s" # value = ("WangYong",) # self.cursor.execute(sql, value) self.cursor.execute(sql) res = self.cursor.fetchall() print(res) if __name__ == '__main__': mysql_obj = MysqlConnector("localhost", "root", "", "connector") mysql_obj.connect_database() # mysql_obj.create_database("connector") mysql_obj.create_table() mysql_obj.insert_data_to_table() mysql_obj.select_database() mysql_obj.sql_inject()
十一、使用pymysql操作MySQL数据库(和mysql.connector基本一样)
import pymysql class PyMySQL: host = None user = None password = None database = None conn = None cursor = None def __init__(self, host="localhost", user="root", password="", database=database): """ init """ self.host = host self.user = user self.password = password self.database = database def connect_database(self): """ 连接数据库 :return: """ self.conn = pymysql.connect( host=self.host, port=3306, # 数据库端口号 user=self.user, password=self.password, database=self.database, charset='utf8', # 编码千万不要加- 如果写成了utf-8会直接报错 autocommit=True # 这个参数配置完成后 增删改操作都不需要在手动加conn.commit()了 ) print(self.conn) # 产生游标对象 self.cursor = self.conn.cursor(pymysql.cursors.DictCursor) # 产生一个游标对象 每行数据 以字典的形式或列表套元组 def create_database(self, database): """ 创建新的数据库 :param database: :return: """ # 创建数据库 sql = f"create database {database}" self.cursor.execute(sql) # 展示执行数据库 sql = f"show databases" self.cursor.execute(sql) # 展示执行结果 # print(self.cursor) # MySQLCursor: show databases for database in self.cursor: print(database) # ('connector',), ('day02',) def create_table(self): """ 创建数据表 :return: """ # 创建表 sql = """ create table user ( id int auto_increment primary key, name varchar(20), class varchar(255) ) """ self.cursor.execute(sql) def insert_data_to_table(self): """ 插入数据到数据表中 :return: """ # 插入一条数据 sql = "insert into user(name, class) values (%s, %s)" values = ("WangYong", "211") # 元组格式 # execute也可以传入多个值,第一个是 sql语句,第二个是 sql语句的占位符数据 self.cursor.execute(sql, values) # 提交 autocommit=True # self.conn.commit() # 查看影响的行数 rowcount = self.cursor.rowcount print(f"{rowcount}记录创建成功") # 插入多条数据 sql = "insert into user(name, class) values (%s, %s)" values = [("WeiWei", "212"), ("WY", "213"), ("WW", "214")] self.cursor.executemany(sql, values) # autocommit=True # self.conn.commit() rowcount = self.cursor.rowcount print(f"{rowcount}记录创建成功") def select_database(self): """ 查看数据表的数据 fetchall()获取所有的记录 fetchone()获取第一行记录 fetchmany(size)获取前几行记录 :return: """ sql = "select * from user where name=%s" value = ("WeiWei",) self.cursor.execute(sql, value) res = self.cursor.fetchall() print(type(res), res) # <class 'list'> [(1, 'WangYong', '211'), (2, 'WangYong', '211')] if __name__ == '__main__': mysql_obj = PyMySQL("localhost", "root", "", "PyMySQL") mysql_obj.connect_database() # mysql_obj.create_database("PyMySQL") mysql_obj.create_table() mysql_obj.insert_data_to_table() mysql_obj.select_database()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号