五、SWIG 之 库
使用 %include 指令包含库文件。搜索文件时,将按以下顺序搜索目录:
1. 当前目录
2. 用 -I 命令行选项指定的目录
3. ./swig_lib
4. SWIG 库的安装位置(由 swig -swiglib 报告),例如 /usr/local/share/swig/1.3.30
5. 在 Windows 上,还将搜索相对于 swig.exe 位置的目录 Lib。
在第 3-5 点提到的目录中,SWIG 首先查找与目标语言相对应的子目录(例如,python)。如果找到,SWIG 将首先搜索特定语言的目录。这允许特定语言的库文件实现。你可以通过设置 SWIG_LIB 环境变量来忽略已安装的 SWIG 库。设置环境变量以保存备用库目录。
使用 -verbose 命令行选项时,将显示搜索到的目录。
2.1 cpointer.i
%pointer_functions(type, name)生成五个用于关于指针 type * 的函数:
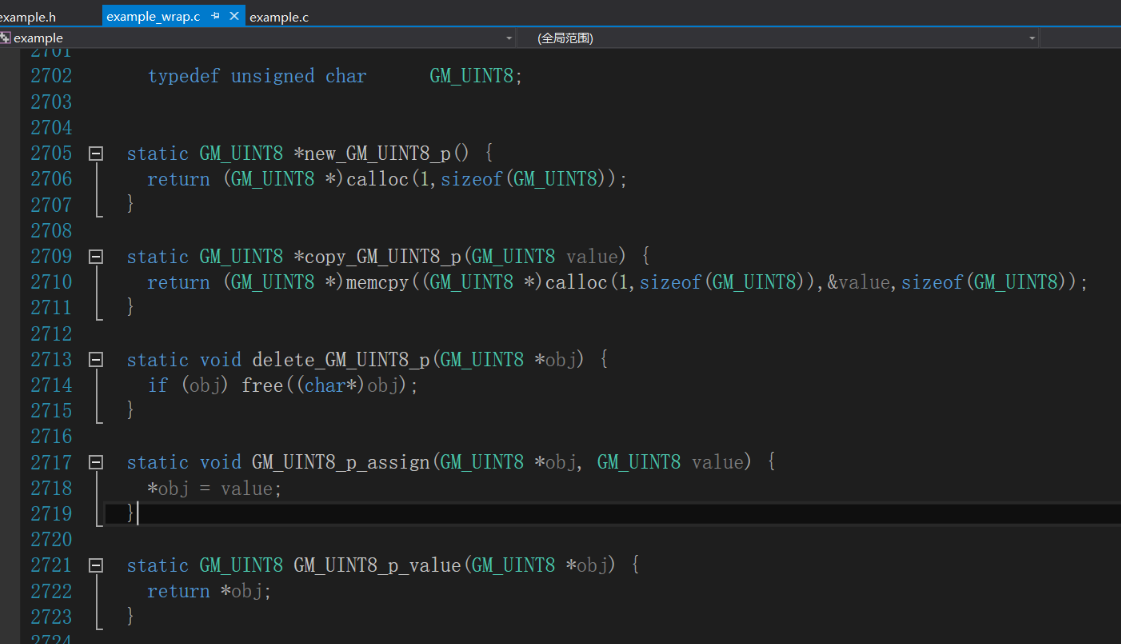
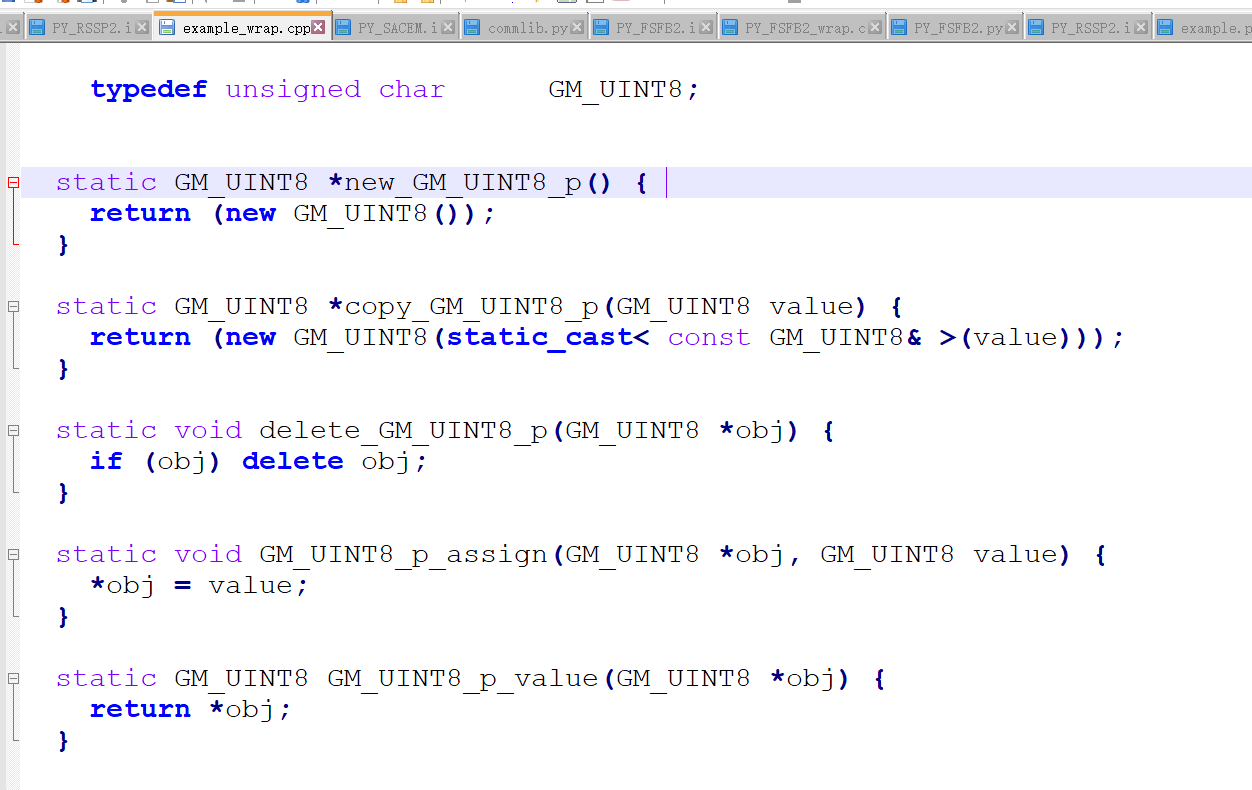
/* example.i */ %module example %include "cpointer.i" %inline %{ typedef unsigned char GM_UINT8; %} %pointer_functions(GM_UINT8, GM_UINT8_p)/* example_wrap.c */ // 创建一个类型为 type 的新对象,并返回一个指向它的指针。在 C 语言中,使用 calloc() 创建对象。在 C++ 中,使用 new。 static GM_UINT8 *new_GM_UINT8_p() { return (GM_UINT8 *)calloc(1,sizeof(GM_UINT8)); } // 创建一个类型为 type 的新对象,并返回一个指向它的指针。通过从 value 中复制值来设置初始值。在 C 语言中,使用 calloc() 创建对象。在 C++ 中,使用 new。 static GM_UINT8 *copy_GM_UINT8_p(GM_UINT8 value) { return (GM_UINT8 *)memcpy((GM_UINT8 *)calloc(1,sizeof(GM_UINT8)),&value,sizeof(GM_UINT8)); } // 删除一个 type 类型的对象。 static void delete_GM_UINT8_p(GM_UINT8 *obj) { if (obj) free((char*)obj); } // 赋值 *obj = value。 static void GM_UINT8_p_assign(GM_UINT8 *obj, GM_UINT8 value) { *obj = value; } // 返回 *obj 的值。 static GM_UINT8 GM_UINT8_p_value(GM_UINT8 *obj) { return *obj; }// example.wrap.cpp static GM_UINT8 *new_GM_UINT8_p() { return (new GM_UINT8()); } static GM_UINT8 *copy_GM_UINT8_p(GM_UINT8 value) { return (new GM_UINT8(static_cast< const GM_UINT8& >(value))); } static void delete_GM_UINT8_p(GM_UINT8 *obj) { if (obj) delete obj; } static void GM_UINT8_p_assign(GM_UINT8 *obj, GM_UINT8 value) { *obj = value; } static GM_UINT8 GM_UINT8_p_value(GM_UINT8 *obj) { return *obj; }
// example.c typedef unsigned int GM_UINT32; void add(GM_UINT32 x, GM_UINT32 y, GM_UINT32 *result) { *result = x + y; }/* example.i */ %module example %include "cpointer.i" %inline %{ typedef unsigned int GM_UINT32; %} %pointer_functions(GM_UINT32, GM_UINT32_p) extern void add(GM_UINT32 x, GM_UINT32 y, GM_UINT32 *result);# script.py import example c = example.new_GM_UINT32_p() example.add(3, 4, c) print(example.GM_UINT32_p_value(c)) # 7 example.delete_GM_UINT32_p(c)
在基于类的接口内包装 type * 指针。该接口如下
说明: 使用 pointer_class 好像就不能使用 typedef unsigned int GM_UINT32; 否则这样传递的参数数字就会报 GM_UINT32 错误,不明白为什么。
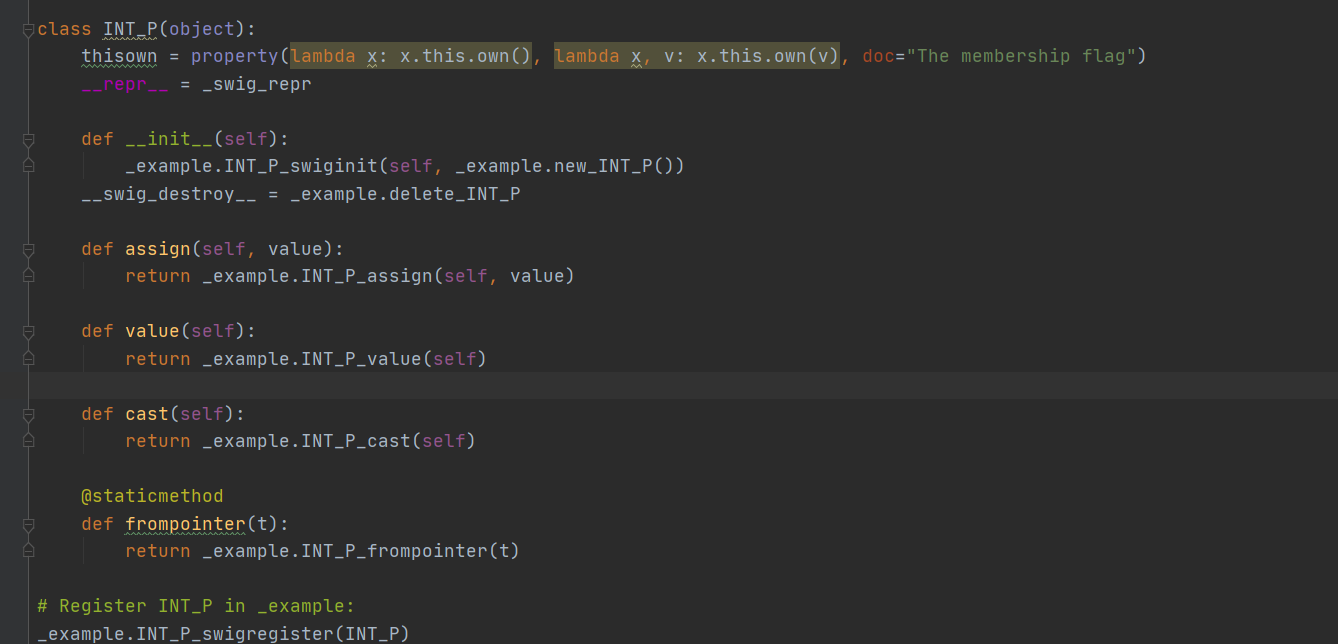
struct name { name(); // Create pointer object ~name(); // Delete pointer object void assign(type value); // Assign value type value(); // Get value type *cast(); // Cast the pointer to original type static name *frompointer(type *); // Create class wrapper from existing // pointer };// example.c void add(int x, int y, int *result) { *result = x + y; }/* example.i */ %module example %include "cpointer.i" %pointer_class(int, INT_P) extern void add(int x, int y, int *result);# script.py import example c = example.INT_P() example.add(3, 4, c) print(c.value()) # 7
和%pointer_functions相对, %pointer_class 可能是处理简单指针时最方便的方法。这是因为指针可以像对象一样被访问,并且可以很容易地对其进行垃圾回收(指针对象的破坏会破坏基础对象)。
/* example.i */ %module example %include "cpointer.i" %pointer_cast(int *, char *, int_to_uint);# script.py import example print(example.int_to_uint(10)) # 10 print(example.int_to_uint(-1)) # 4294967295注意:这些宏均不能安全地处理字符串(char * 或 char **)。
注意:当使用简单的指针时,类型映射通常可以用来提供更无缝的操作。
%array_functions(type, name)生成四个用于关于指针 type * 的函数:
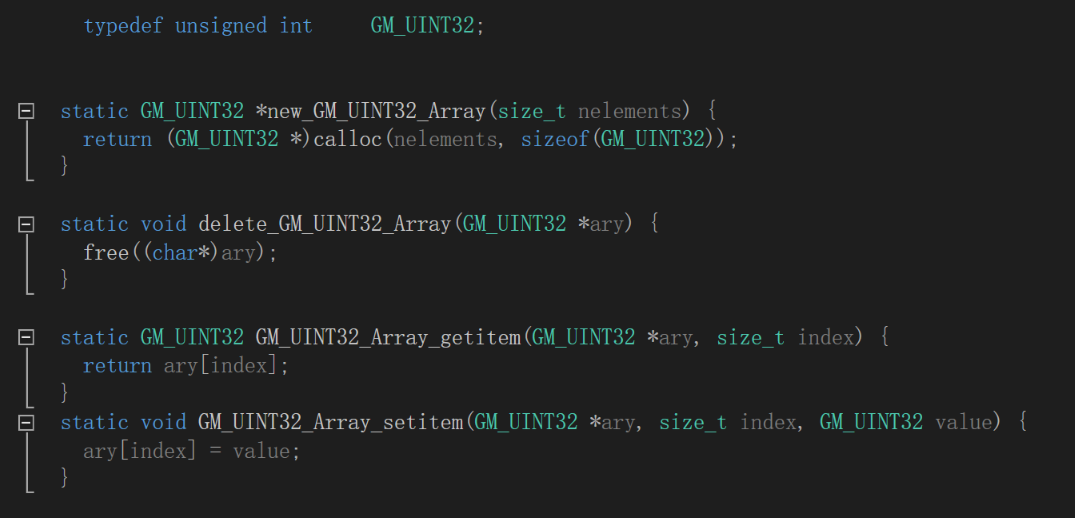
/* example.i */ %module example %include "carrays.i" %inline %{ typedef unsigned int GM_UINT32; %} %array_functions(GM_UINT32, GM_UINT32_Array)/* example_wrap.c */ // 创建一个类型为 type 的对象的数组。在 C 语言中,使用 calloc() 分配数组。在 C++ 中,使用 new []。 static GM_UINT32 *new_GM_UINT32_Array(size_t nelements) { return (GM_UINT32 *)calloc(nelements, sizeof(GM_UINT32)); } // 删除数组。在 C 中使用 free()。在 C++ 中使用 delete []。 static void delete_GM_UINT32_Array(GM_UINT32 *ary) { free((char*)ary); } // 返回值 ary[index]。 static GM_UINT32 GM_UINT32_Array_getitem(GM_UINT32 *ary, size_t index) { return ary[index]; } // 赋值 ary[index] = value。 static void GM_UINT32_Array_setitem(GM_UINT32 *ary, size_t index, GM_UINT32 value) { ary[index] = value; }
// example.wrap.cpp static GM_UINT32 *new_GM_UINT32_Array(size_t nelements) { return (new GM_UINT32[nelements]()); } static void delete_GM_UINT32_Array(GM_UINT32 *ary) { delete[] ary; } static GM_UINT32 GM_UINT32_Array_getitem(GM_UINT32 *ary, size_t index) { return ary[index]; } static void GM_UINT32_Array_setitem(GM_UINT32 *ary, size_t index, GM_UINT32 value) { ary[index] = value; }
使用此宏时,type 可以是任何类型,而 name 必须是目标语言中的合法标识符。名称不应该与接口文件中使用的任何其他名称相对应。

// example.c typedef unsigned int GM_UINT32; void print_array(GM_UINT32 x[10]) { int i; for (i = 0; i < 10; i++) { printf("[%d] = %d\n", i, x[i]); } }/* example.i */ %module example %include "carrays.i" %inline %{ typedef unsigned int GM_UINT32; %} %array_functions(GM_UINT32, GM_UINT32_Array) void print_array(GM_UINT32 x[10]);# script.py import example x = [1, 2, 3, 4, 5, 6, 7, 8] array = example.new_GM_UINT32_Array(1024) [example.GM_UINT32_Array_setitem(array, i, x[i]) for i in range(len(x))] example.print_array(array) example.delete_GM_UINT32_Array(array)
struct name { name(int nelements); // Create an array ~name(); // Delete array type getitem(int index); // Return item void setitem(int index, type value); // Set item type *cast(); // Cast to original type static name *frompointer(type *); // Create class wrapper from // existing pointer };使用此宏时,type 仅限于一个简单的类型名称,例如 int 或 float。不允许使用指针和其他复杂类型。名称必须是尚未使用的有效标识符。将指针包装为类时,可以将其透明地传递给任何需要该指针的函数。
说明: 使用 array_class 好像就不能使用 typedef unsigned int GM_UINT32; 否则这样传递的参数数字就会报 GM_UINT32 错误,不明白为什么。
// example.c void print_array(int x[10]) { int i; for (i = 0; i < 10; i++) { printf("[%d] = %d\n", i, x[i]); } }/* example.i */ %module example %include "carrays.i" %array_class(int, INT_Array) void print_array(int x[10]);# script.py import example x = [1, 2, 3, 4, 5, 6, 7, 8] array = example.INT_Array(10) for i in range(len(x)): array[i] = x[i] example.print_array(array)这些宏不会将 C 数组封装进特殊的数据结构或代理类中。没有边界检查或任何形式的安全检查。如果需要,应该考虑使用特殊的数组对象而不是裸指针
%array_functions() 和 %array_class() 不能和类型 char 或 char * 共同使用。
type *malloc_name(int nbytes = sizeof(type));/* example.i */ %module example %include "cmalloc.i" %inline %{ typedef unsigned char GM_UINT8; %} %malloc(GM_UINT8) %free(GM_UINT8) %malloc(int *, INTP) %free(int *, INTP)# script.py import example malloc_GM_UINT8 = example.malloc_GM_UINT8(1024) example.free_GM_UINT8(malloc_GM_UINT8) malloc_INTP = example.malloc_INTP(1024) example.free_INTP(malloc_INTP)
type *calloc_name(int nobj =1, int sz = sizeof(type));/* example.i */ %module example %include "cmalloc.i" %inline %{ typedef unsigned char GM_UINT8; %} %calloc(GM_UINT8) %free(GM_UINT8) %calloc(int *, INTP) %free(int *, INTP)# script.py import example malloc_GM_UINT8 = example.calloc_GM_UINT8(1024) example.free_GM_UINT8(malloc_GM_UINT8) malloc_INTP = example.calloc_INTP(1024) example.free_INTP(malloc_INTP)
创建以下原型的 realloc() 包装器:
注意:与 C 中的 realloc() 不同,此宏生成的包装器隐式包含相应类型的大小。例如,realloc_int(p, 100) 重新分配 p,使其包含 100 个整数。type *realloc_name(type *ptr, int nitems);
void free_name(type *ptr);
/* example.i */ %module example %include "cmalloc.i" %inline %{ typedef unsigned char GM_UINT8; %} %constant int sizeof_name = sizeof(GM_UINT8);# script.py import example a = example.sizeof_name print(a) # 1
/* example.i */ %module example %include "cmalloc.i" %inline %{ typedef unsigned char GM_UINT8; %} %allocators(GM_UINT8);// example.py def malloc_GM_UINT8(*args): return _example.malloc_GM_UINT8(*args) def calloc_GM_UINT8(*args): return _example.calloc_GM_UINT8(*args) def realloc_GM_UINT8(ptr, nitems): return _example.realloc_GM_UINT8(ptr, nitems) def free_GM_UINT8(ptr): return _example.free_GM_UINT8(ptr) sizeof_GM_UINT8 = _example.sizeof_GM_UINT8# script.py import example a = example.sizeof_GM_UINT8 print(a) # 1 malloc_GM_UINT8 = example.malloc_GM_UINT8(1024) example.free_GM_UINT8(malloc_GM_UINT8) malloc_GM_UINT8 = example.calloc_GM_UINT8(1024) example.free_GM_UINT8(malloc_GM_UINT8)
2.4 cdata.i
// 将 ptr 中 nbytes 大小的数据转换成字符串。ptr 可以是任何指针。 const char *cdata(void *ptr, size_t nbytes)// 将 s 中的所有字符串数据复制到 ptr 指向的内存中。该字符串可能包含嵌入的 NULL 字节。这实际上是 C 标准库中 memmove 函数的包装,该函数被声明为
void memmove(void *ptr,const void *src,size_t n)。src 和 length 参数是从底层包装器代码中特定于语言的字符串 s 中提取的。 void memmove(void *ptr, const char *s)/* example.i */ %module example %include "carrays.i" %include "cdata.i" %inline %{ typedef unsigned char GM_UINT8; %} %array_functions(GM_UINT8, GM_UINT8_Array);# script.py import example _data = [1, 2, 3, 4, 5, 6, 7, 8] array = example.new_GM_UINT8_Array(10) [example.GM_UINT8_Array_setitem(array, i, _data[i]) for i in range(len(_data))] b = example.cdata(array, 10) # 从缓存中取值 print((b,)) # ('\x01\x02\x03\x04\x05\x06\x07\x08\x00\x00',) c = example.new_GM_UINT8_Array(100) example.memmove(c, b) print(example.GM_UINT8_Array_getitem(c, 1)) # 2# 上面的功能可以当做Python2向Python3传递数据修改的方式, 在实际工作中,遇到如下现象的问题,Python2的方式和Python3的方式出现问题以及具体操作如下。 # Python2 import struct _head = struct.pack('!I', 10) # 在Python2 中 _head的数据类型是 str ptrSfmBuf = malloc_GM_UINT8(4096) memmove(ptrSfmBuf, _head) # Python3 import struct _head = struct.pack('!I', 10) # 在Python3 中 _head的数据类型是 bytes ptrSfmBuf = malloc_GM_UINT8(4096) # memmove(ptrSfmBuf, _head) # Python3中不能将bytes类型传递过去 _unhead = struct.unpack("!%dB"%(len(_head)), _head) array = new_GM_UINT8_Array(10) [GM_UINT8_Array_setitem(array, i, _unhead[i]) for i in range(len(_unhead))] _data = cdata(array, 10) # 从缓存中取值 memmove(ptrSfmBuf, _data)
由于并不总是知道数据大小,因此定义了 %cdata(type [, name=type])
生成以下函数为给定类型提取 C 数据。这个功能就相当于在接口文件中定义了取值的大小char *cdata_name(type* ptr, int nitems)nitems 是给定类型要提取的项目数。
注意:这些函数提供对内存的直接访问,并可用于覆盖数据。显然,它们是不安全的。
使用 C 程序时,一个常见的问题是处理使用 char * 操作原始字符数据的函数。部分情况下,出现问题是因为对 char * 有不同的解释——它可以是以 NULL 结尾的字符串,也可以指向二进制数据。此外,操作原始字符串的函数可能会改变数据,执行隐式内存分配或利用固定大小的缓冲区。
使用 char * 的问题(和危险)是众所周知的。但是,SWIG 并不涉及道德操守。本节中的模块提供用于处理原始 C 字符串的基本功能。
// example.c #include <string.h> char *foo(char *s) { printf("s = %s", s); }/* example.i */ %module example %{ extern char *foo(char *s); %} extern char *foo(char *s);# script.py import example example.foo("Hello") # s = Hellos 将指向 Python 解释器中 Hello 的表示。当返回 char * 时,SWIG 假定它是一个以 NULL 结尾的字符串,并对其进行复制。这为目标语言提供了自己的结果副本。
默认行为存在明显的问题。首先,由于 char * 参数指向目标语言内部的数据,因此函数修改该数据是不安全的(这样做可能会破坏解释器并导致崩溃)。此外,默认行为不适用于二进制数据,而是假定字符串以 NULL 终止。
size_t parity(char *str, size_t len, size_t initial);你可以使用类型映射将参数 (char * str, size_t len) 包装为单个参数。即这样做:
类型映射的相关内容在后面介绍
现在,在目标语言中,你可以使用像这样的二进制字符串数据:// example.c #include<string.h> typedef unsigned int size_t; size_t parity(char *str, size_t len, size_t initial) { printf("str=%s, initial=%d\n", str, initial); return len; }/* example.i */ %module example %inline %{ typedef unsigned int size_t; %} %apply (char *STRING, size_t LENGTH) { (char *str, size_t len) }; %{ extern size_t parity(char *str, size_t len, size_t initial); %} extern size_t parity(char *str, size_t len, size_t initial);# script.py import example s = "\x41\x41" # AA print(example.parity(s, 10)) # 5 str=AA, initial=10在包装器函数中,传递的字符串将扩展为指针和长度参数。除了 (char * STRING, size_t LENGTH) 外,(char * STRING, int LENGTH) 多参数类型映射也是可用的。
char *foo() { char *result = (char *) malloc(...); ... return result; }那么 SWIG 生成的包装器将发生内存泄漏,返回的数据将被复制到字符串对象中,而旧内容将被忽略。
要解决内存泄漏,请使用 %newobject 指令。
%newobject foo; ... char *foo();如果目标语言有适当的支持可用,结果将被释放。SWIG 为 char * 提供了适当的 newfree 类型映射,以便释放内存,但是,你可能需要为其他类型提供自己的 newfree 类型映射。
// example.c #include<string.h> typedef unsigned char GM_UINT8; void get_path(GM_UINT8 *path) { sprintf(path, "%s/%s", "base_directory", "sub_directory"); }/* example.i */ %module example %include "cstring.i" %inline %{ typedef unsigned char GM_UINT8; %} %cstring_bounded_output(GM_UINT8 *path, 1024); %{ extern void get_path(GM_UINT8 *); %} extern void get_path(GM_UINT8 *path);# script.py import example print(example.get_path()) # base_directory/sub_directory在内部,包装器函数会分配一个要求大小的小缓冲区(在堆栈上),并将其作为指针值传递。然后将存储在缓冲区中的数据作为函数返回值返回。如果函数已经返回一个值,则将返回值和输出字符串一起返回(多个返回值)。如果写入的字节数超过最大字节数,则程序将因缓冲区溢出而崩溃!
将参数 parm 转换为输出值。输出字符串始终为 chunksize,并且可能包含二进制数据
说明: 尚未研究出来,官方文档出现的现象与实际测试不符,待后续研究
/* example.i */ %module example %include "cstring.i" %inline %{ typedef unsigned char GM_UINT8; %} %define ARRAYHELPER 10 %cstring_chunk_output(char *packet, ARRAYHELPER); %enddef %{ extern void get_path(char *); %} extern void get_path(char *packet);
// example.c #include<string.h> typedef unsigned char GM_UINT8; void make_upper(GM_UINT8 *ustr){ for (char *i = ustr; *i != '\0'; ++i) { if (*i < 'a' || *i > 'z') { continue; } *i -= 'a' - 'A'; } }/* example.i */ %module example %include "cstring.i" %inline %{ typedef unsigned char GM_UINT8; %} %cstring_bounded_mutable(GM_UINT8 *ustr, 1024); %{ extern void make_upper(GM_UINT8 *ustr); %} extern void make_upper(GM_UINT8 *ustr);# script.py import example print(example.make_upper("hello world")) # HELLO WORLD在内部,此宏与 %cstring_bounded_output 几乎完全相同。唯一的区别是参数接受用于初始化内部缓冲区的输入值。需要强调的是,此函数不会使传递来的字符串值发生改变,而是复制输入值,对其进行改变并作为结果返回。如果写入的字节数超过最大字节数,则程序将因缓冲区溢出而崩溃!
// example.c #include<string.h> typedef unsigned char GM_UINT8; void make_upper(GM_UINT8 *ustr){ for (char *i = ustr; *i != '\0'; ++i) { if (*i < 'a' || *i > 'z') { continue; } *i -= 'a' - 'A'; } } void attach_header(GM_UINT8 *hstr){ strcat( hstr, " foot" ); }/* example.i */ %module example %include "cstring.i" %inline %{ typedef unsigned char GM_UINT8; %} %cstring_mutable(GM_UINT8 *ustr); %cstring_mutable(GM_UINT8 *hstr, 10); %{ extern void make_upper(GM_UINT8 *ustr); extern void attach_header(GM_UINT8 *hstr); %} extern void make_upper(GM_UINT8 *ustr); extern void attach_header(GM_UINT8 *hstr);# script.py import example print(example.make_upper("hello world")) # HELLO WORLD print(example.attach_header("hello world")) # hello world foot这个宏与 %cstring_bounded_mutable() 的不同之处在于动态地分配了一个缓冲区(在堆上使用 malloc 或 new)。此缓冲区始终足够大,可以存储输入值的副本以及可能已请求的任何扩展字节。需要强调的是,此函数不会直接更改传递的字符串值,而是复制输入值,对其进行更改并返回结果。如果函数将结果扩展多于扩展多余字节,则程序将因缓冲区溢出而崩溃!
// example.c #include<string.h> typedef unsigned char GM_UINT8; void get_path(GM_UINT8 *path, int maxpath){ sprintf(path, "%s/%s", "base_directory", "sub_directory"); }/* example.i */ %module example %include "cstring.i" %inline %{ typedef unsigned char GM_UINT8; %} %cstring_output_maxsize(GM_UINT8 *path, int maxpath); %{ extern void get_path(GM_UINT8 *path, int maxpath); %} extern void get_path(GM_UINT8 *path, int maxpath);# script.py import example print(example.get_path(1024)) # base_directory/sub_directory print(example.get_path(5)) # base_directory/sub_directory 按理说不应该是这个结果,原因不明对于需要将字符串数据写入缓冲区的函数,此宏提供了更安全的选择。用户提供的缓冲区大小用于在堆上动态分配内存。结果放入该缓冲区中,并作为字符串对象返回。
// example.c #include<string.h> typedef unsigned char GM_UINT8; void get_data(GM_UINT8 *data, int *maxdata){ sprintf(data, "%s/%s", "base_directory", "sub_directory"); }/* example.i */ %module example %include "cstring.i" %inline %{ typedef unsigned char GM_UINT8; %} %cstring_output_withsize(GM_UINT8 *data, int *maxdata); %{ extern void get_data(GM_UINT8 *data, int *maxdata); %} extern void get_data(GM_UINT8 *data, int *maxdata);# script.py import example print(example.get_data(1024)) # base_directory/sub_directory print(example.get_data(5)) # base_这个宏是 %cstring_output_chunk() 的更强大的版本。内存是动态分配的,可以任意大。此外,一个函数可以通过更改 maxparm 参数的值来控制实际返回多少数据。
五、实用函数库
SWIG_exception(int code, const char *message)message 是一个字符串,指示有关该问题的更多信息。
在目标语言中引发异常。code 是以下符号常量之一:SWIG_MemoryError SWIG_IOError SWIG_RuntimeError SWIG_IndexError SWIG_TypeError SWIG_DivisionByZero SWIG_OverflowError SWIG_SyntaxError SWIG_ValueError SWIG_SystemError%include "exception.i" %exception std::vector::getitem { try { $action } catch (std::out_of_range& e) { SWIG_exception(SWIG_IndexError, const_cast<char*>(e.what())); } }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号